korpatbert
1.0.0
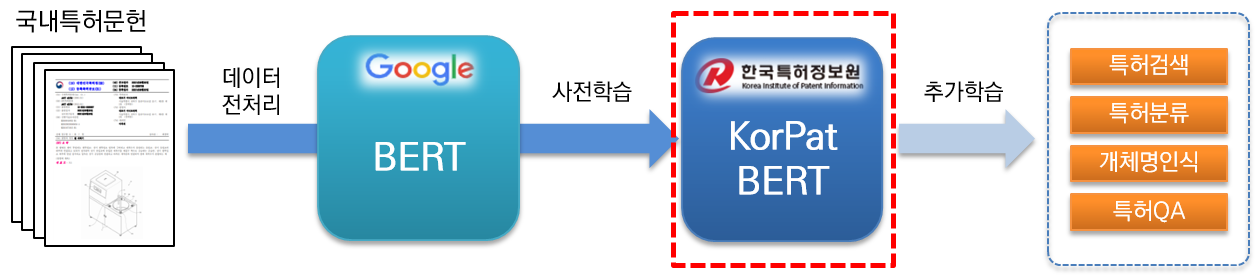
KorPatBERT(韓國專利BERT)是韓國專利資訊院研發的人工智慧語言模式。
為了解決韓國專利領域的自然語言處理問題,準備專利行業的智慧資訊基礎設施,對大量國內專利文檔(基數:約406萬篇文檔,大型:約506萬篇文檔)進行預訓練基於現有的Google BERT 基礎模型的架構(預訓練)並且免費提供。
它是專門針對專利領域的高效能預訓練語言模型,可用於各種自然語言處理任務。
[KorPatBERT-base]
[KorPatBERT-大]
[KorPatBERT-base]
[KorPatBERT-大]
從語言模型學習中使用的專利文獻中提取了大約1000萬個主要名詞和複合名詞,並將它們添加到韓語語素分析器Mecab-ko的用戶詞典中,然後通過Google SentencePiece劃分為子詞。一個專門的MSP。
| 模型 | 前@1(ACC) |
|---|---|
| 谷歌BERT | 72.33 |
| 科爾伯特 | 73.29 |
| 柯伯特 | 33.75 |
| 克爾伯特 | 72.39 |
| KorPatBERT-base | 76.32 |
| KorPatBERT-大 | 77.06 |
| 模型 | 前@1(ACC) | 前@3(ACC) | 前@5(ACC) |
|---|---|---|---|
| KorPatBERT 基礎 | 61.91 | 82.18 | 86.97 |
| KorPatBERT-大 | 62.89 | 82.18 | 87.26 |
| 節目名稱 | 版本 | 安裝引導路徑 | 必需的? |
|---|---|---|---|
| Python | 3.6及以上 | https://www.python.org/ | 是 |
| 蟒蛇 | 4.6.8 及更高版本 | https://www.anaconda.com/ | 氮 |
| 張量流 | 2.2.0 及更高版本 | https://www.tensorflow.org/install/pip?hl=ko | 是 |
| 句子片段 | 0.1.96 或更高 | https://github.com/google/sentencepiece | 氮 |
| 梅卡布科 | 0.996-ko-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | 是 |
| 梅卡卜科迪奇 | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | 是 |
| mecab-python | 0.996-en-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | 是 |
| python-mecab-ko | 1.0.11 或更高版本 | https://pypi.org/project/python-mecab-ko/ | 是 |
| 喀拉斯 | 2.4.3 及更高版本 | https://github.com/keras-team/keras | 氮 |
| bert_for_tf2 | 0.14.4 及更高版本 | https://github.com/kpe/bert-for-tf2 | 氮 |
| 全面品質管理 | 4.59.0 及更高版本 | https://github.com/tqdm/tqdm | 氮 |
| 大豆 | 0.0.493 或更高 | https://github.com/lovit/soynlp | 氮 |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ 與Google BERT基礎學習方法相同,使用範例請參考특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼第2.3節。
我們正在透過一定的程序向對此感興趣的組織、公司和研究人員傳播韓國專利資訊院的語言模型。請按照以下申請流程填寫申請表和協議,並透過電子郵件將申請提交給負責人。
| 檔案名稱 | 解釋 |
|---|---|
| pat_all_mecab_dic.csv | Mecab專利使用者字典 |
| lm_test_data.tsv | 分類樣本資料集 |
| korpat_tokenizer.py | KorPat Tokenizer 程式 |
| test_tokenize.py | 分詞器使用範例 |
| test_tokenize.ipynb | 分詞器使用範例 (Jupiter) |
| 測試_lm.py | 語言模型使用範例 |
| test_lm.ipynb | 語言模型使用範例(Jupyter) |
| korpat_bert_config.json | KorPatBERT 設定檔 |
| korpat_vocab.txt | KorPatBERT 詞彙文件 |
| 型號.ckpt-381250.meta | KorPatBERT 模型文件 |
| 型號.ckpt-381250.index | KorPatBERT 模型文件 |
| model.ckpt-381250.data-00000-of-00001 | KorPatBERT 模型文件 |


