mlmm evaluation
1.0.0
多語言大語言模型評估框架
此儲存庫包含多語言大型語言模型 (LLM) 的基準資料集和評估腳本。這些資料集可用於評估 26 種不同語言的模型,並涵蓋三個不同的任務:ARC、HellaSwag 和 MMLU。這是作為我們的 Okapi 框架的一部分發布的,該框架用於根據人類回饋進行強化學習的多語言指令調整法學碩士。
目前,我們的資料集支援26 種語言:俄語、德語、中文、法語、西班牙語、義大利語、荷蘭語、越南語、印尼語、阿拉伯語、匈牙利語、羅馬尼亞語、丹麥語、斯洛伐克語、烏克蘭語、加泰隆尼亞語、塞爾維亞語、克羅埃西亞語、印地語、孟加拉語、泰米爾語、尼泊爾語、馬拉雅拉姆語、馬拉地語、泰盧固語和卡納達語。
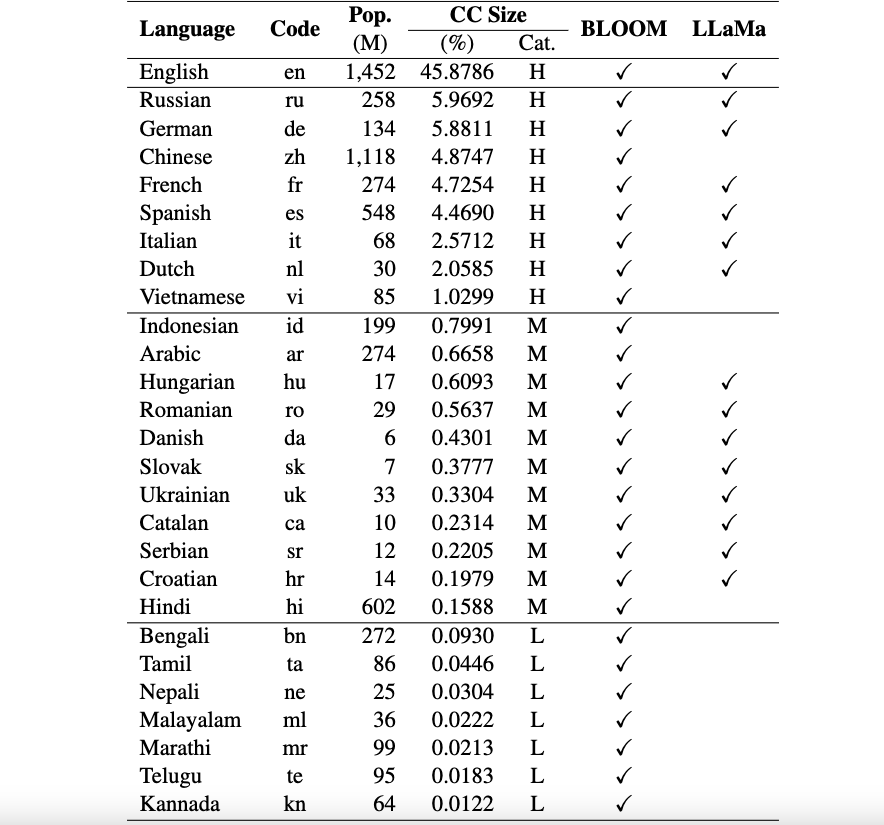
這些資料集是使用 ChatGPT 從原始 ARC、HellaSwag 和 MMLU 資料集翻譯成英文的。您可以在此處找到我們針對 Okapi 的技術論文,該論文描述了資料集以及多個多語言 LLM(例如 BLOOM、LLaMa 和我們的 Okapi 模型)的評估結果。
使用和許可聲明:我們的評估框架僅供研究使用並獲得許可。資料集為 CC BY NC 4.0(僅允許非商業用途),不得在研究目的之外使用。
若要從我們的儲存庫主分支安裝lm-eval ,請執行:
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e " .[multilingual] " 首先,您需要使用以下腳本下載多語言評估資料集:
bash scripts/download.sh要在三個任務上評估模型,您可以使用以下腳本:
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]例如,如果您想評估我們的 Okapi Vietnam 模型,您可以執行:
bash scripts/run.sh vi uonlp/okapi-vi-bloom我們維護一個排行榜來追蹤多語言法學碩士的進度。
我們的框架主要繼承自 EleutherAI 的 lm-evaluation-harness 儲存庫。如果您使用該程式碼,也請引用他們的儲存庫。
如果您使用此儲存庫中的資料、模型或程式碼,請引用:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

