Sound Content Music Recommendation System
1.0.0

如果你跟我一樣,你會熱愛音樂。我熱愛音樂,也喜歡尋找新音樂。 Spotify 是網路上頂級的音樂串流服務之一,它已經包含了一些令人驚嘆的工具,可以幫助您根據您所聽的內容發現新音樂。它透過不同演算法的組合來實現這一點,包括協作過濾,其中追蹤用戶之間的相似使用情況並用於生成推薦或基於內容的推薦,這些推薦基於連結到歌曲的資訊之間的相似資訊推薦新歌曲。就像一首歌一樣?在 Spotify 上,您可以收聽該歌曲的“廣播”,它會以某種方式或多種方式的組合收集與該歌曲相似的一組歌曲。如果您喜歡一首歌,但除了其中的聲音之外不關心任何訊息怎麼辦?有時,這就是我想聽到的一切。
我創建這個專案是為了製作一個僅基於音樂聲音中的信息的音樂推薦系統。它將幫助用戶透過聽起來相似的歌曲找到新的音樂。為此,它還將探索所有音樂之間的相似性,並嘗試以數學方式捕捉歌曲的音色、節奏和風格。
聲音始終就在我們身邊。在我們的一生中,我們逐漸能夠辨別他人的不同聲音。音樂也不例外——音樂有很多種類型,而且音樂通常是許多不同種類的聲音和節奏的組合,我們也可以將它們與其他聲音和節奏區分開來。但我們可以自己量化這些資訊嗎?有時,音樂被分為流派,這意味著流派是一群具有相似風格、形式、節奏、音色、樂器或文化品質的音樂家。但並非每個音樂藝術家都以同一流派創作聲音,也並非每種流派都包含相同類型的音樂。那麼什麼是聲音,我們又該如何辨別不同類型的聲音呢?
聲音是聲波的振動,當聲波振動我們的耳膜時,我們可以透過耳朵感知聲音。聲波是一種訊號,該訊號振動的速度稱為頻率。如果聲音頻率較高,我們會感覺到該聲音的音調較高。在音樂中,低音或低音鼓等樂器會產生較低頻率振動的聲音,而高音則具有較高頻率。聽起來像是鈸或高帽的撞擊聲是不同頻率的許多波的組合,並由「嘈雜」、幾乎隨機的波表示。
聲音看起來像什麼?我們可視化聲音的一種方法是繪製隨時間變化的信號:
當我們縮短每個子圖上的時間視窗時,我們可以更近距離地看到音訊訊號。請注意,在訊號的最放大影像中,波是不同頻率的集合。可能存在一種低頻訊號與較小的高頻訊號組合。
因此,我們可以隨著時間的推移可視化訊號,但我們已經可以看出,僅透過查看此視覺化效果很難理解該聲波。 0.01 秒的視窗中存在哪些頻率?為了回答這個問題,我們將使用傅立葉變換來計算頻譜圖。
傅立葉變換是一種計算音頻訊號部分中存在的頻率幅度的方法。正如您在上圖中看到的,波可能很複雜,訊號的每種變化代表不同的頻率(振動速度)。傅立葉變換本質上會提取每個時間段的頻率,並產生頻率幅度與時間的二維數組。傅立葉變換的產物是頻譜圖。根據頻譜圖,我們將產生的頻率轉換為梅爾標度以建立梅爾頻譜圖。梅爾頻譜圖更好地代表了我們聽到頻率時所感知到的頻率之間的距離。
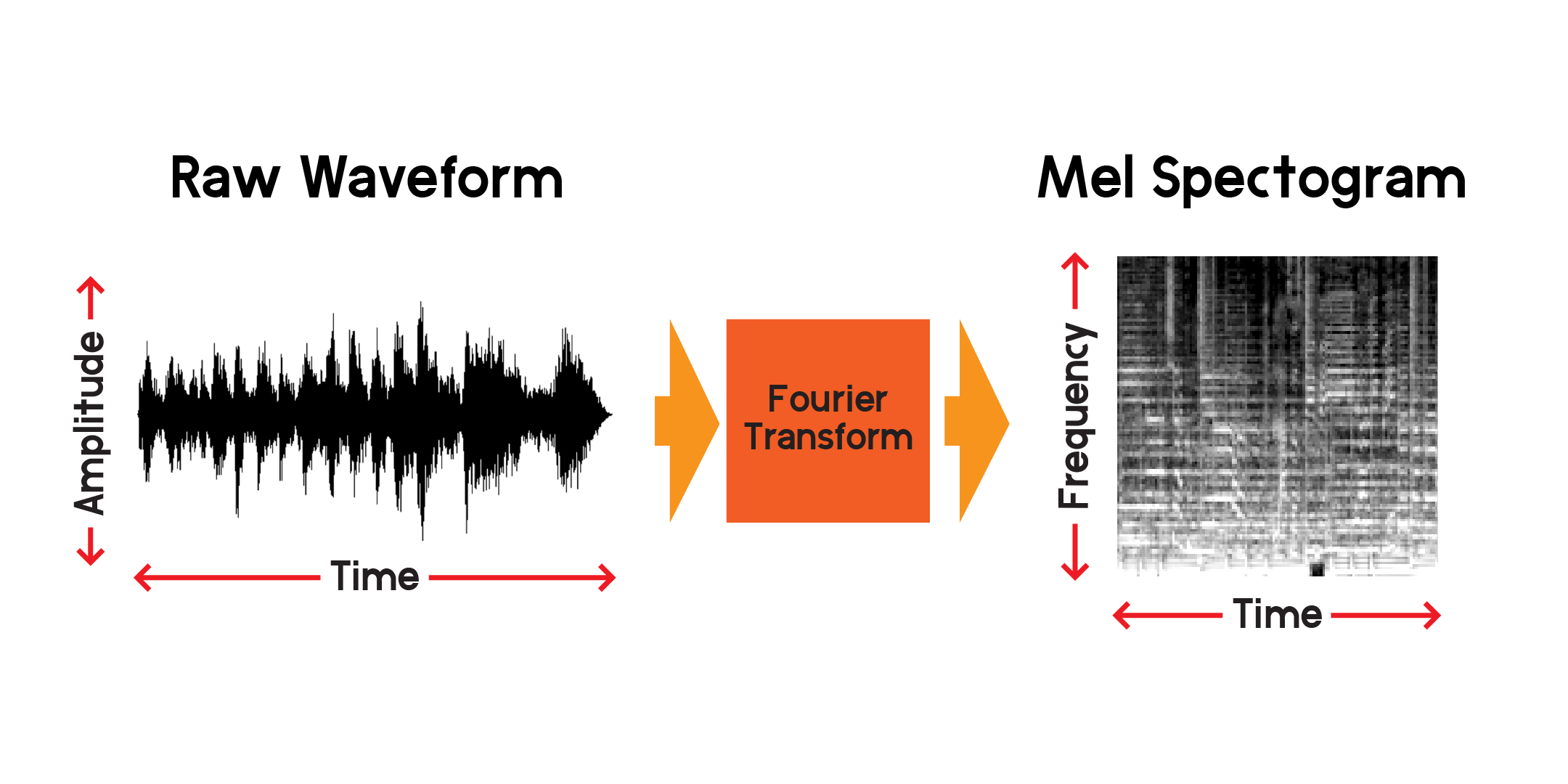
讓我們根據上面繪製的相同音訊樣本繪製梅爾頻譜圖的範例:
使用 Spotify 的公共 API,我在以前的筆記本中抓取了歌曲資訊。從那裡我可以下載每首歌曲的 30 秒 mp3 預覽,並將其轉換為梅爾頻譜圖,以便在訓練圖像的神經網路中使用。首先,讓我們看一下資料框,我們將使用它來收集 mp3 預覽。
在另一台筆記本中,我從 Spotify API 獲取了預覽鏈接,下載了 mp3,並將聲音文件轉換為包含梅爾頻譜圖、梅爾頻率倒譜係數和色譜圖的合成圖像。我創建這個合成圖像的目的是為了可以使用這些其他轉換,但對於這個項目,我將只在梅爾譜圖上訓練神經網路。
為了僅根據聲音內容推薦類似的歌曲,我需要創建以某種方式解釋歌曲內容的功能。此外,為了快速完成此操作,我需要將每首歌曲的資訊壓縮為比梅爾頻譜圖輸入更小的數字集。
每個歌曲預覽文件都有超過 600,000 個樣本。在每個梅爾譜圖中,有 512 x 128 像素,總計 65,536 像素。即使 128x128 的圖像也包含 16,384 個像素。這個自動編碼器模型會將歌曲的內容壓縮為僅 256 個數字。一旦自動編碼器經過充分訓練,網路將能夠以最小的損失從長度為 256 的向量重建歌曲。
自動編碼器是一種神經網絡,由編碼器和解碼器組成。首先,編碼器將輸入的資訊壓縮為更少量的數據,而解碼器將重建數據以盡可能接近原始輸出。
自動編碼器也是一種特殊類型的神經網絡,因為它不受監督,儘管它並非完全無監督。它是自我監督的,因為它使用其輸入來訓練模型的輸出。
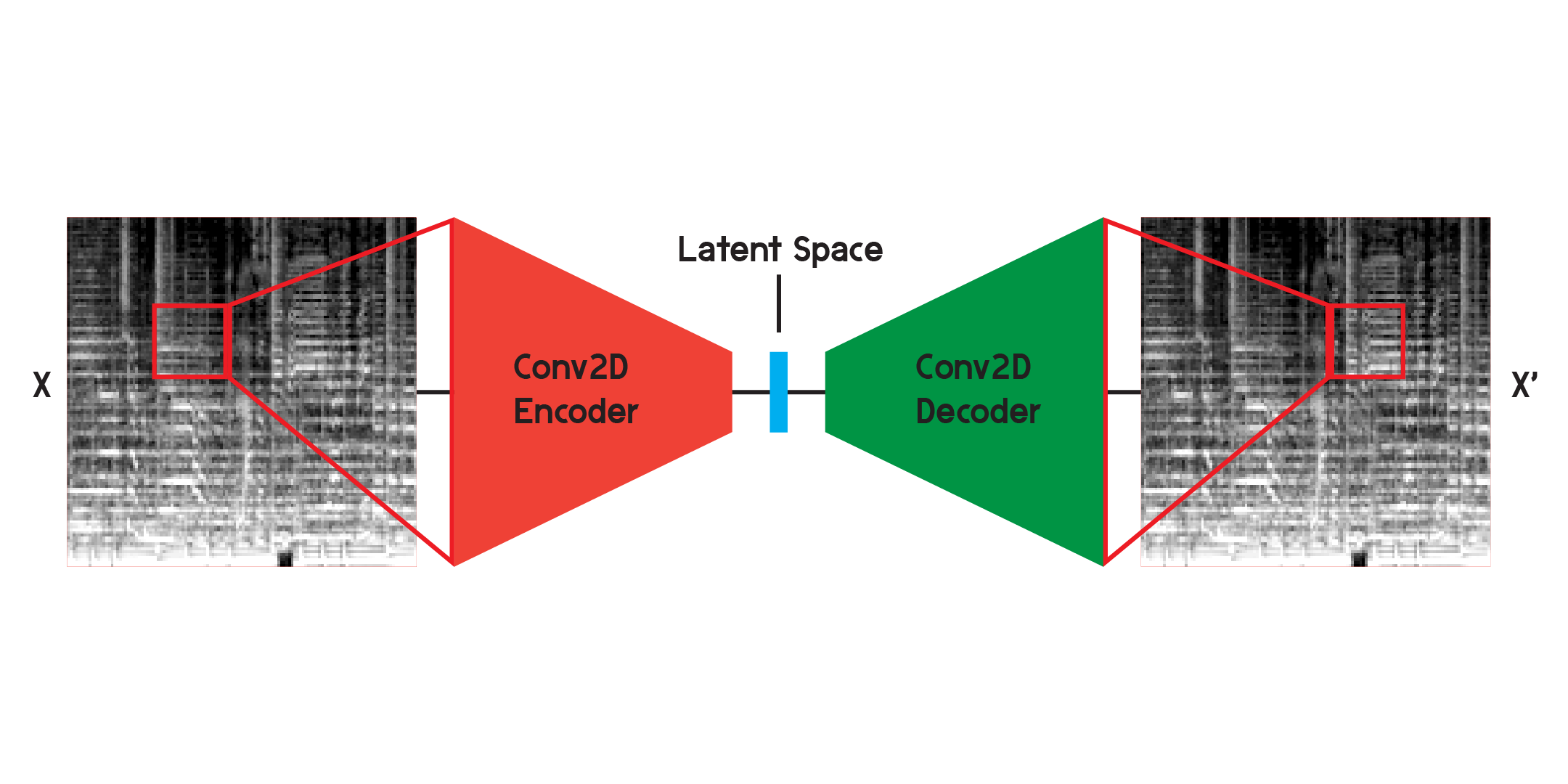
在處理影像時,編碼器是一系列二維卷積層,它創建加權濾波器來提取影像中的模式,同時也將影像壓縮為越來越小的形狀。解碼器是編碼器中過程的鏡像,將少量資料重塑和擴展為更大的資料。此模型最小化原始和重建之間的均方誤差。一旦經過充分訓練,模型的原始輸出和輸出之間的均方誤差將非常小。儘管均方誤差很小,但重建影像與原始影像之間仍然存在視覺差異,尤其是在最小的細節上。自動編碼器是一種降噪器。我們希望提取盡可能多的細節,但最終,自動編碼器也會混合一些細節。
我最初使用上面所示的結構來訓練網絡,但發現重建中缺少許多細節。卷積層搜尋只是整個影像的一小部分的模式。但在訓練和觀察過濾器之後,很難直觀地了解提取的模式。
像這樣的自動編碼器可以用於解決幾個不同的問題,並且透過卷積層,圖像識別和生成有許多應用。但由於梅爾聲譜圖不僅是影像,而且是聲音內容隨時間變化的頻率圖,我相信可以實現稍微不同的結構以最小化重建中的損失,同時也最小化二維卷積產生的不確定性層。
在模型最終結果所使用的模型中,我將編碼器拆分為兩個獨立的編碼器。每個編碼器使用一維卷積層來壓縮影像的空間。一個編碼器在 X 上進行訓練,而另一個編碼器在 X 轉置或輸入的 90 度旋轉版本上進行訓練。這樣,一個編碼器從圖像的時間軸學習訊息,另一個編碼器從頻率軸學習。
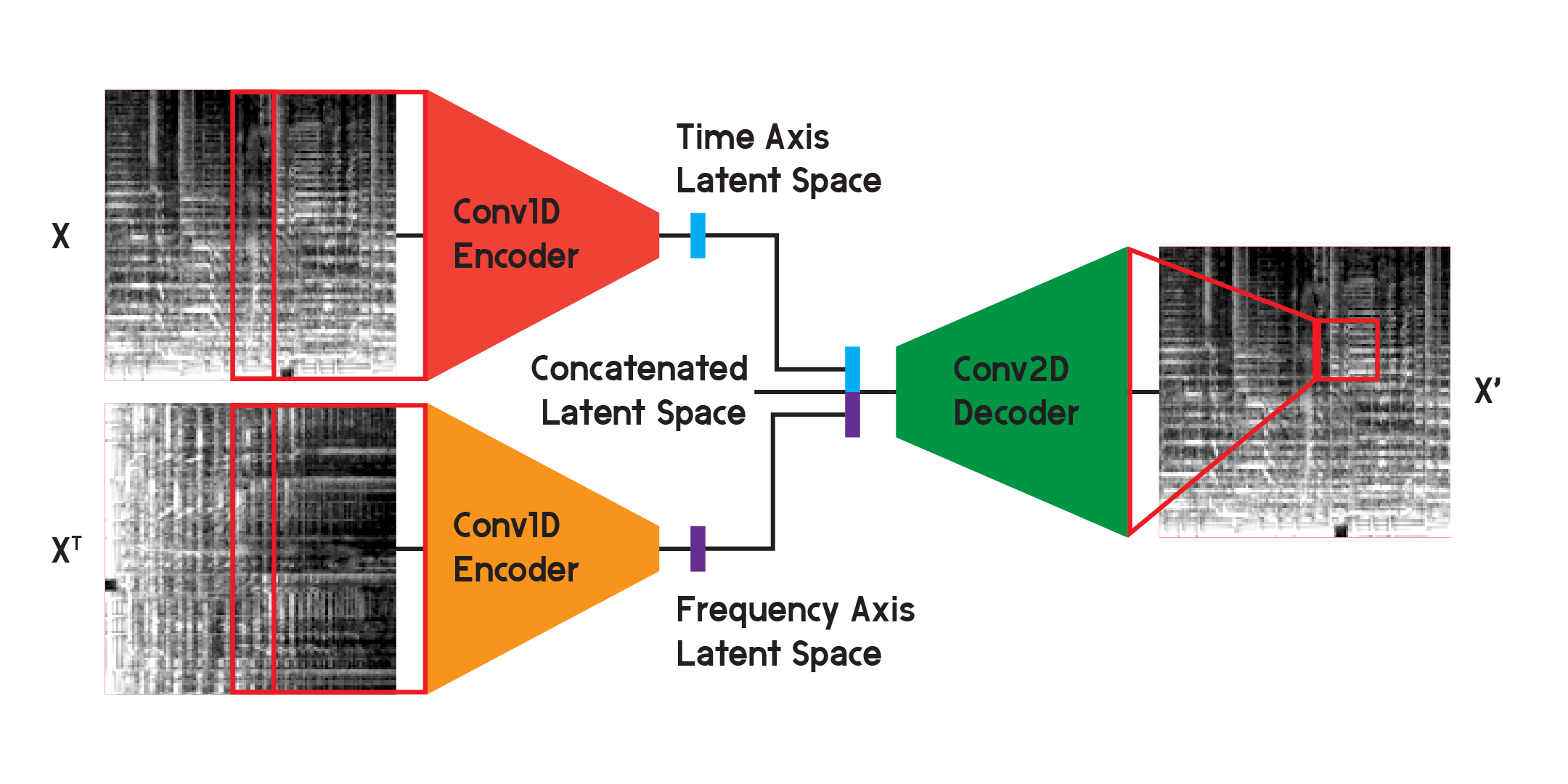
輸入經過每個編碼器後,得到的編碼向量連接成一個向量,並輸入到二維卷積解碼器中,如前所述。像以前一樣,對輸出進行訓練以最小化輸入之間的損失。
最終,最終模型的損失遠低於基本結構,20個epoch後均方誤差達到0.0037(訓練)和0.0037(驗證),訓練集中有125,440張圖像,訓練集中有2560張圖像。
我們將在這裡建立模型僅用於演示目的,因為我在另一個筆記本中訓練了該模型,並且在構建後將從訓練的模型中加載權重。
使用自訂類別透過網路運行推理並保存結果,我們可以為我們擁有的每個梅爾譜圖建立潛在空間。我們可以透過僅透過編碼器運行資料並接收我們初始化模型時大小的向量(在本例中為 256 維)來實現此目的。
為了透過模型探索資料潛在空間所創建的抽象景觀,我們可以使用降維。 UMAP 與 T-SNE 一樣,可以將多維空間縮減為二維,以便在繪圖中可視化。
自訂 LatentSpace 類別將使用每個向量的餘弦相似度來搜尋建議。
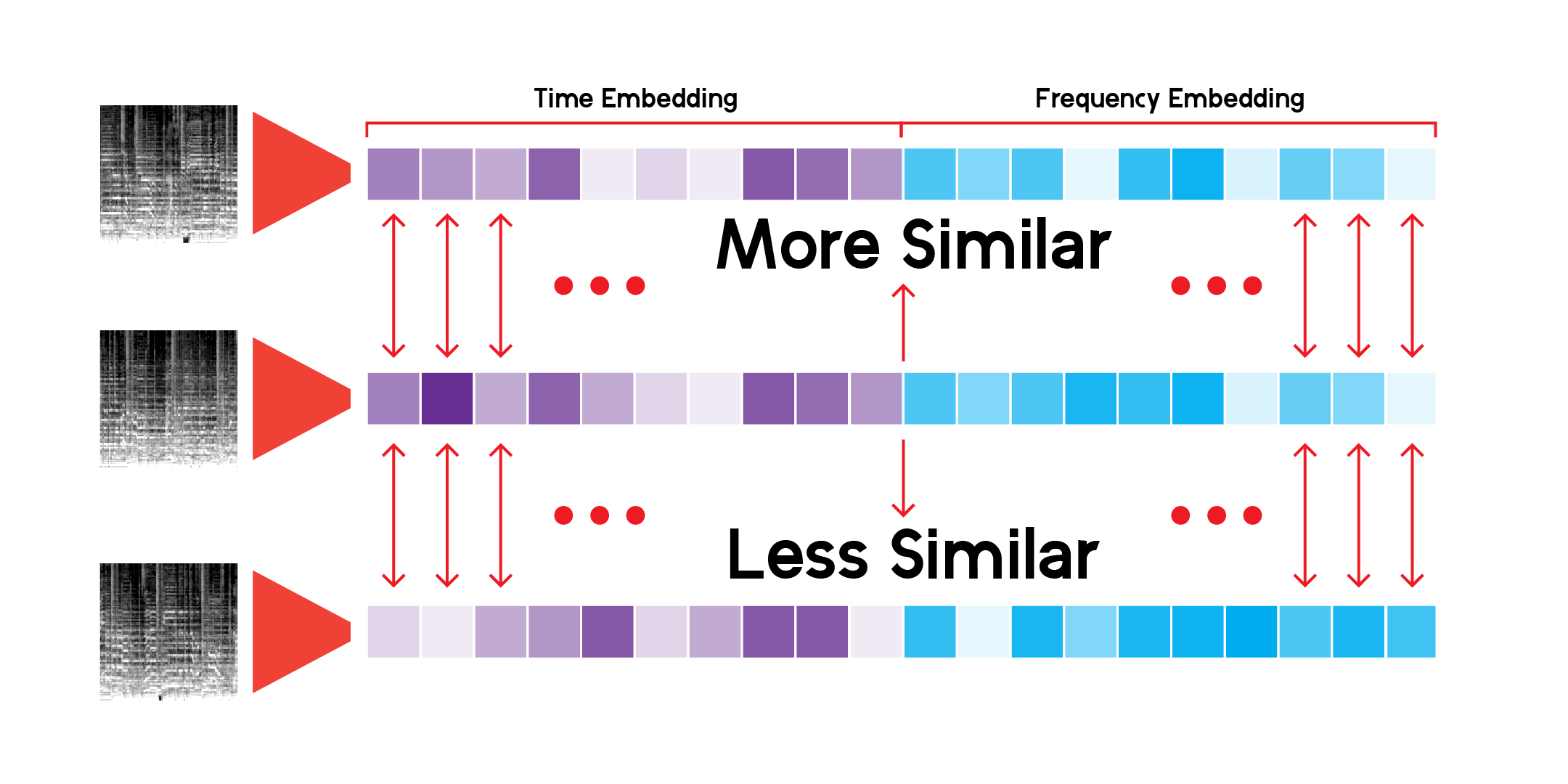
我一直在無休止地搜尋這個推薦系統,我很滿意該模型可以在不同但相似的音樂聲音之間找出非常有趣的聯繫。以下是我的一些結論:
我的意思是,該模型是根據每首歌曲的聲音內容進行推薦,但它並不是在聽歌曲。它創建梅爾譜圖並進行數學比較。
有時系統會根據歌曲的年齡推薦歌曲。如果一首歌曲是很久以前錄製的,那麼錄製材料或設備的那些特定頻率將被模型拾取,並顯示結果。
此外,該模型非常擅長拾取聲音或特定樂器。因此,如果一首歌有很多說唱或說唱,它可能只會推薦口語歌曲。此外,如果歌曲中有很多失真,它可能會建議雨聲或鳥鳴聲。
正如我最初的 EDA 中所指出的,某些曲目預覽在 Spotify API 中不可用。因此,他們對模型的貢獻也缺失,並且當他們可能非常適合時也不會被推薦。例如,沒有詹姆斯布朗、披頭四或普林斯的歌曲。需要更多數據。
該系統使用超過 278,000 個預覽來提供推薦,但這仍然不夠。查看所有軌道的 UMAP 投影,數據有很多連續性,但也存在一些漏洞。理想情況下,系統可以使用更多的數據來利用。
像 Spotify 這樣的推薦系統/服務之所以如此擅長提出推薦,是因為它結合了許多不同類型的推薦系統和像這樣的功能來提供推薦。從追蹤您經常收聽的內容,到使用協作過濾根據相似的用戶使用情況查找推薦,Spotify 可以對某人會喜歡和收聽的內容做出更平衡的預測。我確實發現這個模型對於進行預測很有趣,但是可以透過添加更多功能(例如類似的類型、發行年份和類似的用戶資料)來增強它,以做出更好的預測。
總而言之,除了做出預測和建議之外,我覺得這個模型的真正重要性在於解釋音樂語言和聲音的連續性和光譜。流派是人們給藝術家或聲音貼上的標籤,但流派混合在一起,每個聲音都存在於這個連續的空間中,至少在數學上是如此。
而且,音樂沒有障礙。大多數時候,當在推薦系統中查詢歌曲時,結果將來自各個不同的時代和不同的地方。由於歌曲的任何元資料都不是自動編碼器的輸入,因此結果基於其聲音相似性,僅此而已。


