nlp lt
1.0.0
這項研究的主要目的是研究和學習立陶宛語的自然語言處理(NLP)原理。分析經典的 NLP 方法並了解它們是如何運作的很有趣,因此在這項工作中我實現了文本分類、主題提取、搜尋查詢和聚類思想。實作細節和更多資訊儲存在paper/paper.pdf
沒有文字資料就無法進行資料分析,因為我的工作是從最受歡迎的新聞網站 www.delfi.lt 取得原始資料開始的。我決定抓取 5 個類別的文章(犯罪者[227 篇文章]、音樂[120 篇文章]、電影[167 篇文章]、體育[136 篇文章]、科學[204 篇文章])。
分類性能是使用混淆矩陣來衡量的,其中行是真實類別,列是預測類別。此外,這種方法可以達到 90% 以上的召回率和 90% 以上的準確率。 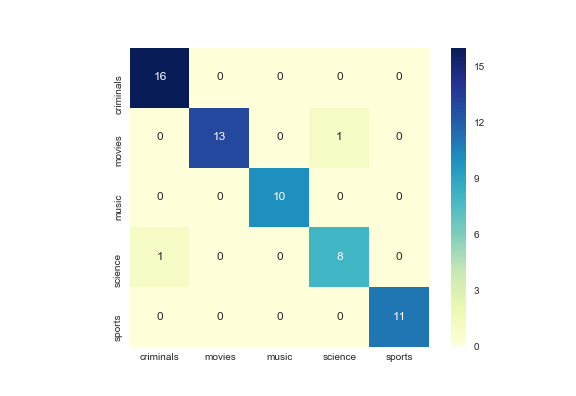
此圖顯示了 6 個元件,每個元件有 10 個令牌。從這些結果中,我們可以檢測最重要的單字並直觀地猜測每個主成分的主題。例如,4 個主成分儲存有關體育和音樂的信息,而 6 個主成分儲存有關犯罪分子的資訊。
主要結果如下: 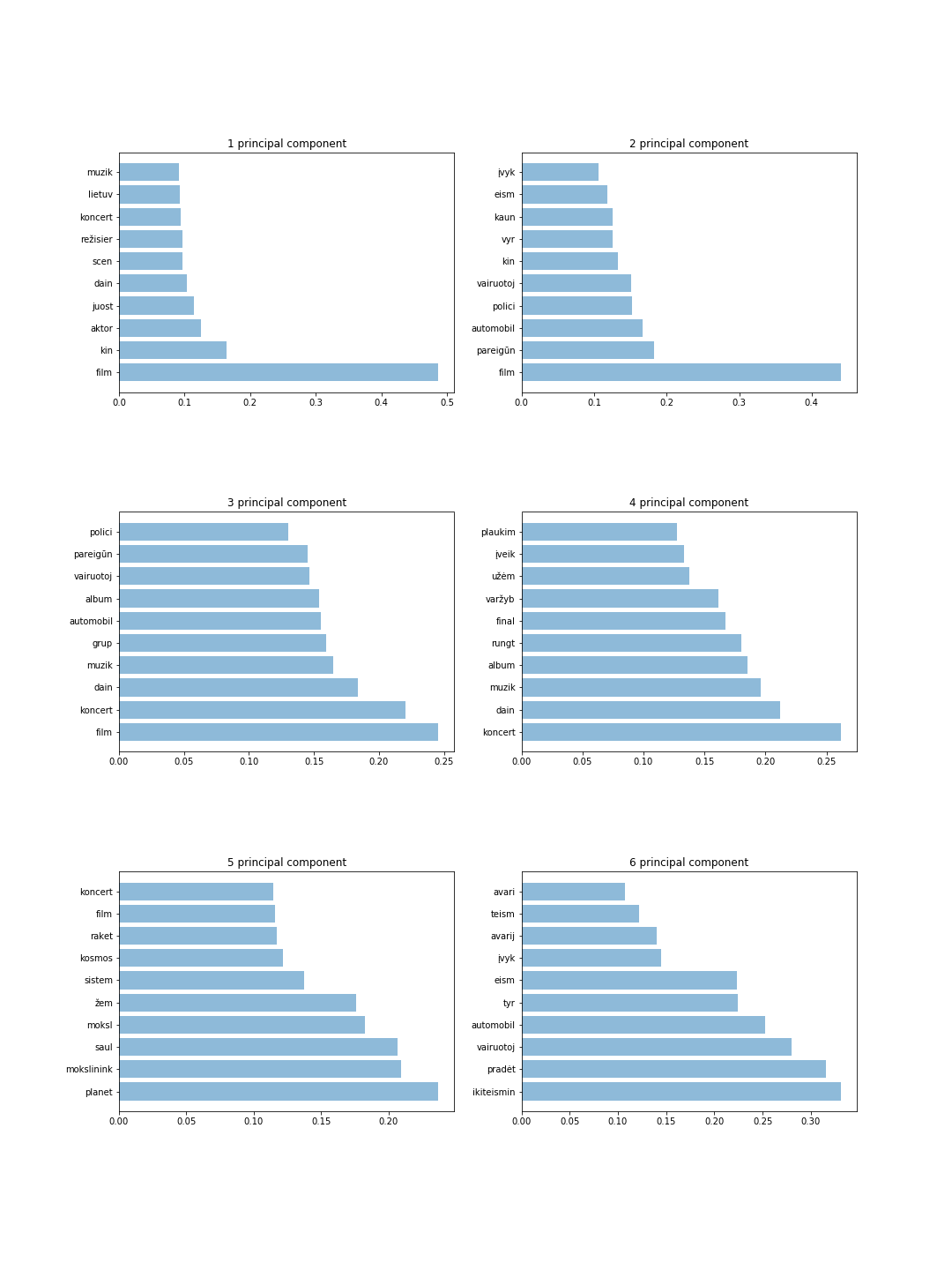
搜尋是基於 http://webhome.cs.uvic.ca/~thomo/svd.pdf 文章,其中 LSA 不僅使用精確的查詢相似性,還使用文件之間更深層的關係來尋找相關文件。 
查詢=“švietim apdovanojam”
結果:
進行中


