JustJoking.ai
1.0.0
在這個專案中,我訓練了一個變壓器模型來產生短笑話。然後,透過對推理方法進行輕微修改,我能夠使用相同的模型,以便給定初始字串作為輸入,模型嘗試以幽默的方式完成它。
有兩個筆記本都執行相同的任務。
笑話生成結果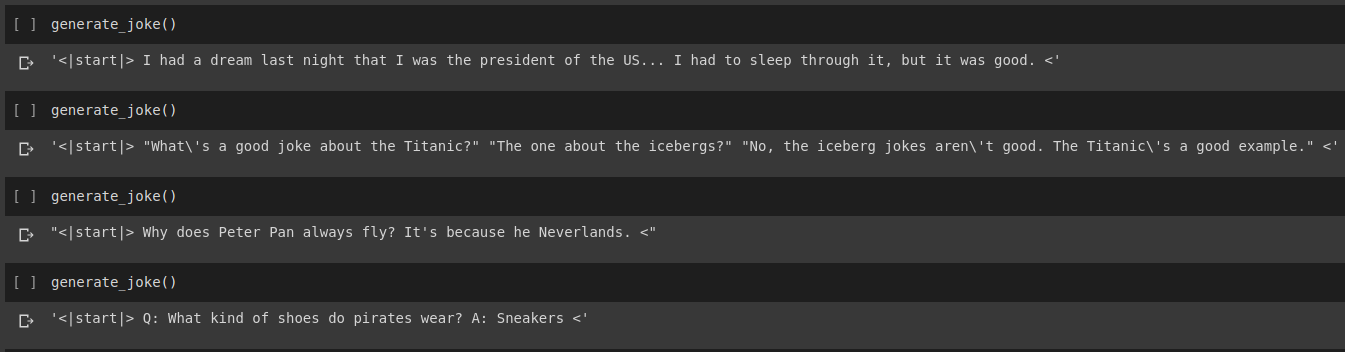
句子完成結果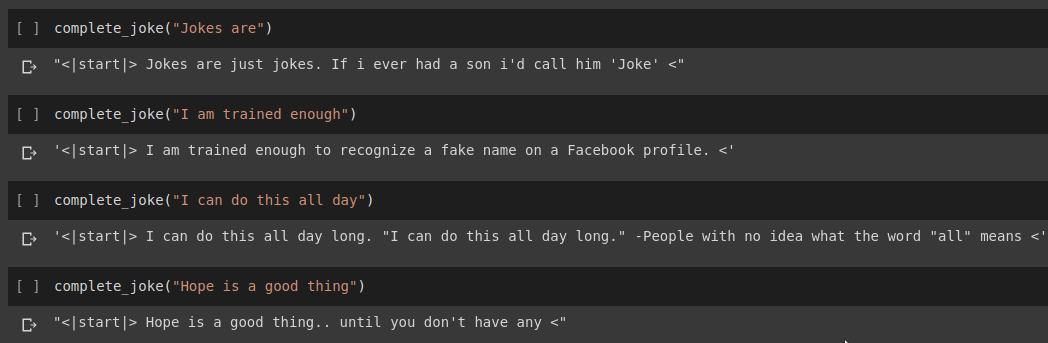
結果
對於我們的任務,我們將使用 Kaggle 上提供的資料集。它是一個 csv,包含超過 200000 個從 Reddit 上刪除的短笑話。
注意:由於該資料集只是從各個 Reddit 子版塊中刪除的,因此資料集中的大量笑話相當種族主義和性別歧視。由於任何人工智慧都將其訓練資料視為單一知識來源,因此應該預期我們的模型有時會產生類似的笑話。
一旦我們標記了我們的笑話字串,我們就在標記化列表的末尾添加一個start_token和一個end_token 。此外,由於我們的笑話字串可能具有不同的長度,我們還在所有字串中應用填充到指定的max_length以便所有批次中的所有張量具有相似的形狀。
相關程式碼可以在筆記本Joke Generation.ipynb中找到。在此,我們將從 HuggingFace 庫中匯入 GPT2Tokenizer 和 TFGPT2LMHead 模型。程式碼是用Tensorflow2寫的。筆記本上有註釋,在適當的位置提供了程式碼的解釋。此外,HuggingFace 文件還提供了關於模型的輸入參數和傳回值的良好文件。基於 PyTorch 的實現,請參閱 Tanul Singh 的 Humour.ai 儲存庫
程式碼可以在筆記本Joke_Completion_Pure_TF2_Implementation.ipynb中找到。為了更深入了解專案的工作原理,我嘗試在沒有外部程式庫的情況下建立變壓器。我參考了 Tensorflow 提供的 Transformers 教程,並將他們教程中提到的一些解釋放在我的筆記本中,並進行了進一步的解釋,以便輕鬆理解發生了什麼。
我首先為我們的資料集建立了一個分詞器,並使用它對字串進行分詞。然後,為Positional Encodings和MultiHeadAttention建造一個層。此外,我還使用Lambda layer為我們的資料建立合適的遮罩。
然後我創建了為我們的解碼器建立單一decoder layer方法。以下是單一解碼器層的架構。
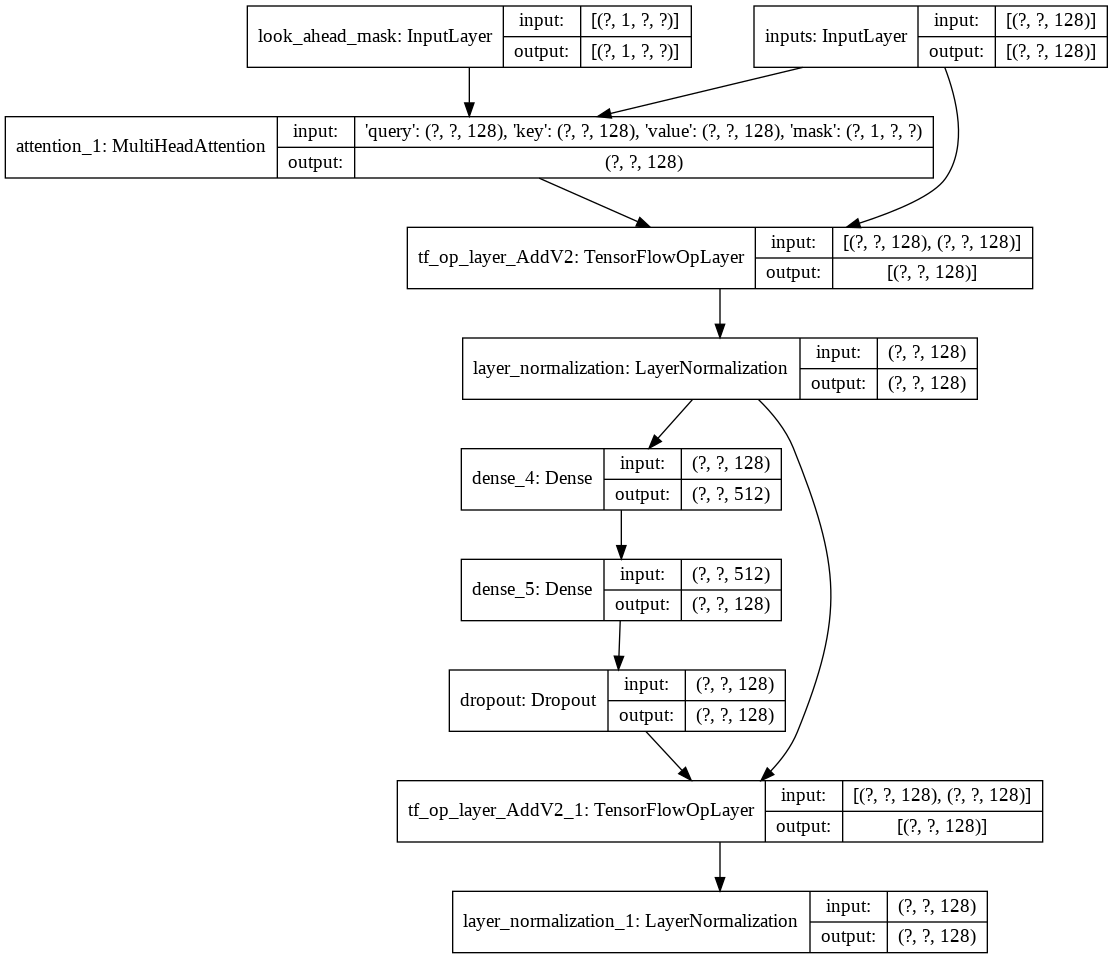
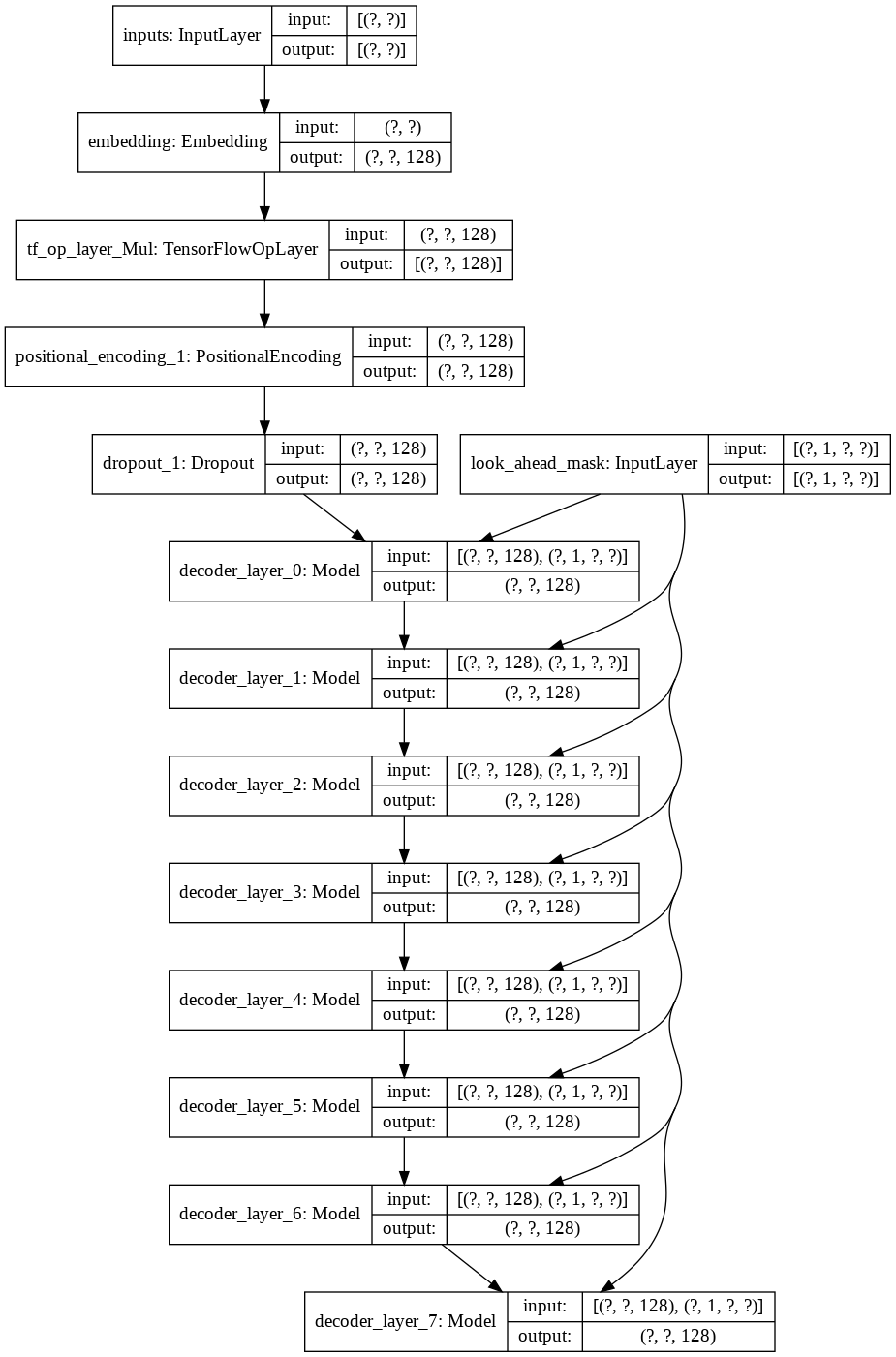
對於最終的transformer模型,它會取得輸入標記,將其傳遞到 lamda 層以獲取掩碼,並將掩碼和標記傳遞到我們的語言解碼器,然後將其輸出傳遞到密集層。以下是我們最終模型的架構。