
該儲存庫包含有關各種技術主題的問題和練習,有時與 DevOps 和 SRE 相關
目前有2624 個練習和問題
️您可以使用這些來準備面試,但大多數問題和練習並不代表實際的面試。請閱讀常見問題頁面以了解更多詳情
? 如果您有興趣從事 DevOps 工程師的職業,學習這裡提到的一些概念會很有用,但您應該知道這並不是要學習此儲存庫中提到的所有主題和技術
您可以透過提交拉取請求來新增更多練習:) 在此閱讀貢獻指南

開發營運 | 
git | 
網路 | 
硬體 | 
庫伯內斯 |

軟體開發 | 
Python | 
去 | 
珀爾 | 
正規表示式 |

雲 | 
AWS | 
天藍色 | 
谷歌雲端平台 | 
開放式堆疊 |

作業系統 | 
Linux | 
虛擬化 | 
域名系統 | 
外殼腳本 |

資料庫 | 
SQL | 
蒙戈 | 
測試 | 
大數據 |

持續整合/持續交付 | 
證書 | 
貨櫃 | 
開放式班次 | 
貯存 |

地形 | 
木偶 | 
分散式 | 
您可以提出的問題 | 
安西布爾 |

可觀測性 | 
普羅米修斯 | 
圓CI | 
| 
格拉法納 |

阿爾戈 | 
軟技能 | 
安全 | 
系統設計 |

混沌工程 | 
雜項 | 
鬆緊帶 | 
卡夫卡 | 
NodeJs |
網路
一般來說,為了溝通你需要什麼?
- 共同語言(供兩端理解)
- 一種稱呼您想要與誰通信的方式
- 連接(以便通信的內容可以到達接收者)
什麼是 TCP/IP?
定義兩個或多個設備如何相互通訊的一組協定。
要了解有關 TCP/IP 的更多信息,請閱讀此處
什麼是乙太網路?
乙太網路只是指當今最常見的區域網路 (LAN) 類型。與跨越較大地理區域的 WAN(廣域網路)不同,LAN 是一個小區域(例如您的辦公室、大學校園,甚至家庭)內的電腦互連網路。
什麼是MAC位址?它有什麼用?
MAC 位址是用來識別網路上各個裝置的唯一識別號碼或代碼。
在乙太網路上傳送的封包始終來自 MAC 位址並傳送到 MAC 位址。如果網路適配器正在接收封包,它會將封包的目標 MAC 位址與適配器自己的 MAC 位址進行比較。
該 MAC 位址何時使用?
當裝置將封包傳送至廣播 MAC 位址 (FF:FF:FF:FF:FF:FF) 時,該封包將會傳送到本機網路上的所有站點。乙太網路廣播用於在資料鏈結層將 IP 位址解析為 MAC 位址(透過 ARP)。
什麼是IP位址?
網際網路通訊協定位址(IP 位址)是指派給連接到使用網際網路協定進行通訊的電腦網路的每個裝置的數位標籤。
解釋子網路遮罩並舉例
子網路遮罩是一個 32 位元數字,用於封鎖 IP 位址並將 IP 位址分為網路位址和主機位址。子網路遮罩是透過將網路位元設為全「1」並將主機位元設為全「0」來形成的。在給定網路中,在可用主機位址總數中,始終保留兩個用於特定目的,並且不能分配給任何主機。它們是第一個位址,被保留為網路位址(也稱為網路 ID),以及最後一個位址用於網路廣播。
例子
什麼是私有IP位址?在哪些場景/系統設計中應該使用它?
私有IP位址分配給同一網路中的主機以實現相互通訊。顧名思義,「私有」意味著分配有私有 IP 位址的裝置無法被任何外部網路的裝置存取。例如,如果我住在旅館裡,並且我希望我的旅館夥伴加入我託管的遊戲伺服器,我會要求他們透過我的伺服器的私人 IP 位址加入,因為網路是旅館的本地網路。什麼是公共IP位址?在哪些場景/系統設計中應該使用它?
公用 IP 位址是面向公眾的 IP 位址。如果您正在託管您希望您的朋友加入的遊戲伺服器,您將向您的朋友提供您的公用 IP 位址,以允許他們的電腦識別和定位您的網路和伺服器,以便進行連線。有時,您不需要使用面向公眾的 IP 位址,如果您正在與與您連接到相同網路的朋友一起玩,在這種情況下,您將使用私人 IP 位址。為了讓某人能夠連接到您位於內部的伺服器,您必須設定一個連接埠轉送來告訴您的路由器允許來自公共網域的流量進入您的網絡,反之亦然。解釋 OSI 模型。有哪幾層?每層負責什麼?
- 應用程式:用戶端(此處為 HTTP)
- 表示:在應用程式層實體之間建立上下文(此處為加密)
- 會話:建立、管理和終止連接
- 傳輸:將可變長度資料序列從來源主機傳輸到目標主機(TCP
- 網路:將資料封包從一個網路傳輸到另一個網路(IP 在這裡)
- 資料鏈路:在兩個直接連接的節點之間提供連結(MAC 在這裡)
- 物理:資料連接的電氣和物理規格(位在這裡
- )
)
您可以在 penguintutor.com 中閱讀有關 OSI 模型的更多信息
對於下列各項,確定其屬於哪一個 OSI 層:- 糾錯
- 資料包路由
- 電纜和電訊號
- MAC位址
- IP位址
- 終止連線
- 3次握手
糾錯 - 資料鏈路資料包路由 - 網路電纜和電訊號 - 實體MAC 位址 - 資料鏈路IP 位址 - 網路終止連線 - 會話3 次握手 - 傳輸您熟悉哪些交付方案?
單播:一對一通信,其中有一個發送者和一個接收者。
廣播:向網路中的每個人發送訊息。地址 ff:ff:ff:ff:ff:ff 用於廣播。使用廣播的兩種常見協定是 AR 和 DHCP。
群播:向一組訂閱者發送訊息。它可以是一對多或多對多。
什麼是 CSMA/CD?它在現代以太網中使用嗎?
CSMA/CD 代表載波偵聽多路存取/衝突偵測。其主要重點是管理對共用媒體/匯流排的訪問,其中在給定時間點只有一台主機可以進行傳輸。
CSMA/CD演算法:
在發送幀之前,它會檢查另一台主機是否已經在發送幀。- 如果沒有人在傳輸,則它開始傳輸該幀。
- 如果兩個主機同時傳輸,就會發生衝突。
- 兩台主機都停止發送幀,並向每個人發送“堵塞信號”,通知每個人發生了衝突
- 他們正在等待隨機時間,然後再次發送
- 一旦每個主機等待隨機時間,它們就會嘗試再次發送幀,因此循環再次開始
描述以下網路設備以及它們之間的差異:
路由器、交換器和集線器都是用於連接區域網路 (LAN) 中的設備的網路設備。然而,每種設備的操作方式不同,並且有其特定的用例。以下是每個設備的簡要說明以及它們之間的差異:
路由器:將多個網段連接在一起的網路設備。它在 OSI 模型的網路層(第 3 層)運行,並使用路由協定在網路之間引導資料。路由器使用 IP 位址來識別設備並將封包路由到正確的目的地。- 交換器:連接區域網路上多個設備的網路設備。它在 OSI 模型的資料鏈結層(第 2 層)運行,並使用 MAC 位址來識別設備並將資料包定向到正確的目的地。交換器允許同一網路上的設備更有效地相互通信,並且可以防止多個設備同時發送資料時可能發生的資料衝突。
- 集線器(Hub):透過一條電纜連接多個設備的網路設備,用於連接多個設備而不需要對網路進行分段。然而,與交換器不同的是,它在 OSI 模型的實體層(第 1 層)運行,並且只是將資料包廣播到與其連接的所有設備,無論該設備是否是預期接收者。這意味著可能會發生資料衝突,從而導致網路效率受到影響。現代網路設定中通常不使用集線器,因為交換器效率更高並提供更好的網路效能。
什麼是「衝突域」?
衝突域是一個網段,其中設備可能會因同時嘗試傳輸資料而相互幹擾。當兩個設備同時傳輸資料時,可能會引起衝突,從而導致資料遺失或損壞。在衝突域中,所有裝置共用相同的頻寬,且任何裝置都可能幹擾其他裝置的資料傳輸。什麼是「廣播域」?
廣播域是一個網段,其中所有設備都可以透過發送廣播訊息來相互通訊。廣播訊息是發送到網路中的所有設備而不是特定設備的訊息。在廣播域中,所有裝置都可以接收和處理廣播訊息,無論該訊息是否是發給它們的。三台電腦連接到一個交換器。有多少個衝突域?有多少個廣播域?
3個衝突域和1個廣播域
路由器如何運作?
路由器是在兩個或多個資料包交換電腦網路之間傳遞訊息的實體或虛擬設備。路由器檢查給定封包的目標網際網路通訊協定位址(IP 位址),計算其到達目的地的最佳方式,然後相應地轉送它。
什麼是NAT?
網路位址轉換 (NAT) 是將一個或多個本機 IP 位址轉換為一個或多個全域 IP 位址(反之亦然)的過程,以便為本機提供 Internet 存取。
什麼是代理?它是如何運作的?我們需要它做什麼?
代理伺服器可作為您和網際網路之間的網關。它是一個中間伺服器,將最終用戶與他們瀏覽的網站分開。
如果您使用代理伺服器,網路流量將透過代理伺服器流向您要求的位址。然後,請求透過同一個代理伺服器返回(此規則也有例外),然後代理伺服器將從網站收到的資料轉發給您。
代理伺服器根據您的使用案例、需求或公司政策提供不同程度的功能、安全性和隱私。
什麼是TCP?它是如何運作的?什麼是3次握手?
TCP 3 次握手或三向握手是 TCP/IP 網路中用於在伺服器和用戶端之間建立連線的過程。
三向握手主要用於建立 TCP 套接字連線。它在以下情況下起作用:
用戶端節點透過 IP 網路將 SYN 封包傳送到同一網路或外部網路上的伺服器。該資料包的目的是詢問/推斷伺服器是否對新連線開放。- 目標伺服器必須具有可以接受和發起新連線的開放連接埠。當伺服器從用戶端節點接收到 SYN 封包時,它會做出回應並傳回確認收據 – ACK 封包或 SYN/ACK 封包。
- 客戶端節點接收來自伺服器的 SYN/ACK 並以 ACK 封包回應。
什麼是往返延遲或往返時間?
來自維基百科:“發送訊號所需的時間加上接收訊號確認所需的時間”
額外問題:LAN 的 RTT 是多少?
SSL 握手如何運作?
SSL 握手是在客戶端和伺服器之間建立安全連線的過程。客戶端向伺服器發送 Client Hello 訊息,其中包含客戶端的 SSL/TLS 協定版本、客戶端支援的加密演算法清單以及隨機值。- 伺服器使用 Server Hello 訊息進行回應,其中包括伺服器的 SSL/TLS 協定版本、隨機值和會話 ID。
- 伺服器發送證書訊息,其中包含伺服器的證書。
- 伺服器傳送 Server Hello Done 訊息,表示伺服器已完成傳送 Server Hello 階段的訊息。
- 客戶端發送客戶端密鑰交換訊息,其中包含客戶端的公鑰。
- 客戶端發送 Change Cipher Spec 訊息,通知伺服器客戶端即將發送使用新密碼規範加密的訊息。
- 用戶端會傳送加密握手訊息,其中包含使用伺服器公鑰加密的預主金鑰。
- 伺服器發送 Change Cipher Spec 訊息,通知客戶端伺服器即將發送使用新密碼規範加密的訊息。
- 伺服器發送加密握手訊息,其中包含使用客戶端公鑰加密的預主密鑰。
- 客戶端和伺服器現在可以交換應用程式資料。
TCP 和 UDP 有什麼差別?
TCP 在客戶端和伺服器之間建立連接以確保包的順序,而 UDP 在客戶端和伺服器之間不建立連接,且不處理包順序。這使得 UDP 比 TCP 更輕量級,並且是串流媒體等服務的完美候選者。
Penguintutor.com 提供了很好的解釋。
您熟悉哪些 TCP/IP 協定?
解釋一下“預設網關”
預設閘道可作為存取點或 IP 路由器,連網電腦使用它向另一個網路或 Internet 中的電腦傳送訊息。
什麼是ARP?它是如何運作的?
ARP 代表位址解析協定。當您嘗試 ping 本機網路上的 IP 位址(例如 192.168.1.1)時,您的系統必須將 IP 位址 192.168.1.1 轉換為 MAC 位址。這涉及到使用 ARP 來解析位址,因此得名。
系統保留一個 ARP 查找表,其中儲存有關哪些 IP 位址與哪些 MAC 位址關聯的資訊。當嘗試將封包傳送到 IP 位址時,系統會先查閱此表以查看它是否已經知道 MAC 位址。如果有快取值,則不使用 ARP。
什麼是TTL?它有助於預防什麼?
TTL(生存時間)是 IP(網際網路協定)資料包中的一個值,用於確定資料包在被丟棄之前可以經過多少跳或路由器。路由器每轉送一個封包,TTL 值就會減一。當 TTL 值達到零時,資料包將被丟棄,並向發送方發送回 ICMP(網際網路控制訊息協定)訊息,表示資料包已過期。- TTL 用於防止封包在網路中無限循環,這會導致擁塞並降低網路效能。
- 它還有助於防止資料包陷入路由環路,即資料包在同一組路由器之間連續傳輸而永遠不會到達目的地。
- 此外,TTL 可用於協助偵測和防止 IP 欺騙攻擊,即攻擊者嘗試使用虛假或偽造的 IP 位址冒充網路上的其他裝置。透過限制封包可以傳輸的跳數,TTL 可以幫助防止封包被路由到不合法的目的地。
什麼是 DHCP?它是如何運作的?
它代表動態主機配置協議,為主機分配 IP 位址、子網路遮罩和網關。它是這樣運作的:
- 主機在進入網路時會廣播一則訊息來搜尋 DHCP 伺服器 (DHCP DISCOVER)
- DHCP 伺服器將提供訊息作為包含租用時間、子網路遮罩、IP 位址等的封包傳回(DHCP OFFER)
- 根據接受的報價,用戶端發回回覆廣播,讓所有 DHCP 伺服器知道(DHCP 請求)
- 伺服器發送確認(DHCP ACK)
在這裡閱讀更多內容
同一網路上可以有兩台 DHCP 伺服器嗎?它是如何運作的?
在同一網路上可以有兩個 DHCP 伺服器,但是,不建議這樣做,並且仔細配置它們以防止衝突和配置問題非常重要。
當在同一網路上配置兩個 DHCP 伺服器時,存在兩個伺服器將 IP 位址和其他網路配置設定指派給相同裝置的風險,這可能會導致衝突和連線問題。此外,如果 DHCP 伺服器配置有不同的網路設定或選項,網路上的裝置可能會收到衝突或不一致的設定。- 然而,在某些情況下,同一網路上可能需要有兩台 DHCP 伺服器,例如在大型網路中,一台 DHCP 伺服器可能無法處理所有請求。在這種情況下,可以將 DHCP 伺服器設定為服務不同的 IP 位址範圍或不同的子網,這樣它們就不會相互幹擾。
什麼是 SSL 隧道?它是如何運作的?
- SSL(安全通訊端層)隧道是一種用於透過不安全網路(例如 Internet)在兩個端點之間建立安全加密連線的技術。 SSL 隧道是透過將流量封裝在 SSL 連線中而建立的,它提供機密性、完整性和身分驗證。
SSL 隧道的工作原理如下:
客戶端發起與伺服器的 SSL 連接,這涉及建立 SSL 會話的握手過程。- SSL會話建立後,用戶端和伺服器協商加密參數,例如加密演算法和金鑰長度,然後交換數位憑證以相互驗證。
- 然後,客戶端透過 SSL 隧道將流量傳送到伺服器,伺服器解密流量並將其轉送到目的地。
- 伺服器透過 SSL 隧道將流量傳送回客戶端,客戶端解密流量並將其轉送到應用程式。
什麼是套接字?在哪裡可以看到系統中的套接字清單?
套接字是一種軟體端點,可透過網路在進程之間進行雙向通訊。套接字為網路通訊提供標準化接口,允許應用程式透過網路發送和接收資料。若要查看 Linux 系統上開啟的套接字清單: netstat -an- 此命令顯示所有開啟的套接字的列表,以及它們的協定、本機位址、外部位址和狀態。
什麼是 IPv6?如果我們有 IPv4,為什麼還要考慮使用它?
- IPv6(網際網路通訊協定版本 6)是網際網路通訊協定 (IP) 的最新版本,用於識別網路上的裝置並與其通訊。 IPv6位址是128位址,以十六進位表示,例如2001:0db8:85a3:0000:0000:8a2e:0370:7334。
我們應該考慮使用 IPv6 而不是 IPv4 有幾個原因:
位址空間:IPv4的位址空間有限,在世界許多地方已經耗盡。 IPv6 提供了更大的位址空間,允許數萬億個唯一的 IP 位址。- 安全性:IPv6 包括對 IPsec 的內建支持,它為網路流量提供端對端加密和身份驗證。
- 效能:IPv6 包含有助於提高網路效能的功能,例如多播路由,它允許將單一資料包同時傳送到多個目的地。
- 簡化網路配置:IPv6 包含可簡化網路配置的功能,例如無狀態自動配置,允許設備自動配置自己的 IPv6 位址,而無需 DHCP 伺服器。
- 更好的行動性支援:IPv6 包含可以改善行動性支援的功能,例如行動 IPv6,它允許設備在不同網路之間移動時保留其 IPv6 位址。
什麼是VLAN?
- VLAN(虛擬區域網路)是一種邏輯網絡,它將實體網路上的一組裝置組合在一起,無論其實體位置為何。 VLAN 是透過設定網路交換器將特定的 VLAN ID 指派給連接到交換器上特定連接埠或連接埠群組的裝置所傳送的封包來建立的。
什麼是 MTU?
MTU 代表最大傳輸單元。它是可以在單一交易中傳送的最大 PDU(協定資料單元)的大小。
如果傳送的資料包大於 MTU,會發生什麼情況?
透過IPv4協議,路由器可以對PDU進行分段,然後透過事務發送所有分段的PDU。
使用 IPv6 協議,它會向使用者的電腦發出錯誤。
是真是假? Ping 使用 UDP,因為它不關心可靠連接
錯誤的。 Ping實際上使用的是ICMP(Internet控制訊息協議),它是一種網路協議,用於發送與網路通訊相關的診斷訊息和控制訊息。
什麼是SDN?
SDN 代表軟體定義網路。它是一種強調網路控制集中化的網路管理方法,使管理員能夠透過軟體抽象化來管理網路行為。- 在傳統網路中,路由器、交換器和防火牆等網路設備是使用專用軟體或命令列介面單獨設定和管理的。相較之下,SDN將網路控制平面與資料平面分開,讓管理員可以透過集中式軟體控制器來管理網路行為。
什麼是 ICMP?它有什麼用?
- ICMP 代表網際網路控制訊息協定。它是一種用於 IP 網路中診斷和控制目的的協定。它是互聯網協議套件的一部分,在網路層運行。
ICMP 訊息有多種用途,包括:
錯誤報告:ICMP 訊息用於報告網路中發生的錯誤,例如無法傳送到目的地的資料包。- Ping:ICMP 用於發送 ping 封包,用於測試主機或網路是否可達以及測量封包的往返時間。
- 路徑MTU發現:ICMP用於發現路徑的最大傳輸單元(MTU),即在不分片的情況下可以傳輸的最大資料包大小。
- Traceroute:traceroute 實用程式使用 ICMP 來追蹤封包通過網路的路徑。
- 路由器發現:ICMP 用於發現網路中的路由器。
什麼是NAT?它是如何運作的?
NAT 代表網路位址轉換。這是一種在傳輸資訊之前將多個本地專用位址對應到公共位址的方法。希望多個裝置使用單一 IP 位址的組織會使用 NAT,大多數家庭路由器也是如此。例如,您電腦的私人 IP 可能是 192.168.1.100,但您的路由器將流量對應到其公用 IP(例如 1.1.1.1)。網路上的任何裝置都會看到來自您的公用 IP (1.1.1.1) 而不是您的私人 IP (192.168.1.100) 的流量。
以下每個協定使用哪個連接埠號碼?- SSH
- 郵件傳輸協定
- HTTP協定
- 域名系統
- HTTPS
- 文件傳輸協定
- SFTP
SSH-22- SMTP-25
- HTTP-80
- 域名系統-53
- HTTPS - 443
- FTP-21
- SFTP-22
哪些因素會影響網路效能?
有幾個因素會影響網路效能,包括:
頻寬:網路連線的可用頻寬會顯著影響其效能。頻寬有限的網路可能會遇到資料傳輸速率慢、延遲高和回應能力差的情況。- 延遲:延遲是指資料從網路中的一點傳輸到另一點時發生的延遲。高延遲可能會導致網路效能下降,尤其是對於視訊會議和線上遊戲等即時應用程式。
- 網路擁塞:當太多設備同時使用網路時,可能會發生網路擁塞,導致資料傳輸速率慢和網路效能差。
- 丟包:當資料包在傳輸過程中遺失時,就會發生丟包。這可能會導致網路速度變慢並降低整體網路效能。
- 網路拓撲:網路的實體佈局(包括交換器、路由器和其他網路設備的放置)可能會影響網路效能。
- 網路協定:不同的網路協定具有不同的效能特徵,這會影響網路效能。例如,TCP 是一種可靠的協議,可以保證資料的傳送,但由於錯誤檢查和重傳所需的開銷,它也會導致效能下降。
- 網路安全:防火牆和加密等安全措施可能會影響網路效能,特別是當它們需要大量處理能力或引入額外延遲時。
- 距離:網路上設備之間的物理距離會影響網路效能,尤其是對於訊號強度和乾擾會影響連接和資料傳輸速率的無線網路。
什麼是APIPA?
APIPA 是當主 DHCP 伺服器無法存取時為設備指派的一組 IP 位址
APIPA 使用什麼 IP 範圍?
APIPA 使用的 IP 範圍:169.254.0.1 - 169.254.255.254。
控制平面和資料平面
「控制平面」指的是什麼?
控制平面是網路的一部分,決定如何將封包路由和轉送到不同的位置。
「數據平面」指的是什麼?
資料平面是實際轉送資料/資料包的網路的一部分。
「管理平面」指的是什麼?
它指的是監控和管理功能。
建立路由表屬於哪個平面(資料、控制…)?
控制平面。
解釋生成樹協定 (STP)。
什麼是鏈路聚合?為什麼要使用它?
什麼是不對稱路由?怎麼處理呢?
您熟悉哪些覆蓋(隧道)協定?
什麼是 GRE?它是如何運作的?
什麼是VXLAN?它是如何運作的?
什麼是 SNAT?
解釋一下OSPF。
OSPF(開放最短路徑優先)是一種可以在各種類型的路由器上實現的路由協定。一般來說,大多數現代路由器都支援 OSPF,包括 Cisco、Juniper 和華為等供應商的路由器。該協定設計用於基於 IP 的網絡,包括 IPv4 和 IPv6。此外,它採用分層網路設計,其中路由器分為多個區域,每個區域都有自己的拓撲圖和路由表。這種設計有助於減少路由器之間需要交換的路由資訊量,提高網路的可擴展性。
OSPF 4 種類型的路由器是:
- 內部路由器
- 區域邊界路由器
- 自治系統邊界路由器
- 骨幹路由器
了解有關 OSPF 路由器類型的更多資訊:https://www.educba.com/ospf-router-types/
什麼是延遲?
延遲是資訊從來源到達目的地所花費的時間。
什麼是頻寬?
頻寬是通訊通道的容量,用於衡量後者在特定時間內可以處理多少資料。更多的頻寬意味著更多的流量處理,從而意味著更多的資料傳輸。
什麼是吞吐量?
吞吐量是指在一定時間內通過任何傳輸通道傳輸的實際資料量的測量。
執行搜尋查詢時,延遲和吞吐量哪個更重要?如何確保我們管理全球基礎設施?
延遲。為了獲得良好的延遲,搜尋查詢應轉發到最近的資料中心。
上傳影片時,延遲和吞吐量哪個更重要?以及如何保證這一點?
吞吐量。為了獲得良好的吞吐量,上傳流應路由到未充分利用的連結。
轉發請求時還有哪些其他考慮因素(延遲和吞吐量除外)?
- 保持快取更新(這意味著請求可能不會轉發到最近的資料中心)
解釋脊柱和葉子
「Spine & Leaf」是資料中心環境中常用的網路拓撲,用於連接多個交換器並有效管理網路流量。它也稱為“主幹-葉”架構或“葉-主幹”拓撲。此設計提供高頻寬、低延遲和可擴展性,使其成為處理大量資料和流量的現代化資料中心的理想選擇。在 Spine & Leaf 網路中,交換器有兩種主要拓撲結構:
- 主幹交換器:主幹交換器是佈置在主幹層中的高效能交換器。這些交換器充當網路的核心,通常與每個葉交換機互連。每個主幹交換器都連接到資料中心中的所有葉子交換器。
- 葉子交換器:葉子交換器連接到伺服器、儲存陣列和其他網路設備等終端設備。每個葉子交換器都連接到資料中心中的每個主幹交換器。這在葉子交換器和主幹交換器之間創建了無阻塞的全網狀連接,確保任何葉子交換機都可以與任何其他葉子交換器以最大吞吐量進行通信。
Spine & Leaf 架構由於能夠滿足現代雲端運算、虛擬化和大數據應用的需求,提供可擴展、高效能和可靠的網路基礎設施,因此在資料中心中越來越受歡迎
什麼是網路壅塞?什麼可能導致它?
當網路上傳輸的資料過多而沒有足夠的容量來處理需求時,就會發生網路擁塞。
這可能會導致延遲增加和資料包遺失。原因可能有多種,例如網路使用率高、檔案傳輸量大、惡意軟體、硬體問題或網路設計問題。
為了防止網路擁塞,監控網路使用情況並實施限製或管理需求的策略非常重要。
您能告訴我有關 UDP 資料包格式的資訊嗎? TCP資料包格式又如何呢?有什麼不同?
什麼是指數退避演算法?它用在哪裡?
使用漢明碼,以下資料字 100111010001101 的代碼字是什麼?
00110011110100011101
給出應用層協定的範例
超文本傳輸協定 (HTTP) - 用於網際網路上的網頁- 簡單郵件傳輸協定 (SMTP) - 電子郵件傳輸
- 電信網路 - (TELNET) - 允許客戶端存取 telnet 伺服器的終端仿真
- 檔案傳輸協定 (FTP) - 促進任意兩台機器之間的檔案傳輸
- 網域名稱系統 (DNS) - 網域翻譯
- 動態主機設定協定 (DHCP) - 為主機指派 IP 位址、子網路遮罩和網關
- 簡單網路管理協定 (SNMP) - 收集網路設備上的數據
給出網路層協定的範例
網際網路通訊協定 (IP) - 協助將資料包從一台機器路由到另一台機器- Internet 控制訊息協定 (ICMP) - 讓人們知道發生了什麼,例如錯誤訊息和偵錯訊息
什麼是HSTS?
HTTP 嚴格傳輸安全性是一個 Web 伺服器指令,它通知使用者代理程式和 Web 瀏覽器如何透過在最開始傳送並返回瀏覽器的回應標頭來處理其連線。這會強制透過 HTTPS 加密進行連接,而忽略透過 HTTP 載入該網域中任何資源的任何腳本呼叫。閱讀更多[此處](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict% 20Transport%20Security %20(HSTS,以及%20返回%20到%20%20瀏覽器。)
網路 - 雜項
什麼是網路?它與萬維網相同嗎?
互聯網是指網路的網絡,在全球範圍內傳輸大量資料。
萬維網是一個運行在互聯網之上的數百萬台伺服器上的應用程序,透過所謂的網絡瀏覽器進行訪問
什麼是 ISP?
ISP(Internet Service Provider)是當地的網路公司供應商。
作業系統
作業系統練習
| 姓名 | 話題 | 目的與說明 | 解決方案 | 評論 |
|---|
| 叉101 | 叉 | 關聯 | 關聯 | |
| 貨叉102 | 叉 | 關聯 | 關聯 | |
作業系統 - 自我評估
什麼是作業系統?
來自《作業系統:三個簡單的部分》一書:
「負責使運行程式變得容易(甚至允許您看似同時運行多個程式),允許程式共享內存,使程式能夠與設備交互,以及其他類似的有趣的東西」。
作業系統-行程
能解釋一下什麼是進程嗎?
進程是一個正在運作的程式。程式是一條或多條指令,程式(或行程)由作業系統執行。
如果您必須為作業系統中的進程設計一個 API,這個 API 會是什麼樣子?
它將支援以下內容:
建立 - 允許建立新進程- 刪除 - 允許刪除/銷毀進程
- 狀態 - 允許檢查進程的狀態,是否正在運作、已停止、正在等待等。
- 停止 - 允許停止正在運行的進程
流程是如何創建的?
作業系統正在讀取程式碼和任何其他相關數據- 程式的程式碼被載入到記憶體中,或更具體地說,載入到進程的位址空間。
- 記憶體分配給程式的堆疊(也稱為運行時堆疊)。此堆疊也由作業系統使用 argv、argc 和 main() 參數等資料進行初始化
- 記憶體分配給程式的堆,這是動態分配資料(例如資料結構鍊錶和哈希表)所需的
- 執行 I/O 初始化任務,就像在基於 Unix/Linux 的系統中一樣,每個進程都有 3 個檔案描述符(輸入、輸出和錯誤)
- 作業系統正在運行程序,從main()開始
是真是假?將程式載入到記憶體中是急切地完成的(一次全部完成)
錯誤的。過去確實如此,但今天的作業系統執行延遲加載,這意味著僅首先加載進程運行所需的相關部分。
進程的不同狀態有哪些?
運行 - 正在執行指令- 準備好了 - 準備運行,但由於不同的原因,它被擱置了
- 阻止 - 它正在等待一些操作完成,例如I/O磁碟請求
一個過程被阻止的原因是什麼?
什麼是間流程通訊(IPC)?
過程間通訊(IPC)是指作業系統提供的機制,該機制允許過程管理共享資料。
什麼是「分享時間」?
即使使用具有一個實體CPU的系統,也可以允許多個使用者處理並執行程式。這是可以隨著時間共享而進行的,在這種情況下,計算資源以某種方式與用戶共享,系統具有多個CPU,但實際上,這僅僅是透過應用多程式設計和多任務來共享的一個CPU。
什麼是「空間共享」?
分享時間的相反。雖然及時共享資源持續了一段時間,然後另一個資源可以使用相同的資源使用,但在共享空間的空間中,該空間由多個實體共享,但在它們之間沒有轉移。
它被一個實體使用,直到該實體決定擺脫它。以儲存為例。在儲存中,檔案是您的,直到您決定刪除它。
哪個組件確定在給定時間時刻運行的過程?
CPU調度程式
作業系統 - 記憶體
什麼是“虛擬記憶體”,什麼用途?
虛擬記憶體將電腦的RAM與硬碟上的臨時空間結合在一起。當RAM低時,虛擬記憶體有助於將資料從RAM移至稱為分頁檔案的空間。將資料移至分頁檔案可以釋放RAM,因此您的電腦可以完成其工作。通常,您的電腦擁有的RAM越多,程式運作越快。 https://www.minitool.com/lib/virtual-memory.html
什麼是需求分頁?
需求分頁是一種記憶體管理技術,僅在透過流程存取時才將頁面載入到實體記憶體中。它透過按需載入頁面來優化記憶體使用量,減少啟動延遲和空間開銷。但是,它首次訪問頁面時會引入一些延遲。總體而言,這是一種用於管理作業系統記憶體資源的經濟高效方法。
什麼是抄寫的?
抄寫(Cow)是一個資源管理概念,其目標是減少不必要的資訊複製。這是一個概念,例如在Posix fork syscall中實現,它創建了呼叫過程的重複過程。想法:
如果在兩個或更多實體之間共享資源(例如,在兩個過程之間共享記憶體段),則不需要為每個實體複製資源,但是每個實體都有在共享資源上讀取操作訪問權限。 (共享段標記為僅閱讀)(想想每個實體都有指向共享資源位置的指針,可以將其刪除以讀取其值)- 如果實體會對共用資源執行寫入操作,則會出現問題,因為所有其他共用的實體也會永久變更資源。 (考慮一個過程,修改堆疊上的某些變量,或在堆上動態分配一些數據,這些更改對共享資源也將適用於所有其他過程,這絕對是不良行為)
- 僅作為解決方案,如果要在共用資源上執行寫入操作,則首先複製此資源,然後套用變更。
什麼是內核,它做什麼?
核心是作業系統的一部分,負責以下任務:
是真是假?核心中的某些程式碼被載入到記憶體的保護區域中,因此應用程式無法覆蓋它們。
真的
什麼是posix?
POSIX(可攜式作業系統介面)是一組標準,可定義類似Unix的作業系統和應用程式之間的介面。
說明什麼是信號量及其在作業系統中的作用。
信號量是一種用於作業系統和同時編程的同步原始詞,以控制對共享資源的存取。這是一種可變數或抽象的資料類型,可作為計數器或訊號傳導機制,用於透過多個流程或執行緒管理對資源存取的存取。
什麼是緩存?什麼是緩衝區?
快取:通常,當過程正在讀取和寫入磁碟以使過程更快地使流程使用時,通常會使用緩存,透過製作可輕鬆存取的不同程式所使用的類似資料。緩衝區:RAM中的保留位置,用於持有臨時目的的資料。
虛擬化
什麼是虛擬化?
虛擬化使用軟體在電腦硬體上建立一個抽象層,該層允許單一電腦的硬體元素 - 處理器,內存,儲存等 - 將分為多個虛擬計算機,通常稱為虛擬機(VMS)。
什麼是管理程序?
Red Hat:「一個虛擬機管理程式是建立和運行虛擬機(VM)的軟體。一個虛擬機,有時稱為虛擬機監視器(VMM),隔離了虛擬機作業系統和資源,並從虛擬機中進行資源,並啟用這些作業系統的建立和管理。
在這裡閱讀更多內容
有哪些類型的管理程序?
託管管理程序和裸金屬管理程序。
裸機管理程式的優點和缺點在託管中的管理程序是什麼?
由於擁有自己的驅動程式並直接存取硬體組件,因此律師管理程式通常會具有更好的效能以及穩定性和可擴展性。
另一方面,對載入(任何)驅動程式可能會有一定的限制,因此託管的管理程式通常會從具有更好的硬體相容性中受益。
有哪種類型的虛擬化?
作業系統虛擬化網路功能虛擬化桌面虛擬化
容器化是一種虛擬化嗎?
是的,這是一個作業系統級虛擬化,其中核心被共享並允許使用多個隔離的用戶空間實例。
虛擬機器的引入如何改變了產業和應用程式的部署方式?
虛擬機的引入使公司可以在同一硬體上部署多個業務應用程序,而每個應用程式都以安全的方式彼此分開,每個應用程式都在自己的單獨作業系統上運行。
虛擬機
在容器時代,我們需要虛擬機器嗎?他們仍然有意義嗎?
是的,即使在容器時代,虛擬機器仍然相關。儘管容器提供了虛擬機器的輕巧替代品,但它們確實有一定的限制。虛擬機器仍然很重要,因為它們提供隔離和安全性,可以運行不同的作業系統,並且對舊應用程式有益。例如,容器限制正在共用主機核心。
普羅米修斯
普羅米修斯是什麼?普羅米修斯的主要功能是什麼?
Prometheus是一種流行的開源系統監視和警報工具包,該工具包最初是在SoundCloud開發的。它旨在收集和儲存時間序列數據,並允許使用稱為promql的功能強大的查詢語言來查詢和分析該數據。普羅米修斯經常用於監視雲端本地應用,微服務和其他現代基礎架構。
Prometheus的一些主要特徵包括:
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
總體而言,Prometheus是一種強大而靈活的工具,用於監視和分析系統和應用程序,並在行業中廣泛用於雲端本地監視和可觀察性。
在哪種情況下,最好不要使用普羅米修斯?
從Prometheus文件中獲取:「如果您需要100%的準確性,例如每次要求計費」。
描述普羅米修斯的建築和組件
普羅米修斯建築由四個主要組成部分組成:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
整體而言,Prometheus架構設計為高度可擴展性和彈性。伺服器和客戶端程式庫可以以分散式方式部署,以支援大規模,高度動態環境的監視
您可以將Prometheus與諸如InfuxDB之類的其他解決方案進行比較嗎?
與其他監視解決方案(例如InfruxDB)相比,Prometheus以其高性能和可擴展性而聞名。它可以處理大量數據,並且可以輕鬆地與監控生態系統中的其他工具整合在一起。另一方面,InfuxDB以其易用性和簡單性而聞名。它具有一個用戶友好的介面,並提供用於收集和查詢資料的易於使用的API。
另一個流行的解決方案Nagios是一個更傳統的監視系統,依賴基於推動的模型來收集數據。 Nagios已經存在了很長時間,並以其穩定性和可靠性而聞名。但是,與Prometheus相比,Nagios缺乏一些更高級的功能,例如多維資料模型和強大的查詢語言。
總體而言,監視解決方案的選擇取決於組織的特定需求和要求。儘管Prometheus是大規模監控和警報的絕佳選擇,但InfluxDB可能更適合需要易於使用和簡單性的較小環境。 Nagios對於將優先於高階功能的穩定性和可靠性確定優先順序的組織仍然是一個可靠的選擇。
什麼是警報?
在Prometheus中,當滿足特定條件或閾值時,警報是觸發的通知。當某些指標越過特定閾值或發生特定事件時,可以將警報配置為觸發。一旦觸發了警報,就可以將其路由到各種管道,例如電子郵件,尋呼機或聊天,以通知相關的團隊或個人以採取適當的措施。警報是任何監視系統的關鍵組成部分,因為它們允許團隊在影響使用者或導致系統停機時間之前主動偵測和回應問題。什麼是實例?什麼是工作?
在Prometheus中,實例是指正在監視的單一目標。例如,單一伺服器或服務。作業是執行相同功能的一組實例,例如一組服務相同應用程式的Web伺服器。工作使您可以一起定義和管理一組目標。
從本質上講,實例是普羅米修斯從中收集指標的個體目標,而作業是可以作為一個小組進行管理的類似實例的集合。
普羅米修斯支持哪些核心指標類型?
Prometheus支援幾種類型的指標,包括: 1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
Prometheus也支援各種功能和操作員,用於匯總和操縱指標,例如總和,最大,最小值和速率。這些功能使其成為監視和警報系統指標的強大工具。
什麼是出口商?它有什麼用?
出口商是第三方系統或應用程式與普羅米修斯之間的橋樑,使Prometheus可以從該系統或應用程式中監視和收集資料。出口商充當伺服器,在特定的網路連接埠上聆聽Prometheus的請求到刮擦指標。它從第三方系統或應用程式收集指標,並將其轉換為普羅米修斯可以理解的格式。然後,出口商透過HTTP端點將這些指標暴露於Prometheus,從而可以收集和分析。
出口商通常用於監視各種類型的基礎架構元件,例如資料庫,Web伺服器和儲存系統。例如,有可用於監視流行資料庫(例如MySQL和PostgreSQL)的導出器,以及Apache和Nginx等Web伺服器。
總體而言,出口商是普羅米修斯生態系統的關鍵組成部分,可以監視廣泛的系統和應用程序,並為平台提供了高度的靈活性和可擴展性。
哪些普羅米修斯最佳實踐?
這是其中的三個: 1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
如何在給定時間段內獲得總請求?
要使用Prometheus在給定的時間內取得總請求,您可以將 * sum *函數與 * rate *函數一起使用。這是一個範例查詢,將為您提供最後一小時內的請求總數: sum(rate(http_requests_total[1h]))
在此查詢中, HTTP_REQUESTS_TOTAL是追蹤HTTP請求總數的度量名稱,速率函數計算了最後一個小時內請求的每秒速率。然後,總和函數添加了所有請求,以在最後一個小時為您提供總數的總數。
您可以透過變更速率函數的持續時間來調整時間範圍。例如,如果您想在最後一天取得請求總數,則可以將功能變更為評分(http_requests_total [1d]) 。
普羅米修斯的HA意味著什麼?
HA代表高可用性。這意味著即使面對失敗或其他問題,該系統也被設計為高度可靠且始終可用。在實踐中,這通常涉及建立多個Prometheus的實例,並確保它們都同步並能夠無縫合作。這可以透過多種技術(例如負載平衡,複製和故障轉移機制)來實現。透過在Prometheus中實施HA,使用者可以確保其監視資料始終可用,並且即使是面對硬體或軟體故障,網路問題或其他可能導致停機時間或資料遺失的問題。
您如何加入兩個指標?
在Prometheus中,可以使用 * join() *函數來實現加入兩個指標。 * join() *函數根據其標籤值結合了兩個或多個時間序列。它需要兩個強制性參數: *on *and *table *。 ON參數指定要加入 * on *的標籤,並且 *表 *參數指定要加入的時間序列。這是如何使用JOIN()函數加入兩個指標的範例:
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
在此範例中, join()函數將基於其服務和實例標籤值的request_count_total和error_count_total時間序列組合。然後, sum_series()函數計算結果時間序列的總和
如何撰寫傳回標籤值的查詢?
要編寫一個傳回Prometheus中標籤值的查詢,您可以使用 * label_values *函數。 * label_values *函數採用兩個參數:標籤的名稱和指標的名稱。例如,如果您的指標稱為http_requests_total ,則帶有名為方法的標籤,並且要傳回方法標籤的所有值,則可以使用下列查詢:
label_values(http_requests_total, method)
這將傳回http_requests_total metric中方法標籤的所有值的清單。然後,您可以在其他查詢中使用此清單或過濾資料。
如何將CPU_USER_SECONDS轉換為百分比的CPU使用?
要將 * cpu_user_seconds *轉換為百分比的CPU使用情況,您需要將其除以總過去的時間和CPU核心的數量,然後乘以100 100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
這裡,是您要查詢的工作的名稱,是您要查詢的時間範圍(例如5M , 1H ),並且是您要查詢的機器上的CPU核心數。
例如,為了在最後5分鐘內將CPU使用百分比以4個CPU核心的電腦上執行的名為My-Job的作業,您可以使用以下查詢:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
去
GO程式語言的某些特徵是什麼?
- 強且靜態的打字 - 變數的類型無法隨著時間的推移而更改,並且必須在編譯時間上定義它們,
- 快速
- 編譯時間
- 內建並發
- 垃圾收集的
- 平台獨立
- 編譯到獨立二進位 - 您需要運行應用程式的任何內容將被編譯成一個二進制。對於運行時的版本管理非常有用。
去也有良好的社區。
var x int = 2和x := 2之間有什麼差別?
結果是相同的,一個值2的變數。
使用var x int = 2我們將變數類型設為整數,而使用x := 2我們讓我們自己弄清楚類型。
是真是假?在Go中,我們可以重新匯總變量,一旦聲明,我們就必須使用它。
錯誤的。我們不能重新匯總變量,但是是的,我們必須使用聲明的變數。
您使用了哪些函式庫?
這應該根據您的用法來回答,但一些示例是:
以下程式碼區塊有什麼問題?如何修復它? func main() {
var x float32 = 13.5
var y int
y = x
}
以下程式碼區塊試圖將整數101轉換為字串,但我們得到了“ E”。這是為什麼?如何修復它? package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
它看起來是設定為101的Unicode值,並將其用於將整數轉換為字串。 y = string(x)要取得“ y = strconv.Itoa(x) ”
以下程式碼有什麼問題? package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
GO中的常數只能使用常數表達式宣告。但是x , y和它們的總和是可變的。
const initializer x + y is not a constant
以下程式碼區塊的輸出將會是什麼? package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
GO的IOTA識別碼用於const聲明中,以簡化增量數字的定義。因為它可以在表達式中使用,所以它提供了超出簡單枚舉的一般性。
x和y在第一個IOTA組中,第二z 。
wiki中的iota頁面
GO中使用什麼_?
它避免了為返回值聲明所有變數。它稱為空白標識符。
回答
以下程式碼區塊的輸出將會是什麼? package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
由於第一個IOTA被宣告為3 ( + 3 ),因此下一個具有值4
以下程式碼區塊的輸出將會是什麼? package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
輸出:2 1 3
關於同步/候補組的Aritcle
Golang軟體包同步
以下程式碼區塊的輸出將會是什麼? package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
輸出:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
在mod1 a是連結中,當我們使用a[i]時,我們將s1值改為。但是在mod2中, append創建了新的切片,而我們只更改a值,而不是s2 。
關於陣列的Aritcle,關於append的部落格文章
以下程式碼區塊的輸出將會是什麼? package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
輸出:3
Golang容器/堆軟體包
蒙戈
MongoDB的優勢是什麼?還是換句話說,為什麼選擇MongoDB而不是NOSQL的其他實作?
MongoDB的優點如下:
SQL和NOSQL有什麼差別?
主要區別在於SQL資料庫是建構的(資料以行和列的表格儲存(例如Excel電子表格表),而NOSQL則是非結構化的,資料儲存可能會根據如何設定NOSQL DB的方式而變更。例如鑰匙值對,面向文檔等。
在哪些情況下,您希望使用nosql/mongo而不是SQL?
異質數據經常變化- 資料一致性和完整性不是當務之急
- 最好如果資料庫需要迅速擴展
什麼是文檔?什麼是集合?
文件是MongoDB中的記錄,該記錄儲存在BSON(Binary JSON)格式中,並且是MongoDB中資料的基本單位。- 一個集合是儲存在MongoDB中一個資料庫中的一組相關文件。
什麼是聚合器?
- 聚合器是MongoDB中的一個框架,該框架對一組資料進行操作以傳回單一計算結果。
什麼更好?嵌入式檔案還是引用?
- 沒有更好的答案,這取決於特定的用例和要求。一些解釋:嵌入式文件提供原子更新,而引用文件則可以更好地歸一化。
您是否在Mongo進行了資料檢索優化?如果沒有,您能考慮優化緩慢資料檢索的方法嗎?
- 在MongoDB中優化資料檢索的一些方法是:索引,正確的模式設計,查詢最佳化和資料庫負載平衡。
查詢
解釋此查詢: db.books.find({"name": /abc/})
解釋此查詢: db.books.find().sort({x:1})
find()和find_one()有什麼差別?
find()傳回與查詢條件相符的所有文件。- find_one()只會傳回一個符合查詢條件的文件(如果找到符合的情況,則為null)。
如何從Mongo DB匯出資料?
SQL
SQL練習
| 姓名 | 話題 | 客觀和指示 | 解決方案 | 評論 |
|---|
| 功能與比較 | 查詢改進 | 鍛鍊 | 解決方案 | |
SQL自我評估
什麼是 SQL?
SQL(結構化查詢語言)是一種關聯式資料庫的標準語言(例如MySQL,Mariadb,...)。
它用於在關係資料庫中讀取,更新,刪除和建立資料。
SQL與NOSQL有何不同
主要區別在於SQL資料庫是建構的(資料以行和列的表格儲存(例如Excel電子表格表),而NOSQL則是非結構化的,資料儲存可能會根據如何設定NOSQL DB的方式而變更。例如鑰匙值對,面向文檔等。
什麼時候最好使用SQL? nosql?
SQL-當資料完整性至關重要時,最好使用。由於其酸合規性,SQL通常在金融領域內的許多企業和地區實施。
NOSQL-如果您需要快速擴展內容,很棒。 NOSQL是考慮到Web應用程式的設計,因此,如果您需要快速將相同的訊息傳播到多個伺服器
此外,由於NOSQL不使用關聯式資料庫所需的列和行結構遵守嚴格的表,因此您可以將不同的資料類型儲存在一起。
實用SQL-基礎知識
對於這些問題,我們將使用下面顯示的客戶和訂單表:
顧客
| customer_id | customer_name | ittem_in_cart | cash_spent_to_date |
|---|
| 100204 | 約翰史密斯 | 0 | 20:00 |
| 100205 | 簡史密斯 | 3 | 40:00 |
| 100206 | 鮑比·弗蘭克(Bobby Frank) | 1 | 100.20 |
訂單
| customer_id | order_id | 物品 | 價格 | date_sold |
|---|
| 100206 | A123 | 橡皮鴨 | 2.20 | 2019-09-18 |
| 100206 | A123 | 泡泡浴 | 8.00 | 2019-09-18 |
| 100206 | Q987 | 80包TP | 90.00 | 2019-09-20 |
| 100205 | Z001 | 貓糧 - 鮪魚魚 | 10:00 | 2019-08-05 |
| 100205 | Z001 | 貓食 - 雞肉 | 10:00 | 2019-08-05 |
| 100205 | Z001 | 貓食 - 牛肉 | 10:00 | 2019-08-05 |
| 100205 | Z001 | 貓食 - 小貓玉米餅 | 10:00 | 2019-08-05 |
| 100204 | X202 | 咖啡 | 20:00 | 2019-04-29 |
如何從該表中選擇所有欄位?
選擇 *
來自客戶;
約翰的購物車中有多少物品?
選擇項目_in_cart
來自客戶
customer_name =「約翰‧史密斯」;
所有客戶花費的所有現金的總和是多少?
選擇sum(cash_spent_to_date)為sum_cash
來自客戶;
他們的購物車中有多少人有物品?
選擇計數(1)為number_of_people_w_items
來自客戶
其中tock_in_cart> 0;
您如何將客戶表加入訂單表?
您將加入他們的唯一鑰匙。在這種情況下,唯一的金鑰是客戶表和訂單表中的customer_id
您將如何顯示哪個客戶訂購哪些項目?
選擇c.customer_name,o.item
來自客戶c
左加入訂單o
在c.customer_id上= o.customer_id;
您將如何顯示誰訂購貓食品以及花費的總金額?
用cat_food as(
選擇customer_id,總和(價格)為total_price
從訂單
諸如“%貓食品%”之類的物品
customer_id的群組
)
選擇customer_name,total_price
來自客戶c
內部加入cat_food f
在c.customer_id = f.customer_id上
c.customer_id in(cat_food中的customer_id);
儘管這是一個簡單的陳述,但「帶有」子句的「真正的查詢」在加入另一個之前需要在表格上運行時確實會發光。用語句很好,因為在執行查詢時可以建立一個偽溫度,而不是建立一個全新的表。
所有購買的貓食品的總和不容易獲得,因此我們使用一個帶有聲明的陳述來創建偽表來檢索每個客戶所花費的價格的總和,然後正常加入表。
您將使用下列哪些查詢? SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
當您使用函數( YEAR(purchased_at) )時,它必須掃描整個資料庫,而不是使用索引,基本上按其自然狀態按原始列來掃描。
開放式堆疊
您熟悉OpenStack的哪些元件/項目?
您能告訴我以下每個服務/專案負責什麼?
Nova-管理虛擬實例- 中子 - 透過提供網路作為服務(NAAS)來管理網絡
- 煤渣 - 塊存儲
- 目光 - 管理虛擬機器和容器的映像(搜索,獲取和註冊)
- Keystone-跨雲端的身份驗證服務
確定用於以下每種服務的服務/項目:- 複製或快照實例
- GUI用於檢視和修改資源
- 區塊儲存
- 管理虛擬實例
一眼 - 圖像服務。也用於複製或快照實例- 地平線 - 用於檢視和修改資源的GUI
- 煤渣 - 塊存儲
- Nova-管理虛擬實例
什麼是租戶/專案?
確定真或錯誤:- OpenStack免費使用
- 負責網路的服務是一眼
- 租戶/項目的目的是在不同項目和OpenStack的用戶之間共享資源
詳細描述如何使用浮動IP提出實例
您接到客戶的電話,說:「我可以ping我的實例,但不能連線(SSH)」。可能是什麼問題?
哪些類型的網路OpenStack支援?
您如何調試OpenStack儲存問題? (工具,日誌,...)
您如何調試OpenStack計算問題? (工具,日誌,...)
OpenStack部署和Tripleo
您過去是否部署過OpenStack?如果是,您能描述您是如何做到的嗎?
您熟悉Tripleo嗎?它與Devstack或Packstack有何不同?
您可以在這裡閱讀有關Tripleo的信息
OpenStack Compute
能詳細描述Nova嗎?
用於提供和管理虛擬實例- 它支援不同級別的多租戶 - 記錄,最終用戶控制,審計等。
- 高度可擴展
- 可以使用內部系統或LDAP進行身份驗證
- 支援多種類型的區塊存儲
- 試圖成為硬體和管理程序不可知論者
您對Nova架構和元件有什麼了解?
NOVA -API-服務元資料並計算API的伺服器- 不同的NOVA組件透過使用隊列(通常是兔子)和資料庫進行通信
- NOVA-SCHEDULER檢查了建立實例的請求,該請求確定將在何處建立實例並執行實例
- NOVA-COMPUTE是負責與管理程式進行交流以建立實例並管理其生命週期的元件
OpenStack網路(中子)
詳細說明中子
OpenStack和獨立專案的核心組成部分之一- 中子專注於交付網路作為服務
- 使用中子,用戶可以在雲端中設定網路並配置和管理各種網路服務
- 中子與:
- Nova -Nova與Neva通訊將NIC插入網絡
- 地平線 - 支援儀表板中的網路實體,還提供拓撲視圖,其中包括網路詳細信息
解釋以下每個組件:- 中子DHCP代理
- 中子L3代理
- 中子計算機
- 中子 - * - 敏捷
- 中子伺服器
中子L3代理-L3/NAT轉送(例如,為VM提供外部網路存取)- 中子DHCP代理-DHCP服務
- 中子計算機-L3交通計量
- 中子 - * - agtent-管理每個計算上的本地vswitch配置(基於選擇的插件)
- 中子伺服器 - 如果需要,請公開網路API並將請求傳遞給其他插件
解釋這些網路類型:
管理網路 - 用於OpenStack元件之間的內部通訊。該網路中的任何IP位址僅在資料列中訪問- 來賓網路 - 用於實例/VM之間的通信
- API網路 - 用於服務API通訊。該網路中的任何IP位址均可公開存取
- 外部網路 - 用於公共通訊。 Internet上的任何人都可以存取該網路中的任何IP位址
您應在哪個順序中刪除以下實體:
原因有很多。例如:如果分配了活動端口,則無法刪除路由器。
什麼是提供者網路?
L2和L3存在哪些元件和服務?
什麼是ML2外掛?解釋其架構
什麼是L2代理?它是如何運作的,什麼是負責?
什麼是L3代理?它是如何運作的,什麼是負責?
解釋元數據代理負責
哪些網路實體中子支援?
您如何調試OpenStack網路問題? (工具,日誌,...)
OpenStack-一眼
詳細說明
一眼是OpenStack Image服務- 它處理與實例磁碟和映像有關的請求
- 一眼也用於建立快速實例備份的快照
- 用戶可以使用眼神創建新圖像或上傳現有圖像
描述Glance架構
GLANCE -API-負責處理影像API調用,例如檢索和儲存。它由兩個API組成:1。- Glance -Registry-負責處理圖像元資料請求(例如大小,類型等)。該組件是私人的,這意味著它不公開可用
- 元資料定義服務 - 自訂元資料的API
- 資料庫 - 用於儲存影像元數據
- 影像儲存庫 - 用於儲存影像。這可以是檔案系統,Swift物件存儲,HTTP等。
OpenStack- Swift
詳細解釋Swift
Swift是對象商店服務,是一家高度可用,分佈且一致的商店,旨在儲存大量數據- Swift將資料寫入多個磁碟時,將資料分發到多個伺服器
- 可以選擇新增其他伺服器以擴展叢集。在迅速保持資訊和資料複製的完整性的同時。
預設情況下,用戶可以儲存100GB的物件嗎?
預設不是。物件儲存API將最大值限制為每個物件的5GB,但可以進行調整。
關於Swift說明以下內容:
容器 - 定義物件的命名空間。- 帳戶 - 定義容器的名稱空間
- 物件 - 資料內容(例如圖像,文檔,...)
是真是假?在同一容器中可以有兩個具有相同名稱的對象,但在兩個不同的容器中卻沒有
錯誤的。如果兩個物件在不同的容器中,則可以具有相同的名稱。
OpenStack -Cinder
詳細解釋煤渣
Cinder是OpenStack Block儲存服務- 它基本上提供了可以與其他服務(例如Nova)一起消費的儲存資源
- Cinder支援的最常用的儲存實作之一是LVM
- 從用戶角度來看,這是透明的,這意味著用戶不知道幕後,存儲在哪裡或使用了哪種類型的存儲
描述煤渣的組件
Cinder -API-收到API要求- Cinder -volume-管理連接的區塊設備
- 煤渣安排 - 負責儲存量
OpenStack -Keystone
Can you describe the following concepts in regards to Keystone?
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
使用:
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- 聚丙烯醯胺
- 記憶體快取
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
木偶
What is Puppet?它是如何運作的?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
鬆緊帶
什麼是彈性堆疊?
The Elastic Stack consists of:
- 彈性搜尋
- 木花
- 日誌儲存
- 節拍
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
來自官方文件:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
來自部落格:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
什麼是基巴納?
來自官方文件:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
彈性搜尋
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
來自官方文件:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
什麼是索引?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
來自官方文件:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red.這是什麼意思? What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
是真是假? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
錯誤的。來自官方文件:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot".這是什麼意思?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API?你會用它做什麼?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
查詢DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
來自官方文件:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
日誌儲存
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
木花
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits".這是什麼意思?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
文件節拍
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
在這裡閱讀
是真是假? a single harvester harvest multiple files, according to the limits set in filebeat.yml
錯誤的。 One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
彈性堆疊
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
分散式
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
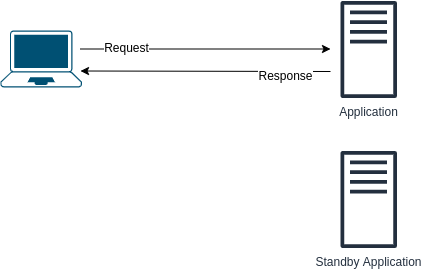
What are the problems with the following design? How to improve it?
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
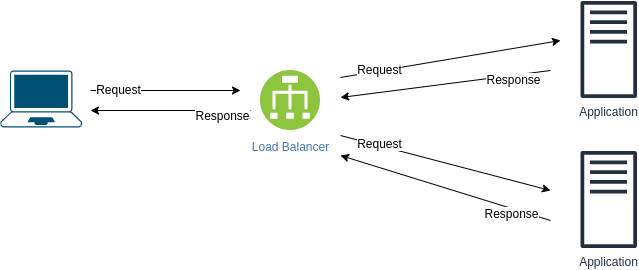
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the architectures where the request can get to one of many noout and the em many nounage from wry many noage, , 記憶, ...)。
Explain the Sidecar Pattern (Or sidecar proxy)
雜項
| 姓名 | 話題 | Objective & Instructions | 解決方案 | 評論 |
|---|
| Highly Available "Hello World" | 鍛鍊 | 解決方案 | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
應用程式介面
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
是真是假? API Definition is the same as API Specification
錯誤的。 From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
優點:
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
什麼是自動化? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
什麼是元數據?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Which one would you use?為什麼?
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
是真是假? Any valid JSON file is also a valid YAML file
真的。 Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
韌體
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
卡桑德拉
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP協定
什麼是 HTTP?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP請求
- HTTP response
是真是假? HTTP is stateful
錯誤的。 It doesn't maintain state for incoming request.
How HTTP request looks like?
它包括:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
什麼是 HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server.這是什麼意思?
The server didn't receive a response from another server it communicates with in a timely manner.
什麼是代理?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
負載平衡器
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
循環賽- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- 來源IP哈希
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
什麼是應用程式負載平衡器?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
缺點:
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
餅乾. There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- 循環賽
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- 來源IP哈希
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
許可證
Are you familiar with "Creative Commons"?你對此了解多少?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
隨機的
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache.來源
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem?今天是否相關?
https://idiallo.com/blog/c10k-2016
貯存
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
優點:
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
優點:
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
蘋果電腦作業系統:
Explain Dark Data
Explain MBR
Questions you CAN ask
作為候選人,您可以在面試期間或面試後向面試官提出的問題清單。這些只是建議,請謹慎使用。並非每個面試官都能回答這些問題(或樂意回答),這可能是您在這樣的地方工作的危險信號警告,但這實際上取決於您。
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
測試
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
什麼是 A/B 測試?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
解釋以下類型的測試:- 負載測試
- 壓力測試
- Capacity Testing
- 容量測試
- 耐力測試
正規表示式
給定一個文字文件,執行以下練習
提煉
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
代替
Replace tabs with four spaces
Replace 'red' with 'green'
系統設計
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure.什麼是CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- 程式碼重複
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. 可擴展性
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling?為了執行水平縮放通常需要什麼?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
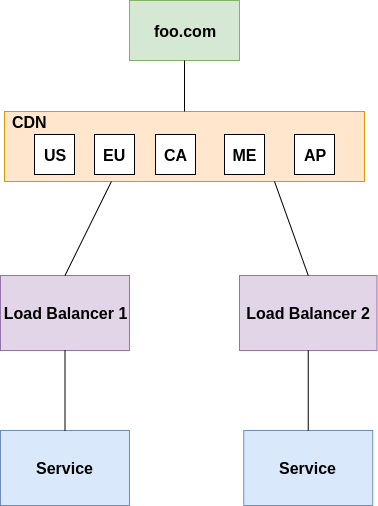
What is the problem with the following architecture and how would you fix it?
生產者或消費者的負載可能很高,這將導致他們掛起或崩潰。
消費者不是在「推播模式」下工作,而是只有在準備好處理任務時才能拉取任務。它可以透過使用 Kafka、Kinesis 等串流平台來解決。

Users report that there is huge spike in process time when adding little bit more data to process as an input.可能是什麼問題?

How would you scale the architecture from the previous question to hundreds of users?
快取
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
看看這裡
Which cache replacement policies are you familiar with?
You can find a list here
解釋以下快取策略:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
遷移
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

硬體
什麼是CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
什麼是 GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
安全措施:
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
適應性:
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Networking Equipment :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
什麼是 DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
外部的- 機器檢查
- 輸入/輸出
- 程式
- 重新啟動
- Supervisor call (SVC)
大數據
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
什麼是資料倉儲?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
阿帕契Hadoop
Explain what is Hadoop
Apache Hadoop - 維基百科
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS架構
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
頭孢
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers.是真是假? Ceph favor consistency and correctness over performances
真的Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- 一致性強
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
監視器- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- 主管
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server?它是如何運作的?
包裝機
What is Packer?它有什麼用?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
發布
Explain Semantic Versioning
該頁面完美地解釋了這一點:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
證書
如果您正在尋找準備某項考試的方法,那麼本部分就是適合您的。在這裡您將找到一個證書列表,每個證書都引用一個單獨的文件,其中包含有助於您準備考試的重點問題。祝你好運 :)
AWS
- 雲端從業人員(最新更新:2020)
- 解決方案架構師助理(最新更新:2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
天藍色
庫伯內斯
- 認證 Kubernetes 管理員 (CKA)(最新更新:2022)
其他 DevOps 和 SRE 項目




製作人員
感謝我們所有出色的貢獻者,他們讓每個人都能輕鬆學習新事物:)
標誌學分可在此處找到
執照


