inverted_index
1.0.0
搜尋周圍人說的短語可能很困難。這個資料集的動態更新怎麼樣?可擴充儲存和低延遲?我這個專案的主要目標是建立一個滿足這些要求並允許即時了解推文中存在的最新趨勢的系統。
按照倒排索引的想法,我實現了一個應用程序,可以實時查找具有特定內容的推文,將它們存儲在本地文件系統中,並允許在初始化客戶端連接後立即進行基於單詞的搜索。
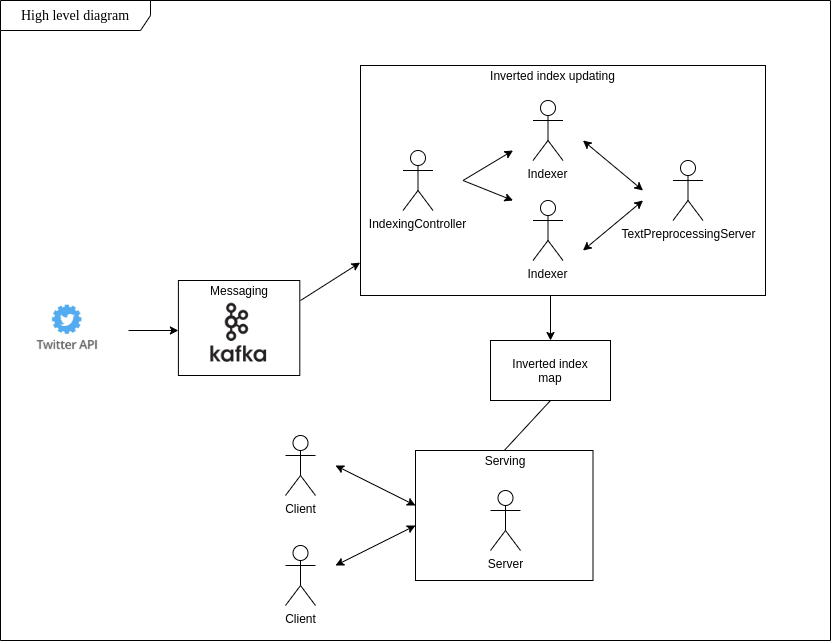
為了運行該應用程序,您需要:
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' 為客戶端和伺服器建立 Dockerfile:
./gradlew clean build createClientDockerfile createMainDockerfile
這將在根目錄中產生 app_server.Dockerfile 和 app_client.Dockerfile。
開始申請:
docker-compose up
啟動客戶端會話:
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
開始輸入感興趣的單字。伺服器將以「dataset_v2//tweet_N.txt」格式傳回推文的位置。例如:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
請參閱未決問題以取得建議功能(和已知問題)的清單。
根據 MIT 許可證分發。請參閱LICENSE以了解更多資訊。


