cassandra lucene index
2.1.20.0
Stratio 的Cassandra Lucene Index 源自Stratio Cassandra,是Apache Cassandra 的一個插件,它擴展了其索引功能以提供近乎即時的搜索,例如ElasticSearch 或Solr,包括全文搜尋功能和免費的多變量、地理空間和雙時態搜尋。它是透過基於 Apache Lucene 的 Cassandra 二級索引實作來實現的,其中叢集的每個節點都為其自己的資料建立索引。 Stratio 的 Cassandra 索引是 Stratio BigData 平台所基於的核心模組之一。
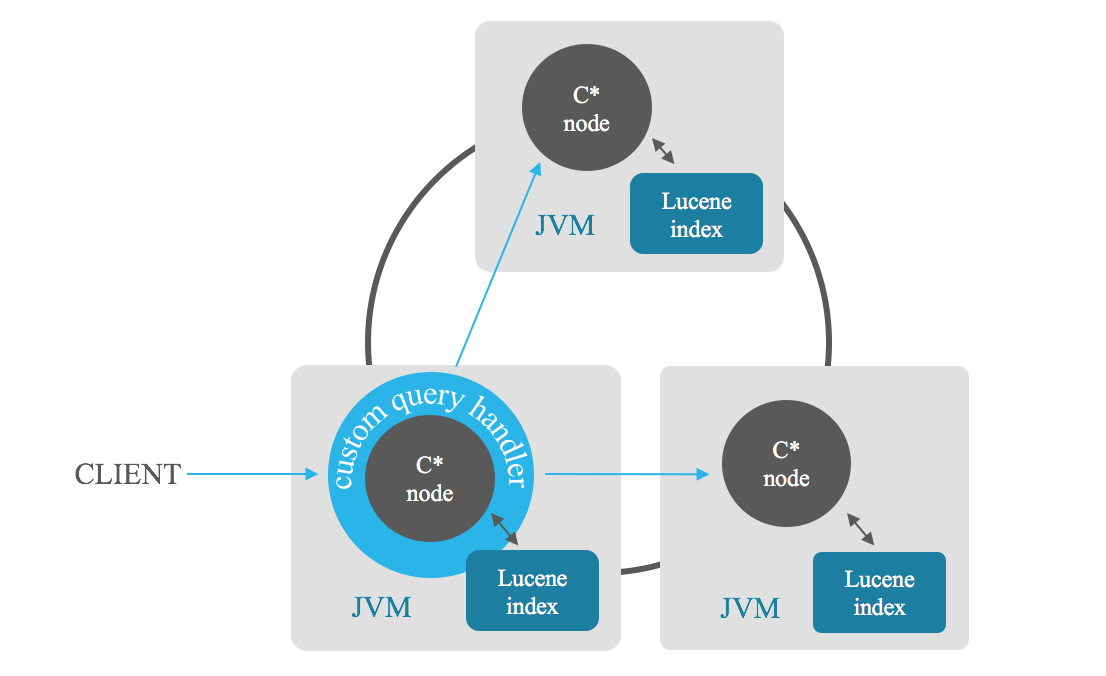
索引相關性搜尋可讓您檢索滿足搜尋的n 個以上相關結果。協調器節點將搜尋發送到叢集中的每個節點,每個節點返回其n 個最佳結果,然後協調器組合這些部分結果並給出其中的n 個最佳結果,從而避免完全掃描。您也可以根據欄位組合進行排序。
表中的任何單元格都可以建立索引,包括主鍵和集合中的單元格。也支援寬行。您可以掃描令牌/鍵範圍、套用其他 CQL3 子句並對篩選結果進行分頁。
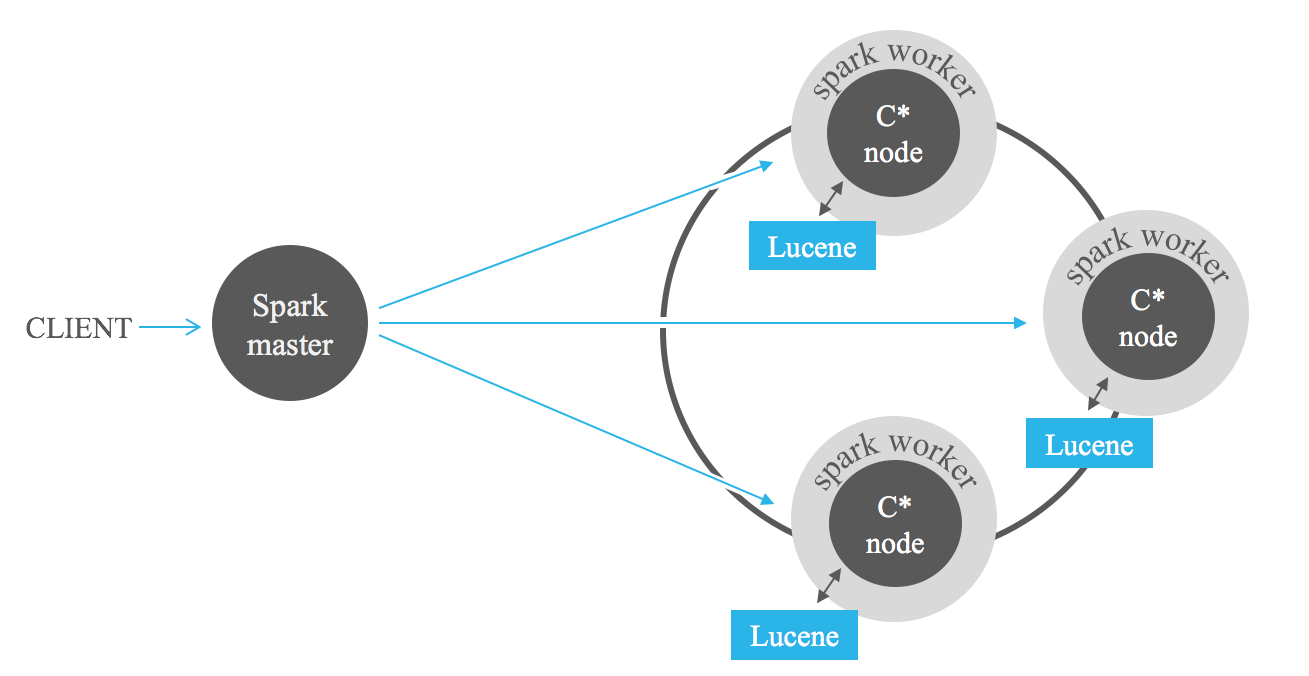
當使用 Apache Hadoop 或更好的 Apache Spark 等 MapReduce 框架分析儲存在 Cassandra 中的資料時,索引過濾搜尋提供了強大的幫助。在作業輸入中新增 Lucene 過濾器可以顯著減少要處理的資料量,避免完全掃描。
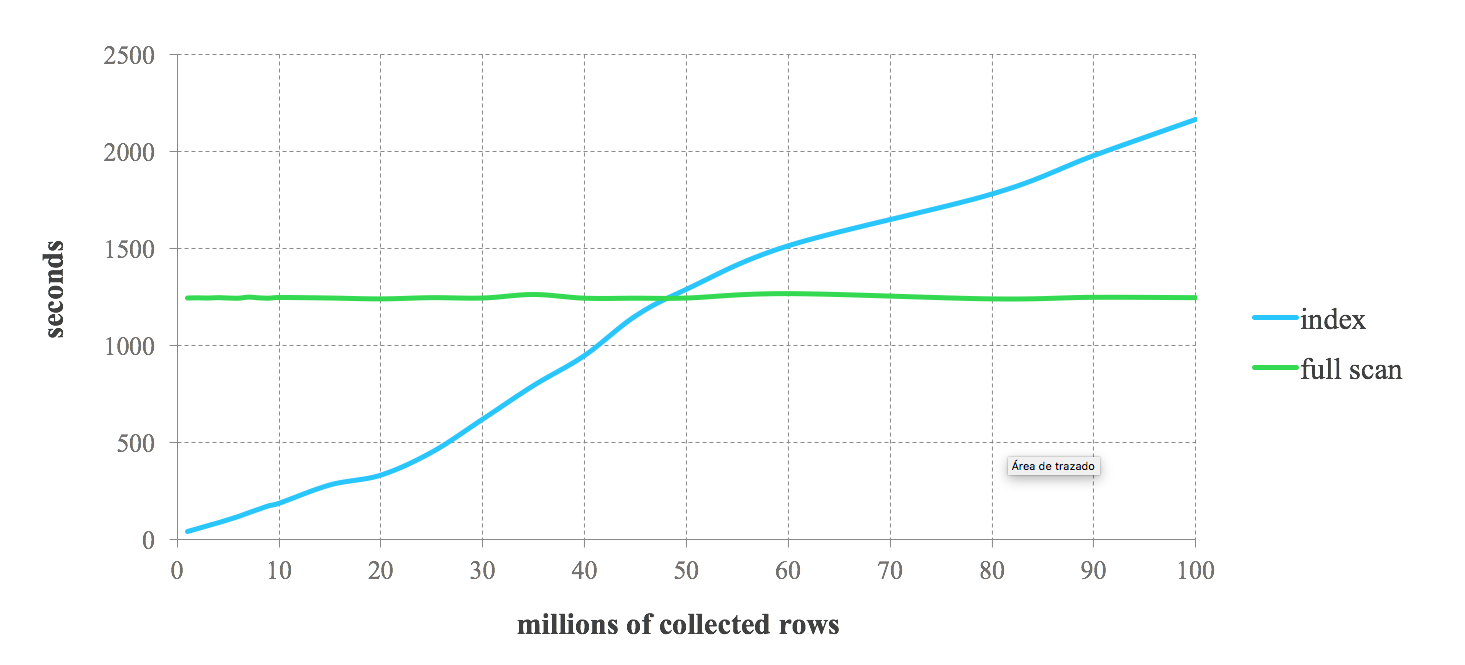
以下基準測試結果可讓您了解將 Lucene 索引與 Spark 結合使用時的預期效能。我們對 1% 到 100% 的儲存資料進行連續查詢。我們可以看到索引對於請求強過濾資料的查詢具有高效能。然而,在限制較少的查詢中,效能會下降。隨著查詢回傳的記錄數量增加,我們會達到索引變得比完整掃描慢的程度。因此,在 Spark 作業中使用索引的決定取決於查詢選擇性。兩種方法之間的權衡取決於特定的用例。一般來說,對於檢索不超過 25% 儲存資料的作業,建議將 Lucene 索引與 Spark 結合使用。
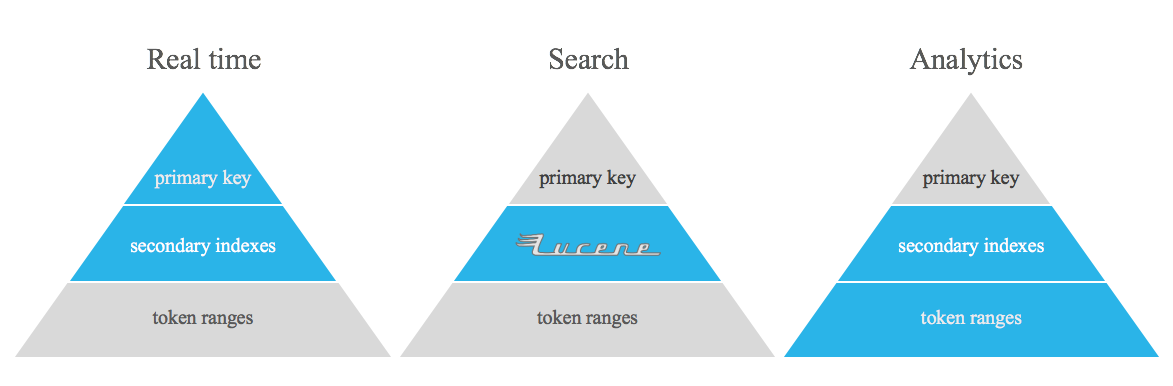
此專案無意取代 Apache Cassandra 非規範化表、倒排索引和/或二級索引。它只是一個執行某種查詢的工具,這些查詢很難使用 Apache Cassandra 開箱即用的功能來解決,從而填補了即時和分析之間的空白。
更多詳細資訊請參閱 Stratio 的 Cassandra Lucene 索引文件。
Lucene 搜尋技術整合到 Cassandra 中可以提供:
Stratio 的 Cassandra Lucene 索引及其與 Lucene 搜尋技術的整合提供:
尚不支持:
counter列Stratio 的 Cassandra Lucene Index 作為 Apache Cassandra 的插件進行分發。因此,您只需建立一個包含該插件的 JAR 並將其新增至 Cassandra 的類別路徑中:
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/特定的 Cassandra Lucene 索引版本針對特定的 Apache Cassandra 版本。因此,cassandra-lucene-index ABCX 設計用於與 Apache Cassandra ABC 一起使用,例如 cassandra-lucene-index:3.0.7.1 用於 cassandra:3.0.7。請注意,生產就緒版本是版本標籤(例如3.0.6.3),不要在生產中使用branch-X或master分支。
或者,也可以使用此 Maven 設定檔來完成修補,指定 Cassandra 安裝的路徑,此任務也會刪除 CASSANDRA_HOME/lib/ 目錄中先前插件的 JAR 版本:
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >如果您沒有安裝 Cassandra 版本,還有一個替代設定檔可以讓 Maven 下載並修補正確版本的 Apache Cassandra:
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >現在您可以執行 Cassandra 並使用 Cassandra 查詢語言進行一些測試:
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh Lucene 的索引檔案將儲存在與 Cassandra 相同的目錄中。預設資料目錄是/var/lib/cassandra/data ,每個索引都放置在其索引列族的 SSTable 旁邊。
請記住,如果您使用地理形狀搜索,則需要包含 JTS jar。
有關 Apache Cassandra 的更多詳細信息,請參閱其文件。
我們將建立下表來儲存推文:
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);現在您可以使用以下語句在其上建立自訂 Lucene 索引:
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
};這將為表中指定類型的所有列建立索引,並且每秒刷新一次。或者,您可以使用具有一致性ALL空搜尋明確刷新所有索引分片:
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUM現在,要搜尋特定日期範圍內的推文:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );可以執行相同的搜索,強制明確刷新所涉及的索引分片:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;現在,要搜尋上述日期範圍內正文欄位包含「大數據給組織」這個短語的前 100 條更相關的推文:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;要優化搜尋以僅獲取姓名以“a”開頭的用戶撰寫的推文:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;若要取得最近 100 個篩選結果,您可以使用排序選項:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;先前的搜尋可以限制為靠近某個地理位置創建的推文:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;也可以按到地理位置的距離對結果進行排序:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;最後但並非最不重要的一點是,您可以將任何搜尋路由到特定的令牌範圍或分區,這樣只有叢集節點的子集會被命中,從而節省寶貴的資源:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;最後是 Hadoop、Spark 和其他 MapReduce 框架支援的基礎。
請參閱 Stratio 的 Cassandra Lucene Index 綜合文件。


