elastic_transformers
1.0.0
帶有句子轉換器的語義彈性搜尋。我們將利用 Elastic 的強大功能和 BERT 的魔力來索引一百萬篇文章,並對它們進行詞彙和語義搜尋。
目的是提供一種易於使用的方式來設定您自己的 Elasticsearch,並使用 NLP 轉換器實現上下文嵌入/語義搜尋的近乎最先進的功能。
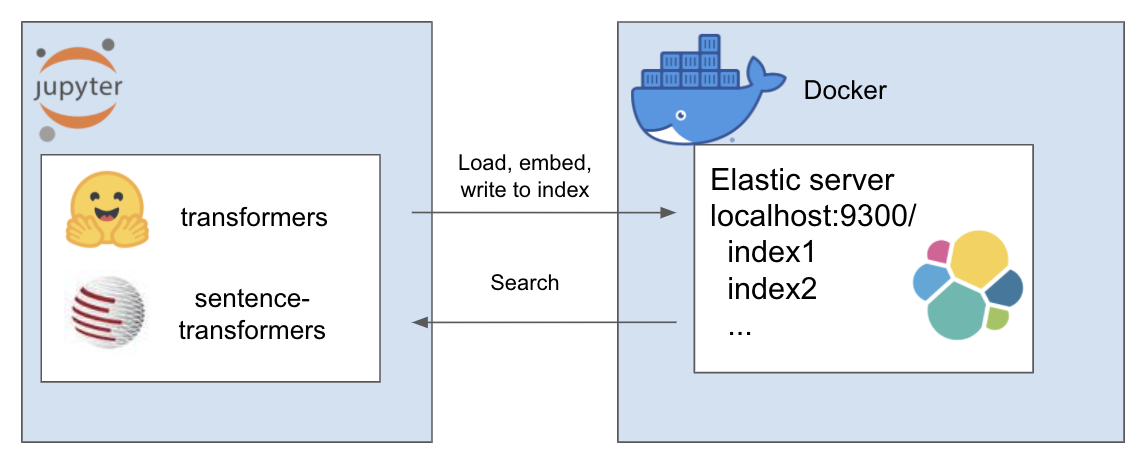
上述設定的工作原理如下
我的環境稱為et ,我為此使用 conda。在專案目錄內導航
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txt在本教程中,我使用 Rohk 的 A Million News Headlines 並將其放置在專案目錄內的資料資料夾中。
elastic_transformers/
├── data/
您會發現這些步驟非常抽象,因此您也可以使用您選擇的資料集來執行此操作
請按照此處 Elastic 頁面上有關使用 Docker 設定 Elastic 的說明進行操作。
該存儲庫引入了 ElasiticTransformers 類別。協助建立、索引和查詢包含嵌入的 Elasticsearch 索引的實用程序
啟動連接連結以及(可選)要使用的索引的名稱
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec定義索引的對應。可以提供相關欄位的清單以用於關鍵字搜尋或語義(密集向量)搜尋。它還具有密集向量大小的參數,因為這些參數可能會有所不同create_index - 使用先前建立的規格來建立可供搜尋的索引
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - 將大型 csv 檔案分解為區塊,並迭代地使用預先定義的嵌入實用程式為每個區塊建立嵌入列表,然後將結果提供給索引
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )搜尋- 允許選擇關鍵字(Elastic 中的“匹配”)或語義(Elastic 中的密集)搜尋。值得注意的是,它需要與 write_large_csv 中使用的相同嵌入函數
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )成功設定後,使用以下筆記本使這一切正常工作
這個 repo 結合了以下傑出人士的精彩作品。如果您還沒有這樣做,請檢查他們的工作...


