vector search api
1.0.0
請依照以下步驟設定並執行專案:
安裝 PostgreSQL
admin 。配置專案
config資料夾。db.js並更新第 3 行:mayanksharma變更為您的系統使用者名稱。設定資料庫
CREATE EXTENSION vector;安裝奧拉馬
ollama pull snowflake-arctic-embed安裝專案依賴項
npm install
node server.js安裝 REST 用戶端擴展
測試API
api.http檔案以測試 API 端點。 {
"query" : " your_search_query "
}{
"title" : " magazine_title " ,
"author" : " author_name " ,
"category" : " magazine_category " ,
"content" : " magazine_content "
}我將 PostgreSQL 與 pgvector(儲存嵌入向量)和 tsvector(儲存內容文字)一起使用。
需求:從100萬筆記錄中搜尋
新增了分層可導航小世界(HNSW)索引,用於內容嵌入上的向量搜尋原因:搜尋需要高召回率,這使得 hnsw 比 ivfflat 更好參考
新增了標題、作者和內容的索引
新增分頁以減少載入時間
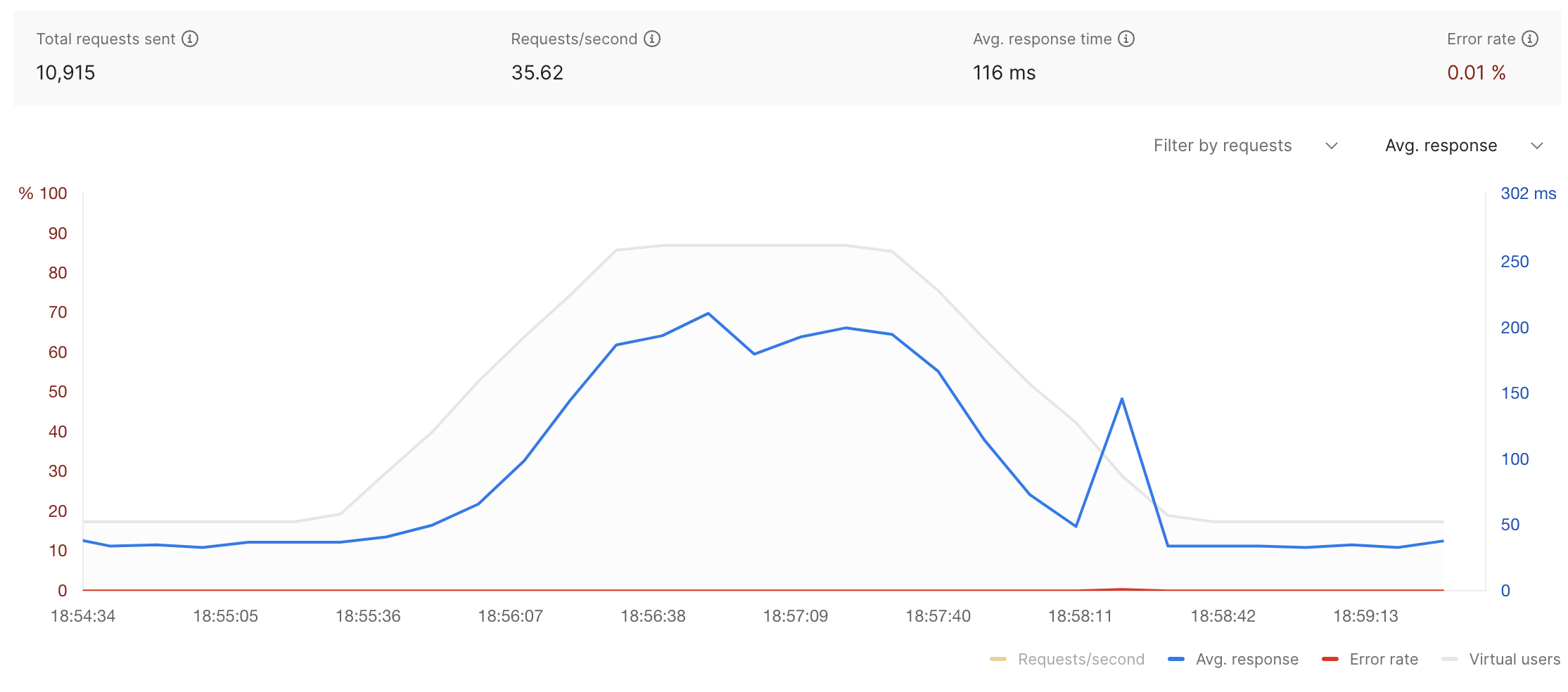
簡介:巔峰
虛擬用戶: 20
測驗時間: 5 分鐘
端點命中: POST /api/v1/magazine/hybridsearch/1(“glasgow”、“game”、“business”、“shubham”、“food”和“modern”)
發送的請求總數: 10,915
每秒請求數: 35.62
平均反應時間: 116 毫秒
使用兩個單獨的文字搜尋和向量搜尋服務
嵌入是由Meta llama“雪花-北極-嵌入”模型產生的,是輕量級的。
步驟 1:首先顯示向量和全文搜尋結果中的常見對象,
第 2 步:接下來是僅文字搜尋的對象,
步驟 3:向量搜尋中的其餘物件。
查詢:向量“glasgow”,返回“凱爾特盛宴日記”,其中包含“蘇格蘭內容”
查詢:向量“shortbread”,返回“凱爾特盛宴日記”,因為“shortbread”與“蘇格蘭”相關
查詢:關鍵字/全文“shubham”,傳回作者姓名為“Shubham Thorve”的“Physics Refresher”
查詢:關鍵字/全文“mayank”,返回作者姓名為“Mayank Khurana”的“Digit Gaming”
查詢:關鍵字/全文“月份”,返回“Dalal Street Journal”,其內容為“本月有關視頻遊戲的所有內容”
/model

