SmartFilteringRAG
1.0.0
您是否曾經搜尋過「古老的黑白喜劇」卻被現代動作片的轟炸所困擾?令人沮喪,對吧?這就是傳統搜尋引擎面臨的挑戰——它們常常難以理解我們查詢的細微差別,讓我們費力地瀏覽不相關的結果。
這就是智慧過濾的用武之地。想像一下,輕鬆找到您渴望的經典喜劇。
我們將深入了解智慧過濾是什麼、它是如何運作的,以及為什麼它對於建立更好的搜尋體驗至關重要。讓我們揭開這項技術背後的魔力,並探索它如何徹底改變您的搜尋方式。
向量搜尋是一種強大的工具,可以幫助電腦理解資料背後的含義,而不僅僅是單字本身。它不是匹配關鍵字,而是關注底層概念和關係。想像搜尋「狗」並獲得包括「小狗」、「犬」甚至狗的圖像的結果。這就是向量搜尋的魔力!
它是如何運作的?嗯,它將資料轉換為稱為向量的數學表示形式。這些向量就像地圖上的座標,相似的資料點在這個向量空間中距離更近。當您搜尋某些內容時,系統會找到最接近您的查詢的向量,為您提供語義相似的結果。
雖然向量搜尋在理解上下文方面非常出色,但在執行簡單的過濾任務時有時會表現不佳。例如,查找 2000 年之前發行的所有電影需要精確的過濾,而不僅僅是語義理解。這就是智慧過濾可以補充向量搜尋的地方。
雖然向量讓我們更接近理解查詢的真正含義,但用戶想要的和搜尋引擎提供的之間仍然存在差距。像「2000 年之前最早的喜劇電影」這樣的複雜搜尋查詢仍然是一個挑戰。語義搜尋可能會理解「喜劇」和「電影」的概念,但可能難以理解「最早」和「2000 年之前」的具體細節。
這就是結果開始變得混亂的地方。我們可能會混合新舊喜劇,甚至是錯誤包含的戲劇。為了真正滿足用戶,我們需要一種方法來細化這些搜尋結果並使其更加精確。這就是預過濾器發揮作用的地方。
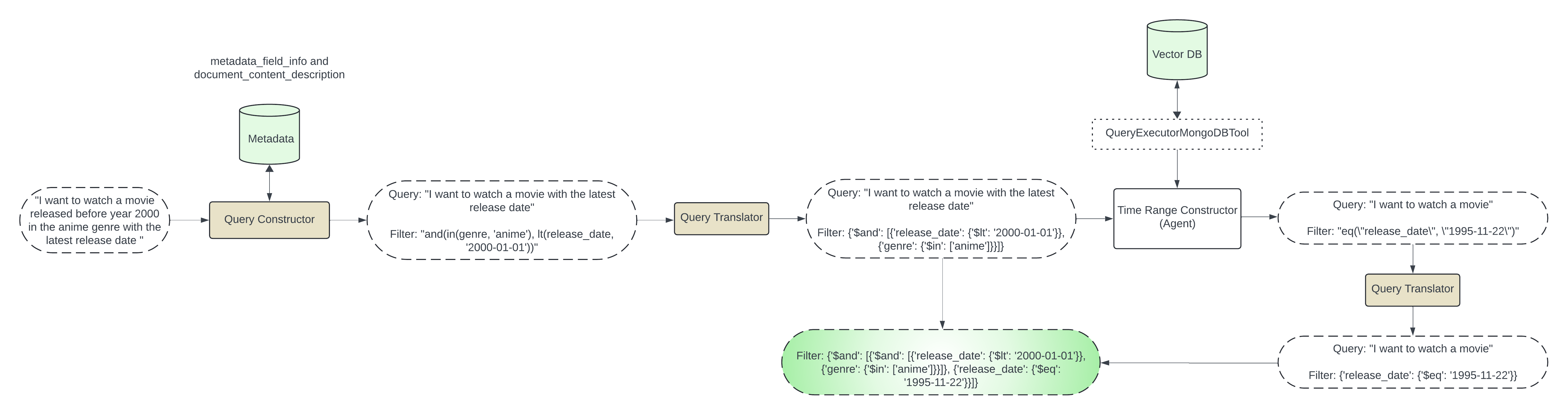
智慧過濾是應對這項挑戰的解決方案。這是一種使用資料集的元資料建立特定過濾器、優化搜尋結果並使其更加準確和高效的技術。透過分析有關資料的資訊(例如其結構、內容和屬性),智慧過濾器可以識別相關條件來過濾您的搜尋。
想像一下搜尋「2000 年之前上映的喜劇電影」。智慧過濾將使用流派、發行日期等元數據,甚至可能是情節關鍵字來創建僅包含符合這些條件的電影的過濾器。這樣,您就可以獲得您想要的內容的列表,而不會產生無關的噪音。
讓我們在下一節中更深入地了解智慧過濾的工作原理。
智慧過濾是一個多步驟過程,涉及從資料中提取資訊、分析資訊以及根據您的需求建立特定的過濾器。讓我們來分解一下:
元資料擷取:第一步是收集有關資料的相關資訊。這包括以下詳細資訊:
預過濾器產生:一旦獲得元數據,您就可以開始建立預過濾器。這些是資料必須滿足才能包含在搜尋結果中的特定條件。例如,如果您要搜尋 2000 年之前發行的喜劇電影,您可以為以下內容建立預過濾器:
與向量搜尋整合:最後一步是將這些預過濾器與向量搜尋結合。這可確保向量搜尋僅考慮符合您預定義條件的資料點。
透過執行這些步驟,智慧過濾可顯著提高搜尋結果的準確性和效率。
元資料提取:為了簡化事情,我們將使用範例資料並手動定義元資料。請參閱: prepare_test_data.py中的 get_docs_metadata 。
預過濾器產生:我們將分兩步驟產生預過濾器。
第 1 步:基於元資料的過濾器
此步驟包括基於元資料生成過濾器。我們將把使用者查詢和元資料傳遞給 LLM 並產生元資料過濾器。
我們將使用使用此 DEFAULT_SCHEMA_PROMPT 初始化的 query_constructor。
注意:根據您的用例更新提示和一些鏡頭範例。
例如:如果元資料有genre和release_date ,並且使用者要求2020年之前發布的action類型電影,那麼我們可以使用LLM產生以下過濾器:
{"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}
步驟 2:基於時間的過濾
在這一步驟中,我們將處理使用者請求latest 、 most recent 、 earliest類型資訊的情況。我們必須查詢實際資料才能取得此資訊。我們將在此步驟中使用LLM代理程式來使用執行器工具查詢mongodb集合:QueryExecutorMongoDBTool我們在generate_time_based_filter中產生基於時間的篩選器。我們也將在聚合階段的$match中使用第一步產生的pre_filter。例如:如果使用者想要最新的電影,LLM代理程式將使用執行器工具執行以下聚合查詢:
Invoking: `mongo_db_executor` with `{'pipeline': '[{"$match": {"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}}, { "$sort": { "release_date": -1 } }, { "$limit": 1 }, { "$project": { "release_date": 1 } }]'}`
與向量搜尋整合:產生的預過濾器將與 MongoDBAtlasVectorSearch 檢索器一起使用:
retriever = vectorstore.as_retriever(
search_kwargs={ ' pre_filter ' : pre_filter}
)創造新的python環境
python3 -m venv env
source env/bin/activate安裝要求
pip3 install -r requirements.txt在config.yaml中設定配置
database_name: < your database name >
collection_name: < your collection name >
vector_index_name: default
embedding_model_dimensions: 1536
similarity: cosine
model: gpt-4o
embedding_model: text-embedding-ada-002設定環境變數
export OPEN_AI_API_KEY = " "
export OPEN_API_BASE = " "
# headers are optional
export OPEN_API_DEFAULT_HEADERS= " "
export MONGO_URI= " "使用範例資料初始化 mongodb 集合。此命令將索引一些範例數據,並在集合上建立向量搜尋索引。
python3 rag/initialize_mongo_collection.pypython3 rag/main.py --queries < list of queries in json format > python3 rag/main.py --queries ' ["I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010", "Recommend an anime movie released before 2023 with the latest release date"] '產生的 Pre_filters:
輸入查詢: "I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010"
輸出: 
輸入查詢: "Recommend a thriller or action movie release after Feb, 2010"
輸出: 
輸入查詢: "Recommend an anime movie released before 2023 with the latest release date"
輸出: 
智慧過濾為表格帶來了許多優勢,使其成為增強搜尋體驗的寶貴工具:
提高搜尋準確性:透過精確定位與查詢相符的數據,智慧過濾大大增加了找到相關結果的可能性。不再費力地瀏覽不相關的資訊。
更快的搜尋結果:由於智慧過濾縮小了搜尋範圍,系統可以更有效地處理訊息,從而更快地獲得結果。
增強的使用者體驗:當使用者快速輕鬆地找到他們正在尋找的內容時,就會帶來更高的滿意度和更好的整體體驗。
多功能性:智慧過濾可應用於從電子商務產品搜尋到內容推薦的各個領域,使其成為多功能工具。
透過利用元資料並創建有針對性的預過濾器,智慧過濾使您能夠提供真正滿足用戶期望的搜尋結果。
智慧過濾是一個強大的工具,可以透過彌合使用者意圖和結果之間的差距來改變體驗。透過利用元資料和向量搜尋的力量,它可以提供更準確、相關和高效的搜尋結果。
無論您是建立電子商務平台、內容推薦系統還是任何依賴有效搜尋的應用程序,結合智慧過濾都可以顯著提高用戶滿意度並帶來更好的結果。
透過了解智慧過濾的基礎知識,您可以探索其潛力並在您的專案中實施。那為什麼還要等呢?立即開始利用智慧過濾的強大功能,徹底改變您的搜尋遊戲!
靈感來自 LangChain 的自助查詢檢索器。


