Interactive RAG
1.0.0
代理正在徹底改變我們利用語言模型進行決策和執行任務的方式。代理是使用語言模型做出決策和執行任務的系統。與傳統方法相比,它們旨在處理複雜的場景並提供更大的靈活性。代理可以被認為是推理引擎,利用語言模型來處理資訊、檢索相關資料、攝取(區塊/嵌入)並產生回應。
未來,隨著語言模型的進步,代理將在處理文字、自動化任務和改善人機互動方面發揮至關重要的作用。
在此範例中,我們將特別關注在動態檢索增強生成(RAG)中利用代理。使用 ActionWeaver 和 MongoDB Atlas,您將能夠透過對話互動即時修改 RAG 策略。無論是選擇更多區塊、增加區塊大小或調整其他參數,您都可以微調 RAG 方法以實現所需的回應品質和準確性。您甚至可以使用自然語言為向量資料庫新增/刪除來源!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
分塊文字很棒,但是如何儲存它呢?
總結可以節省空間並加快速度,但可能會失去細節。
儲存原始資料是準確的,但體積龐大、速度較慢且「嘈雜」。
總結的優點:
總結的缺點:
什麼適合你?這取決於您的需求!考慮:
演示1
創建新的Python環境
python3 -m venv env啟動新的Python環境
source env/bin/activate安裝要求
pip3 install -r requirements.txt在params.py中設定參數:
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
使用以下定義建立搜尋索引
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}設定環境
export OPENAI_API_KEY=運行 RAG 應用程式
env/bin/streamlit run rag/app.py應用程式產生的日誌資訊將附加到app.log。
該機器人支援以下操作:回答問題、搜尋網路、讀取 URL、刪除來源、列出所有來源以及重置訊息。它還支援稱為 iRAG 的操作,可讓您動態控制代理程式的 RAG 策略。
例如:「將 RAG 配置設定為 3 個來源,區塊大小為 1250」=> 新的 RAG 配置:{'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}。
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
如果機器人無法根據 Atlas Vector 儲存中儲存的資料和您的 RAG 策略(來源數量、區塊大小、min_rel_score 等)提供問題的答案,它將啟動 Web 搜尋以查找相關資訊。然後,您可以指示機器人讀取這些結果並從中學習。
RAG 很酷,但制定正確的「RAG 策略」卻很棘手。區塊大小和獨特來源的數量將直接影響法學碩士產生的回應。
在製定有效的 RAG 策略時,網路來源的攝取過程、分塊、嵌入、區塊大小以及所使用來源的數量起著至關重要的作用。分塊對輸入文字進行分解以更好地理解,嵌入捕獲含義,來源數量影響響應多樣性。在區塊大小和來源數量之間找到適當的平衡對於準確且相關的響應至關重要。需要進行實驗和微調來確定最佳設定。
在我們深入“檢索”之前,我們先來談談“攝取過程”
為什麼需要一個單獨的過程來將您的內容「攝取」到向量資料庫中?利用代理的魔力,我們可以輕鬆地將新內容添加到向量資料庫中。
有許多類型的資料庫可以儲存這些嵌入,每種都有其特殊用途。但對於涉及 GenAI 應用程式的任務,我推薦 MongoDB。
將 MongoDB 視為一塊既可吃又可吃的蛋糕。它為您提供了進行查詢的語言(Mongo 查詢語言)的強大功能。它還包括 MongoDB 的所有強大功能。最重要的是,它允許您儲存這些構建塊(向量嵌入)並對它們進行數學運算,所有這些都在一個地方。這使得 MongoDB Atlas 成為滿足您所有向量嵌入需求的一站式商店!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
使用 ActionWeaver(函數呼叫 API 的輕量級包裝器),我們可以建立一個使用者代理,使用 MongoDB Atlas 高效檢索和攝取相關資訊。
代理程式是一個中間人,將客戶端請求傳送到其他伺服器或資源,然後回傳回應。
此代理程式以互動式和可自訂的方式向使用者呈現數據,從而增強整體使用者體驗。
UserProxyAgent有幾個可以自訂的RAG參數,例如chunk_size (例如1000)、 num_sources (例如2)、 unique (例如True)和min_rel_score (例如0.00)。
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
以下是影響我們選擇 ActionWeaver 決定的一些主要優勢:
代理基本上只是一個電腦程式或系統,旨在感知其環境、做出決策並實現特定目標。
將代理視為一個軟體實體,它顯示一定程度的自主權,並代表其使用者或所有者在其環境中執行操作,但以相對獨立的方式。它透過審議其選項來主動採取行動以實現其目標。代理的核心思想是使用語言模型來選擇要採取的一系列操作。與鏈相反,鏈中的一系列操作被硬編碼在代碼中,代理使用語言模型作為推理引擎來確定要採取哪些操作以及按什麼順序。
操作是代理可以呼叫的函數。圍繞操作有兩個重要的設計考量:
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
如果你不考慮這兩點,你將無法建立一個有效的代理。如果您不授予代理程式存取一組正確操作的權限,它將永遠無法實現您賦予它的目標。如果你沒有很好地描述這些動作,代理將不知道如何正確使用它們。
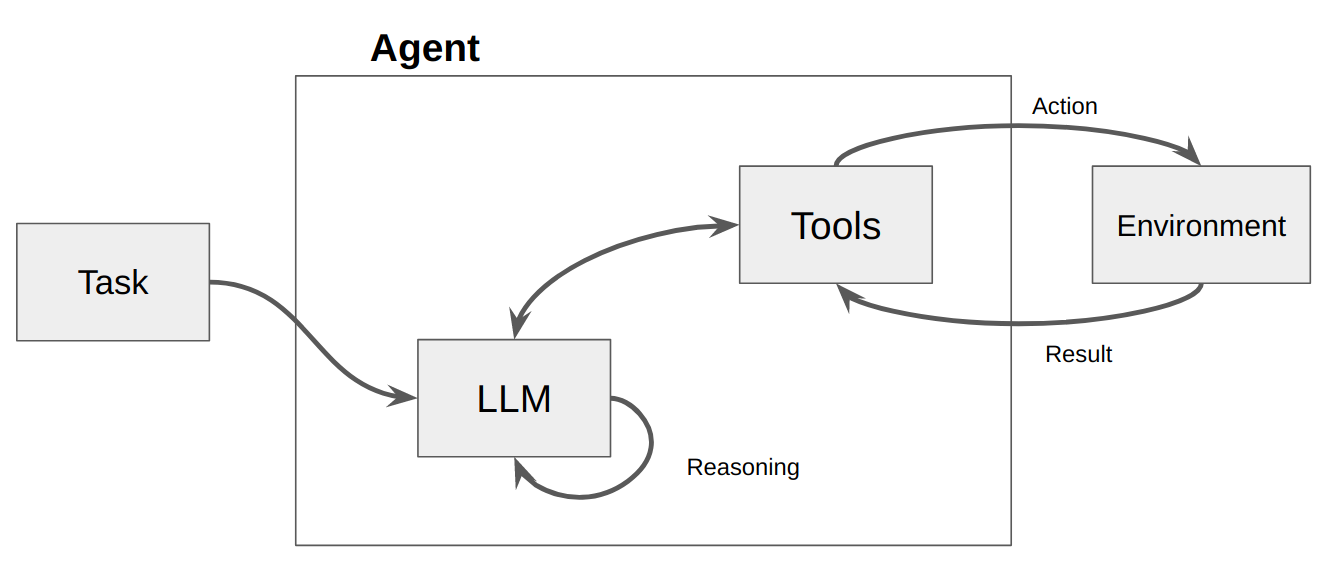
然後呼叫 LLM,導致對使用者的回應或要採取的操作。如果確定需要回應,則將其傳遞給用戶,並且該週期結束。如果確定需要採取行動,則採取該行動,並進行觀察(行動結果)。該操作和相應的觀察被添加回提示(我們稱之為“代理草稿本”),並且循環重置,即。再次呼叫 LLM(使用更新的代理暫存器)。
在 ActionWeaver 中,我們可以將stop=True|False加入操作中來影響循環。如果stop=True ,LLM 將立即傳回函數的輸出。這也將限制 LLM 進行多個函數呼叫。在此示範中,我們將僅使用stop=True
ActionWeaver 也支援使用orch_expr(SelectOne[actions])和orch_expr(RequireNext[actions])更複雜的循環控制,但我會把它留給第二部分。
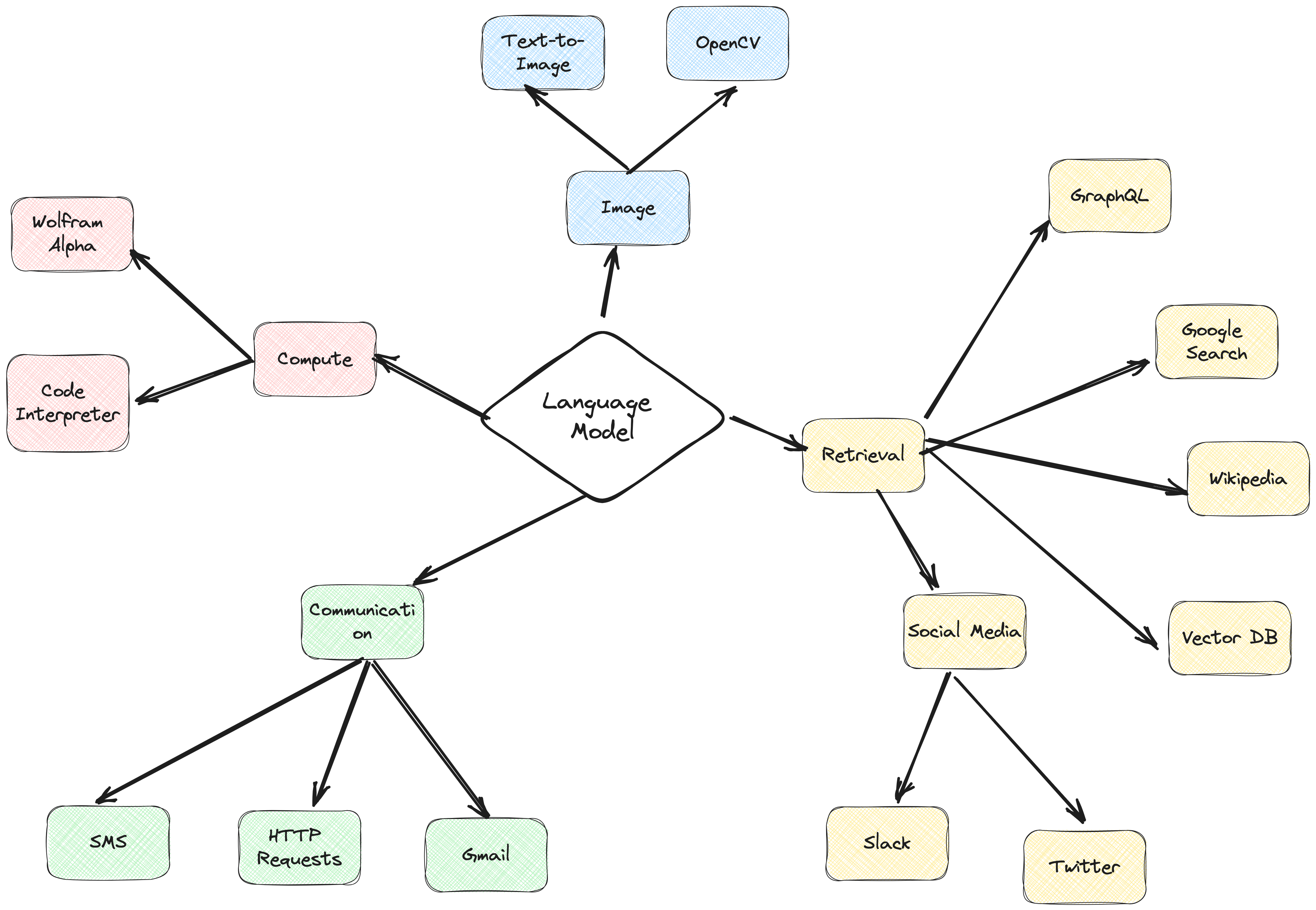
ActionWeaver代理框架是一個以函數呼叫為核心的AI應用框架。它旨在實現傳統計算系統與語言模型強大的推理功能的無縫合併。 ActionWeaver 是圍繞著 LLM 函數呼叫的概念構建的,而像 Langchain 和 Haystack 這樣的流行框架是圍繞管道的概念構建的。

了解更多:https://thinhdanggroup.github.io/function-calling-openai/
開發人員可以使用簡單的裝飾器將任何 Python 函數附加為工具。在下面的範例中,我們引入了 get_sources_list 操作,該操作將由 OpenAI API 呼叫。
ActionWeaver 利用裝飾方法的簽章和文件字串作為描述,將它們傳遞給 OpenAI 的函數 API。
ActionWeaver 提供了一個輕量級包裝器,負責將文件字串/裝飾器資訊轉換為 OpenAI API 的正確格式。
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True 新增到操作時表示 LLM 將立即傳回函數的輸出,但這也限制了 LLM 進行多個函數呼叫。例如,如果詢問紐約和舊金山的天氣,模型將為每個城市依序呼叫兩個單獨的函數。但是,使用stop=True時,一旦第一個函數返回紐約市或舊金山的天氣資訊(取決於它首先查詢哪個城市),此過程就會中斷。
若想更深入了解該機器人的工作原理,請參閱 bot.py 檔案。此外,您可以探索 ActionWeaver 儲存庫以獲取更多詳細資訊。
生成推理軌跡允許模型誘導、追蹤和更新行動計劃,甚至處理異常。此範例使用 ReAct 與思想鏈 (CoT) 結合。
思想鏈
推理+行動
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
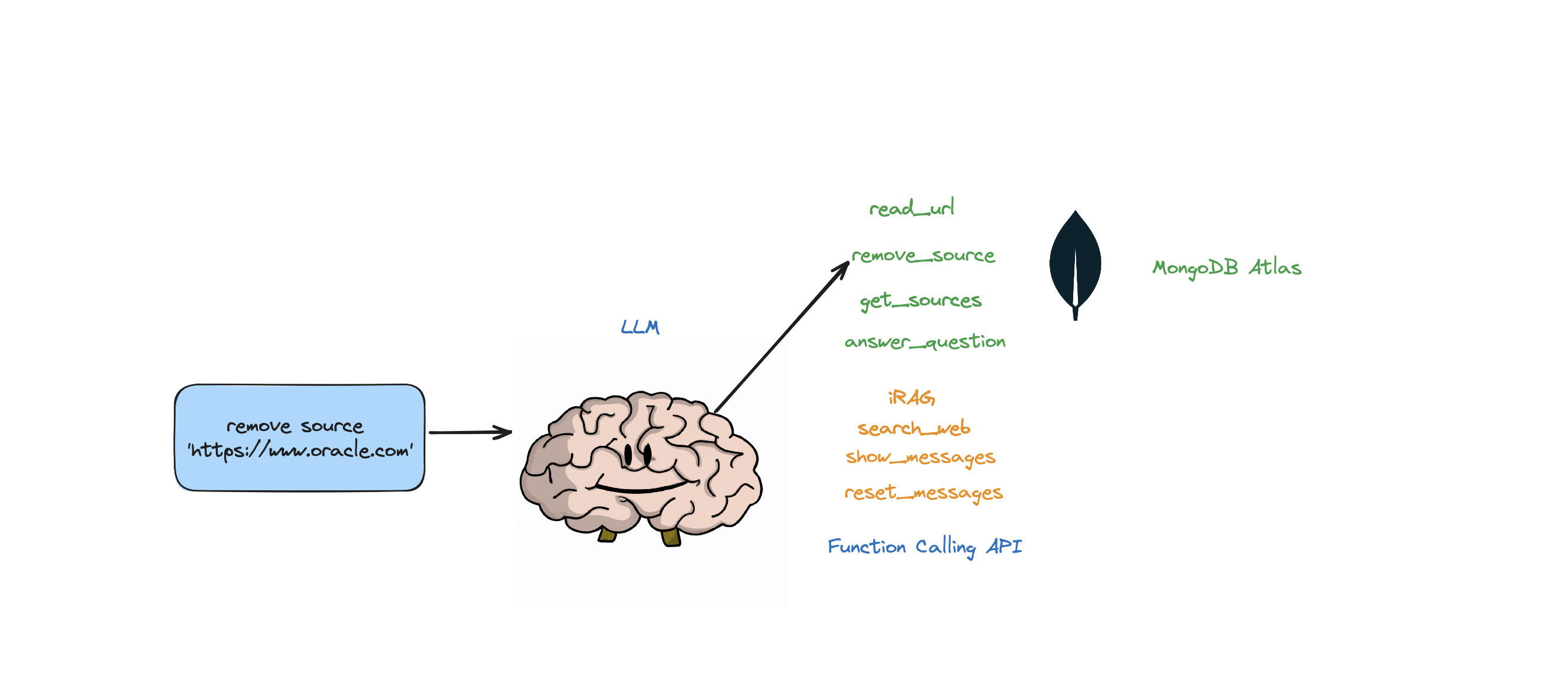
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
思維鏈 (CoT) 和 ReAct 提示技術在這些範例中都發揮了作用。方法如下:
思想鏈(CoT)提示:
反應提示:
總之,CoT 和 ReAct 在這些範例中都發揮著至關重要的作用。 CoT 使模型能夠逐步推理並選擇適當的操作,而 ReAct 則透過允許模型與其環境互動並相應地更新其計劃來擴展此功能。這種推理和行動的結合使大型語言模型更加靈活和通用,使它們能夠處理更廣泛的任務和情況。
讓我們先向我們的代理詢問一個問題。在這種情況下, “什麼是芒果?” 。首先發生的事情是,它將嘗試使用向量嵌入相似性來「回憶」任何相關資訊。然後,它會用它「召回」的內容制定回應,或執行網路搜尋。由於我們的知識庫目前是空的,因此我們需要添加一些來源,然後才能製定回應。
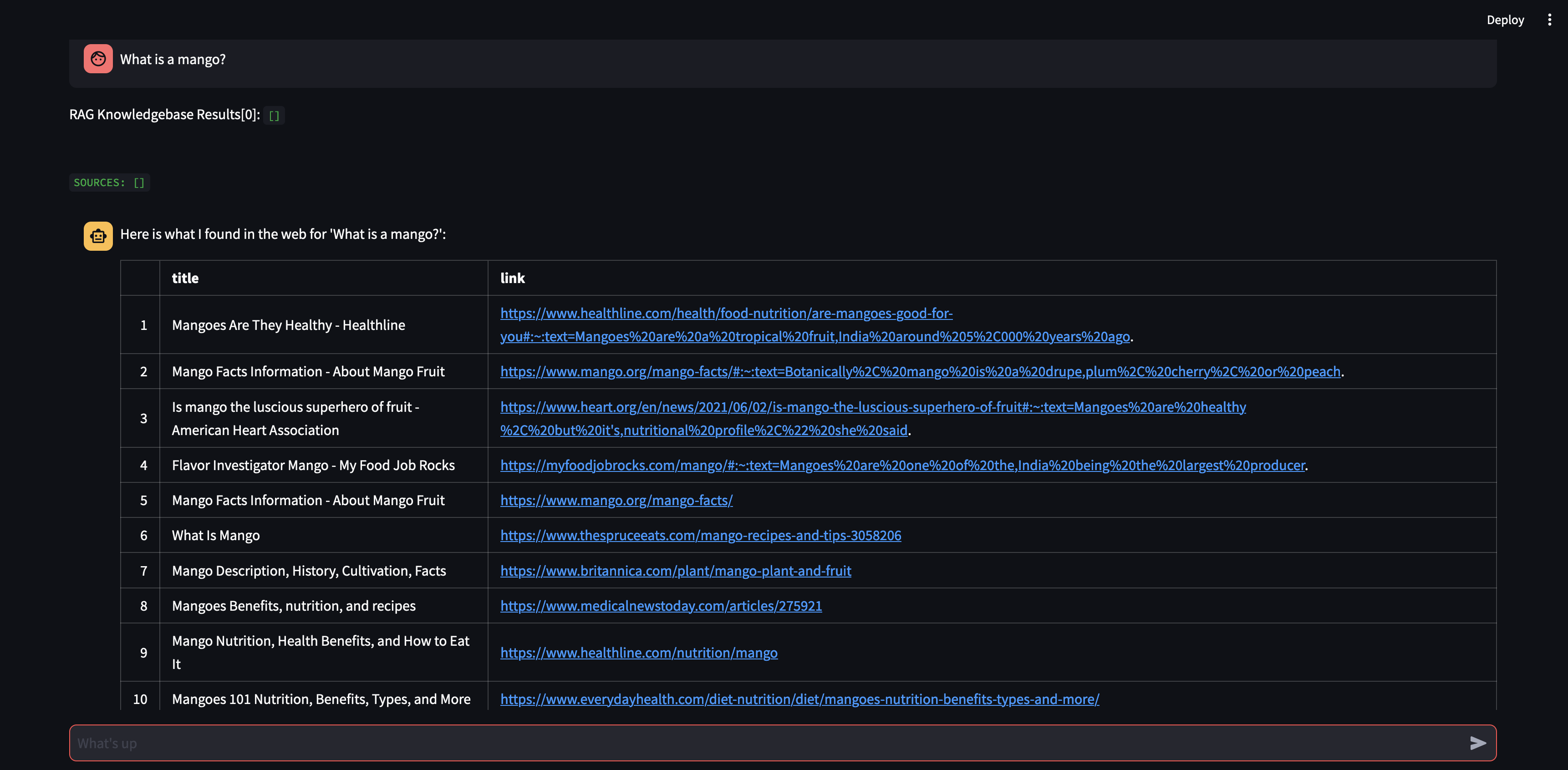
由於機器人無法使用向量資料庫中的內容提供答案,因此它啟動了 Google 搜尋以尋找相關資訊。我們現在可以告訴它應該「學習」哪些來源。在本例中,我們將告訴它從搜尋結果中了解前兩個來源。
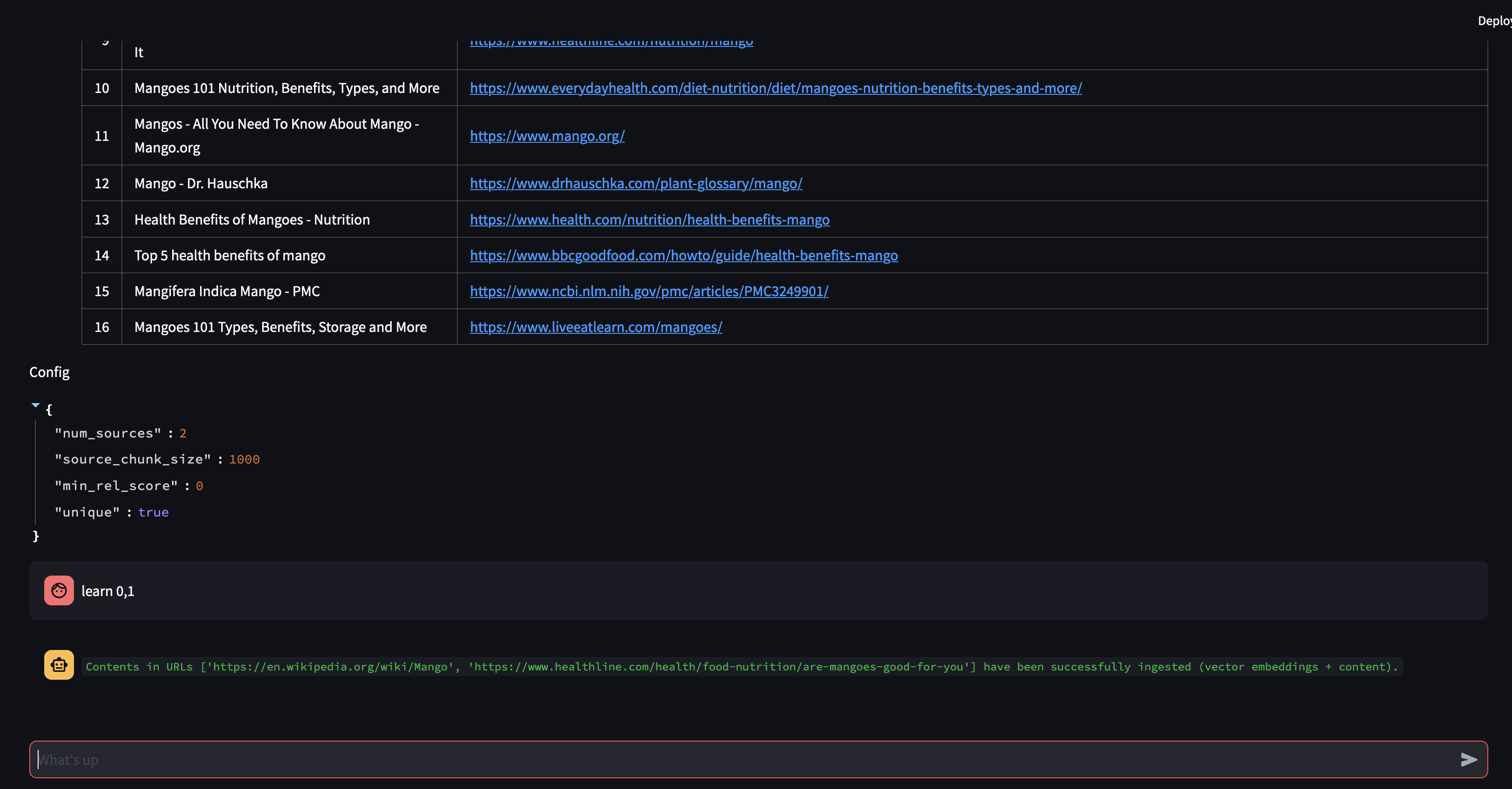
接下來我們來修改RAG策略!讓我們讓它只使用一個來源,並讓它使用 500 個字元的小塊。
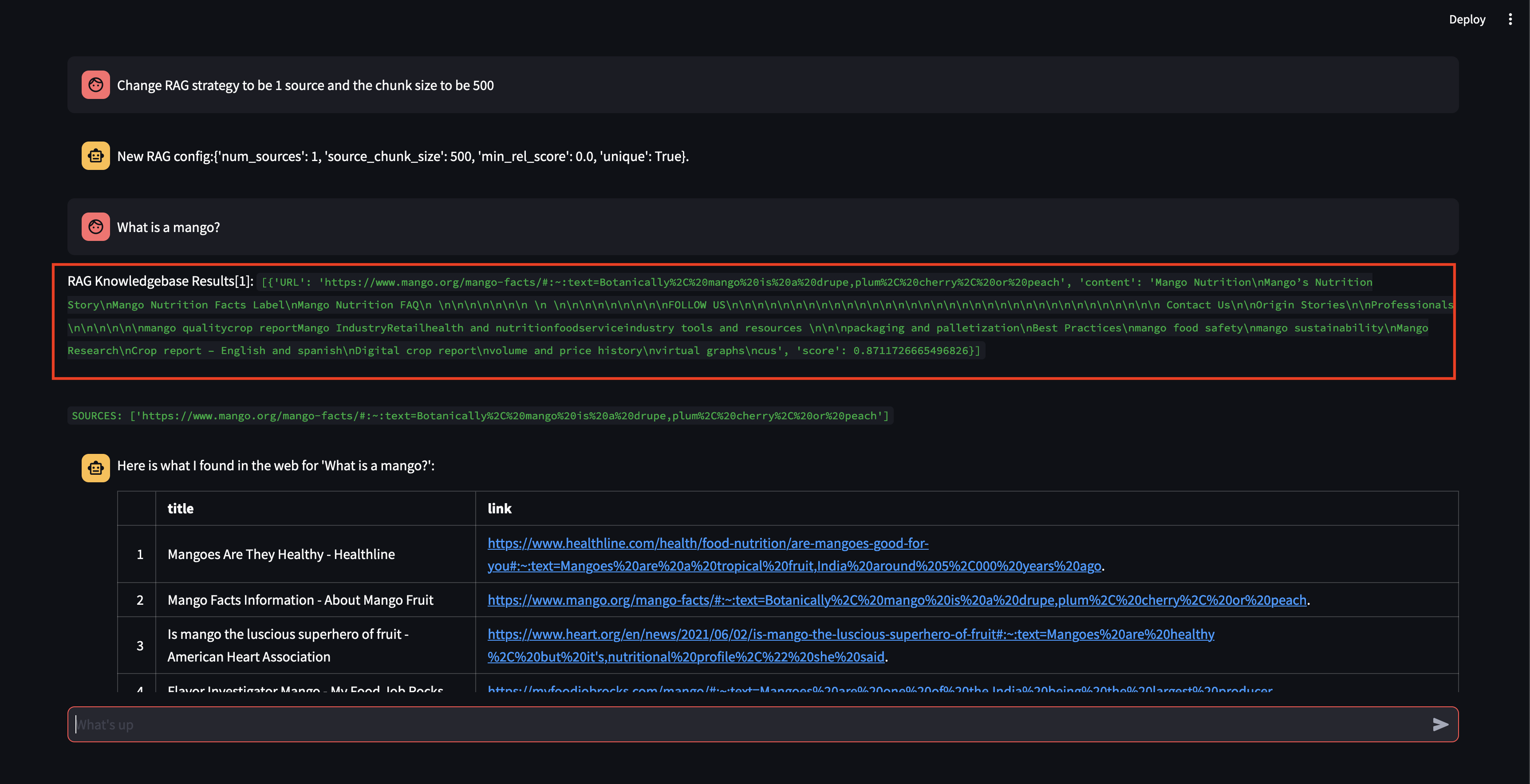
請注意,雖然它能夠檢索具有相當高的相關性分數的區塊,但它無法產生回應,因為區塊大小太小且區塊內容的相關性不足以製定回應。由於它無法產生小塊的回應,因此它代表用戶執行網路搜尋。
讓我們看看如果將區塊大小從 500 個字元增加到 3000 個字元會發生什麼。
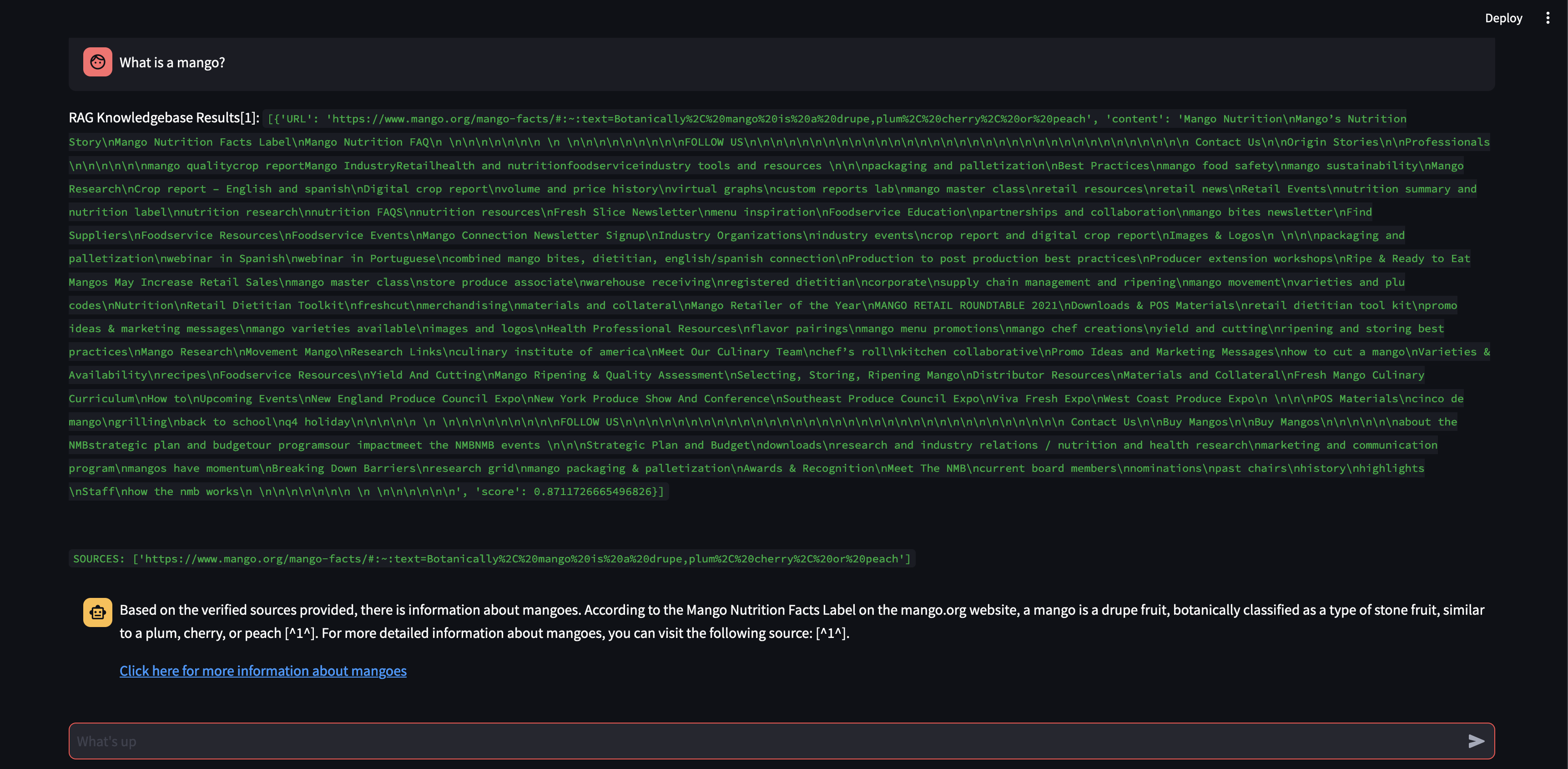
現在,有了更大的區塊大小,它就能夠使用向量資料庫中的知識準確地制定回應!
讓我們透過詢問代理商的知識庫中可用的內容:您的知識庫中有哪些資源?
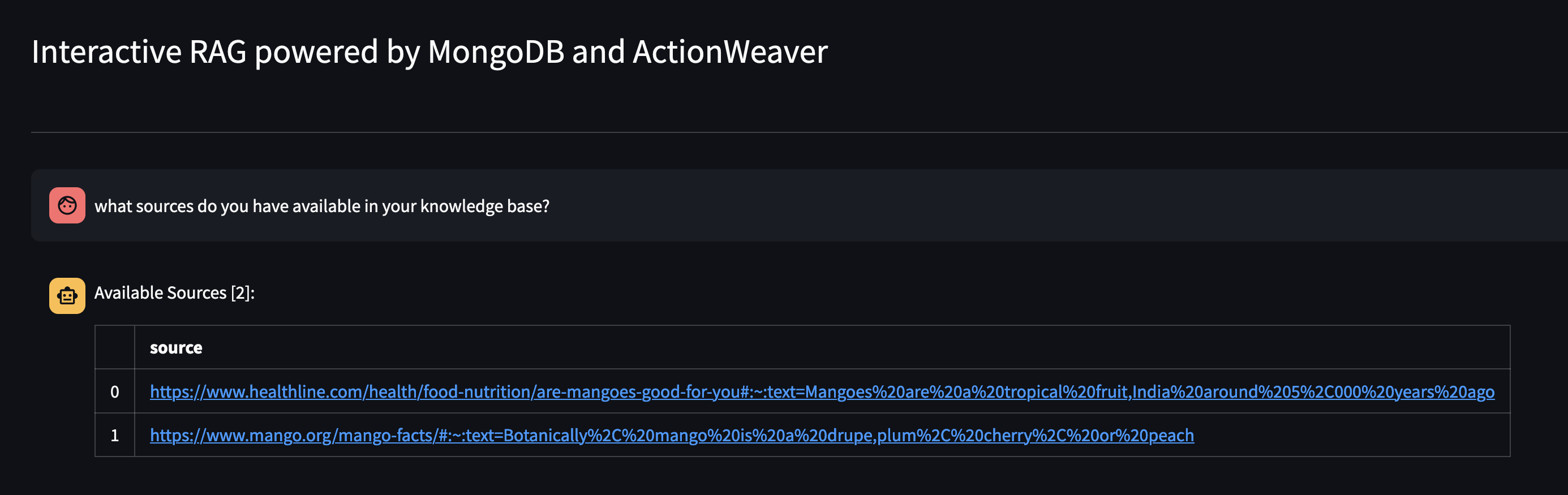
如果您想要刪除特定資源,您可以執行以下操作:
USER: remove source 'https://www.oracle.com' from the knowledge base
要刪除集合中的所有來源 - 我們可以執行以下操作:
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
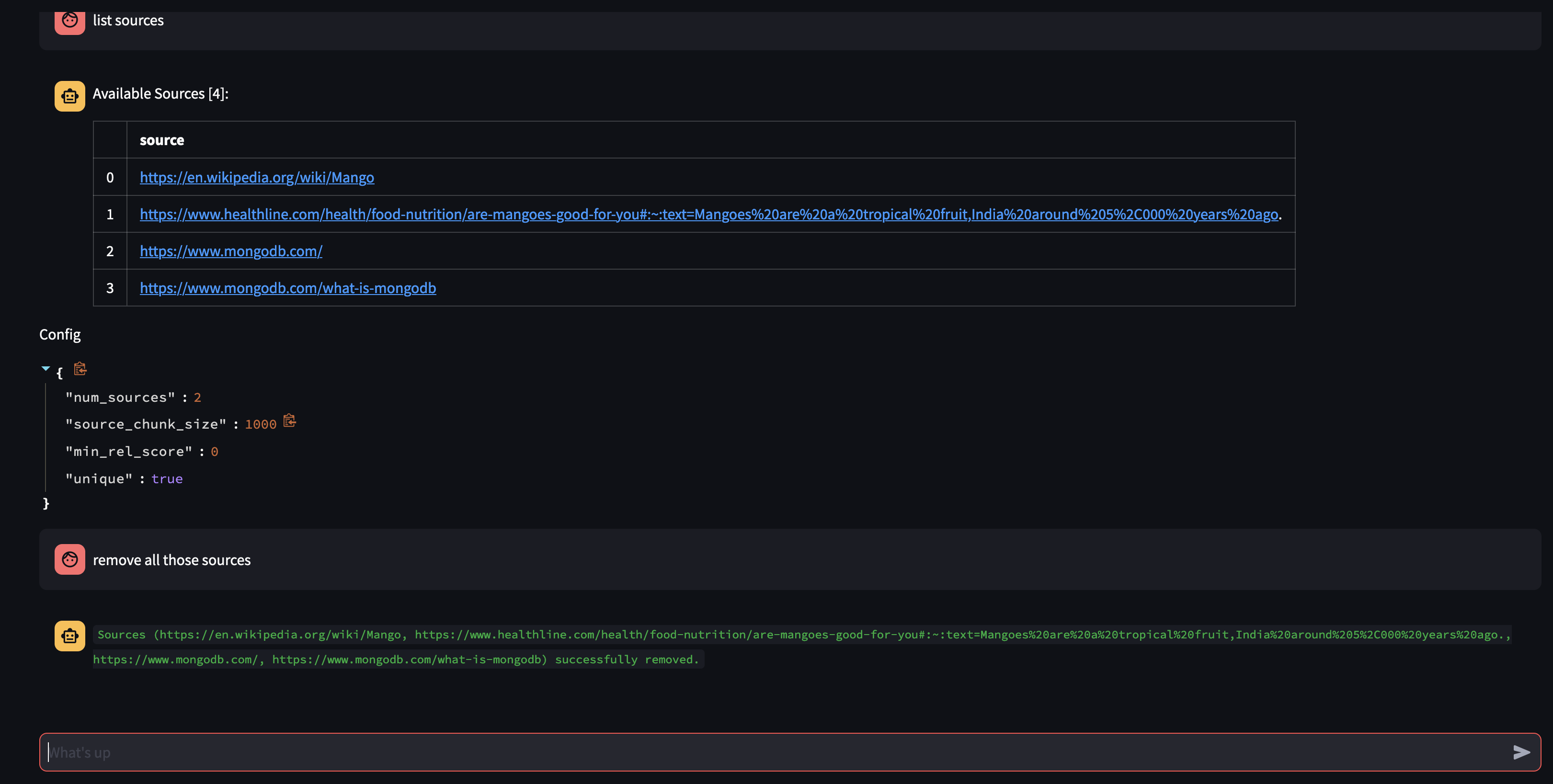
該演示讓我們了解了人工智慧代理的內部工作原理,並展示了它以互動方式學習和回應用戶查詢的能力。我們見證了它如何將內部知識庫與即時網路搜尋無縫結合,以提供全面且準確的資訊。這項技術的潛力是巨大的,遠遠超出了簡單的問答範疇。如果沒有函數呼叫 API的魔力,這一切都是不可能的。
這是受到 https://github.com/TengHu/Interactive-RAG 的啟發
我們歡迎開源社群的貢獻。
阿帕契許可證 2.0


