Hibernate SpringBoot
1.0.0
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
Hibernate 和 Spring Boot 範例
描述:此應用程式是如何在 UTC 時區儲存日期、時間和時間戳記的範例。第二個設定useLegacyDatetimeCode僅適用於 MySQL。否則,僅設定hibernate.jdbc.time_zone 。
要點:
spring.jpa.properties.hibernate.jdbc.time_zone=UTCspring.datasource.url=jdbc:mysql://localhost:3306/screenshotdb?useLegacyDatetimeCode=false描述:透過 Log4J 2 記錄器設定查看準備好的語句綁定/擷取的參數。
要點:
pom.xml中,排除 Spring Boot 的預設日誌記錄pom.xml中,新增 Log4j 2 依賴項log4j2.xml加入, <Logger name="org.hibernate.type.descriptor.sql" level="trace"/>輸出範例: 
說明:透過DataSource-Proxy查看查詢詳細資訊(查詢類型、綁定參數、批次大小、執行時間等)
要點:
pom.xml中加入datasource-proxy依賴項DataSource beanProxyFactory和MethodInterceptor的實作包裝DataSource bean輸出範例: 
saveAll(Iterable<S> entities)批次插入描述:透過 MySQL 中的SimpleJpaRepository#saveAll(Iterable<S> entities)方法批次插入
要點:
application.properties中設定spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties設定spring.jpa.properties.hibernate.generate_statistics (只是為了檢查批次是否正常運作)application.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 進行最佳化)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_inserts=true以透過排序插入來最佳化批次IDENTITY將導致插入批次被停用@Version屬性以避免在批次之前觸發額外的SELECT語句(還可以防止在多請求事務中遺失更新)。 Extra- SELECT語句是使用merge()而不是persist()的效果;在幕後, saveAll()使用save() ,在非新實體(具有 ID 的實體)的情況下,它將呼叫merge() ,這指示 Hibernate 觸發SELECT語句以確保具有相同識別碼的資料庫saveAll()的插入量,以免「淹沒」持久性上下文;通常EntityManager應該不時地刷新和清除,但是在saveAll()執行期間你根本不能這樣做,所以如果在saveAll()中有一個包含大量數據的列表,所有這些數據都將命中 Persistence上下文(一級緩存)並將保留在記憶體中直到刷新時間;使用相對少量的資料應該沒問題(在本例中,每批 30 個實體在單獨的交易和持久上下文中運行)saveAll()方法傳回一個包含持久化實體的List<S> ;每個持久化實體都被加入到此列表中;如果您不需要這個List ,那麼它就被創建了spring.jpa.properties.hibernate.cache.use_second_level_cache=false停用二級緩存說明:此應用程式是透過 MySQL 中的EntityManager進行批次插入的範例。這樣您就可以輕鬆控制目前交易內持久性上下文(一級快取)的flush()和clear()週期。這是透過 Spring Boot saveAll(Iterable<S> entities)不可能實現的,因為此方法對每個交易執行一次刷新。另一個優點是您可以呼叫persist()而不是merge() - 這是由 SpringBoot saveAll(Iterable<S> entities)和save(S entity)在幕後使用的。
如果您想對每個事務執行一批(建議),請檢查此範例。
要點:
application.properties中設定spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties設定spring.jpa.properties.hibernate.generate_statistics (只是為了檢查批次是否正常運作)application.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 進行最佳化)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_inserts=true以透過排序插入來最佳化批次IDENTITY將導致插入批次被停用spring.jpa.properties.hibernate.cache.use_second_level_cache=false停用二級緩存輸出範例: 
描述:透過 MySQL 中的JpaContext/EntityManager批量插入。
要點:
application.properties中設定spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties設定spring.jpa.properties.hibernate.generate_statistics (只是為了檢查批次是否正常運作)application.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 進行最佳化)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_inserts=true以透過排序插入來最佳化批次IDENTITY將導致插入批次被停用EntityManager是透過JpaContext#getEntityManagerByManagedType(Class<?> entity)取得每個實體類型的spring.jpa.properties.hibernate.cache.use_second_level_cache=false停用二級緩存輸出範例: 
說明:透過 MySQL 中的 Hibernate 會話級批次(Hibernate 5.2 或更高版本)進行批次插入。
要點:
application.properties設定spring.jpa.properties.hibernate.generate_statistics (只是為了檢查批次是否正常運作)application.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 進行最佳化)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_inserts=true以透過排序插入來最佳化批次IDENTITY將導致插入批次被停用Session是透過EntityManager#unwrap(Session.class)解包取得的Session#setJdbcBatchSize(Integer size)設定並透過Session#getJdbcBatchSize()取得spring.jpa.properties.hibernate.cache.use_second_level_cache=false停用二級緩存輸出範例: 
findById() 、 JPA EntityManager和 Hibernate Session直接取得描述:透過 Spring Data、 EntityManager和 Hibernate Session範例直接取得。
要點:
findById()EntityManager直接取得使用find()Session直接取得使用get()注意:您可能還想閱讀食譜“如何透過 Spring 投影使用虛擬屬性豐富 DTO”
描述:透過 Spring Data Projections (DTO) 從資料庫中僅取得所需的資料。
要點:
List<projection>正確查詢LIMIT )注意:使用投影並不限於使用 Spring 資料儲存庫基礎架構中內建的查詢建構器機制。我們也可以透過 JPQL 或本機查詢來取得投影。例如,在此應用程式中我們使用 JPQL。
輸出範例(選擇前 2 行;僅選擇“姓名”和“年齡”): 
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
描述:預設情況下,實體的屬性會立即載入(一次全部載入)。但是,我們也可以延遲載入它們。這對於儲存大量資料的列類型非常有用: CLOB 、 BLOB 、 VARBINARY等或應按需載入的詳細資訊。在此應用程式中,我們有一個名為Author實體。它的屬性是: id 、 name 、 genre 、 avatar和age 。並且,我們想要延遲載入avatar 。因此, avatar應該按需加載。
要點:
pom.xml中,啟動 Hibernate字節碼增強(例如使用 Maven字節碼增強插件)@Basic(fetch = FetchType.LAZY)註解應該延遲載入的屬性application.properties中,停用在視圖中開啟會話還要檢查:
- 延遲載入屬性的預設值
- 屬性延遲載入和 Jackson 序列化
描述:當子實體可以透過對其父實體的引用( @ManyToOne或@OneToOne關聯)進行持久化時,Hibernate 代理程式會很有用。在這種情況下,從資料庫取得父實體(執行SELECT語句)會降低效能並且是毫無意義的操作,因為 Hibernate 可以為未初始化的代理程式設定基礎外鍵值。
要點:
EntityManager#getReference()JpaRepository#getOne() -> 在本例中使用load()Author和Book ,參與單向@ManyToOne關聯( Author是父端)SELECT ),我們建立一本新書,我們將代理人設定為這本書的作者,然後儲存這本書(這將觸發book表中的INSERT )輸出範例:
INSERT ,且未觸發SELECT描述: N+1 是延遲取得的問題(但是,eager 也不例外)。該應用程式重現了 N+1 行為。
要點:
@OneToMany關聯中定義兩個實體: Author和BookBook ,因此沒有Author (結果為 1 個查詢)Book集合,並為每個條目取得對應的Author (結果 N 個查詢)Author ,因此沒有Book (導致 1 個查詢)Author集合,並為每個條目取得相應的Book (結果 N 個查詢)輸出範例: 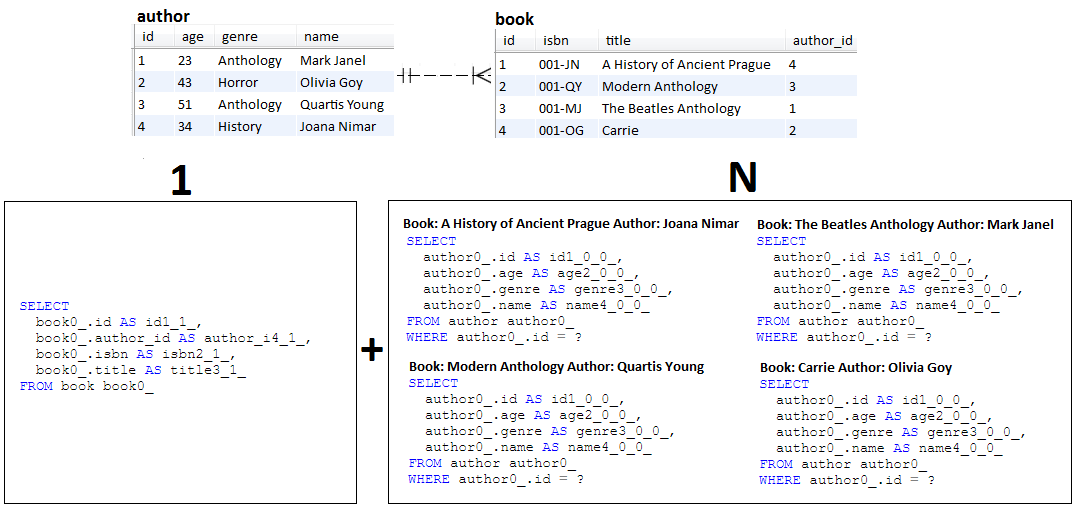
SELECT DISTINCT HINT_PASS_DISTINCT_THROUGH提示描述:從 Hibernate 5.2.2 開始,我們可以透過HINT_PASS_DISTINCT_THROUGH提示優化SELECT DISTINCT類型的 JPQL (HQL) 查詢實體。請記住,此提示僅對 JPQL (HQL) JOIN FETCH 查詢有用。對於標量查詢(例如List<Integer> )、DTO 或 HHH-13280 沒有用。在這種情況下,需要將DISTINCT JPQL 關鍵字傳遞給基礎 SQL 查詢。這將指示資料庫從結果集中刪除重複項。
要點:
@QueryHints(value = @QueryHint(name = HINT_PASS_DISTINCT_THROUGH, value = "false"))輸出範例: 
注意: Hibernate髒檢查機制負責辨識刷新時的實體修改並代表我們觸發對應的UPDATE語句。
說明:在 Hibernate 版本 5 之前,髒檢查機制會依賴 Java Reflection API 來檢查每個託管實體的每個屬性。從 Hibernate 版本 5 開始,髒檢查機制可以依賴於髒追蹤機制(實體追蹤其自身屬性變更的能力),這需要應用程式中存在 Hibernate字節碼增強功能。髒追蹤機制可以維持更好的效能,尤其是當實體數量相對較多時。
對於髒跟踪,在字節碼增強過程中,Hibernate 透過添加跟踪器$$_hibernate_tracker來檢測實體類字節碼。在刷新時,Hibernate 將使用此追蹤器來發現實體變更(每個實體追蹤器將報告變更)。這比檢查每個託管實體的每個屬性要好。
通常(預設),檢測在建置時進行,但也可以配置為在運行時或部署時進行。最好在建置時進行,以避免運行時的開銷。
新增字節碼增強和啟用髒追蹤可以透過 Maven 或 Gradle 新增的插件來完成(也可以使用 Ant)。我們使用 Maven,因此我們將其添加到pom.xml中。
要點:
pom.xml檔中加入字節碼增強插件輸出範例: 
字節碼增強效果可以在此處的Author.class上看到。請注意如何使用$$_hibernate_tracker來偵測字節碼。
Optional描述:此應用程式是一個範例,說明如何在實體和查詢中正確使用 Java 8 Optional 。
要點:
Optional的Spring Data內建查詢方法(例如findById() )Optional查詢Optionaldata-mysql.sql@OneToMany雙向關聯的最佳方法描述:此應用程式從效能角度證明如何正確實現雙向@OneToMany關聯的概念。
要點:
mappedByorphanRemoval來刪除沒有引用的子級@NaturalId ))和/或資料庫產生的標識符並正確覆蓋(在子端) equals()和hashCode()方法,如下所示toString() ,那麼注意只涉及從資料庫載入實體時取得的基本屬性注意:注意刪除操作,尤其是刪除子實體。 CascadeType.REMOVE和orphanRemoval=true可能會產生太多查詢。在這種情況下,依靠批量操作在大多數情況下是刪除的最佳方法。
說明:此應用程式是如何透過JpaRepository 、 EntityManager和Session編寫查詢的範例。
要點:
JpaRepository使用@Query或 Spring Data 查詢創建EntityManager和Session使用createQuery()方法AUTO產生器類型描述:在 MySQL 和 Hibernate 5 中, GenerationType.AUTO產生器類型將導致使用TABLE產生器。這會顯著增加效能損失。可以透過使用GenerationType.IDENTITY或本機產生器來將此行為轉換為IDENTITY產生器。
要點:
GenerationType.IDENTITY而不是GenerationType.AUTO輸出範例: 
描述:此應用程式是呼叫實體的save()是多餘的(不必要)的範例。
要點:
UPDATE語句,而不需要明確地呼叫save()方法save() )不會影響觸發查詢的數量,但它意味著底層 Hibernate 進程的效能損失| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
BIG ) SERIAL描述:在 PostgreSQL 中,使用GenerationType.IDENTITY將停用插入批次。 (BIG)SERIAL的行為「幾乎」就像 MySQL 的AUTO_INCREMENT 。在此應用程式中,我們使用允許插入批次的GenerationType.SEQUENCE ,並透過hi/lo優化演算法對其進行最佳化。
要點:
GenerationType.SEQUENCE而不是GenerationType.IDENTITYhi/lo演算法在資料庫往返中取得hi值( hi值對於在記憶體中產生特定/給定數量的識別碼很有用;在您還沒有耗盡所有記憶體中識別碼之前,不需要去取另一個嗨)pooled和pooled-lo標識符產生器(這些是hi/lo的最佳化,允許外部服務使用資料庫而不會導致重複鍵錯誤)spring.datasource.hikari.data-source-properties.reWriteBatchedInserts=true優化批次輸出範例: 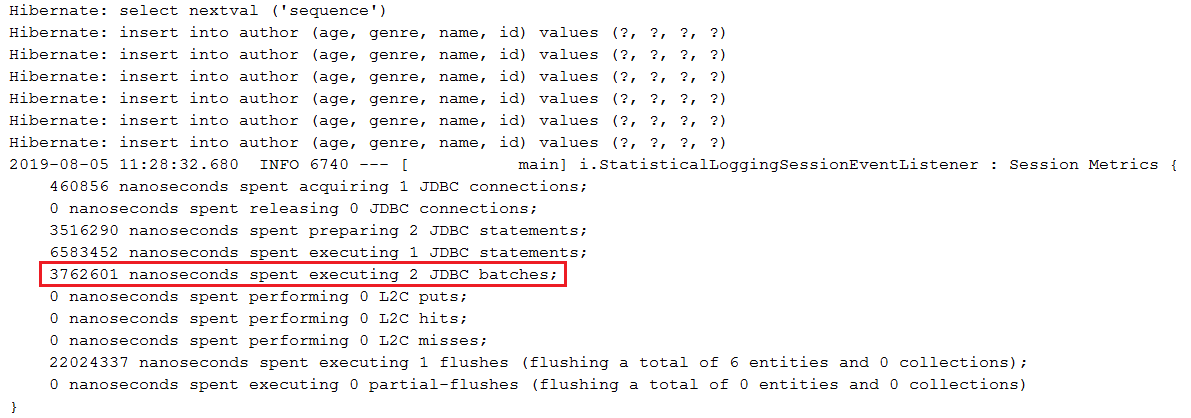
SINGLE_TABLE描述:此應用程式是使用 JPA 單表繼承策略 ( SINGLE_TABLE ) 的範例。
要點:
@Inheritance(strategy=InheritanceType.SINGLE_TABLE) )@NotNull和 MySQL 觸發器確保子類別屬性不可為空TINYINT類型來優化輸出範例(下面是從 3 個實體獲得的單一表格): 
描述:此應用程式是對「幕後」觸發的 SQL 語句進行計數和斷言的範例。對 SQL 語句進行計數非常有用,以確保您的程式碼不會產生您可能認為的更多 SQL 語句(例如,可以透過斷言預期語句的數量輕鬆偵測到 N+1)。
要點:
pom.xml中,新增 DataSource-Proxy 函式庫和 Vlad Mihalcea 的 db-util 函式庫的依賴項countQuery()建立ProxyDataSourceBuilderSQLStatementCountValidator.reset()重設計數器assertInsert/Update/Delete/Select/Count(long expectedNumberOfSql)斷言INSERT 、 UPDATE 、 DELETE和SELECT輸出範例(當預期SQL數量與實際不相等時拋出異常): 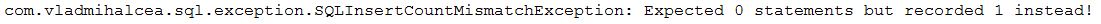
說明:此應用程式是設定 JPA 回呼( Pre/PostPersist 、 Pre/PostUpdate 、 Pre/PostRemove和PostLoad )的範例。
要點:
void且不帶任何參數輸出範例: 
@MapsId在@OneToOne關係中共享標識符說明:最好依賴單向@OneToOne和@MapsId ,而不是常規的單向/雙向@OneToOne 。該應用程式是一個概念驗證。
要點:
@MapsId@JoinColumn自訂主鍵列的名稱@OneToOne關聯, @MapsId將與父表共享主鍵( id屬性既充當主鍵又充當外鍵)筆記:
@MapsId也可用於@ManyToOneSqlResultSetMapping和EntityManager取得 DTO描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依賴SqlResultSetMapping和EntityManager 。
要點:
SqlResultSetMapping和EntityManagerSqlResultSetMapping和NamedNativeQuery取得 DTO注意:如果您想要依賴{EntityName}.{RepositoryMethodName}命名約定來簡單地在儲存庫中建立與本機命名查詢同名的介面方法,請跳過此應用程式並選取此應用程式。
描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依賴SqlResultSetMapping 、 NamedNativeQuery 。
要點:
SqlResultSetMapping 、 NamedNativeQueryjavax.persistence.Tuple和本機 SQL 取得 DTO描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依賴javax.persistence.Tuple和本機 SQL。
要點:
java.persistence.Tuple並將查詢標記為nativeQuery = truejavax.persistence.Tuple和 JPQL 取得 DTO描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依賴javax.persistence.Tuple和 JPQL。
要點:
java.persistence.Tuple描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依賴建構函式表達式和 JPQL。
要點:
SELECT new com.bookstore.dto.AuthorDto(a.name, a.age) FROM Author a參見:
如何透過建構函式和 Spring Data 查詢生成器機制來取得 DTO
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
ResultTransformer和 Native SQL 取得 DTO描述:取得超出需求的資料很容易導致效能下降。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依賴 Hibernate、 ResultTransformer和本機 SQL。
要點:
AliasToBeanConstructorResultTransformer進行 DTO,無需設定器,但具有建構函數Transformers.aliasToBean()進行帶有 setter 的 DTOEntityManager.createNativeQuery()和unwrap(org.hibernate.query.NativeQuery.class)ResultTransformer已被棄用,但在替代品可用之前(可能在 Hibernate 6.0 中),可以使用它(進一步閱讀)ResultTransformer和 JPQL 取得 DTO描述:取得超出需求的資料很容易導致效能下降。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依賴 Hibernate、 ResultTransformer和 JPQL。
要點:
AliasToBeanConstructorResultTransformer進行 DTO,不帶 setter,有建構函數Transformers.aliasToBean()進行帶有 setter 的 DTOEntityManager.createQuery()和unwrap(org.hibernate.query.Query.class)ResultTransformer已被棄用,但在替代品可用之前(在 Hibernate 6.0 中),可以使用它(進一步閱讀)描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依賴 Blaze-Persistence 實體視圖。
要點:
pom.xml中新增特定於 Blaze-Persistence 的依賴項CriteriaBuilderFactory和EntityViewManager配置 Blaze-PersistenceEntityViewRepository編寫以 Spring 為中心的儲存庫findAll() 、 findOne()等@ElementCollection (不含@OrderColumn )如何運作描述:此應用程式揭示了使用@ElementCollection可能帶來的效能損失。在這種情況下,沒有@OrderColumn 。正如您在下一項 (34) 中看到的,添加@OrderColumn可以減輕一些效能損失。
要點:
@ElementCollection沒有主鍵@ElementCollection映射到單獨的表中@ElementCollection ;插入/刪除將導致 Hibernate 刪除所有現有的表行,在記憶體中處理集合,並重新插入剩餘的表行以從記憶體中鏡像集合輸出範例: 
@ElementCollection和@OrderColumn如何運作描述:此應用程式揭示了使用@ElementCollection的效能損失。在本例中,使用@OrderColumn 。但是,正如您在此應用程式中所看到的(與第 33 項相比),當操作發生在集合尾部附近時(例如,在集合末尾添加/刪除),透過添加@OrderColumn可以減輕一些效能損失。主要是,位於新增/刪除條目之前的所有元素都保持不變,因此如果我們影響靠近集合尾部的行,則可以忽略效能損失。
要點:
@ElementCollection沒有主鍵@ElementCollection映射到單獨的表中@ElementCollection和@OrderColumn輸出範例: 
注意:在閱讀本文之前,請嘗試查看 Hibernate5Module 是否不是您正在尋找的內容。
描述: SpringBoot 中預設啟動 Open-Session in View 反模式。現在,想像一下兩個實體Author和Book (一個作者關聯了更多書籍)之間的惰性關聯(例如, @OneToMany )。接下來,REST 控制器端點取得沒有關聯Book Author 。但是,視圖(更準確地說,傑克遜)也強制延遲加載相關Book 。由於 OSIV 將提供已開啟的Session ,因此代理初始化會成功進行。避免這種效能損失的解決方案首先是停用 OSIV。此外,明確初始化未取得的惰性關聯。這樣,View就不會強制延遲載入。
要點:
application.properties中新增此設定來停用 OSIV: spring.jpa.open-in-view=falseAuthor實體並使用(預設)值(例如null )明確初始化其關聯的Book@JsonInclude(Include.NON_EMPTY)以避免呈現null或結果 JSON 中被視為空的內容注意:如果啟用了 OSIV,開發人員仍然可以手動初始化未取得的惰性關聯,只要他在交易之外執行此操作即可避免刷新。但是,為什麼這有效呢?既然Session是開啟的,為什麼手動初始化託管實體的關聯不會觸發刷新?答案可以在OpenSessionInViewFilter的文件中找到,其中指定:此篩選器預設不會刷新 Hibernate Session ,刷新模式設定為FlushMode.NEVER 。它假設與關心刷新的服務層事務結合使用:活動事務管理器將在讀寫事務期間臨時將刷新模式更改為FlushMode.AUTO ,最後將刷新模式重置為FlushMode.NEVER每筆交易的。如果您打算在沒有交易的情況下使用此篩選器,請考慮變更預設刷新模式(透過「flushMode」屬性)。

描述:此應用程式是使用 Spring Projections (DTO) 和透過 JPQL 和本機 SQL(適用於 MySQL)編寫的內部聯結的概念證明。
要點:
@OneToMany關聯中的Author和Book )resources/data-mysql.sql )AuthorNameBookTitle.java )
描述:此應用程式是使用 Spring Projections (DTO) 和透過 JPQL 和本機 SQL(適用於 MySQL)編寫的左側連接的概念證明。
要點:
@OneToMany關聯中的Author和Book )resources/data-mysql.sql )AuthorNameBookTitle.java )
描述:此應用程式是使用 Spring Projections (DTO) 和透過 JPQL 和本機 SQL(適用於 MySQL)編寫的右連接的概念證明。
要點:
@OneToMany關聯中的Author和Book )resources/data-mysql.sql )AuthorNameBookTitle.java )
描述:此應用程式是使用 Spring Projections (DTO) 和透過 JPQL 和本機 SQL(針對 PostgreSQL)編寫的包含式完整聯結的概念證明。
要點:
@OneToMany關聯中的Author和Book )resources/data-mysql.sql )AuthorNameBookTitle.java )| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|

描述:此應用程式是使用 Spring Projections (DTO) 和透過 JPQL 和本機 SQL(適用於 MySQL)編寫的獨佔左聯接的概念證明。
要點:
@OneToMany關聯中的Author和Book )resources/data-mysql.sql )AuthorNameBookTitle.java )
描述:此應用程式是使用 Spring Projections (DTO) 和透過 JPQL 和本機 SQL(適用於 MySQL)編寫的獨佔右連接的概念證明。
要點:
@OneToMany關聯中的Author和Book )resources/data-mysql.sql )AuthorNameBookTitle.java )
描述:此應用程式是使用 Spring Projections (DTO) 和透過 JPQL 和本機 SQL(針對 PostgreSQL)編寫的獨佔完整聯接的概念證明。
要點:
@OneToMany關聯中的Author和Book )resources/data-mysql.sql )AuthorNameBookTitle.java )描述:此應用程式是使用 Spring 提交後掛鉤及其如何影響持久層效能的概念證明。
要點:
描述:此應用程式是使用 Spring Projections (DTO) 和連接不相關實體的概念證明。 Hibernate 5.1 引入了對不相關實體的明確連接,其語法和行為類似於 SQL JOIN語句。
要點:
Author和Book無關的實體)resources/data-mysql.sql )BookstoreDto )@EqualsAndHashCode和@Data以及如何重寫equals()和hashCode()描述:實體應該實作equals()和hashCode()如下所示。主要想法是 Hibernate 要求實體在其所有狀態轉換(瞬態、附加、分離和刪除)中等於自身。使用 Lombok @EqualsAndHashCode (或@Data )將不遵守此要求。
要點:
避免這些方法
@EqualsAndHashCode的 Lombok 預設行為(實體: LombokDefaultBook ,測試: LombokDefaultEqualsAndHashCodeTest )@EqualsAndHashCode (實體: LombokIdBook ,測試: LombokEqualsAndHashCodeWithIdOnlyTest )equals()和hashCode() (實體: DefaultBook ,測試: DefaultEqualsAndHashCodeTest )equals()和hashCode() (實體: IdBook ,測試: IdEqualsAndHashCodeTest )更喜歡這些方法
BusinessKeyBook ,測試: BusinessKeyEqualsAndHashCodeTest )@NaturalId (實體: NaturalIdBook ,測試: NaturalIdEqualsAndHashCodeTest )IdManBook ,測試: IdManEqualsAndHashCodeTest )IdGenBook ,測試: IdGenEqualsAndHashCodeTest ) 
JOIN FETCH避免LazyInitializationException參見:
描述:通常,當我們收到LazyInitializationException時,我們傾向於將關聯獲取類型從LAZY修改為EAGER 。那是非常糟糕的!這是代碼味道。避免此異常的最佳方法是依賴JOIN FETCH (如果您打算修改所取得的實體)或JOIN + DTO(如果僅讀取所取得的資料)。 JOIN FETCH允許使用單一SELECT初始化關聯及其父物件。這對於獲取關聯集合特別有用。
此應用程式是一個JOIN FETCH範例,用於避免LazyInitializationException 。
要點:
@OneToMany惰性雙向關聯中的Author和Book )JOIN FETCH來取得作者(包括他的書)JOIN FETCH (或JOIN )來取得包括其作者在內的書籍輸出範例: 
描述:這是一個基於以下文章的 Spring Boot 範例。是 Vlad 範例的功能實作。強烈建議閱讀該文章。
要點:
描述:這是一個 Spring Boot 範例,它利用 Hibernate 5.2.10 根據需要延遲連線取得的功能。預設情況下,在資源本地模式下,呼叫@Transactional註解的方法後會立即取得資料庫連線。如果此方法在第一個 SQL 語句之前包含一些耗時的任務,則連線將毫無意義地保持開啟。但是,Hibernate 5.2.10 允許我們根據需要延遲連線取得。此範例依賴 HikariCP 作為 Spring Boot 的預設連線池。
要點:
spring.datasource.hikari.auto-commit=falseapplication.properties中設定spring.jpa.properties.hibernate.connection.provider_disables_autocommit=true輸出範例: 

hi/lo演算法產生標識符序列注意:如果應用程式外部的系統需要在表中插入行,則不要依賴hi/lo演算法,因為在這種情況下,可能會因產生重複的識別碼而導致錯誤。依賴pooled或pooled-lo演算法( hi/lo的最佳化)。
描述:這是一個 Spring Boot 範例,使用hi/lo演算法在 10 次資料庫往返中產生 1000 個標識符,以 30 為一組批次處理 1000 個插入。
要點:
SEQUENCE產生器類型(例如,在 PostgreSQL 中)Author.java實體中的方式配置hi/lo演算法輸出範例: 
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
@ManyToMany關聯的最佳方式描述:此應用程式從效能角度證明如何正確實現雙向@ManyToMany關聯。
要點:
mappedBy者Set not List實現關係集合CascadeType.PERSIST和CascadeType.MERGE ,但避免CascadeType.REMOVE/ALL@ManyToMany預設是惰性的;就這樣吧!@NaturalId ))和/或資料庫生成的標識符並正確覆蓋(兩側) equals()和hashCode()方法,如下所示toString() ,則注意僅涉及從資料庫載入實體時取得的基本屬性@ManyToMany關聯中更喜歡Set而不是List描述:這是一個 Spring Boot 範例,在雙向@ManyToMany情況下分別使用List和Set刪除行。結論是Set好得多!這也適用於單向!
要點:
Set比List高效得多輸出範例: 
log4jdbc查看查詢詳細信息說明:透過log4jdbc查看查詢詳細資訊。
要點:
pom.xml中新增log4jdbc依賴項輸出樣本: 
描述:透過TRACE查看準備好的語句綁定/提取的參數。
要點:
application.properties新增: logging.level.org.hibernate.type.descriptor.sql=TRACE輸出樣本: 
java.time.YearMonth儲存為Integer或Date描述: Hibernate 類型是 Hibernate Core 預設不支援的一組額外類型。其中一種類型是java.time.YearMonth 。這是一個 Spring Boot 應用程序,它使用 Hibernate Type 將此YearMonth作為整數或日期儲存在 MySQL 資料庫中。
要點:
pom.xml中新增 Hibernate 類型作為依賴項@TypeDef將typeClass對應到defaultForType輸出範例: 
注意:在 JPA 2.1 中查詢的WHERE部分(而不是SELECT部分)中使用 SQL 函數可以透過function()完成,如下所示。
描述:嘗試在 JPQL 查詢中使用 SQL 函數(標準或定義)可能會導致異常,如果 Hibernate 無法識別它們並且無法解析 JPQL 查詢。例如,MySQL的concat_ws函式不被Hibernate辨識。該應用程式是基於 Hibernate 5.3 的 Spring Boot 應用程序,它透過MetadataBuilderContributor註冊concat_ws函數,並透過metadata_builder_contributor屬性通知 Hibernate。此範例也使用@Query和EntityManager ,因此您可以看到兩個用例。
要點:
MetadataBuilderContributor並註冊concat_ws MySQL函數application.properties中,設定spring.jpa.properties.hibernate.metadata_builder_contributor以指出 Hibernate 到MetadataBuilderContributor的實現輸出範例: 
描述:此應用程式是透過DataSource-Proxy僅記錄慢速查詢的範例。慢查詢是執行時間大於特定閾值(以毫秒為單位)的查詢。
要點:
pom.xml中新增 DataSource-Proxy 依賴項DataSource beanProxyFactory和MethodInterceptor的實作包裝DataSource beanafterQuery()輸出範例: 
SELECT COUNT子查詢並返回Page<dto>描述:該應用程式透過 Spring Boot 偏移分頁以Page<dto>形式取得資料。大多數時候,應該分頁的資料是只讀資料。只有當我們計劃修改該數據時,才應將數據提取到實體中,因此,將只讀數據作為Page<entity>提取並不可取,因為它最終可能會導致顯著的性能損失。用於計算記錄總數而觸發的SELECT COUNT是主SELECT的子查詢。因此,將有一次資料庫往返而不是兩次(通常,需要一個查詢來獲取數據,一個查詢來計算記錄總數)。
要點:
PagingAndSortingRepository的儲存庫List<dto>中List<dto>和正確的Pageable建立Page<dto>SELECT COUNT子查詢並傳回List<dto>描述:該應用程式透過 Spring Boot 偏移分頁以List<dto>形式取得資料。大多數時候,應該分頁的資料是只讀資料。只有當我們計劃修改該資料時,才應將資料提取到實體中,因此,將唯讀資料作為List<entity>提取並不可取,因為它最終可能會導致顯著的效能損失。用於計算記錄總數而觸發的SELECT COUNT是主SELECT的子查詢。因此,將有一次資料庫往返而不是兩次(通常,需要一個查詢來獲取數據,一個查詢來計算記錄總數)。
要點:
PagingAndSortingRepository的儲存庫List<dto>中如果您使用spring-boot-starter-jdbc或spring-boot-starter-data-jpa “starters”,您會自動獲得對 HikariCP 的依賴關係
注意:調整連接池參數的最佳方法是使用 Vlad Mihalcea 的 Flexy Pool。透過 Flexy Pool,您可以找到維持連接池高效能的最佳設定。
描述:這是一個僅透過application.properties設定 HikariCP 的啟動應用程式。 jdbcUrl是為 MySQL 資料庫設定的。出於測試目的,應用程式使用ExecutorService來模擬並髮用戶。檢查顯示連線池狀態的 HickariCP 報告。
要點:
application.properties中,依賴spring.datasource.hikari.*來設定 HikariCP輸出樣本: 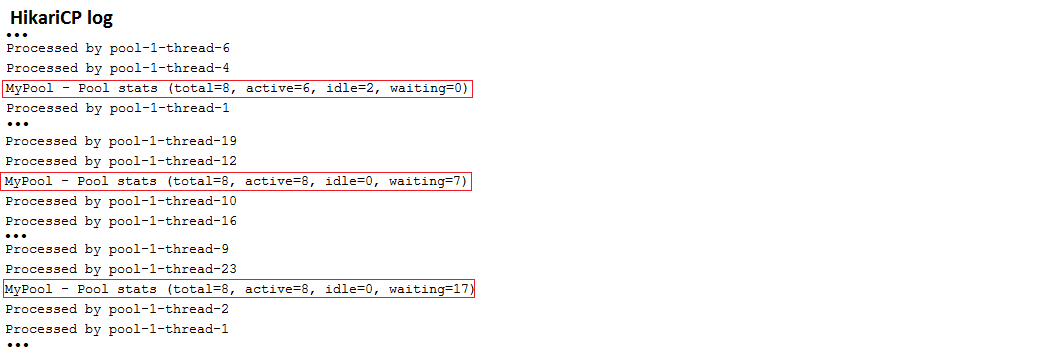
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
DataSourceBuilder自訂 HikariCP 設定如果您使用spring-boot-starter-jdbc或spring-boot-starter-data-jpa “starters”,您會自動獲得對 HikariCP 的依賴關係
注意:調整連接池參數的最佳方法是使用 Vlad Mihalcea 的 Flexy Pool。透過 Flexy Pool,您可以找到維持連接池高效能的最佳設定。
描述:這是一個透過DataSourceBuilder設定 HikariCP 的啟動應用程式。 jdbcUrl是為 MySQL 資料庫設定的。出於測試目的,應用程式使用ExecutorService來模擬並髮用戶。檢查顯示連線池狀態的 HickariCP 報告。
要點:
application.properties中,透過自訂前綴配置 HikariCP,例如app.datasource.*DataSource的@Bean輸出樣本:
此 DZone 文章詳細介紹了此應用程式。
DataSourceBuilder自訂 BoneCP 設定注意:調整連接池參數的最佳方法是使用 Vlad Mihalcea 的 Flexy Pool。透過 Flexy Pool,您可以找到維持連接池高效能的最佳設定。
描述:這是一個透過DataSourceBuilder設定 BoneCP 的啟動應用程式。 jdbcUrl是為 MySQL 資料庫設定的。出於測試目的,應用程式使用ExecutorService來模擬並髮用戶。
要點:
pom.xml中加入 BoneCP 依賴項application.properties中,透過自訂前綴配置 BoneCP,例如app.datasource.*DataSource的@Bean輸出樣本: 
DataSourceBuilder自訂 ViburDBCP 設定注意:調整連接池參數的最佳方法是使用 Vlad Mihalcea 的 Flexy Pool。透過 Flexy Pool,您可以找到維持連接池高效能的最佳設定。
描述:這是一個透過DataSourceBuilder設定 ViburDBCP 的啟動應用程式。 jdbcUrl是為 MySQL 資料庫設定的。出於測試目的,應用程式使用ExecutorService來模擬並髮用戶。
要點:
pom.xml上新增 ViburDBCP 依賴項application.properties中,透過自訂前綴配置 ViburDBCP,例如app.datasource.*DataSource的@Bean輸出樣本: 
DataSourceBuilder自訂 C3P0 設定注意:調整連接池參數的最佳方法是使用 Vlad Mihalcea 的 Flexy Pool。透過 Flexy Pool,您可以找到維持連接池高效能的最佳設定。
描述:這是一個透過DataSourceBuilder設定 C3P0 的啟動應用程式。 jdbcUrl是為 MySQL 資料庫設定的。出於測試目的,應用程式使用ExecutorService來模擬並髮用戶。
要點:
pom.xml上新增 C3P0 依賴項application.properties中,透過自訂前綴配置 C3P0,例如app.datasource.*DataSource的@Bean輸出樣本: 
DataSourceBuilder自訂 DBCP2 設定注意:調整連接池參數的最佳方法是使用 Vlad Mihalcea 的 Flexy Pool。透過 Flexy Pool,您可以找到維持連接池高效能的最佳設定。
描述:這是一個透過DataSourceBuilder設定 DBCP2 的啟動應用程式。 jdbcUrl是為 MySQL 資料庫設定的。出於測試目的,應用程式使用ExecutorService來模擬並髮用戶。
要點:
pom.xml上新增 DBCP2 依賴項application.properties中,透過自訂前綴配置 DBCP2,例如app.datasource.*DataSource的@BeanDataSourceBuilder自訂 Tomcat 設定注意:調整連接池參數的最佳方法是使用 Vlad Mihalcea 的 Flexy Pool。透過 Flexy Pool,您可以找到維持連接池高效能的最佳設定。
描述:這是一個透過DataSourceBuilder設定 Tomcat 的啟動應用程式。 jdbcUrl是為 MySQL 資料庫設定的。出於測試目的,應用程式使用ExecutorService來模擬並髮用戶。
要點:
pom.xml中加入Tomcat依賴application.properties中,透過自訂前綴配置 Tomcat,例如app.datasource.*DataSource的@Bean輸出樣本: 
注意:調整連接池參數的最佳方法是使用 Vlad Mihalcea 的 Flexy Pool。透過 Flexy Pool,您可以找到維持連接池高效能的最佳設定。
描述:這是一個啟動應用程序,它使用兩個資料來源(兩個 MySQL 資料庫,一個名為authorsdb ,一個名為booksdb )和兩個連接池(每個資料庫使用自己的具有不同設定的HikariCP 連接池)。基於以上內容,配置來自兩個不同提供者的兩個連接池也非常容易。
要點:
application.properties中,透過兩個自訂前綴配置兩個 HikariCP 連接池,例如app.datasource.ds1和app.datasource.ds2DataSource的@Bean並將其標記為@PrimaryDataSource的@BeanEntityManagerFactory並指出要掃描的套件EntityManager的網域和儲存庫放入正確的套件中輸出樣本: 
注意:如果您希望在不更改 setter 的情況下提供 Fluent API,請考慮此項目。
描述:這是一個範例應用程序,它更改實體設定器方法以支援 Fluent API。
要點:
this而不是 setter 中的void流暢的 API 範例: 
注意:如果您希望透過更改 setter 來提供 Fluent API,請考慮此項目。
描述:這是一個範例應用程序,它在實體中添加了其他方法(例如,對於setName ,我們添加name )方法,以增強 Fluent API 的能力。
要點:
this而不是void附加方法流暢的 API 範例: 
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
Slice<T> findAll()最有可能這就是你想要的: How To Fetch Slice<entity> / Slice<dto> Via fetchAll / fetchAllDto
Slice<T> findAll()的一些實作:
"SELECT e FROM " + entityClass.getSimpleName() + " e;"CriteriaBuilder而不是硬編碼 SQL 的極簡實現Sort實現,因此可以對結果進行排序Sort和 Spring 資料Specification的實現Sort 、 LockModeType 、 QueryHints和 Spring Data Specification的實現SimpleJpaRepository來提供 Spring Data Pageable和/或Specification 。基本上,此實作是唯一傳回Page<T>而不是Slice<T>的實現,但它不會觸發額外的SELECT COUNT因為它是透過重寫Page<T> readPage(...)方法而消除的SimpleJpaRepository 。主要缺點是,透過返回Page<T>您不知道是否有下一頁或當前頁面是最後一頁。儘管如此,也有一些解決方法可以實現這一點。在此實作中,您無法設定LockModeType或查詢提示。故事:Spring Boot 提供了一種基於偏移量的內建分頁機制,該機制傳回Page或Slice 。每個 API 都代表一頁資料和一些元資料。主要差異在於Page包含記錄總數,而Slice只能判斷是否還有其他頁面可用。對於Page ,Spring Boot 提供了一個findAll()方法,能夠將Pageable和/或Specification或Example作為參數。為了建立包含總記錄數的Page ,此方法會在用於取得目前頁面資料的查詢旁邊觸發一個SELECT COUNT額外查詢。這可能會降低效能,因為每次請求頁面時都會觸發SELECT COUNT查詢。為了避免這種額外的查詢,Spring Boot 提供了一個更寬鬆的 API,即Slice API。使用Slice而不是Page可以消除此額外SELECT COUNT查詢的需要,並傳回頁面(記錄)和一些元數據,而無需傳回記錄總數。因此,雖然Slice不知道記錄總數,但它仍然可以判斷當前頁面之後是否還有可用的頁面,或者這是最後一頁。問題是Slice對於包含 SQL、 WHERE子句的查詢(包括那些使用 Spring Data 內建的查詢建構器機制的查詢)運作得很好,但對於findAll()不起作用。此方法仍將傳回Page而非Slice ,因此Slice<T> findAll(...);會觸發SELECT COUNT查詢; 。
描述:這是一套範例應用程序,提供不同版本的Slice<T> findAll(...)方法。我們有一個依賴硬編碼查詢的極簡實作: "SELECT e FROM " + entityClass.getSimpleName() + " e"; (本節),到支援排序、規範、鎖定模式和查詢提示的自訂實現,該實作依賴於擴展SimpleJpaRepository 。
要點:
Slice<T> findAll(...)方法的abstract類別 ( SlicePagingRepositoryImplementation )findAll()方法以傳回Slice<T> (或Page<T> ,但不包含元素總數)SliceImpl ( Slice<T> ) 或PageImpl ( Page<T> )readSlice()方法或覆寫SimpleJpaRepository#readPage()頁面以避免SELECT COUNTAuthorRepository ) 將實體類別(例如Author.class )傳遞給該abstract類別COUNT(*) OVER並回傳List<dto>描述:通常,在偏移分頁中,需要一個查詢來取得數據,另一個查詢用於計算記錄總數。但是,我們可以透過嵌套在主SELECT中的SELECT COUNT子查詢在單一資料庫往返中取得此資訊。更好的是,對於支援視窗函數的資料庫供應商,有一種依賴COUNT(*) OVER()的解決方案,如本應用程式中所示,該應用程式在針對MySQL 8 的本機查詢中使用此視窗SELECT COUNT 。
要點:
COUNT(*) OVER()視窗函數的傳回的額外列例子: 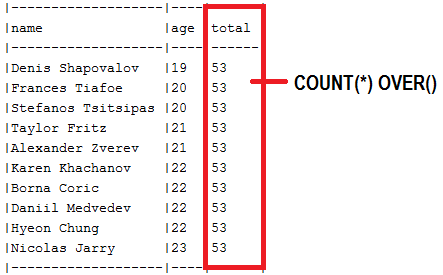
描述:當我們依賴偏移量分頁時,我們會因在達到所需偏移量之前丟棄n 筆記錄而導致效能損失。較大的n會導致顯著的性能損失。當我們有一個大的n時,最好依賴鍵集分頁,它可以為大型資料集保持「恆定」的時間。為了了解偏移量的表現如何,請查看這篇文章:
該文章的螢幕截圖(偏移分頁): 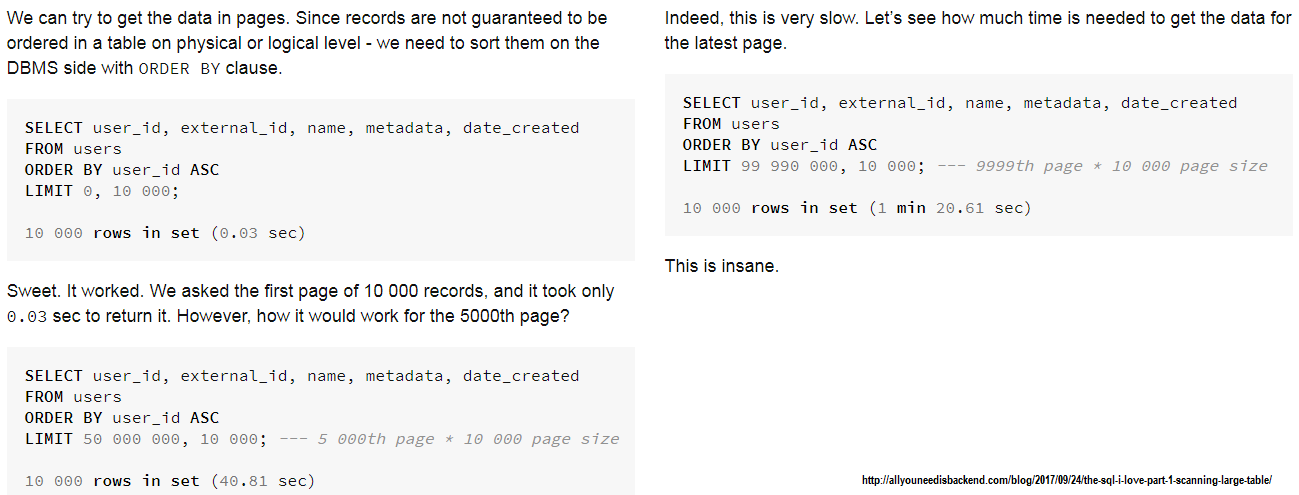
需要知道是否還有更多紀錄?
從本質上來說,鍵集不使用SELECT COUNT來取得總記錄數。但是,透過一點調整,我們可以輕鬆判斷是否有更多記錄,從而顯示Next Page類型的按鈕。主要是,如果您需要這樣的東西,請考慮這個應用程序,其高潮如下所示:
public AuthorView fetchNextPage(long id, int limit) {
List<Author> authors = authorRepository.fetchAll(id, limit + 1);
if (authors.size() == (limit + 1)) {
authors.remove(authors.size() - 1);
return new AuthorView(authors, true);
}
return new AuthorView(authors, false);
}
或者,像這樣(依賴Author.toString()方法):
public Map<List<Author>, Boolean> fetchNextPage(long id, int limit) {
List<Author> authors = authorRepository.fetchAll(id, limit + 1);
if(authors.size() == (limit + 1)) {
authors.remove(authors.size() -1);
return Collections.singletonMap(authors, true);
}
return Collections.singletonMap(authors, false);
}
可以根據第一筆記錄輕鬆實現Previous Page按鈕。
要點:
id )WHERE和ORDER BY子句中的列描述:這是一個經典的 Spring Boot偏移分頁範例。然而,不建議在生產中使用這種方法,因為其性能損失將進一步解釋。
當我們依賴偏移量分頁時,我們會因在達到所需偏移量之前丟棄n 筆記錄而導致效能損失。較大的n會導致顯著的性能損失。另一個缺點是需要額外的SELECT來計算記錄總數。為了了解偏移分頁的效能有多差,請查看這篇文章。該文章的螢幕截圖如下:儘管如此,也許這個例子有點極端。對於相對較小的資料集,偏移分頁還不錯(它在效能上接近鍵集分頁),並且由於 Spring Boot 透過Page API 提供了對偏移分頁的內建支持,因此使用起來非常容易。但是,根據情況,我們可以稍微優化一下偏移分頁,如下例所示:
取得一個頁面作為Page :
COUNT(*) OVER並回傳Page<dto>COUNT(*) OVER並透過額外列返回Page<entity>SELECT COUNT子查詢並返回Page<dto>SELECT COUNT子查詢並透過額外列返回Page<entity>SELECT COUNT子查詢並傳回透過投影映射實體和記錄總數的Page<projection>以List形式取得頁面:
COUNT(*) OVER並回傳List<dto>COUNT(*) OVER並透過額外列返回List<entity>SELECT COUNT子查詢並傳回List<dto>SELECT COUNT子查詢並傳回List<entity>SELECT COUNT子查詢並傳回透過投影對映實體和記錄總數的List<projection>但是:如果偏移分頁導致效能問題,並且您決定使用鍵集分頁,那麼請檢查此處(鍵集分頁)。
經典偏移分頁的要點:
PagingAndSortingRepository的儲存庫Page<entity>的方法經典的偏移分頁範例:
findAll(Pageable)而不進行排序:repository.findAll(PageRequest.of(page, size));findAll(Pageable)進行排序:repository.findAll(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "name")));Page<Author> findByName(String name, Pageable pageable);Page<Author> queryFirst10ByName(String name, Pageable pageable);描述:假設Author和Book實體之間存在一對多關係。當我們保存一個作者時,由於級聯所有/持久,我們也保存了他的書。我們想要建立一堆作者的書籍,並使用批次技術將它們保存在資料庫(例如,MySQL 資料庫)中。預設情況下,這將導致對每個作者和每個作者的書籍進行批次處理(一批用於作者,一批用於書籍,另一批用於作者,另一批用於書籍,依此類推)。為了批量處理作者和書籍,我們需要像此應用程式一樣訂購插入內容。
重點:除了 MySQL 中批次插入的所有設定之外,我們還需要在application.properties中設定以下屬性: spring.jpa.properties.hibernate.order_inserts=true
沒有有序插入的範例: 
有序插入的範例: 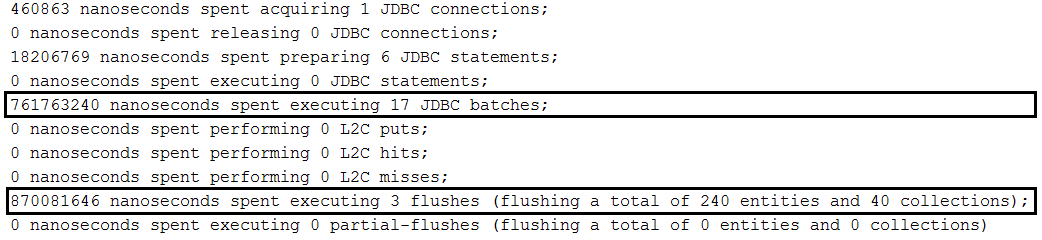
實施:
描述: MySQL 中的批次更新。
要點:
application.properties中設定spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 的最佳化,語句被重寫到單一字串緩衝區中並在單一請求中傳送)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_updates=true以透過排序最佳化批次更新application.properties中設置一個設置,用於在更新和刪除操作期間啟用版本化實體的批次(包含@Version的實體用於隱式樂觀鎖定);這個設定是: spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true ;從 Hibernate 5 開始,預設此設定應為true單一實體的輸出範例: 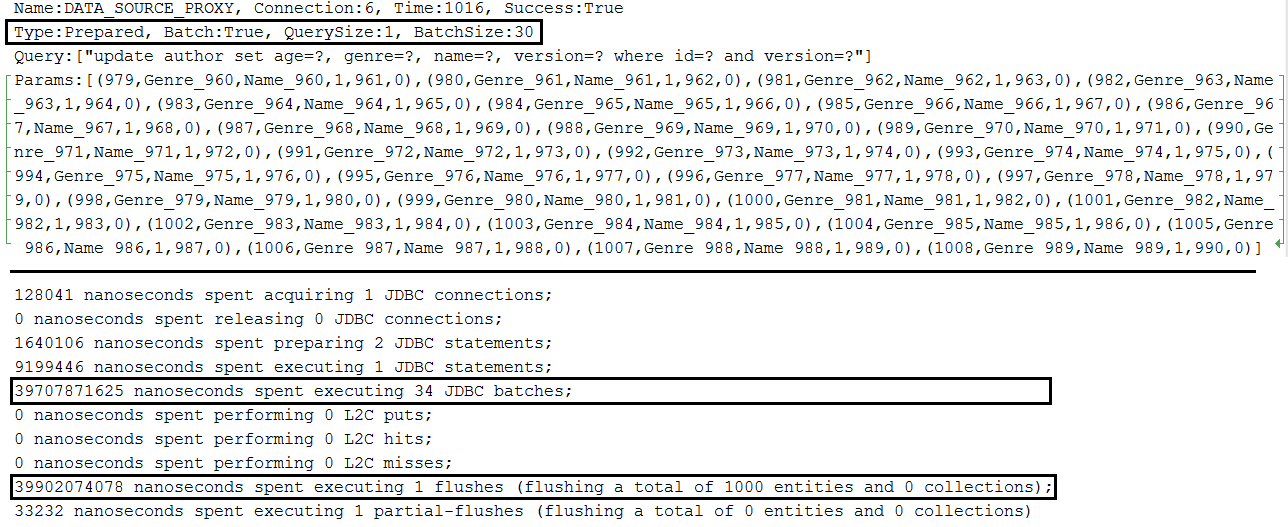
父子關係輸出範例: 
說明: MySQL中不涉及關聯的批次刪除。
注意: Spring的deleteAllInBatch()和deleteInBatch()不使用刪除批次處理,也不利用自動樂觀鎖定機制來防止遺失更新(例如, @Version被忽略)。它們依賴Query.executeUpdate()來觸發批次操作。這些操作很快,但 Hibernate 不知道哪些實體被刪除,因此,持久性上下文不會相應更新(由您相應地刷新(刪除前)和關閉/清除(刪除後)持久性上下文以避免由未刷新(如果有)或過時(如果有)實體建立的問題)。第一個 ( deleteAllInBatch() ) 只是觸發delete from entity_name語句,對於刪除所有記錄非常有用。第二個( deleteInBatch() )觸發delete from entity_name where id=? or id=? or id=? ...因此,如果產生的DELETE語句超過可接受的最大大小,則語句很容易導致問題。這個問題可以透過分塊刪除資料、依賴IN運算子等來控制。批次操作比批次處理更快,批次可以透過deleteAll() 、 deleteAll(Iterable<? extends T> entities)或delete()方法來實現。在幕後,兩種風格的deleteAll()都依賴delete() 。 delete() / deleteAll()方法依賴EntityManager.remove()因此持久性上下文會相應地同步。此外,如果啟用自動樂觀鎖定機制(以防止遺失更新),則將使用它。
定期刪除批次的要點:
deleteAll() 、 deleteAll(Iterable<? extends T> entities)或delete()方法application.properties中設定spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 的最佳化,語句被重寫到單一字串緩衝區中並在單一請求中傳送)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))@Version Hibernate 5之前,我們需要在application.properties中進行設定。此設定為: spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true ;從Hibernate 5開始,預設應為true輸出範例: 
描述: MySQL中的批次刪除透過orphanRemoval=true 。
注意: Spring deleteAllInBatch()和deleteInBatch()不要使用刪除批次處理,也不要利用級聯刪除, orphanRemoval和自動最佳鎖定鎖定機制來防止遺失更新(例如,@version忽略@Version )。他們依賴Query.executeUpdate()來觸發批次操作。這些操作很快,但是Hibernate不知道刪除了哪些實體,因此,持久性上下文沒有相應地更新(取決於您(刪除之前)並關閉/清除(刪除後)持久上下文以避免以避免由未覺得(如果有)或過時(如果有)實體創建的問題。第一個( deleteAllInBatch() )只需觸發delete from entity_name ,對於刪除所有記錄非常有用。第二個( deleteInBatch() )觸發delete from entity_name where id=? or id=? or id=? ... ,如果產生的DELETE語句超過最大可接受的大小,則很容易造成問題。可以透過刪除區塊中的數據,依賴IN員等來控制此問題。批次操作比批次處理快,可以透過deleteAll() , deleteAll(Iterable<? extends T> entities)或delete()方法來實現。在現場的後面, deleteAll()的兩個口味依賴於delete() 。 delete() / deleteAll()方法依賴EntityManager.remove()因此持久性上下文會相應地同步。如果啟用了自動最佳鎖定機制(以防止遺失更新),則將使用它。此外,級聯的去除和orphanRemoval也有效。
使用deleteAll()/delete()的要點:
Author實體,每個作者都可以有幾Book (一對多)orphanRemoval=true and CascadeType.ALLBook與通訊Author分離orphanRemoval=true進入場景的時候;由於此設置,所有分離的書籍將被刪除;產生的DELETE語句被批次(如果將orphanRemoval設為false ,則將執行大量更新,而不是刪除)deleteAll()或delete()方法刪除所有Author (由於我們已經脫離了所有Book ,因此Author刪除也將利用批次)ON DELETE CASCADE在MySQL中批次刪除描述: MySQL via via ON DELETE CASCADE中的批次刪除。自動產生的資料庫架構將包含ON DELETE CASCADE指令。
注意: Spring deleteAllInBatch()和deleteInBatch()不要使用刪除批次處理,也不要利用級聯刪除, orphanRemoval和自動樂觀的鎖定機制來防止丟失的更新(例如, @Version忽略了),但它們都需要使用在ON DELETE CASCADE的優勢非常有效。它們透過Query.executeUpdate()觸發批次操作,因此,持久性上下文沒有相應同步(取決於您(刪除之前)並關閉/清除(在刪除後)相應地避免持久性上下文,以避免由Unflushed(Unflushed( Unflushed)造成的問題(如果有)或過時的(如果有)實體)。第一個只是觸發delete from entity_name ,而第二個則delete from entity_name where id=? or id=? or id=? ...陳述。對於批次中的刪除,依賴deleteAll() , deleteAll(Iterable<? extends T> entities)或delete()方法。在現場的後面, deleteAll()的兩個口味依賴於delete() 。將批次與資料庫自動操作( ON DELETE CASCADE )中混合將導致部分同步的持久上下文。
要點:
Author實體,每個作者都可以有幾Book (一對多)orphanRemoval或將其設定為falseCascadeType.PERSIST和CascadeType.MERGE@OneToMany旁邊設定@OnDelete(action = OnDeleteAction.CASCADE)spring.jpa.properties.hibernate.dialect設定為org.hibernate.dialect.MySQL5InnoDBDialect (or, MySQL8Dialect )deleteFoo()方法輸出範例:

@NaturalId替代實作:如果您想避免擴展SimpleJpaRepository檢查此實作。
描述:這是一個使用Hibernate @NaturalId來對應自然業務金鑰的Springboot應用程式。此實作使我們可以使用@NaturalId因為它是Spring提供的。
要點:
Book )中,標記應用程式@NaturalId充當自然ID的屬性(業務金鑰);通常,有一個這樣的屬性,但在這裡得到了多個屬性@NaturalId(mutable = false)和@Column(nullable = false, updatable = false, unique = true, ...)@NaturalId(mutable = true)和@Column(nullable = false, updatable = true, unique = true, ...)equals()和hashCode()@NoRepositoryBean介面( NaturalRepository )來定義兩種方法,命名為findBySimpleNaturalId()和findByNaturalId()Session , bySimpleNaturalId()和byNaturalId()方法的此介面( NaturalRepositoryImpl )的實現@EnableJpaRepositories(repositoryBaseClass = NaturalRepositoryImpl.class)將此實作註冊為基類findBySimpleNaturalId()或findByNaturalId()| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
描述:這是使用P6SPY的Spring Boot應用程式。 P6SPY是一個框架,可以使資料庫資料無縫截獲和登錄,而沒有對應用程式進行程式碼變更。
要點:
pom.xml中,加入p6spy maven依賴關係application.properties中,設定JDBC URL為jdbc:p6spy:mysql://localhost:3306/db_usersapplication.properties中,設定驅動程式類別名稱為, com.p6spy.engine.spy.P6SpyDriverspy.properties (此檔案包含p6spy配置);在此應用程式中,日誌將輸出到控制台,但是您可以輕鬆切換到檔案。有關P6Spy配置的更多詳細資訊可以在文件中找到輸出樣本: 
OptimisticLockException異常( @Version )之後重試交易(@version)注意:透過@Version樂觀鎖定機制也適用於獨立實體。
描述:這是一個春季啟動應用程序,該應用程式模擬了導致樂觀鎖定異常的方案。當發生這種例外時,應用程式透過Vlad Mihalcea開發的DB-Util程式庫來重試相應的交易。
要點:
pom.xml中,加入db-util依賴性OptimisticConcurrencyControlAspect Bean@Transactional註釋)(或稱為容易投擲的方法(可以使用@Transactional可以註釋此方法))一個樂觀的鎖定異常@Retry(times = 10, on = OptimisticLockingFailureException.class)輸出樣本: 
OptimisticLockException異常後重試交易(Hibernate無版本的樂觀鎖定機制)注意:透過冬眠版本的樂觀鎖定機制不適用於獨立實體(不要關閉持久性上下文)。
描述:這是一個彈簧啟動應用程序,該應用程式模擬了一個導致樂觀鎖定異常的方案(例如,在Spring boot, OptimisticLockingFailureException )透過Hibernate-node-worder-wordent-wording opportist鎖定。當發生這種例外時,應用程式透過Vlad Mihalcea開發的DB-Util程式庫來重試相應的交易。
要點:
pom.xml中,加入db-util庫依賴關係OptimisticConcurrencyControlAspect Bean@DynamicUpdate和@OptimisticLocking(type = OptimisticLockType.DIRTY)註解對應的實體(例如, Inventory )(type = opportisticlocktype.dirty)@Transactional註釋)(或稱為容易投擲的方法(可以使用@Transactional可以註釋此方法))一個樂觀的鎖定異常@Retry(times = 10, on = OptimisticLockingFailureException.class)注意:您也可能想閱讀食譜:“如何透過春季資料投影建立DTO”
描述:這是一個應用程式範例,僅透過彈簧資料投影(DTO)從資料庫中取得所需的列,並透過虛擬屬性豐富結果。
要點:
name和ageAuthorNameAge ,使用@Value和Spring Spel指向域模型的支援屬性(在這種情況下,域模型屬性age透過虛擬屬性years暴露)AuthorNameAge ,使用@Value和Spring Spel透過兩個虛擬屬性在域模型中沒有匹配(在這種情況下, rank和books )中豐富結果輸出範例: 
描述: Spring資料帶有JPA的查詢創建機制,該機制能夠解釋查詢方法名稱並將其轉換為適當方言中的SQL查詢。只要我們尊重這種機制的命名慣例,這就是可能的。這是一種利用此機制來編寫限制結果大小的查詢的應用程式。基本上,查詢方法的名稱指示彈簧資料如何在產生的SQL查詢中新增LIMIT (或類似子句)(或類似的子句)。
要點:
AuthorRepository )範例:
- List<Author> findFirst5ByAge(int age);
- List<Author> findFirst5ByAgeGreaterThanEqual(int age);
- List<Author> findFirst5ByAgeLessThan(int age);
- List<Author> findFirst5ByAgeOrderByNameDesc(int age);
- List<Author> findFirst5ByGenreOrderByAgeAsc(String genre);
- List<Author> findFirst5ByAgeGreaterThanEqualOrderByNameAsc(int age);
- List<Author> findFirst5ByGenreAndAgeLessThanOrderByNameDesc(String genre, int age);
- List<AuthorDto> findFirst5ByOrderByAgeAsc();
- Page<Author> queryFirst10ByName(String name, Pageable p);
- Slice<Author> findFirst10ByName(String name, Pageable p);
支援的關鍵字列表如下: 
schema-*.sql注意:通常,在實際應用中,避免透過hibernate.ddl-auto產生模式或設定其validate 。使用Flyway schema-*.sql Liquibase
描述:此應用程式是使用schema-*.sql
要點:
application.properties中,設定JDBC URL(例如, spring.datasource.url=jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=true )application.properties中,停用ddl auto(但不要明確新增hibernate.ddl-auto設定)application.properties中,指示彈簧啟動以初始化schema-mysql.sql檔案初始化架構@Table schema-*.sql注意:通常,在實際應用中,避免透過hibernate.ddl-auto產生模式或設定其validate 。使用Liquibase schema-*.sql Flyway
描述:此應用程式是使用schema-*.sql透過@Table在實體映射中匹配資料庫。
要點:
application.properties中,設定沒有資料庫的JDBC URL,例如, spring.datasource.url=jdbc:mysql://localhost:3306application.properties中,停用ddl auto(但不要指定hibernate.ddl-auto )aaplication.properties中,指示彈簧啟動以初始化schema-mysql.sql檔案初始化架構Author實體中,指定對應的表( author )在資料庫authorsdb中通過@Table(schema="authorsdb")Book實體中,指定對應的表( book )在資料庫booksdb中透過@Table(schema="booksdb")輸出範例:
Author會導致以下SQL: insert into authorsdb.author (age, genre, name) values (?, ?, ?) 。Book結果結果:以下SQL: insert into booksdb.book (isbn, title) values (?, ?)注意:對於Web應用程序,分頁應該是必經之路,而不是串流。但是,如果選擇串流傳輸,請記住黃金法則:保持結果設定為盡可能小的。另外,請記住,執行計劃可能不如使用SQL級分頁時那麼有效。
描述:此應用程式是透過Spring Data和MySQL串流傳輸結果集的範例。可以為資料庫採用此範例,該資料庫在單一往返中取得整個結果,從而導致效能懲罰。
要點:
@Transactional(readOnly=true) )Integer.MIN_VALUE (在mySQL中推薦))Statement設為Integer.MIN_VALUE ,或將useCursorFetch=true加到jdbc url中,然後將Statement fetch-size fetch-size to to a position Integer(Eg,30)createDatabaseIfNotExist注意:對於生產,請勿依賴hibernate.ddl-auto (或對應物)將模式DDL匯出到資料庫。只需刪除(停用) hibernate.ddl-auto或將其設定為validate即可。依靠飛行或液體。
描述:此應用程式是資料庫存在時透過Flyway遷移MySQL資料庫的範例(是在透過MySQL特定參數遷移之前建立的, createDatabaseIfNotExist=true )。
要點:
pom.xml中,加入飛行依賴性spring.jpa.hibernate.ddl-autoapplication.properties中,設定JDBC URL如下: jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=trueclasspath:db/migrationV1.1__Description.sql , V1.2__Description.sql ,...spring.flyway.schemas建立的Flyway -資料庫遷移MySQL資料庫注意:對於生產,請勿依賴hibernate.ddl-auto (或對應物)將模式DDL匯出到資料庫。只需刪除(停用) hibernate.ddl-auto或將其設定為validate即可。依靠飛行或液體。
說明:此應用程式是當Flyway透過spring.flyway.schemas建立資料庫時遷移MySQL資料庫的範例。在這種情況下,請套用@Table(schema = "bookstoredb")或@Table(catalog = "bookstoredb")註解實體。在這裡,資料庫名稱是bookstoredb 。
要點:
pom.xml中,加入飛行依賴性spring.jpa.hibernate.ddl-autoapplication.properties中,設定JDBC URL如下: jdbc:mysql://localhost:3306/application.properties中,新增spring.flyway.schemas=bookstoredb ,其中bookstoredb是Flyway應該建立的資料庫(隨時可以新增您自己的資料庫名稱)@Table(schema/catalog = "bookstoredb")classpath:db/migrationV1.1__Description.sql , V1.2__Description.sql ,...遷移歷史的輸出範例: 
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
注意:對於生產而言,不要依賴hibernate.ddl-auto來建立模式。刪除(停用) hibernate.ddl-auto或將其設定為validate 。依靠飛行或液體。
說明:此應用程式是MySQL和PostgreSQL自動建立和遷移模式的範例。此外,每個資料來源都使用其自己的Hikaricp連接池。如果mysql,則schema =資料庫,我們基於createDatabaseIfNotExist=true自動建立模式( authorsdb )。如果是PostgreSQL,資料庫可以使用多個模式,則我們使用預設的postgres資料庫,並在其中使用schema, booksdb 。為此,我們依賴Flyway,它能夠創造缺少的模式。
要點:
pom.xml中,加入飛行依賴性spring.jpa.hibernate.ddl-auto或將其設定為validateapplication.properties中,為mysql設定JDBC URL為JDBC jdbc:mysql://localhost:3306/authorsdb?createDatabaseIfNotExist=true and postgreSql as,jdbc as jdbc:postgresql://localhost:5432/postgres?currentSchema=booksdbapplication.properties中,設定spring.flyway.enabled=false到停用預設行為DataSourceFlywayDataSource ,一個用於PostgreSQLEntityManagerFactory ,一個用於PostgreSQLdbmigrationmysql中dbmigrationpostgresql中注意:對於生產,請勿依賴hibernate.ddl-auto (或對應物)將模式DDL匯出到資料庫。只需刪除(停用) hibernate.ddl-auto或將其設定為validate即可。依靠飛行或液體。
說明:此應用程式是使用Flyway在PostgreSQL中自動建立和遷移兩個模式的範例。此外,每個資料來源都使用其自己的Hikaricp連接池。如果在PostgreSQL的情況下,資料庫可以使用多個模式,我們使用預設的postgres資料庫並自動建立兩個模式, authors和books 。為此,我們依賴Flyway,它能夠創造缺少的模式。
要點:
pom.xml中,加入飛行依賴性spring.jpa.hibernate.ddl-auto或將其設定為validateapplication.properties中,將books的jdbc url配置為jdbc: jdbc:postgresql://localhost:5432/postgres?currentSchema=authors jdbc:postgresql://localhost:5432/postgres?currentSchema=books and authors as jdbc:postgreSql:// postgresql:// localhost:localhost:54332/gred jdbc:postgresql://localhost:5432/postgres?currentSchema=authorsapplication.properties中,設定spring.flyway.enabled=false到停用預設行為DataSource ,一個用於books ,一個用於authorsFlywayDataSource ,一本用於books ,另一個用於authorsEntityManagerFactory ,一個用於books ,另一個用於authorsbooks ,將遷移SQLS檔案放在dbmigrationbooks中authors ,將遷移SQLS檔案放在dbmigrationauthors中JOIN FETCH @ElementCollection描述:此應用程式是套用JOIN FETCH以獲得@ElementCollection的範例。
要點:
@ElementCollection已加載懶惰,保持懶惰JOIN FETCH@Subselect )注意:僅當使用DTO,DTO和額外查詢時,請考慮使用@Subselect ,或將資料庫視圖對應到實體不是解決方案。
描述:此應用程式是透過Hibernate, @Subselect將實體對應到查詢的範例。主要是,我們在雙向一對多協會中有兩個實體。 Author寫了幾Book 。這個想法是寫一個只讀的查詢,以從Author中獲取一些字段(例如,DTO),但也有能力調用getBooks()並以懶惰的方式獲取這Book 。如您所知,無法使用經典的DTO,因為該DTO沒有管理,我們無法導航關聯(不支援與其他實體的任何託管關聯)。透過Hibernate @Subselect我們可以將一個僅讀取和不可變的實體對應到查詢。這次,我們可以懶惰地導航關聯。
要點:
Author所需的欄位(包括與Book的關聯)@Immutable因為不允許寫入操作@Synchronize為二手實體進行沖洗狀態過渡@Subselect編寫所需的查詢,將實體對應到SQL查詢描述:此應用程式是在Spring Boot應用程式中使用Hibernate軟刪除的範例。
要點:
deleted的欄位定義abstract類別的BaseEntityAuthor和Book實體)應擴展BaseEntity@Where註釋如下: @Where(clause = "deleted = false")@SQLDelete註解標記以觸發UPDATE SQLS代替DELETE SQLS,如下所示: @SQLDelete(sql = "UPDATE author SET deleted = true WHERE id = ?")輸出範例: 
DataSourceBuilder編程自訂HikarICP設定如果您使用spring-boot-starter-jdbc或spring-boot-starter-data-jpa “啟動器”,則自動獲得對Hikaricp的依賴
注意:調整連接池參數的最佳方法包括使用Vlad Mihalcea使用Flexy Pool。透過Flexy池,您可以找到維持連線池高效能的最佳設定。
描述:這是一個透過DataSourceBuilder設定Hikaricp的開球應用程式。 jdbcUrl設定為MySQL資料庫。為了進行測試,該應用程式使用ExecutorService服務來模擬並髮用戶。檢查Hickaricp報告顯示連線池狀態。
要點:
@Bean ,以程式方式傳回DataSource描述:審核對於維護歷史記錄很有用。稍後,這可以幫助我們追蹤用戶活動。
要點:
abstract基礎實體(例如, BaseEntity ),並使用@MappedSuperclass和@EntityListeners({AuditingEntityListener.class})對其進行註解。@CreatedDate protected LocalDateTime created;@LastModifiedDate protected LocalDateTime lastModified;@CreatedBy protected U createdBy;@LastModifiedBy protected U lastModifiedBy;@EnableJpaAuditing(auditorAwareRef = "auditorAware")AuditorAware的實作(這是持續執行修改的使用者所需的;使用Spring Security返回目前登入的使用者)@Bean公開此實現spring.jpa.hibernate.ddl-auto=create )描述:審核對於維護歷史記錄很有用。稍後,這可以幫助我們追蹤用戶活動。
要點:
@Audited註釋@AuditTable的註釋實體,可以重命名用於審核的表ValidityAuditStrategy進行快速資料庫讀取,但寫入較慢(比預設DefaultAuditStrategy慢)描述:預設情況下,實體的屬性是急切的(一次)。此應用程式是如何從這裡使用Hibernate屬性懶惰載入的替代方法。該應用程式使用基類來隔離應急切地載入的屬性(擴展基類擴展的實體),以隔離應按需加載的屬性。
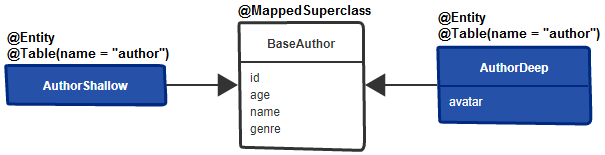
要點:
BaseAuthor ,並用@MappedSuperclass註釋BaseAuthor的AuthorShallow subentity,並且不要在其中新增任何屬性(這將繼承超級類別的屬性)AuthorDeep subsentity的BaseAuthor並新增應按需載入的屬性(例如, avatar )@Table(name = "author")將兩個次級對應到同一表AuthorShallowRepository和AuthorDeepRepository執行以下請求(透過BookStoreController):
localhost:8080/authors/shallowlocalhost:8080/authors/deep還要檢查:
描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。在此應用程式中,我們依靠建構函數和彈簧資料查詢建構器機制。
要點:
參見:
DTO透過構造函數表達式和JPQL
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
JOIN描述:使用JOIN對於獲取DTO(從未修改的數據,而不是在當前或後續請求中)非常有用。例如,在懶惰的@OneToMany協會中考慮兩個實體, Author和Book 。而且,我們想從父表( author )中取得一部分列,並從子表( book )中取得列的子集。這項工作非常適合JOIN ,可以從不同的表中獲取列並建立原始結果集。這樣,我們只獲取所需的數據。此外,我們可能希望將結果集中在頁面中(例如,透過LIMIT )。該應用程式包含幾種透過偏移分頁來完成此任務的方法。
要點:
Page上的分頁(與( SELECT COUNT和COUNT(*) OVER()視窗函數)Slice和List分頁DENSE_RANK()分頁避免了結果集的截斷(作者只能用他的書的一部分取得)LEFT JOIN FETCH參見:
描述:假設我們有兩個實體從事一對多(或多個)懶散的雙向(或單向)關係(例如, Author有更多Book )。而且,我們想觸發一個SELECT ,該選擇獲取所有Author和相應的Book 。這是JOIN FETCH的工作,該工作將在場景後面轉換為INNER JOIN 。作為INNER JOIN ,SQL將僅傳回擁有Book的Author 。如果我們想退還所有Author ,包括沒有Book作者,那麼我們可以依靠LEFT JOIN FETCH 。類似,我們可以獲得所有Book ,包括沒有註冊Author書。這可以透過LEFT JOIN FETCH或LEFT JOIN來完成。
要點:
Author和Book )LEFT JOIN FETCH以獲取所有作者和書籍(即使沒有註冊書籍,他們即使他們沒有登記書)LEFT JOIN FETCH以獲取所有書籍和作者(即使他們沒有註冊的作者,也取出書籍)JOIN VS。 JOIN FETCH參見:
描述:這是一個旨在揭示JOIN和JOIN FETCH之間的差異的應用程式。要牢記的重要一件事是,在LAZY的情況下, JOIN將無法使用單一SQL SELECT初始化關聯的集合以及其父物件。另一方面, JOIN FETCH能夠完成此類任務。但是,不要低估JOIN ,因為當我們需要在同一查詢中組合/加入兩個(或更多)表的列時, JOIN是適當的選擇,但是我們不需要初始化返回實體的關聯集合(例如,對於獲取DTO非常有用)。
要點:
Author和Book )JOIN並JOIN FETCH以獲得作者,包括他的書JOIN以獲取書(1)JOIN以獲取一本書,包括其作者(2)JOIN FETCH以獲取一本書,包括作者請注意:
JOIN ,取得Author Book需要其他SELECT陳述,容易受到n+1績效懲罰JOIN (1),獲取Book的Author需要其他SELECT陳述,容易n+1績效懲罰JOIN (2),取得Book的Author完全可以JOIN FETCH (需要一個SELECT )JOIN FETCH ,獲取Book的每個Author需要一個SELECT描述:如果出於某種原因,您需要彈簧投影(DTO)中的實體,則此應用程式向您展示如何透過範例進行操作。在這種情況下,有兩個實體, Author和Book ,涉及懶惰的雙向一對多協會(也可以是其他協會,甚至沒有實現的協會)。而且,我們想在春季投影中作為實體, Author和書籍title獲取。
要點:
Author和Book )public Author getAuthor()和public String getTitle()的適當彈簧預測()描述:如果出於某種原因,您需要彈簧投影(DTO)中的實體,則此應用程式向您展示如何透過範例進行操作。在這種情況下,有兩個實體, Author和Book ,它們之間沒有實現的關聯,但是它們具有genre屬性。我們使用此屬性透過JPQL加入作者。而且,我們想在春季投影中作為實體, Author和書籍title獲取。
要點:
Author和Book )public Author getAuthor()和public String getTitle()的適當彈簧預測()描述:假設我們有兩個實體, Author和Book 。它們之間沒有實現的關聯,但是,這兩個實體都有一個命名為genre屬性。我們希望使用此屬性加入對應於Author和Book表,並在DTO中取得結果。結果應包含Author實體,並且僅包含Book中的title屬性。好吧,當您在此處的情況下,強烈建議您避免透過建構函式表達式來取得DTO。此方法無法在單一SELECT中取得數據,且容易n+1。勝過它,包括使用春季預測,JPA Tuple甚至Hibernate ResultTransformer 。這些方法將在單一SELECT中獲取資料。此應用程式不做此範例。檢查取得資料所需的查詢數量。到位,請按照此處的操作:春季投影中的實體(無關聯)。
@ElementCollection描述:此應用程式是取得包含@ElementCollection屬性的DTO的範例。
要點:
@ElementCollection已載入懶惰,保持懶惰JOIN儲存庫@OrderBy訂購@ManyToMany協會中的相關實體Set描述:在@ManyToMany關聯的情況下,我們始終應該依靠Set (不在List )來映射關聯實體的集合(另一個父母側的實體)。為什麼?好吧,請參閱@manytomany關係中的優先設定而不是清單。但是,眾所周知, HashSet沒有預先定義的元素輸入順序。如果這是一個問題,那麼此應用程式依賴@OrderBy ,該ORDER BY在SQL語句中的子句中新增了訂單。資料庫將處理訂購。此外,Hibernate將透過LinkedHashSet保留訂單。
該應用程式使用兩個實體, Author和Book ,涉及懶惰的雙向多一關係。首先,我們憑標題取得一Book 。此外,我們稱getAuthors()取得本書的作者。被提取的作者按名稱下降。 The ordering is done by the database as a result of adding @OrderBy("name DESC") , and is preserved by Hibernate.
要點:
@OrderByHashSet , but doesn't provide consistency across all transition states (eg, transient state)LinkedHashSet instead of HashSet Note: Alternatively, we can use @OrderColumn . This gets materialized in an additional column in the junction table. This is needed for maintaining a permanent ordering of the related data.
Description: This is a sample application that shows how versioned ( @Version ) optimistic locking and detached entity works. Running the application will result in an optimistic locking specific exception (eg, the Spring Boot specific, OptimisticLockingFailureException ).
要點:
findById(1L) ; commit transaction and close the Persistence ContextfindById(1L) and update it; commit the transaction and close the Persistence Contextsave() and pass to it the detached entity; trying to merge ( EntityManager.merge() ) the entity will end up in an optimistic locking exception since the version of the detached and just loaded entity don't matchOptimisticLockException Shaped Via @Version Note: Optimistic locking via @Version works for detached entities as well.
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. So, running the application should end up with a Spring specific ObjectOptimisticLockingFailureException exception.
要點:
@Transactional method used for updating data| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
TransactionTemplate After OptimisticLockException Exception ( @Version ) Note: Optimistic locking via @Version works for detached entities as well.
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. When such exception occurs, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
要點:
pom.xml , add the db-util dependencyOptimisticConcurrencyControlAspect beanTransactionTemplateOptimisticLockException In Version-less Optimistic LockingNote: Version-less optimistic locking doesn't work for detached entities (do not close the Persistence Context).
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. So, running the application should end up with a Spring specific ObjectOptimisticLockingFailureException exception.
要點:
@Transactional method used for updating dataTransactionTemplate After OptimisticLockException Shaped Via Hibernate Version-less Optimistic Locking MechanismNote: Version-less optimistic locking doesn't work for detached entities (do not close the Persistence Context).
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. When such exception occur, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
要點:
pom.xml , add the db-util dependencyOptimisticConcurrencyControlAspect beanTransactionTemplateDescription: This is a sample application that shows how to take advantage of versioned optimistic locking and detached entities in HTTP long conversations. The climax consists of storing the detached entities across multiple HTTP requests. Commonly, this can be accomplished via HTTP session.
要點:
@Version@SessionAttributes for storing the detached entities Sample output (check the message caused by optimistic locking exception): 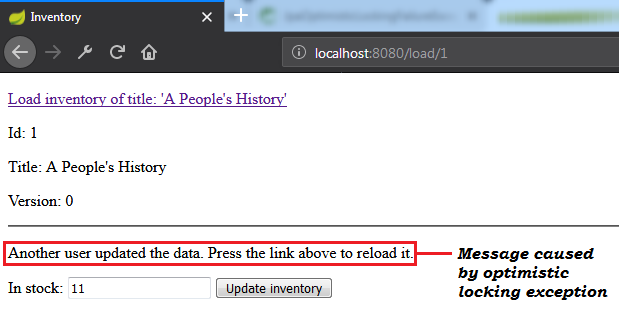
@Where Note: Rely on this approach only if you simply cannot use JOIN FETCH WHERE or @NamedEntityGraph .
Description: This application is a sample of using Hibernate @Where for filtering associations.
要點:
@Where(clause = "condition to be met") in entity (check the Author entity)Description: Batch inserts (in MySQL) in Spring Boot style.
要點:
application.properties中設定spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties設定spring.jpa.properties.hibernate.generate_statistics (只是為了檢查批次是否正常運作)application.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 進行最佳化)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_inserts=true以透過排序插入來最佳化批次IDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=false輸出範例: 
COUNT(*) OVER And Return Page<entity> Via Extra Column描述:通常,在偏移分頁中,取得資料需要一個查詢,一個用於計算記錄總數。但是,我們可以透過嵌套在主SELECT中的SELECT COUNT查詢中的單一資料庫中來取得此資訊。更好的是,對於支援視窗函數的資料庫供應商,有一個解決方案依賴COUNT(*) OVER() SELECT COUNT在此應用程式中使用該視窗函數在本機查詢中使用MySQL 8。 fetches data as Page<entity> via Spring Boot offset pagination, but, if the fetched data is read-only , then rely on Page<dto> as here.
要點:
PagingAndSortingRepository的儲存庫@Column(insertable = false, updatable = false)List<entity>List<entity> and Pageable to create a Page<entity>SELECT COUNT Subquery And Return List<entity> Via Extra Column Description: This application fetches data as List<entity> via Spring Boot offset pagination.觸發用於計數記錄總數的SELECT COUNT是主SELECT的子查詢。 Therefore, there will be a single database roundtrip instead of two (typically, one query is needed for fetching the data and one for counting the total number of records).
要點:
PagingAndSortingRepository的儲存庫entity , add an extra column for representing the total number of records and annotate it as @Column(insertable = false, updatable = false)SELECT COUNT subquery) into a List<entity>SELECT COUNT Subquery And Return List<projection> That Maps Entities And The Total Number Of Records Via Projection Description: This application fetches data as List<projection> via Spring Boot offset pagination. The projection maps the entity and the total number of records. This information is fetched in a single database rountrip because the SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT .因此,將有一個資料庫往返,而不是兩個(通常,取得資料需要一個查詢,一個用於計算記錄總數)。 Use this approch only if the fetched data is not read-only . Otherwise, prefer List<dto> as here.
要點:
PagingAndSortingRepository的儲存庫SELECT COUNT subquery) into a List<projection>COUNT(*) OVER And Return List<entity> Via Extra Column描述:通常,在偏移分頁中,取得資料需要一個查詢,一個用於計算記錄總數。但是,我們可以透過嵌套在主SELECT中的SELECT COUNT查詢中的單一資料庫中來取得此資訊。更好的是,對於支援視窗函數的資料庫供應商,有一個解決方案依賴COUNT(*) OVER() SELECT COUNT在此應用程式中使用該視窗函數在本機查詢中使用MySQL 8。 fetches data as List<entity> via Spring Boot offset pagination, but, if the fetched data is read-only , then rely on List<dto> as here.
要點:
PagingAndSortingRepository的儲存庫entity , add an extra column for representing the total number of records and annotate it as @Column(insertable = false, updatable = false)COUNT(*) OVER subquery) into a List<entity>| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
SELECT COUNT Subquery And Return Page<entity> Via Extra Column Description: This application fetches data as Page<entity> via Spring Boot offset pagination. Use this only if the fetched data will be modified. Otherwise, fetch Page<dto> as here.觸發用於計數記錄總數的SELECT COUNT是主SELECT的子查詢。因此,將有一個資料庫往返,而不是兩個(通常,取得資料需要一個查詢,一個用於計算記錄總數)。
要點:
PagingAndSortingRepository的儲存庫@Column(insertable = false, updatable = false)List<entity>List<entity> and Pageable to create a Page<entity>SELECT COUNT Subquery And Return Page<projection> That Maps Entities And The Total Number Of Records Via Projection Description: This application fetches data as Page<projection> via Spring Boot offset pagination. The projection maps the entity and the total number of records. This information is fetched in a single database rountrip because the SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT .
要點:
PagingAndSortingRepository的儲存庫List<projection>List<projection> and Pageable to create a Page<projection>COUNT(*) OVER And Return Page<dto>描述:通常,在偏移分頁中,取得資料需要一個查詢,一個用於計算記錄總數。但是,我們可以透過嵌套在主SELECT中的SELECT COUNT查詢中的單一資料庫中來取得此資訊。更好的是,對於支援視窗函數的資料庫供應商,有一個解決方案依賴COUNT(*) OVER() SELECT COUNT在此應用程式中使用該視窗函數在本機查詢中使用MySQL 8。 This application return a Page<dto> .
要點:
PagingAndSortingRepository的儲存庫List<dto>List<dto> and Pageable to create a Page<dto>例子:
Slice<entity> / Slice<dto> Via fetchAll / fetchAllDto故事:Spring Boot提供了基於偏移的內建分頁機制,機制會傳回Page或Slice 。這些API中的每一個都代表資料頁面和一些元資料。主要差異是Page包含記錄總數,而Slice只能判斷是否有另一個頁面。對於Page ,Spring Boot提供了findAll()能夠將其作為參數作為Pageable和/或Specification或Example方法。 In order to create a Page that contains the total number of records, this method triggers an SELECT COUNT extra-query next to the query used to fetch the data of the current page .這可能是效能懲罰,因為每次我們請求頁面時都會觸發SELECT COUNT查詢。為了避免這種超等格,彈簧靴提供了一個更輕鬆的API,即Slice API。使用Slice而不是Page消除了此額外的SELECT COUNT查詢的需求,並返回頁面(記錄)和一些元數據,而沒有記錄總數。因此,儘管Slice不知道記錄的總數,但它仍然可以判斷當前一頁之後是否有另一個頁面,或者是最後一頁。問題在於, Slice可用於包含SQL的查詢, WHERE條款(包括使用查詢建構器機制的條款中的條款),但它不適用於findAll() 。此方法仍將傳回Page而非Slice因此SELECT COUNT查詢是為Slice<T> findAll(...); 。
Workaround: The trick is to simply define a method named fetchAll() that uses JPQL and Pageable to return Slice<entity> , and a method named fetchAllDto() that uses JPQL and Pageable as well to return Slice<dto> . So, avoid naming the method findAll() .
使用範例:
public Slice<Author> fetchNextSlice(int page, int size) {
return authorRepository.fetchAll(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "age")));
}
public Slice<AuthorDto> fetchNextSliceDto(int page, int size) {
return authorRepository.fetchAllDto(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "age")));
}

Description: This application is a proof of concept for using Spring Projections(DTO) and inclusive full joins written in native SQL (for MySQL).
要點:
Author and Book in a lazy bidirectional @OneToMany relationship)resources/data-mysql.sql )AuthorNameBookTitle.java )EhCache ) Description: This application is a sample of declaring an immutable entity. Moreover, the immutable entity will be stored in Second Level Cache via EhCache implementation.
Key points of declaring an immutable entity:
@Immutable (org.hibernate.annotations.Immutable)hibernate.cache.use_reference_entries configuration to trueDataSourceBuilder如果您使用spring-boot-starter-jdbc或spring-boot-starter-data-jpa “啟動器”,則自動獲得對Hikaricp的依賴
注意:調整連接池參數的最佳方法包括使用Vlad Mihalcea使用Flexy Pool。透過Flexy池,您可以找到維持連線池高效能的最佳設定。
描述:這是一個透過DataSourceBuilder設定Hikaricp的開球應用程式。 jdbcUrl設定為MySQL資料庫。為了進行測試,該應用程式使用ExecutorService服務來模擬並髮用戶。檢查Hickaricp報告顯示連線池狀態。
要點:
@Bean that returns the DataSource programmatically輸出樣本:
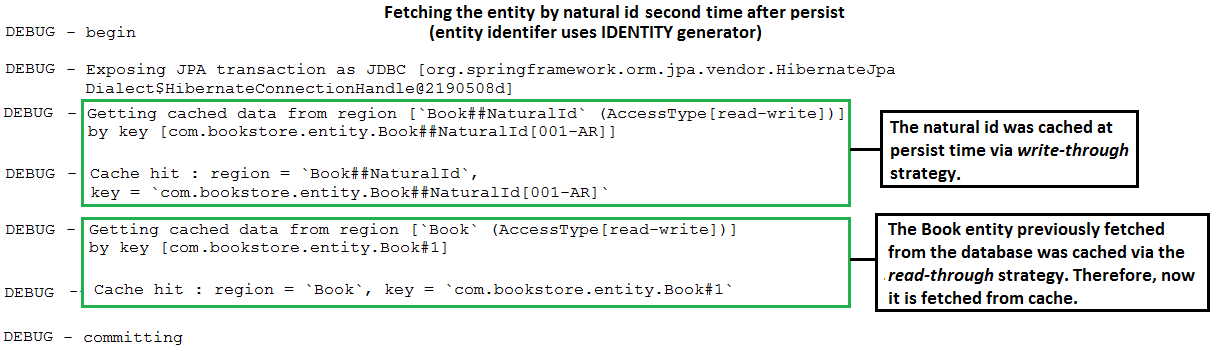
@NaturalIdCache For Skipping The Entity Identifier Retrieval Description: This is a SpringBoot - MySQL application that maps a natural business key using Hibernate @NaturalId . This implementation allows us to use @NaturalId as it was provided by Spring. Moreover, this application uses Second Level Cache ( EhCache ) and @NaturalIdCache for skipping the entity identifier retrieval from the database.
要點:
EhCache )@NaturalIdCache for caching natural ids@Cache(usage = CacheConcurrencyStrategy.READ_WRITE, region = "Book") for caching entites as well Output sample (for MySQL with IDENTITY generator, @NaturalIdCache and @Cache ): 
@PostLoad Description: This application is an example of calculating a non-persistent property of an entity based on the persistent entity attributes. In this case, we will use JPA, @PostLoad .
要點:
@Transient@PostLoad that calculates this non-persistent property based on the persistent entity attributes@Generated Description: This application is an example of calculating an entity persistent property at INSERT and/or UPDATE time via Hibernate, @Generated .
要點:
Calculate at INSERT time:
@Generated(value = GenerationTime.INSERT)@Column(insertable = false) Calculate at INSERT and UPDATE time:
@Generated(value = GenerationTime.ALWAYS)@Column(insertable = false, updatable = false)Further, apply:
方法一:
columnDefinition element of @Column to specify as an SQL query expression the formula for calculating the persistent property方法二:
CREATE TABLE Note: In production, you should not rely on columnDefinition . You should disable hibernate.ddl-auto (by omitting it) or set it to validate , and add the SQL query expression in CREATE TABLE (in this application, check the discount column in CREATE TABLE , file schema-sql.sql ). Nevertheless, not even schema-sql.sql is ok in production. The best way is to rely on Flyway or Liquibase.
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
@Formula Description: This application is an example of calculating a non-persistent property of an entity based on the persistent entity attributes. In this case, we will use Hibernate, @Formula .
要點:
@Transient@Formula@Formula add the SQL query expression that calculates this non-persistent property based on the persistent entity attributescreated , createdBy , lastModified And lastModifiedBy In Entities Via HibernateNote: The same thing can be obtained via Spring Data JPA auditing as here.
Description: This application is an example of adding in an entity the fields, created , createdBy , lastModified and lastModifiedBy via Hibernate support. These fields will be automatically generated/populated.
要點:
abstract class (eg, BaseEntity ) annotated with @MappedSuperclassabstract class, define a field named created and annotate it with the built-in @CreationTimestamp annotationabstract class, define a field named lastModified and annotate it with the built-in @UpdateTimestamp annotationabstract class, define a field named createdBy and annotate it with the @CreatedBy annotationabstract class, define a field named lastModifiedBy and annotate it with the @ModifiedBy annotation@CreatedBy annotation via AnnotationValueGeneration@ModifiedBy annotation via AnnotationValueGenerationcreated , createdBy , lastModified and lastModifiedBy will extend the BaseEntityschema-mysql.sql )Description: Auditing is useful for maintaining history records. This can later help us in tracking user activities.
要點:
@Audited@AuditTable to rename the table used for auditingValidityAuditStrategy for fast database reads, but slower writes (slower than the default DefaultAuditStrategy )spring.jpa.hibernate.ddl-auto or set it to validate for avoiding schema generated from JPA annotationsschema-mysql.sql and provide the SQL statements needed by Hibernate Enversspring.jpa.properties.org.hibernate.envers.default_catalog for MySQL or spring.jpa.properties.org.hibernate.envers.default_schema for the restDataSource Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is a kickoff for setting Flyway and MySQL DataSource programmatically.
要點:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateDataSource and Flyway programmaticallypostgres And Schema public Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of migrating a PostgreSQL database via Flyway for the default database postgres and schema public .
要點:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties , set the JDBC URL as follows: jdbc:postgresql://localhost:5432/postgresclasspath:db/migrationV1.1__Description.sql , V1.2__Description.sql , ...postgres And Schema Created Via spring.flyway.schemas Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of migrating a schema ( bookstore ) created by Flyway via spring.flyway.schemas in the default postgres database. In this case, the entities should be annotated with @Table(schema = "bookstore") .
要點:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties , set the JDBC URL as follows: jdbc:postgresql://localhost:5432/postgresapplication.properties , add spring.flyway.schemas=bookstore , where bookstore is the schema that should be created by Flyway in the postgres database (feel free to add your own database name)@Table(schema = "bookstore")classpath:db/migrationV1.1__Description.sql , V1.2__Description.sql , ...DataSource Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is a kickoff for setting Flyway and PostgreSQL DataSource programmatically.
要點:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateDataSource and Flyway programmatically Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of auto-creating and migrating two databases in MySQL using Flyway. In addition, each data source uses its own HikariCP connection pool. In case of MySQL, where a database is the same thing with schema, we create two databases, authorsdb and booksdb .
要點:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties , configure the JDBC URL for booksdb as jdbc:mysql://localhost:3306/booksdb?createDatabaseIfNotExist=true and for authorsdb as jdbc:mysql://localhost:3306/authorsdb?createDatabaseIfNotExist=trueapplication.properties , set spring.flyway.enabled=false to disable default behaviorDataSource , one for booksdb and one for authorsdbFlywayDataSource , one for booksdb and one for authorsdbEntityManagerFactory , one for booksdb and one for authorsdbbooksdb , place the migration SQLs files in dbmigrationbooksdbauthorsdb , place the migration SQLs files in dbmigrationauthorsdbhi/lo Algorithm And External Systems Issue Description: This is a Spring Boot sample that exemplifies how the hi/lo algorithm may cause issues when the database is used by external systems as well. Such systems can safely generate non-duplicated identifiers (eg, for inserting new records) only if they know about the hi/lo presence and its internal work. So, better rely on pooled or pooled-lo algorithm which doesn't cause such issues.
要點:
SEQUENCE產生器類型(例如,在PostgreSQL中)hi/lo Author.javahi/loNEXTVAL('hilo_sequence') and is not aware of hi/lo presence and/or behavior) Output sample: Running this application should result in the following error:
ERROR: duplicate key value violates unique constraint "author_pkey"
Detail: Key (id)=(2) already exists.
pooled Algorithm Note: Rely on pooled-lo or pooled especially if, beside your application, external systems needs to insert rows in your tables. Don't rely on hi/lo since, in such cases, it may cause errors resulted from generating duplicated identifiers.
Description: This is a Spring Boot example of using the pooled algorithm. The pooled is an optimization of hi/lo . This algorithm fetched from the database the current sequence value as the top boundary identifier (the current sequence value is computed as the previous sequence value + increment_size ). This way, the application will use in-memory identifiers generated between the previous top boundary exclusive (aka, lowest boundary) and the current top boundary inclusive.
要點:
SEQUENCE產生器類型(例如,在PostgreSQL中)pooled algorithm as in Author.java entitypooledNEXTVAL('hilo_sequence') and is not aware of pooled presence and/or behavior) Conclusion: In contrast to the classical hi/lo algorithm, the Hibernate pooled algorithm doesn't cause issues to external systems that wants to interact with our tables. In other words, external systems can concurrently insert rows in the tables relying on pooled algorithm. Nevertheless, old versions of Hibernate can raise exceptions caused by INSERT statements triggered by external systems that uses the lowest boundary as identifier. This is a good reason to update to Hibernate latest versions (eg, Hibernate 5.x), which have fixed this issue.
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
pooled-lo Algorithm Note: Rely on pooled-lo or pooled especially if, beside your application, external systems needs to insert rows in your tables. Don't rely on hi/lo since, in such cases, it may cause errors resulted from generating duplicated identifiers.
Description: This is a Spring Boot example of using the pooled-lo algorithm. The pooled-lo is an optimization of hi/lo similar with pooled . Only that, the strategy of this algorithm fetches from the database the current sequence value and use it as the in-memory lowest boundary identifier. The number of in-memory generated identifiers is equal to increment_size .
要點:
SEQUENCE產生器類型(例如,在PostgreSQL中)pooled-lo algorithm as in Author.java entitypooled-loNEXTVAL('hilo_sequence') and is not aware of pooled-lo presence and/or behavior)@BatchSize Description: This application uses Hibernate specific @BatchSize at class/entity-level and collection-level. Consider Author and Book entities invovled in a bidirectional-lazy @OneToMany association.
First use case fetches all Author entities via a SELECT query. Further, calling the getBooks() method of the first Author entity will trigger another SELECT query that initializes the collections of the first three Author entities returned by the previous SELECT query. This is the effect of @BatchSize at Author 's collection-level.
Second use case fetches all Book entities via a SELECT query. Further, calling the getAuthor() method of the first Book entity will trigger another SELECT query that initializes the authors of the first three Book entities returned by the previous SELECT query. This is the effect of @BatchSize at Author class-level.
Note: Fetching associated collections in the same query with their parent can be done via JOIN FETCH or entity graphs as well. Fetching children with their parents in the same query can be done via JOIN FETCH , entity graphs and JOIN as well.
要點:
Author and Book are in a lazy relationship (eg, @OneToMany bidirectional relationship)Author entity is annotated with @BatchSize(size = 3)Author 's collection is annotated with @BatchSize(size = 3)@NamedEntityGraph ) In Spring Boot Note: In a nutshell, entity graphs (aka, fetch plans ) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity's related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans . To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType .
Load Graph , javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated according to their specified or default FetchType .
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic ( @Basic ) attributes. 。更多詳細資訊請參閱此處。
Description: This is a sample application of using entity graphs in Spring Boot.
要點:
Author and Book , involved in a lazy bidirectional @OneToMany associationAuthor entity use the @NamedEntityGraph to define the entity graph (eg, load in a single SELECT the authors and the associatated books)AuthorRepositry rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous step Note: In a nutshell, entity graphs (aka, fetch plans ) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity's related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans . To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType .
Load Graph , javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated according to their specified or default FetchType .
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic ( @Basic ) attributes. 。更多詳細資訊請參閱此處。
Description: This is a sample application of using entity sub-graphs in Spring Boot. There is one example based on @NamedSubgraph and one based on the dot notation (.) in an ad-hoc entity graph .
要點:
Author , Book and Publisher ( Author and Book are involved in a lazy bidirectional @OneToMany relationship, Book and Publisher are also involved in a lazy bidirectional @OneToMany relationship; between Author and Publisher there is no relationship) Using @NamedSubgraph
Author entity define an entity graph via @NamedEntityGraph ; load the authors and the associatated books and use @NamedSubgraph to define a sub-graph for loading the publishers associated with these booksAuthorRepository rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous stepUsing the dot notation (.)
PublisherRepository define an ad-hoc entity graph that fetches all publishers with associated books, and further, the authors associated with these books (eg, @EntityGraph(attributePaths = {"books.author"}) . Note: In a nutshell, entity graphs (aka, fetch plans ) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity's related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans . To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType .
Load Graph , javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated according to their specified or default FetchType .
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic ( @Basic ) attributes. 。更多詳細資訊請參閱此處。
Description: This is a sample application of defining ad-hoc entity graphs in Spring Boot.
要點:
Author and Book , involved in a lazy bidirectional @OneToMany relationshipSELECT the authors and the associatated booksAuthorRepository rely on Spring @EntityGraph(attributePaths = {"books"}) annotation to indicate the ad-hoc entity graph@Basic Attributes In Hibernate And Spring Boot Note: In a nutshell, entity graphs (aka, fetch plans ) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity's related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans . To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType .
Load Graph , javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated according to their specified or default FetchType .
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic ( @Basic ) attributes. In other words, by default, attributes are annotated with @Basic which rely on the default fetch policy. The default fetch policy is FetchType.EAGER . These attributes are also loaded in case of fetch graph even if they are not explicitly specified via @NamedAttributeNode . Annotating the basic attributes that should not be fetched with @Basic(fetch = FetchType.LAZY) it is not enough. Both, fetch graph and load graph will ignore these settings as long as we don't add bytecode enhancement as well.
The main drawback consists of the fact the these basic attributes are fetched LAZY by all other queries (eg, findById() ) not only by the queries using the entity graph, and most probably, you will not want this behavior.
Description: This is a sample application of using entity graphs with @Basic attributes in Spring Boot.
要點:
Author and Book , involved in a lazy bidirectional @OneToMany associationAuthor entity use the @NamedEntityGraph to define the entity graph (eg, load the authors names (only the name basic attribute; ignore the rest) and the associatated books)@Basic(fetch = FetchType.LAZY)AuthorRepository rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous stepSoftDeleteRepository In Spring Boot ApplicationNote: Spring Data built-in support for soft deletes is discussed in DATAJPA-307.
Description: This application is an example of implementing soft deletes in Spring Data style via a repository named, SoftDeleteRepository .
要點:
abstract class, BaseEntity , annotated with @MappedSuperclassBaseEntity define a flag-field named deleted (default this field to false or in other words, not deleted)BaseEntity classs@NoRepositoryBean named SoftDeleteRepository and extend JpaRepositorySoftDeleteRepository輸出範例:
SKIP_LOCKED In MySQL 8 Description: This application is an example of how to implement concurrent table based queue via SKIP_LOCKED in MySQL 8. SKIP_LOCKED can skip over locks achieved by other concurrent transactions, therefore is a great choice for implementing job queues. In this application, we run two concurrent transactions. The first transaction will lock the records with ids 1, 2 and 3. The second transaction will skip the records with ids 1, 2 and 3 and will lock the records with ids 4, 5 and 6.
要點:
Book entity)BookRepository setup @Lock(LockModeType.PESSIMISTIC_WRITE)BookRepository use @QueryHint to setup javax.persistence.lock.timeout to SKIP_LOCKEDorg.hibernate.dialect.MySQL8Dialect dialectSKIP_LOCKEDSKIP_LOCKED In PostgreSQL Description: This application is an example of how to implement concurrent table based queue via SKIP_LOCKED in PostgreSQL. SKIP_LOCKED can skip over locks achieved by other concurrent transactions, therefore is a great choice for implementing job queues. In this application, we run two concurrent transactions. The first transaction will lock the records with ids 1, 2 and 3. The second transaction will skip the records with ids 1, 2 and 3 and will lock the records with ids 4, 5 and 6.
要點:
Book entity)BookRepository setup @Lock(LockModeType.PESSIMISTIC_WRITE)BookRepository use @QueryHint to setup javax.persistence.lock.timeout to SKIP_LOCKEDorg.hibernate.dialect.PostgreSQL95Dialect dialectSKIP_LOCKEDJOINED Description: This application is a sample of JPA Join Table inheritance strategy ( JOINED )
要點:
@Inheritance(strategy=InheritanceType.JOINED)@PrimaryKeyJoinColumn| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
TABLE_PER_CLASS Description: This application is a sample of JPA Table-per-class inheritance strategy ( TABLE_PER_CLASS )
要點:
IDENTITY generator@Inheritance(strategy=InheritanceType.TABLE_PER_CLASS)@MappedSuperclass Description: This application is a sample of using the JPA @MappedSuperclass .
要點:
abstract , and is annotated with @MappedSuperclass@MappedSuperclass is the proper alternative to the JPA table-per-class inheritance strategyNote: Hibernate5Module is an add-on module for Jackson JSON processor which handles Hibernate datatypes; and specifically aspects of lazy-loading .
Description: By default, in Spring Boot, the Open Session in View anti-pattern is enabled. Now, imagine a lazy relationship (eg, @OneToMany ) between two entities, Author and Book (an author has associated more books).接下來,REST 控制器端點取得沒有關聯Book Author 。但是,視圖(更準確地說,傑克遜)也強制延遲加載相關Book 。 Since OSIV will supply the already opened Session , the Proxy initializations take place successfully.
Of course, the correct decision is to disable OSIV by setting it to false , but this will not stop Jackson to try to force the lazy initialization of the associated Book entities. Running the code again will result in an exception of type: Could not write JSON: failed to lazily initialize a collection of role: com.bookstore.entity.Author.books, could not initialize proxy - no Session; nested exception is com.fasterxml.jackson.databind.JsonMappingException: failed to lazily initialize a collection of role: com.bookstore.entity.Author.books, could not initialize proxy - no Session .
Well, among the Hibernate5Module features we have support for dealing with this aspect of lazy loading and eliminate this exception. Even if OSIV will continue to be enabled (not recommended), Jackson will not use the Session opened via OSIV.
要點:
pom.xml@Bean that returns an instance of Hibernate5ModuleAuthor bean with @JsonInclude(Include.NON_EMPTY) to exclude null or what is considered empty from the returned JSON Note: The presence of Hibernate5Module instructs Jackson to initialize the lazy associations with default values (eg, a lazy associated collection will be initialized with null ). Hibernate5Module doesn't work for lazy loaded attributes. For such case consider this item.
profileSQL=true In MySQL Description: View the prepared statement binding parameters via profileSQL=true in MySQL.
要點:
application.properties append logger=Slf4JLogger&profileSQL=true to the JDBC URL (eg, jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=true&logger=Slf4JLogger&profileSQL=true )輸出樣本: 
Description: This application is an example of shuffling small results sets. DO NOT USE this technique for large results sets, since is extremely expensive.
要點:
SELECT query and append to it ORDER BY RAND()RAND() (eg, in PostgreSQL is random() ) Description: Commonly, deleting a parent and the associated children via CascadeType.REMOVE and/or orphanRemoval=true involved several SQL statements (eg, each child is deleted in a dedicated DELETE statement). When the number of entities is significant, this is far from being efficient, therefore other approaches should be employed.
Consider Author and Book in a bidirectional-lazy @OneToMany association. This application exposes the best way to delete the parent(s) and the associated children in four scenarios listed below. These approaches relies on bulk deletions, therefore they are not useful if you want the deletions to take advantage of automatic optimistic locking mechanisms (eg, via @Version ):
Best way to delete author(s) and the associated books via bulk deletions when:
Author is in Persistent Context, no BookAuthor are in the Persistent Context, no BookAuthor and the associated Book are in Persistent ContextAuthor or Book is in Persistent Context Note: The most efficient way to delete all entities via a bulk deletion can be done via the built-in deleteAllInBatch() .
Description: Bulk operations (updates and deletes) are faster than batching, can benefit from indexing, but they have three main drawbacks:
@Version is ignored), therefore the lost updates are not prevented (it is advisable to signal these updates by explicitly incrementing version (if any is present))CascadeType.REMOVE ) and orphanRemoval This application provides examples of bulk updates for Author and Book entities (between Author and Book there is a bidirectional lazy @OneToMany association). Both, Author and Book , has a version field.
@OneToMany And Prefer Bidirectional @OneToMany Relationship Description: As a rule of thumb, unidirectional @OneToMany association is less efficient than the bidirectional @OneToMany or the unidirectional @ManyToOne associations. This application is a sample that exposes the DML statements generated for reads, writes and removal operations when the unidirectional @OneToMany mapping is used.
要點:
@OneToMany is less efficient than bidirectional @OneToMany association@OrderColumn come with some optimizations for removal operations but is still less efficient than bidirectional @OneToMany association@JoinColumn eliminates the junction table but is still less efficient than bidirectional @OneToMany associationSet instead of List or bidirectional @OneToMany with @JoinColumn relationship (eg, @ManyToOne @JoinColumn(name = "author_id", updatable = false, insertable = false) ) still performs worse than bidirectional @OneToMany associationWHERE / HAVING Clause Description: This application is an example of using subqueries in JPQL WHERE clause (you can easily use it in HAVING clause as well).
要點:
Keep in mind that subqueries and joins queries may or may not be semantically equivalent (joins may returns duplicates that can be removed via DISTINCT ).
Even if the Execution Plan is specific to the database, historically speaking joins are faster than subqueries among different databases, but this is not a rule (eg, the amount of data may significantly influence the results). Of course, do not conclude that subqueries are just a replacement for joins that doesn't deserve attention. Tuning subqueries can increases their performance as well, but this is an SQL wide topic. So, benchmark!基準!基準!
As a rule of thumb, prefer subqueries only if you cannot use joins, or if you can prove that they are faster than the alternative joins.
WHERE Part Of JPQL Query And JPA 2.1 Note: Using SQL functions in SELECT part (not in WHERE part) of the query can be done as here.
Description: Starting with JPA 2.1, a JPQL query can call SQL functions in the WHERE part via function() . This application is an example of calling the MySQL, concat_ws function, but user defined (custom) functions can be used as well.
要點:
function()| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
Description: This application is an example of calling a MySQL stored procedure that returns a value (eg, an Integer ).
要點:
@NamedStoredProcedureQuery to shape the stored procedure in the entity@Procedure in repository Description: This application is an example of calling a MySQL stored procedure that returns a result set. The application fetches entities (eg, List<Author> ) and DTO (eg, List<AuthorDto> ).
要點:
EntiyManager since Spring Data @Procedure will not workDescription: This application is an example of calling a MySQL stored procedure that returns a result set (entity or DTO) via a native query.
要點:
@Query(value = "{CALL FETCH_AUTHOR_BY_GENRE (:p_genre)}", nativeQuery = true)JdbcTemplate Note: Most probably you'll like to process the result set via BeanPropertyRowMapper as here. This is less verbose than the approach used here. Nevertheless, this approach is useful to understand how the result set looks like.
Description: This application is an example of calling a MySQL stored procedure that returns a result set via JdbcTemplate .
要點:
JdbcTemplate and SimpleJdbcCallDescription: This application is an example of retrieving the database auto-generated primary keys.
要點:
getId()JdbcTemplateSimpleJdbcInsert描述:當子實體可以透過對其父實體的引用( @ManyToOne或@OneToOne關聯)進行持久化時,Hibernate 代理程式會很有用。 In such cases, fetching the parent entity from the database (execute the SELECT statement) is a performance penalty and a pointless action. Hibernate can set the underlying foreign key value for an uninitialized proxy. This topic is discussed here.
A proxy can be unproxied via Hibernate.unproxy() . This method is available starting with Hibernate 5.2.10.
要點:
JpaRepository#getOne()Hibernate.unproxy()Boolean To Yes/No Via AttributeConverter Description: This application is an example of converting a Boolean to Yes / No strings via AttributeConverter . This kind of conversions are needed when we deal with legacy databases that connot be changed. In this case, the legacy database stores the booleans as Yes / No .
要點:
AttributeConverter@OManyToOne Note: The @ManyToOne association maps exactly to the one-to-many table relationship. The underlying foreign key is under child-side control in unidirectional or bidirectional relationship.
Description: This application shows that using only @ManyToOne is quite efficient. On the other hand, using only @OneToMany is far away from being efficient. Always, prefer bidirectional @OneToMany or unidirectional @ManyToOne . Consider two entities, Author and Book in a unidirectional @ManyToOne relationship.
要點:
JOIN FETCH And Pageable Pagination Description: Trying to combine JOIN FETCH / LEFT JOIN FETCH and Pageable results in an exception of type org.hibernate.QueryException: query specified join fetching, but the owner of the fetched association was not present in the select list . This application is a sample of how to avoid this exception.
要點:
countQuery Note: Fixing the above exception will lead to an warning of type HHH000104, firstResult / maxResults specified with collection fetch; applying in memory! 。 If this warning is a performance issue, and most probably it is, then follow by reading here.
Description: HHH000104 is a Hibernate warning that tell us that pagination of a result set is tacking place in memory. For example, consider the Author and Book entities in a lazy-bidirectional @OneToMany association and the following query:
@Transactional
@Query(value = "SELECT a FROM Author a LEFT JOIN FETCH a.books WHERE a.genre = ?1",
countQuery = "SELECT COUNT(a) FROM Author a WHERE a.genre = ?1")
Page<Author> fetchWithBooksByGenre(String genre, Pageable pageable);
Calling fetchWithBooksByGenre() works fine only that the following warning is signaled: HHH000104: firstResult / maxResults specified with collection fetch; applying in memory! Obviously, having pagination in memory cannot be good from performance perspective. This application implement a solution for moving pagination at database-level.
要點:
Page of entities in read-write or read-only modeSlice or List of entities in read-write or read-only mode| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
@Transactional(readOnly=true) Actually Do Description: This application is meant to reveal what is the difference between @Transactional(readOnly = false) and @Transactional(readOnly = true) . In a nuthsell, readOnly = false (default) fetches entites in read-write mode (managed). Before Spring 5.1, readOnly = true just set FlushType.MANUAL/NEVER , therefore the automatic dirty checking mechanism will not take action since there is no flush. In other words, Hibernate keep in the Persistent Context the fetched entities and the hydrated (loaded) state. By comparing the entity state with the hydrated state, the dirty checking mechanism can decide to trigger UPDATE statements in our behalf. But, the dirty checking mechanism take place at flush time, therefore, without a flush, the hydrated state is kept in Persistent Context for nothing, representing a performance penalty. Starting with Spring 5.1, the read-only mode is propagated to Hibernate, therefore the hydrated state is discarded immediately after loading the entities. Even if the read-only mode discards the hydrated state the entities are still loaded in the Persistent Context, therefore, for read-only data, relying on DTO (Spring projection) is better.
要點:
readOnly = false load data in read-write mode (managed)readOnly = true discard the hydrated state (starting with Spring 5.1)Description: This application is an example of getting the current database transaction id in MySQL. Only read-write database transactions gets an id in MySQL. Every database has a specific query for getting the transaction id. Here it is a list of these queries.
要點:
SELECT tx.trx_id FROM information_schema.innodb_trx tx WHERE tx.trx_mysql_thread_id = connection_id() Description: This application is a sample of inspecting the Persistent Context content via org.hibernate.engine.spi.PersistenceContext .
要點:
SharedSessionContractImplementorPersistenceContext API Description: This application is an example of using the Hibernate SPI, org.hibernate.integrator.spi.Integrator for extracting tables metadata.
要點:
org.hibernate.integrator.spi.Integrator and override integrate() method to return metadata.getDatabase()Integrator via LocalContainerEntityManagerFactoryBean@ManyToOne Relationship To A SQL Query Via The Hibernate @JoinFormula Description: This application is an example of mapping the JPA @ManyToOne relationship to a SQL query via the Hibernate @JoinFormula annotation. We start with two entities, Author and Book , involved in a unidirectional @ManyToOne relationship. Each book has a price. While we fetch a book by id (let's call it book A ), we want to fetch another book B of the same author whose price is the next smaller price in comparison with book A price.
要點:
B is done via @JoinFormulaDescription: This application is an example of fetching a read-only MySQL database view in a JPA immutable entity.
要點:
data-mysql.sql fileGenreAndTitleView.javaDescription: This application is an example of updating, inserting and deleting data in a MySQL database view. Every update/insert/delete will automatically update the contents of the underlying table(s).
要點:
data-mysql.sql fileWITH CHECK OPTION Description: This application is an example of preventing inserts/updates of a MySQL view that are not visible through this view via WITH CHECK OPTION . In other words, whenever you insert or update a row of the base tables through a view, MySQL ensures that the this operation is conformed with the definition of the view.
要點:
WITH CHECK OPTION to the viewjava.sql.SQLException: CHECK OPTION failed 'bookstoredb.author_anthology_view Description: This application is an example of assigning a database temporary sequence of values to rows via the window function, ROW_NUMBER() . This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
要點:
ROW_NUMBER() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by ROW_NUMBER as wellROW_NUMBER() window function輸出樣本: 
Description: This application is an example of finding top N rows of every group.
要點:
ROW_NUMBER() window function輸出樣本: 
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
ROW_NUMBER() Window Function Description: This application is an example of using ROW_NUMBER() (and COUNT(*) OVER() for counting all elements) window function to implement pagination.
要點:
ROW_NUMBER()Page or Slice , we return it as List , therefore Pageable is not used@Transactional annotation is being ignored Description: This application is an example of fixing the case when @Transactional annotation is ignored. Most of the time, this annotation is ignored in the following scenarios:
@Transactional was added to a private , protected or package-protected method@Transactional was added to a method defined in the same class where it is invoked要點:
@Transactional methods therepublic@Transactional methods from other services Description: This is a Spring Boot example of using the hi/lo algorithm and a custom implementation of SequenceStyleGenerator for generating custom sequence IDs (eg, A-0000000001 , A-0000000002 , ...).
要點:
SequenceStyleGenerator and override the configure() and generate() methodsClob And Blob To byte[] And String Description: This application is an example of mapping Clob and Blob as byte[] and String .
要點:
LOB Locators Clob And Blob Description: This application is an example of mapping to JDBC's LOB locators Clob and Blob .
要點:
SINGLE_TABLE Inheritance Hierarchy Description: This application is a sample of fetching a certain subclass from a SINGLE_TABLE inheritance hierarchy. This is useful when the dedicated repository of the subclass doesn't automatically add in the WHERE clause a dtype based condition for fetching only the needed subclass.
要點:
WHERE clause a TYPE check@NaturalId Description: This is a SpringBoot application that defines a @ManyToOne relationship that doesn't reference a primary key column. It references a Hibernate @NaturalId column.
要點:
@JoinColumn(referencedColumnName = "natural_id_column")Specification Description: This application is an example of implementing an advanced search via Specification API. Mainly, you can give the search filters to a generic Specification and fetch the result set. Pagination is supported as well. You can chain expressions via logical AND and OR to create compound filters. Nevertheless, there is room for extensions to add brackets support (eg, (x AND y) OR (x AND z) ), more operations, conditions parser and so on and forth.
要點:
SpecificationSpecification Query Fetch Joins Description: This application contains two examples of how to define JOIN in Specification to emulate JPQL join-fetch operations.
要點:
SELECT statements and the pagination is done in memory (very bad!)SELECT statements but the pagination is done in the databaseJOIN is defined in a Specification implementationNote: You may also like to read the recipe, "How To Enrich DTO With Virtual Properties Via Spring Projections"
描述:透過 Spring Data Projections (DTO) 從資料庫中僅取得所需的資料。 The projection interface is defined as a static interface (can be non- static as well) in the repository interface.
要點:
List<projection>正確查詢LIMIT ) - here, we can use query builder mechanism built into Spring Data repository infrastructure注意:使用投影並不限於使用 Spring 資料儲存庫基礎架構中內建的查詢建構器機制。我們也可以透過 JPQL 或本機查詢來取得投影。例如,在此應用程式中我們使用 JPQL。
輸出範例(選擇前 2 行;僅選擇“姓名”和“年齡”):
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
Description: Consider an entity named Review . This entity defines three @ManyToOne relationships to Book , Article and Magazine . A review can be associated with either a book, a magazine or an article. To validate this constraint, we can rely on Bean Validation as in this application.
要點:
null@JustOneOfMany ) added at class-level to the Review entityTRIGGER ) Description: This application uses EnumType.ORDINAL and EnumType.STRING for mapping Java enum type to database. As a rule of thumb, strive to keep the data types as small as possible (eg, for EnumType.ORDINAL use TINYINT/SMALLINT , while for EnumType.STRING use VARCHAR(max_needed_bytes) ). Relying on EnumType.ORDINAL should be more efficient but is less expressive than EnumType.STRING .
要點:
EnumType.ORDINAL set @Column(columnDefinition = "TINYINT") )enum To Database Via AttributeConverter Description: This application maps a Java enum via AttributeConverter . In other words, it maps the enum values HORROR , ANTHOLOGY and HISTORY to the integers 1 , 2 and 3 and viceversa. This allows us to set the column type as TINYINT/SMALLINT which is less space-consuming than VARCHAR(9) needed in this case.
要點:
AttributeConverter@Converter the corresponding entity fieldenum To PostgreSQL enum Type Description: This application maps a Java enum type to PostgreSQL enum type.
要點:
EnumTypeEnumType via package-info.java@Typeenum To PostgreSQL enum Type Via Hibernate Types Library Description: This application maps a Java enum type to PostgreSQL enum type via Hibernate Types library.
要點:
pom.xml@TypeDef to specify the needed type class@Type Description: Hibernate Types is a library of extra types not supported by Hibernate Core by default. This is a Spring Boot application that uses this library to persist JSON data (JSON Java Object ) in a MySQL json column and for querying JSON data from the MySQL json column to JSON Java Object . Updates are supported as well.
要點:
pom.xml中的依賴性@TypeDef to map typeClass to JsonStringType Description: Hibernate Types is a library of extra types not supported by Hibernate Core by default. This is a Spring Boot application that uses this library to persist JSON data (JSON Java Object ) in a PostgreSQL json column and for querying JSON data from the PostgreSQL json column to JSON Java Object . Updates are supported as well.
要點:
pom.xml中的依賴性@TypeDef to map typeClass to JsonBinaryTypeOPTIMISTIC_FORCE_INCREMENT Description: This application is a sample of how OPTIMISTIC_FORCE_INCREMENT works in MySQL. This is useful when you want to increment the version of the locked entity even if this entity was not modified. Via OPTIMISTIC_FORCE_INCREMENT the version is updated (incremented) at the end of the currently running transaction.
要點:
Chapter (which uses @Version )Modification entityModification (child-side) and Chapter (parent-side) there is a lazy unidirectional @ManyToOne associationINSERT statement against the modification table, therefore the chapter table will not be modified by editorsChapter entity version is needed to ensure that modifications are applied sequentially (the author and editor are notified if a modificaton was added since the chapter copy was loaded)version is forcibly increased at each modification (this is materialized in an UPDATE triggered against the chapter table at the end of the currently running transaction)OPTIMISTIC_FORCE_INCREMENT in the corresponding repositoryObjectOptimisticLockingFailureExceptionPESSIMISTIC_FORCE_INCREMENT Description: This application is a sample of how PESSIMISTIC_FORCE_INCREMENT works in MySQL. This is useful when you want to increment the version of the locked entity even if this entity was not modified. Via PESSIMISTIC_FORCE_INCREMENT the version is updated (incremented) immediately (the entity version update is guaranteed to succeed immediately after acquiring the row-level lock). The incrementation takes place before the entity is returned to the data access layer.
要點:
Chapter (which uses @Version )Modification entityModification (child-side) and Chapter (parent-side) there is a lazy unidirectional @ManyToOne associationINSERT statement against the modification table, therefore the chapter table will not be modified by editorsChapter entity version is needed to ensure that modifications are applied sequentially (each editor is notified if a modificaton was added since his chapter copy was loaded and he must re-load the chapter)version is forcibly increased at each modification (this is materialized in an UPDATE triggered against the chapter table immediately after aquiring the row-level lock)PESSIMISTIC_FORCE_INCREMENT in the corresponding repositoryOptimisticLockException and one that will lead to QueryTimeoutException Note: Pay attention to the MySQL dialect: MySQL5Dialect (MyISAM) doesn't support row-level locking, MySQL5InnoDBDialect (InnoDB) acquires row-level lock via FOR UPDATE (timeout can be set), MySQL8Dialect (InnoDB) acquires row-level lock via FOR UPDATE NOWAIT .
PESSIMISTIC_READ And PESSIMISTIC_WRITE Works In MySQL Description: This application is an example of using PESSIMISTIC_READ and PESSIMISTIC_WRITE in MySQL. In a nutshell, each database system defines its own syntax for acquiring shared and exclusive locks and not all databases support both types of locks. Depending on Dialect , the syntax can vary for the same database as well (Hibernate relies on Dialect for chosing the proper syntax). In MySQL, MySQL5Dialect doesn't support locking, while InnoDB engine ( MySQL5InnoDBDialect and MySQL8Dialect ) supports shared and exclusive locks as expected.
要點:
@Lock(LockModeType.PESSIMISTIC_READ) and @Lock(LockModeType.PESSIMISTIC_WRITE) on query-levelTransactionTemplate to trigger two concurrent transactions that read and write the same row| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
PESSIMISTIC_WRITE Works With UPDATE / INSERT And DELETE Operations Description: This application is an example of triggering UPDATE , INSERT and DELETE operations in the context of PESSIMISTIC_WRITE locking against MySQL. While UPDATE and DELETE are blocked until the exclusive lock is released, INSERT depends on the transaction isolation level. Typically, even with exclusive locks, inserts are possible (eg, in PostgreSQL). In MySQL, for the default isolation level, REPEATABLE READ , inserts are prevented against a range of locked entries, but, if we switch to READ_COMMITTED , then MySQL acts as PostgreSQL as well.
要點:
SELECT with PESSIMISTIC_WRITE to acquire an exclusive lockUPDATE , INSERT or DELETE on the rows locked by Transaction AUPDATE , DELETE and INSERT + REPEATABLE_READ , Transaction B is blocked until it timeouts or Transaction A releases the exclusive lockINSERT + READ_COMMITTED , Transaction B can insert in the range of rows locked by Transaction A even if Transaction A is holding an exclusive lock on this range Note: Do not test transaction timeout via Thread.sleep() !這不行! Rely on two transactions and exclusive locks or even better rely on SQL sleep functions (eg, MySQL, SELECT SLEEP(n) seconds, PostgreSQL, SELECT PG_SLEEP(n) seconds). Most RDBMS supports a sleep function flavor.
Description: This application contains several approaches for setting a timeout period for a transaction or query. The timeout is signaled by a specific timeout exception (eg, .QueryTimeoutException ). After timeout, the transaction is rolled back. You can see this in the database (visually or query) and on log via a message of type: Initiating transaction rollback; Rolling back JPA transaction on EntityManager [SessionImpl(... <open>)] .
要點:
spring.transaction.default-timeout in seconds (see, application.properties )@Transactional(timeout = n) in secondsjavax.persistence.query.timeout hint in millisecondsorg.hibernate.timeout hint in seconds Note: If you are using TransactionTemplate then the timeout can be set via TransactionTemplate.setTimeout(n) in seconds.
@Embeddable Description: This application is a proof of concept of how to define a composite key via @Embeddable and @EmbeddedId . This application uses two entities, Author and Book involved in a lazy bidirectional @OneToMany association. The identifier of Author is composed by name and age via AuthorId class. The identifier of Book is just a regular auto-generated numeric value.
要點:
AuthorId ) is publicSerializableequals() and hashCode()@IdClass Description: This application is a proof of concept of how to define a composite key via @IdClass . This application uses two entities, Author and Book involved in a lazy bidirectional @OneToMany association. The identifier of Author is composed by name and age via AuthorId class. The identifier of Book is just a typical auto-generated numeric value.
要點:
AuthorId ) is publicSerializableequals() and hashCode() Note : The @IdClass can be useful when we cannot modify the compsite key class. Otherwise, rely on @Embeddable .
@Embeddable Composite Primary Key Description: This application is a proof of concept of how to define a relationship in an @Embeddable composite key. The composite key is AuthorId and it belongs to the Author class.
要點:
AuthorId ) is publicSerializableequals() and hashCode() Description: This is a SpringBoot application that loads multiple entities by id via a @Query based on the IN operator and via the Hibernate 5 MultiIdentifierLoadAccess interface.
要點:
IN operator in a @Query simply add the query in the proper repositoryMultiIdentifierLoadAccess in Spring Data style provide the proper implementationMultiIdentifierLoadAccess implementation allows us to load entities by multiple ids in batches and by inspecting or not the current Persistent Context (by default, the Persistent Context is not inspected to see if the entities are already loaded or not) Description: This application is a sample of fetching all attributes of an entity ( Author ) as a Spring projection (DTO). Commonly, a DTO contains a subset of attributes, but, sometimes we need to fetch the whole entity as a DTO. In such cases, we have to pay attention to the chosen approach. Choosing wisely can spare us from performance penalties.
要點:
List<Object[]> or List<AuthorDto> via a JPQL of type SELECT a FROM Author a WILL fetch the result set as entities in Persistent Context as well - avoid this approachList<Object[]> or List<AuthorDto> via a JPQL of type SELECT a.id AS id, a.name AS name, ... FROM Author a will NOT fetch the result set in Persistent Context - this is efficientList<Object[]>或List<AuthorDto> via a native SQL of type SELECT id, name, age, ... FROM author will NOT fetch the result set in Persistent Context - but, this approach is相當慢List<Object[]> via Spring Data query builder mechanism WILL fetch the result set in Persistent Context - avoid this approachList<AuthorDto> via Spring Data query builder mechanism will NOT fetch the result set in Persistent ContextfindAll() method) should be considered after JPQL with explicit list of columns to be fetched and query builder mechanism@ManyToOne Or @OneToOne Associations Description: This application fetches a Spring projection including the @ManyToOne association via different approaches. It can be easily adapted for @OneToOne association as well.
要點:
Description: This application inspect the Persistent Context content during fetching Spring projections that includes collections of associations. In this case, we focus on a @OneToMany association. Mainly, we want to fetch only some attributes from the parent-side and some attributes from the child-side.
Description: This application is a sample of reusing an interface-based Spring projection. This is useful to avoid defining multiple interface-based Spring projections in order to cover a range of queries that fetches different subsets of fields.
要點:
@JsonInclude(JsonInclude.Include.NON_DEFAULT) annotation to avoid serialization of default fields (eg, fields that are not available in the current projection and are null - these fields haven't been fetched in the current query)null fields)| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
Description: This application is a sample of using dynamic Spring projections.
要點:
<T> List<T> findByGenre(String genre, Class<T> type); )說明:此應用程式是透過 MySQL 中的EntityManager進行批次插入的範例。這樣您就可以輕鬆控制目前交易內持久性上下文(一級快取)的flush()和clear()週期。這是透過 Spring Boot saveAll(Iterable<S> entities)不可能實現的,因為此方法對每個交易執行一次刷新。另一個優點是您可以呼叫persist()而不是merge() - 這是由 SpringBoot saveAll(Iterable<S> entities)和save(S entity)在幕後使用的。
Moreover, this example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
要點:
application.properties中設定spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties設定spring.jpa.properties.hibernate.generate_statistics (只是為了檢查批次是否正常運作)application.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 進行最佳化)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_inserts=true以透過排序插入來最佳化批次IDENTITY將導致插入批次被停用spring.jpa.properties.hibernate.cache.use_second_level_cache=false停用二級緩存輸出範例:
Description: This is a Spring Boot application that reads a relatively big JSON file (200000+ lines) and inserts its content in MySQL via batching using ForkJoinPool , JdbcTemplate and HikariCP.
要點:
json typeListrewriteBatchedStatements=true -> this setting will force sending the batched statements in a single request;cachePrepStmts=true -> enable caching and is useful if you decide to set prepStmtCacheSize , prepStmtCacheSqlLimit , etc as well; without this setting the cache is disableduseServerPrepStmts=true -> this way you switch to server-side prepared statements (may lead to signnificant performance boost); moreover, you avoid the PreparedStatement to be emulated at the JDBC Driver level;...?cachePrepStmts=true&useServerPrepStmts=true&rewriteBatchedStatements=true&createDatabaseIfNotExist=trueStopWatch to measure the time needed to transfer the file into the databasecitylots.zip in the current location; this is the big JSON file collected from Internet;DatasourceProxyBeanPostProcessor.java component by uncomment the line, // @Component ; This is needed because this application relies on DataSource-Proxy (for details, see the following item)CompletableFuture Description: This application is a sample of using CompletableFuture for batching inserts. This CompletableFuture uses an Executor that has the number of threads equal with the number of your computer cores. Usage is in Spring style.
描述:假設我們在Author和Book實體之間有一對多的關係。當我們拯救作者時,我們也保存了他的書,這要歸功於所有級聯/持久。我們希望使用批次技術建立一堆帶有書籍的作者,並將其保存在資料庫(例如MySQL資料庫)中。預設情況下,這將導致每位作者和每個作者的書籍(作者的一批,一批書籍,另一批作者,作者的另一批,另一批書籍,等等)。為了批處作者和書籍,我們需要像本應用程式一樣訂購插入物。
Moreover, this example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
要點:
application.properties the following property: spring.jpa.properties.hibernate.order_inserts=true Example without ordered inserts:
Example with ordered inserts:
Description: Batch inserts (in MySQL) in Spring Boot style. This example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches.
要點:
application.properties中設定spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties設定spring.jpa.properties.hibernate.generate_statistics (只是為了檢查批次是否正常運作)application.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 進行最佳化)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_inserts=true以透過排序插入來最佳化批次IDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=false輸出範例:
IN Clause Parameter Padding Description: This application is an example of using Hibernate IN cluase parameter padding. This way we can reduce the number of Execution Plans. Mainly, Hibernate is padding parameters as follows:
要點:
application.properties set spring.jpa.properties.hibernate.query.in_clause_parameter_padding=true描述:透過 Spring Data Projections (DTO) 從資料庫中僅取得所需的資料。 In this case, via class-based projections.
要點:
equals() and hashCode() only for the columns that should be fetched from the databaseList<projection>正確查詢LIMIT )注意:使用投影並不限於使用 Spring 資料儲存庫基礎架構中內建的查詢建構器機制。我們也可以透過 JPQL 或本機查詢來取得投影。例如,在此應用程式中我們使用 JPQL。
輸出範例(選擇前 2 行;僅選擇“姓名”和“年齡”):
說明:透過 MySQL 中的 Hibernate 會話級批次(Hibernate 5.2 或更高版本)進行批次插入。 This example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
要點:
application.properties設定spring.jpa.properties.hibernate.generate_statistics (只是為了檢查批次是否正常運作)application.properties中設定 JDBC URL 並使用rewriteBatchedStatements=true (針對 MySQL 進行最佳化)application.properties中使用cachePrepStmts=true設置 JDBC URL(啟用緩存,如果您決定設置prepStmtCacheSize 、 prepStmtCacheSqlLimit等,則很有用;如果沒有此設置,緩存將被禁用)application.properties中使用useServerPrepStmts=true設定 JDBC URL(這樣您可以切換到伺服器端準備好的語句(可能會導致效能顯著提升))spring.jpa.properties.hibernate.order_inserts=true以透過排序插入來最佳化批次IDENTITY將導致插入批次被停用Session是透過EntityManager#unwrap(Session.class)解包取得的Session#setJdbcBatchSize(Integer size)設定並透過Session#getJdbcBatchSize()取得spring.jpa.properties.hibernate.cache.use_second_level_cache=false停用二級緩存輸出範例:
Description: This application highlights the difference betweeen loading entities in read-write vs. read-only mode. If you plan to modify the entities in a future Persistent Context then fetch them as read-only in the current Persistent Context.
要點:
Note: If you never plan to modify the fetched result set then use DTO (eg, Spring projection), not read-only entities.
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
Note: Domain events should be used with extra-caution! The best practices for using them are revealed in my book, Spring Boot Persistence Best Practices.
Description: Starting with Spring Data Ingalls release publishing domain events by aggregate roots becomes easier. Entities managed by repositories are aggregate roots. In a Domain-Driven Design application, these aggregate roots usually publish domain events. Spring Data provides an annotation @DomainEvents you can use on a method of your aggregate root to make that publication as easy as possible. A method annotated with @DomainEvents is automatically invoked by Spring Data whenever an entity is saved using the right repository. Moreover, Spring Data provides the @AfterDomainEventsPublication annotation to indicate the method that should be automatically called for clearing events after publication. Spring Data Commons comes with a convenient template base class ( AbstractAggregateRoot ) to help to register domain events and is using the publication mechanism implied by @DomainEvents and @AfterDomainEventsPublication . The events are registered by calling the AbstractAggregateRoot.registerEvent() method. The registered domain events are published if we call one of the save methods (eg, save() ) of the Spring Data repository and cleared after publication.
This is a sample application that relies on AbstractAggregateRoot and its registerEvent() method. We have two entities, Book and BookReview involved in a lazy-bidirectional @OneToMany association. A new book review is saved in CHECK status and a CheckReviewEvent is published. This event handler is responsible to check the review grammar, content, etc and switch the review status from CHECK to ACCEPT or REJECT and propagate the new status to the database. So, this event is registered before saving the book review in CHECK status and is published automatically after we call the BookReviewRepository.save() method. After publication, the event is cleared.
要點:
AbstractAggregateRoot and provide a method for registering eventsCheckReviewEvent ), but more can be registeredCheckReviewEventHandler in an asynchronous manner via @AsyncDescription: This application is an example of testing the Hibernate Query Plan Cache (QPC). Hibernate QPC is enabled by default and, for entity queries (JPQL and Criteria API), the QPC has a size of 2048, while for native queries it has a size of 128. Payaltention to alter the native value al has a sizes 128。應用。 If the number of exectued queries is higher than the QPC size (especially for entity queries) then you will start to experiment performance penalties caused by entity compilation time added for each query execution.
In this application, you can adjust the QPC size in application.properties . Mainly, there are 2 JPQL queries and a QPC of size 2. Switching from size 2 to size 1 will cause the compilation of one JPQL query at each execution. Measuring the times for 5000 executions using a QPC of size 2, respectively 1 reveals the importance of QPC in terms of time.
要點:
hibernate.query.plan_cache_max_sizehibernate.query.plan_parameter_metadata_max_sizeDescription: This is a SpringBoot application that enables Hibernate Second Level Cache and EhCache provider. It contains an example of caching entities and an example of caching a query result.
要點:
EhCache )@CacheHINT_CACHEABLE Description: This is a SpringBoot application representing a kickoff application for Spring Boot caching and EhCache .
要點:
EhCacheSqlResultSetMapping And NamedNativeQuery注意:如果您想要依賴{EntityName}.{RepositoryMethodName}命名約定來簡單地在儲存庫中建立與本機命名查詢同名的介面方法,請跳過此應用程式並選取此應用程式。
Description: This is a sample application of using SqlResultSetMapping , NamedNativeQuery and EntityResult for fetching single entity and multiple entities as List<Object[]> .
要點:
SqlResultSetMapping , NamedNativeQuery and EntityResult Description: This is a SpringBoot application that loads multiple entities by id via a @Query based on the IN operator and via Specification .
要點:
IN operator in a @Query simply add the query in the proper repositorySpecification rely on javax.persistence.criteria.Root.in()ResultTransformer Description: Fetching more read-only data than needed is prone to performance penalties.使用 DTO 允許我們僅提取所需的資料。 Sometimes, we need to fetch a DTO made of a subset of properties (columns) from a parent-child association. For such cases, we can use SQL JOIN that can pick up the desired columns from the involved tables. But, JOIN returns an List<Object[]> and most probably you will need to represent it as a List<ParentDto> , where a ParentDto instance has a List<ChildDto> . For such cases, we can rely on a custom Hibernate ResultTransformer . This application is a sample of writing a custom ResultTransformer .
要點:
ResultTransformer interface Description: Is a common scenario to have a big List and to need to chunk it in multiple smaller List of given size. For example, if we want to employee a concurrent batch implementation we need to give to each thread a sublist of items. Chunking a list can be done via Google Guava, Lists.partition(List list, int size) method or Apache Commons Collections, ListUtils.partition(List list, int size) method. But, it can be implemented in plain Java as well. This application exposes 6 ways to do it. The trade-off is between the speed of implementation and speed of execution. For example, while the implementation relying on grouping collector is not performing very well, it is quite simple and fast to write it.
要點:
Chunk.java class which relies on the built-in List.subList() method Time-performance trend graphic for chunking 500, 1_000_000, 10_000_000 and 20_000_000 items in lists of 5 items: 
Description: Consider the Book and Chapter entities. A book has a maximum accepted number of pages ( book_pages ) and the author should not exceed this number. When a chapter is ready for review, the author is submitting it. At this point, the publisher should check that the currently total number of pages doesn't exceed the allowed book_pages :
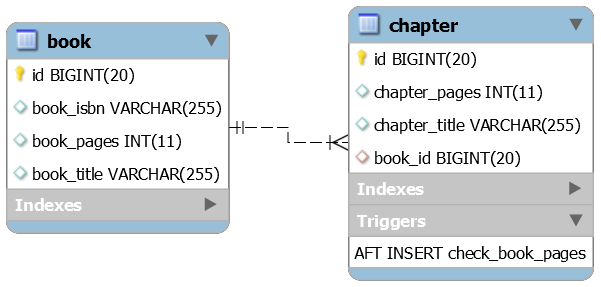
This kind of checks or constraints are easy to implement via database triggers. This application relies on a MySQL trigger to empower our complex contraint ( check_book_pages ).
要點:
AFTER INSERT OR AFTER UPDATE ) Description: This application is an example of using Spring Data Query By Example (QBE) to check if a transient entity exists in the database. Consider the Book entity and a Spring controller that exposes an endpoint as: public String checkBook(@Validated @ModelAttribute Book book, ...) . Beside writting an explicit JPQL, we can rely on Spring Data Query Builder mechanism or, even better, on Query By Example (QBE) API. In this context, QBE API is quite useful if the entity has a significant number of attributes and:
要點:
BookRepository extends QueryByExampleExecutor<S extends T> boolean exists(Example<S> exmpl) with the proper probe (an entity instance populated with the desired fields values)ExampleMatcher which defines the details on how to match particular fields Note: Do not conclude that Query By Example (QBE) defines only the exists() method. Check out all methods here.
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
@Transactional Description: This application is meant to highlight that the best place to use @Transactional for user defined query-methods is in repository interface, and afterwards, depending on situation, on service-methods level.
要點:
JOINED Inheritance Strategy And Visitor Design Pattern Description: This application is an example of using JPA JOINED inheritance strategy and Visitor pattern.
要點:
JOINED Inheritance Strategy And Strategy Design Pattern Description: This application is an example of using JPA JOINED inheritance strategy and Strategy pattern.
要點:
Description: This folder holds several applications that shows how each Spring transaction propagation works.
要點:
GenerationType.AUTO And UUID Identifiers Description: This application is an example of using the JPA GenerationType.AUTO for assigning automatically UUID identifiers.
要點:
BINARY(16) columnDescription: This application is an example of manually assigning UUID identifiers.
要點:
BINARY(16) columnuuid2 For Generating UUID Identifiers Description: This application is an example of using the Hibernate RFC 4122 compliant UUID generator, uuid2 .
要點:
BINARY(16) columnDescription: This Spring Boot application is a sample that reveals how Hibernate session-level repeatable reads works. Persistence Context guarantees session-level repeatable reads.看看它是如何工作的。
要點:
TransactionTemplateNote: For a detailed explanation of this application consider my book, Spring Boot Persistence Best Practices
hibernate.enable_lazy_load_no_trans Description: This application is an example of using Hibernate-specific hibernate.enable_lazy_load_no_trans . Check out the application log to see how transactions and database connections are used.
要點:
hibernate.enable_lazy_load_no_trans Description: This application is an example of cloning entities. The best way to achieve this goal relies on copy-constructors. This way we can control what we copy. Here we use a bidirectional-lazy @ManyToMany association between Author and Book .
要點:
Author (only the genre ) and associate the corresponding booksAuthor (only the genre ) and clone the books as well| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
UPDATE Statement Only The Modified Columns Via Hibernate @DynamicUpdate Description: This application is an example of using the Hibernate-specific, @DynamicUpdate . By default, even if we modify only a subset of columns, the triggered UPDATE statements will include all columns. By simply annotating the corresponding entity at class-level with @DynamicUpdate the generated UPDATE statement will include only the modified columns.
要點:
UPDATE for different subsets of columns via JDBC statements caching (each triggered UPDATE string will be cached and reused accordingly)Description: This application is an example of logging execution time for a repository query-method.
要點:
RepositoryProfiler ) Description: This application is an example of using the TransactionSynchronizationAdapter for overriding beforeCommit() , beforeCompletion() , afterCommit() and afterCompletion() callbacks globally (application-level) and at method-level.
要點:
TransactionProfiler )TransactionSynchronizationManager.registerSynchronization()SqlResultSetMapping And NamedNativeQuery Using {EntityName}.{RepositoryMethodName} Naming Convention描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。 In this application we rely on SqlResultSetMapping , NamedNativeQuery and the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
要點:
SqlResultSetMapping 、 NamedNativeQuerySqlResultSetMapping And NamedNativeQuery Using {EntityName}.{RepositoryMethodName} Naming Convention Description: This is a sample application of using SqlResultSetMapping , NamedNativeQuery and EntityResult for fetching single entity and multiple entities as List<Object[]> . In this application we rely on the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
要點:
SqlResultSetMapping , NamedNativeQuery and EntityResult@NamedQuery And Spring Projection (DTO) Description: This application is an example of combining JPA named queries @NamedQuery and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
要點:
@NamedNativeQuery And Spring Projection (DTO) Description: This application is an example of combining JPA named native queries @NamedNativeQuery and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
要點:
Description: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. Spring Data allows us to write our named (native) queries in a typical *.properties file inside the META-INF folder of your classpath. This way, we avoid modifying our entities. This application shows you how to do it.
Warning: Cannot use native queries with dynamic sorting ( Sort ). Nevertheless, using Sort in named queries works fine. Moreover, using Sort in Pageable works fine for both, named queries and named native queries. At least this is how it behave in Spring Boot 2.2.2. From this point of view, this approach is better than using @NamedQuery / @NamedNativeQuery or orm.xml file.
要點:
META-INF/jpa-named-queries.properties{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementationorm.xml File Description: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. Spring Data allows us to write our named (native) queries in a typical orm.xml file inside the META-INF folder of your classpath. This way, we avoid modifying our entities. This application shows you how to do it.
Warning: Pay attention that, via this approach, we cannot use named (native) queries with dynamic sorting ( Sort ). Using Sort in Pageable is ignored, therefore you need to explicitly add ORDER BY in the queries. At least this is how it behave in Spring Boot 2.2.2. A better approach relies on using a properties file for listing the named (native) queries. In this case, dynamic Sort works for named queries, but not for named native queries. Using Sort in Pageable works as expected in named (native) queries.
要點:
META-INF/orm.xml{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementation Description: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. This application shows you how to do it.
Warning: Pay attention that, via this approach, we cannot use named (native) queries with dynamic sorting ( Sort ). Using Sort in Pageable is ignored, therefore you need to explicitly add ORDER BY in the queries. At least this is how it behave in Spring Boot 2.2.2. A better approach relies on using a properties file for listing the named (native) queries. In this case, dynamic Sort works for named queries, but not for named native queries. Using Sort in Pageable works as expected in named (native) queries. And, you don't need to modify/pollute entitites with the above annotations.
要點:
@NamedQuery and @NamedNativeQuery annotations in entity classes{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementationSort and Pageable| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
Description: This application is an example of combining JPA named queries listed in a properties file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
要點:
jpa-named-queries.properties ) in a folder named META-INF the application classpath Description: This application is an example of combining JPA named native queries listed in a properties file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
要點:
jpa-named-queries.properties ) in a folder named META-INF the application classpathorm.xml File And Spring Projection (DTO) Description: This application is an example of combining JPA named queries listed in orm.xml file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
要點:
orm.xml file in a folder named META-INF the application classpathorm.xml File And Spring Projection (DTO) Description: This application is an example of combining JPA named native queries listed in orm.xml file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
要點:
orm.xml file in a folder named META-INF the application classpathorm.xml描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。 In this application we rely on named native queries and result set mapping via orm.xml and the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
要點:
<named-native-query/> and <sql-result-set-mapping/> to map the native query to AuthorDto class
Description: This application is a proof of concept for using Spring Projections(DTO) and cross joins written via JPQL and native SQL (for MySQL).
要點:
Book and Formatresources/data-mysql.sql )BookTitleAndFormatType.java )JdbcTemplate And BeanPropertyRowMapper Description: This application is an example of calling a MySQL stored procedure that returns a result set via JdbcTemplate and BeanPropertyRowMapper .
要點:
JdbcTemplate , SimpleJdbcCall and BeanPropertyRowMapper@EntityListeners Description: This application is a sample of using the JPA @MappedSuperclass and @EntityListeners with JPA callbacks.
要點:
Book , is not an entity, it can be abstract , and is annotated with @MappedSuperclass and @EntityListeners(BookListener.class)BookListener defines JPA callbacks (eg, @PrePersist )Book is persisted, loaded, updated, etc the corresponding JPA callbacks are called@Fetch(FetchMode.JOIN) May Causes N+1 Issues Advice: Always evaluate JOIN FETCH and entities graphs before deciding to use FetchMode.JOIN . The FetchMode.JOIN fetch mode always triggers an EAGER load so the children are loaded when the parents are. Beside this drawback, FetchMode.JOIN may return duplicate results. You'll have to remove the duplicates yourself (eg storing the result in a Set ). But, if you decide to go with FetchMode.JOIN at least pay attention to avoid N+1 issues discussed below.
Note: Let's assume three entities, Author , Book and Publisher . Between Author and Book there is a bidirectional-lazy @OneToMany association. Between Author and Publisher there is a unidirectional-lazy @ManyToOne . Between Book and Publisher there is no association.
Now, we want to fetch a book by id ( BookRepository#findById() ), including its author, and the author's publisher. In such cases, using Hibernate fetch mode, @Fetch(FetchMode.JOIN) works as expected. Using JOIN FETCH or entity graph is also working as expected.
Next, we want to fetch all books ( BookRepository#findAll() ), including their authors, and the authors publishers. In such cases, using Hibernate fetch mode, @Fetch(FetchMode.JOIN) will cause N+1 issues. It will not trigger the expected JOIN . In this case, using JOIN FETCH or entity graph should be used.
要點:
@Fetch(FetchMode.JOIN) doesn't work for query-methods@Fetch(FetchMode.JOIN) works in cases that fetches the entity by id (primary key) like using EntityManager#find() , Spring Data, findById() , findOne() .RANK() Description: This application is an example of assigning a database temporary ranking of values to rows via the window function, RANK() . This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
要點:
RANK() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by RANK() as wellRANK() window function輸出樣本: 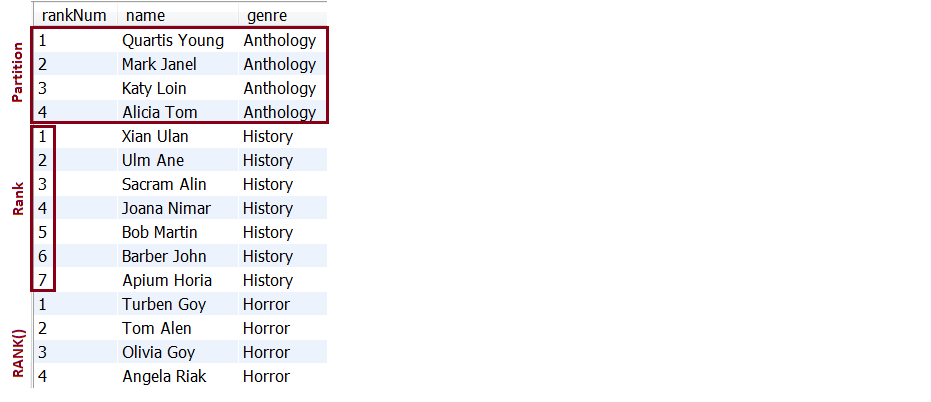
| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
DENSE_RANK() Description: This application is an example of assigning a database temporary ranking of values to rows via the window function, DENSE_RANK() . In comparison with the RANK() window function, DENSE_RANK() avoid gaps within partition. This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
要點:
DENSE_RANK() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by DENSE_RANK() as wellDENSE_RANK() window function輸出樣本: 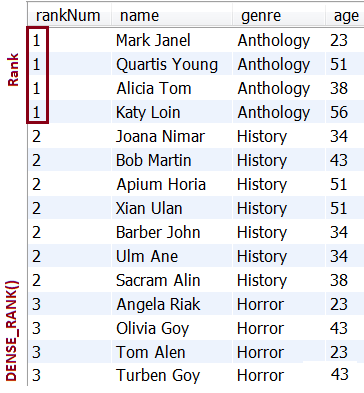
NTILE(N) Description: This application is an example of distributing the number of rows in the specified (N) number of groups via the window function, NTILE(N) . This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
要點:
NTILE() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by NTILE() as wellNTILE() window function輸出樣本: 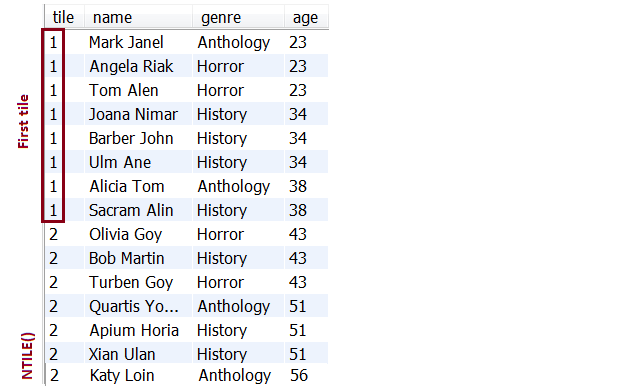
Description: Spring Data comes with the Query Builder mechanism for JPA that is capable to interpret a query method name (known as a derived query) and convert it into a SQL query in the proper dialect. This is possible as long as we respect the naming conventions of this mechanism. Beside the well-known query of type find... , Spring Data supports derived count queries and derived delete queries.
要點:
count... (eg, long countByGenre(String genre) ) - Spring Data will generate a SELECT COUNT(...) FROM ... querydelete... or remove... and returns long (eg, long deleteByGenre(String genre) ) - Spring Data will trigger first a SELECT to fetch entities in the Persistence Context, and, afterwards, it triggers a DELETE for each entity that must be deleteddelete... or remove... and returns List<entity> (eg, List<Author> removeByGenre(String genre) ) - Spring Data will trigger first a SELECT to fetch entities in the Persistence Context, and, afterwards, it triggers a DELETE for each entity that must be deletedDescription: Property expressions can refer to a direct property of the managed entity. However, you can also define constraints by traversing nested properties. This application is a sample of traversing nested properties for fetching entities and DTOs.
要點:
Author has several Book and each book has several Review (between Author and Book there is a bidirectional-lazy @oneToMany association, and, between Book and Review there is also a bidirectional-lazy @OneToMany association)Review and we want to know the Author of the Book that has received this ReviewAuthorRepository the following query that will be processed by the Spring Data Query Builder mechanism: Author findByBooksReviews(Review review);SELECT with two LEFT JOINbooks.reviews . The algorithm starts by interpreting the entire part ( BooksReviews ) as the property and checks the domain class for a property with that name (uncapitalized). If the algorithm succeeds, it uses that property. If not, the algorithm splits up the source at the camel case parts from the right side into a head and a tail and tries to find the corresponding property — in our example, Books and Reviews . If the algorithm finds a property with that head, it takes the tail and continues building the tree down from there, splitting the tail up in the way just described. If the first split does not match, the algorithm moves the split point to the left and continues.Author class has an booksReview property as well. The algorithm would match in the first split round already, choose the wrong property, and fail (as the type of booksReview probably has no code property).要解決這種歧義,您可以在方法名稱中使用 _ 來手動定義遍歷點。 So our method name would be as follows: Author findByBooks_Reviews(Review review);Note: Fetching read-only data should be done via DTO, not managed entities. But, there is no tragedy to fetch read-only entities in a context as follows:
@Transactional(readOnly = true)Under these circumstances, let's tackle a common case that I saw quite a lot. There is even an SO answer about it (don't do this):

Description: Let's assume that Author and Book are involved in a bidirectional-lazy @OneToMany association. Imagine an user that loads a certain Author (without the associated Book ). The user may be interested or not in the Book , therefore, we don't load them with the Author . If the user is interested in the Book then he will click a button of type, View books . Now, we have to return the List<Book> associated to this Author .
So, at first request (query), we fetch an Author . The Author is detached. At second request (query), we want to load the Book associated to this Author . But, we don't want to load the Author again (for example, we don't care about lost updates of Author ), we just want to load the associated Book in a single SELECT . A common (not recommended) approach is to load the Author again (eg, via findById(author.getId()) ) and call the author.getBooks() . But, this end up in two SELECT statements. One SELECT for loading the Author , and another SELECT after we force the collection initialization. We force collection initialization because it will not be initialize if we simply return it. In order to trigger the collection initialization the developer call books.size() or he rely on Hibernate.initialize(books); 。
But, we can avoid such solution by relying on an explicit JPQL or Query Builder property expressions. This way, there will be a single SELECT and no need to call size() or Hibernate.initialize();
要點:
This item is detailed in my book, Spring Boot Persistence Best Practices.
Description: Behind the built-in Spring Data save() there is a call of EntityManager#persist() or EntityManager#merge() . It is important to know this aspect in several cases. Among this cases, we have the entity update case (simple update or update batching).
Consider Author and Book involved in a bidirectional-lazy @OneToMany association. And, we load an Author , detach it, update it in the detached state, and save it to the database via save() method. Calling save() will come with the following two issues resulting from calling merge() behind the scene:
SELECT (merge) and one UPDATESELECT will contain a LEFT OUTER JOIN to fetch the associated Book as well (we don't need the books!) How about triggering only the UPDATE instead of this? The solution relies on calling Session#update() . Calling Session.update() requires to unwrap the Session via entityManager.unwrap(Session.class) .
要點:
Session.update() will trigger only the UPDATE (there is no SELECT )Session.update() works with versioned optimistic locking mechanism as well (so, lost updates are prevented)Streamable Description: This application is a sample of fetching Streamable<entity> and Streamable<dto> . But, more important, this application contains three examples of how to not use Streamable . It is very tempting and comfortable to fetch a Streamable result set and chop it via filter() , map() , flatMap() , and so on until we obtain only the needed data instead of writing a query (eg, JPQL) that fetches exactly the needed result set from the database. Mainly, we just throw away some of the fetched data to keep only the needed data. But, is not advisable to follow such practices because fetching more data than needed can cause significant performance penalties.
Moreover, pay attention to combining two or more Streamable via the and() method. The returned result may be different from what you are expecting to see. Each Streamable produces a separate SQL statement and the final result set is a concatenation of the intermediate results sets (prone to duplicate values).
要點:
map() )filter() )Streamable via and() ; each Streamable produces a separate SQL statement and the final result set is a concatenation of the intermediate results sets (prone to duplicate values)Streamable Wrapper TypesDescription: A common practice consists of exposing dedicated wrappers types for collections resulted after mapping a query result set. This way, on a single query execution, the API can return multiple results. After we call a query-method that return a collection, we can pass it to a wrapper class by manually instantiation of that wrapper-class. But, we can avoid the manually instantiation if the code respects the following key points.
要點:
Streamablestatic factory method named of(…) or valueOf(…) taking Streamable as argumentDescription: JPA 2.1 come with schema generation features. This feature can setup the database or export the generated commands to a file. The parameters that we should set are:
spring.jpa.properties.javax.persistence.schema-generation.database.action : Instructs the persistence provider how to setup the database. Possible values include: none , create , drop-and-create , drop
javax.persistence.schema-generation.scripts.action : Instruct the persistence provider which scripts to create. Possible values include: none , create , drop-and-create , drop .
javax.persistence.schema-generation.scripts.create-target : Indicate the target location of the create script generated by the persistence provider. This can be as a file URL or a java.IO.Writer .
javax.persistence.schema-generation.scripts.drop-target : Indicate the target location of the drop script generated by the persistence provider. This can be as a file URL or a java.IO.Writer .
Moreover, we can instruct the persistence provider to load data from a file into the database via: spring.jpa.properties.javax.persistence.sql-load-script-source . The value of this property represents the file location and it can be a file URL or a java.IO.Writer .
要點:
application.properties Description: Sometimes, we need to write in repositories certain query-methods that return a Map instead of a List or a Set . For example, when we need a Map<Id, Entity> or we use GROUP BY and we need a Map<Group, Count> . This application shows you how to do it via default methods directly in repository.
要點:
default methods and Collectors.toMap() Description: Consider one of the JPA inheritance strategies (eg, JOINED ). Handling entities inheritance With Spring Data repositories can be done as follows:
Description: This application is a sample of logging only slow queries via Hibernate 5.4.5, hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS property.緩慢的查詢是一個查詢,其執行時間比毫秒中的特定閾值大。
要點:
application.properties add hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS輸出範例: 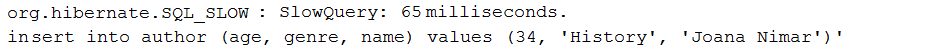
描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。 In this application we rely on JDK14 Records feature and Spring Data Query Builder Mechanism.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points: Define the AuthorDto as:
public record AuthorDto(String name, int age) implements Serializable {}
描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。 In this application we rely on JDK 14 Records, Constructor Expression and JPQL.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
要點:
Define the AuthorDto as:
public record AuthorDto(String name, int age) implements Serializable {}
ResultTransformer Description: Fetching more read-only data than needed is prone to performance penalties.使用 DTO 允許我們僅提取所需的資料。 Sometimes, we need to fetch a DTO made of a subset of properties (columns) from a parent-child association. For such cases, we can use SQL JOIN that can pick up the desired columns from the involved tables. But, JOIN returns an List<Object[]> and most probably you will need to represent it as a List<ParentDto> , where a ParentDto instance has a List<ChildDto> . For such cases, we can rely on a custom Hibernate ResultTransformer . This application is a sample of writing a custom ResultTransformer .
As DTO, we rely on JDK 14 Records. From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
要點:
AuthorDto and BookDtoResultTransformer interfaceJdbcTemplate And ResultSetExtractor描述:取得超出需求的資料很容易導致效能損失。使用 DTO 允許我們僅提取所需的資料。 In this application we rely on JDK14 Records feature, JdbcTemplate and ResultSetExtractor .
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
要點:
AuthorDto and BookDtoJdbcTemplate and ResultSetExtractorDescription: This application is a sample of using dynamic Spring projections via DTO classes.
要點:
<T> List<T> findByGenre(String genre, Class<T> type); )| 如果您需要深入了解此儲存庫中公開的效能秘訣,那麼我相信您會喜歡我的書“Spring Boot Persistence Best Practices” | 如果您需要 100 多個 Java 持久性效能問題的提示和說明,那麼「Java 持久性效能說明指南」非常適合您。 |
|
|
CompletableFuture And Return List<S> Description: This application is a sample of using CompletableFuture for batching inserts. This CompletableFuture uses an Executor that has the number of threads equal with the number of your computer cores. Usage is in Spring style. It returns List<S> :
CompletableFuture And Return List<S> (1)CompletableFuture And Return List<S> (2) Description: This application is an example of causing a database deadlock in MySQL. This application produces an exception of type: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction . However, the database will retry until transaction (A) succeeds.
要點:
SELECT with PESSIMISTIC_WRITE to acquire an exclusive lock to table authorauthor genre with success and sleeps for 10sSELECT with PESSIMISTIC_WRITE to acquire an exclusive lock to table bookbook title with success and sleeps for 10s Description: This application is a proof of concept of how to define a composite key having an explicit part ( name ) and a generated part ( authorId via SEQUENCE generator).
要點:
@IdClass Description: Sometimes we need to intercept the generated SQL that originates from Spring Data, EntityManager , Criteria API, JdbcTemplate and so on. This can be done as in this sample application. After interception, you can log, modify or even return a brand new SQL that will be executed in the end.
要點:
StatementInspector SPIapplication.properties via spring.jpa.properties.hibernate.session_factory.statement_inspector281. Force inline params in Criteria API
NOTE Use this with high precaution since you open the gate for SQL injections.
Description: Sometimes we need to force inline params in Criteria API. By default, numeric parameters are inlined, but string parameters are not.
要點:
application.properties the setting spring.jpa.properties.hibernate.criteria.literal_handling_mode as inlineDescription: Arthur Gavlyukovskiy provide a suite of Spring Boot starters for quickly integrate P6Spy, Datasource Proxy, and FlexyPool. In this example, we add Datasource Proxy, but please consider this for more details.
要點:
pom.xml , add the datasource-proxy-spring-boot-starter starterapplication.properties enable DEBUG level for loggingDescription: This application is an example of using Java records as embeddable. This is available starting with Hibernate 6.0, but it was refined to be more accessible and easy to use in Hibernate 6.2
要點:
Contact )Author ) via @EmbeddedAuthorDto )



