羊駝-rlhf
使用 RLHF(帶有人類回饋的強化學習)微調 LLaMA。
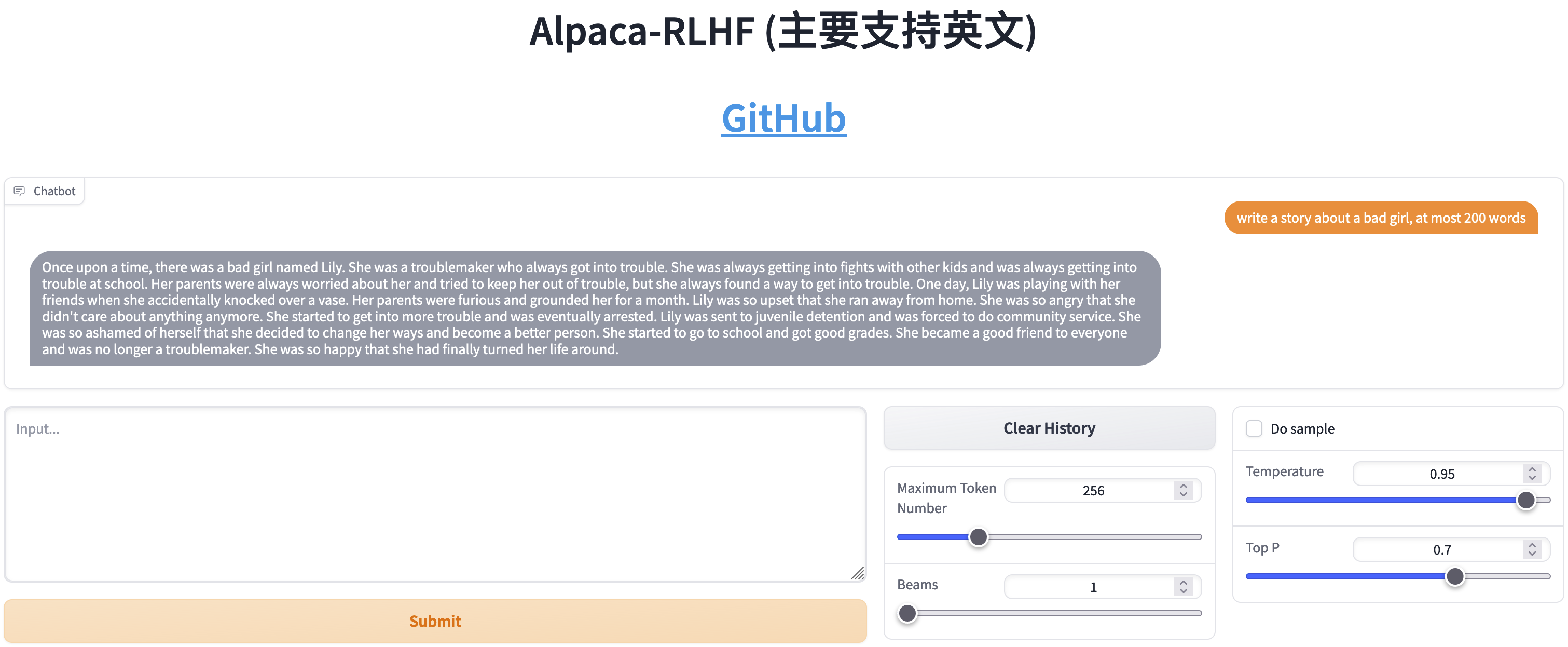
線上示範
DeepSpeed Chat 的修改
步驟1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- 僅針對反應進行訓練並添加 eos
- 刪除 end_of_conversation_token
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
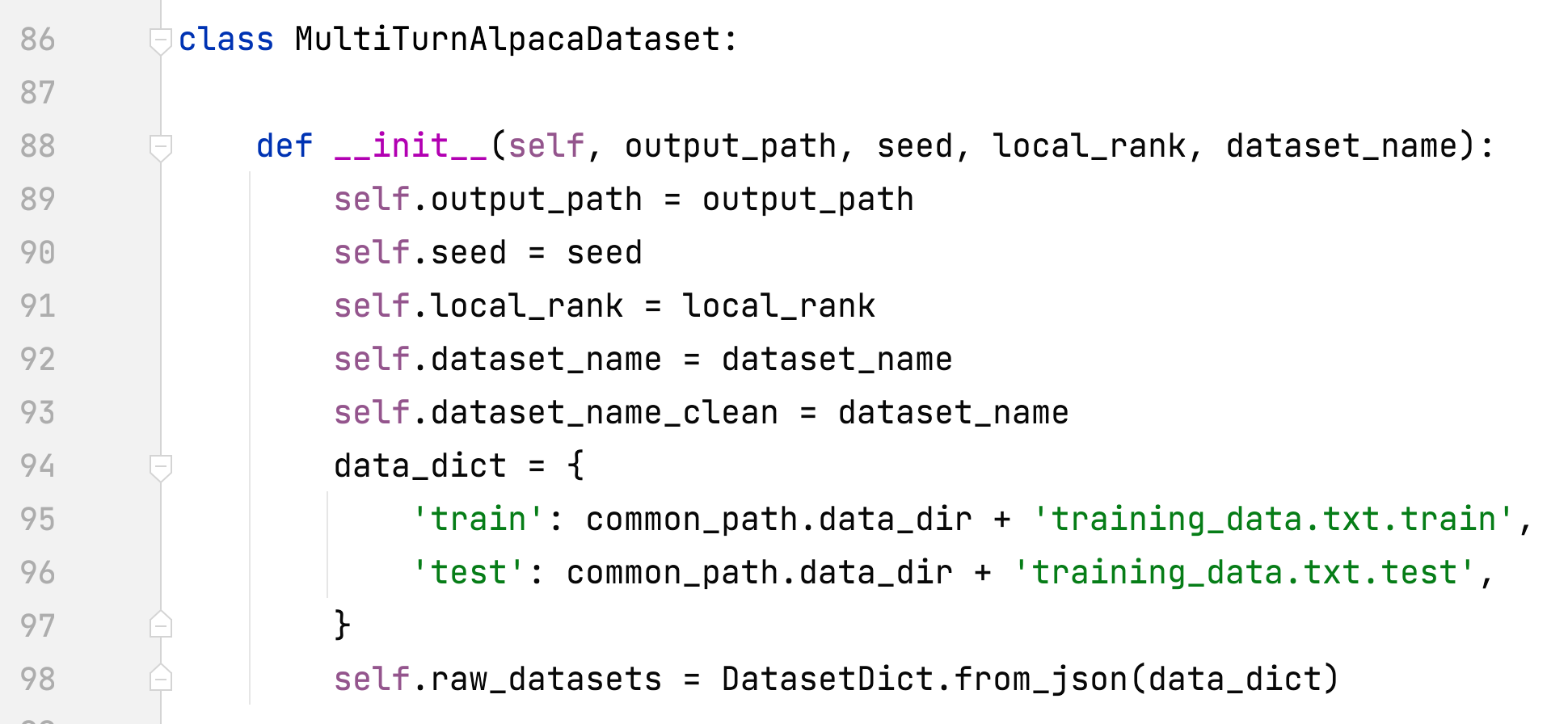
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- 新增 MultiTurnAlpacaDataset
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
步驟2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- 刪除 end_of_conversation_token
步驟3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollateRLHF#調用
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
斯泰一步一步
- 在 2 x A100 80G 上運行所有三個步驟
- 數據集
- Dahoas/rm-static Huggingface 論文 GitHub
- 多圈羊駝毛
- 這是 alpaca 資料集的多輪版本,基於 AlpacaDataCleaned 和 ChatAlpaca 建置。
- 先進入./alpaca_rlhf目錄,然後執行以下指令:
- 步驟1:sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_fTurnAlpaca --s_r/ppaca --s/Fir_Felpacao_r/firpaca --Fel_mp/gpaca +/sad-pir/Fir_Firpaca +/Fir_gpaca +/Fir_gpa/Fir_Firpaca --d/Fir_mp/Fir_Felpaca --d/garapa(Ft/Fir_Firpaca +/Fir_gpaca>/Fir_mp/Fir_Fel/gpaca +/sad-gL/Fir_Fel/gpaca +/sad-gL/Fir_Firpaca --d/Fel(Felpacas>/Firpaca>/Fir_Felpaca --s/p.^gpa research /llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_warps 88/Ft. f/actor - -lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- 新增--sft_only_data_path MultiTurnAlpaca時,請先解壓縮data/data.zip。
- 步驟2: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /cap/audop-tmp-meperfalage/poda-h/lowm. 7b -hf --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_step 108/m dl-tmp/ rlhf /critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
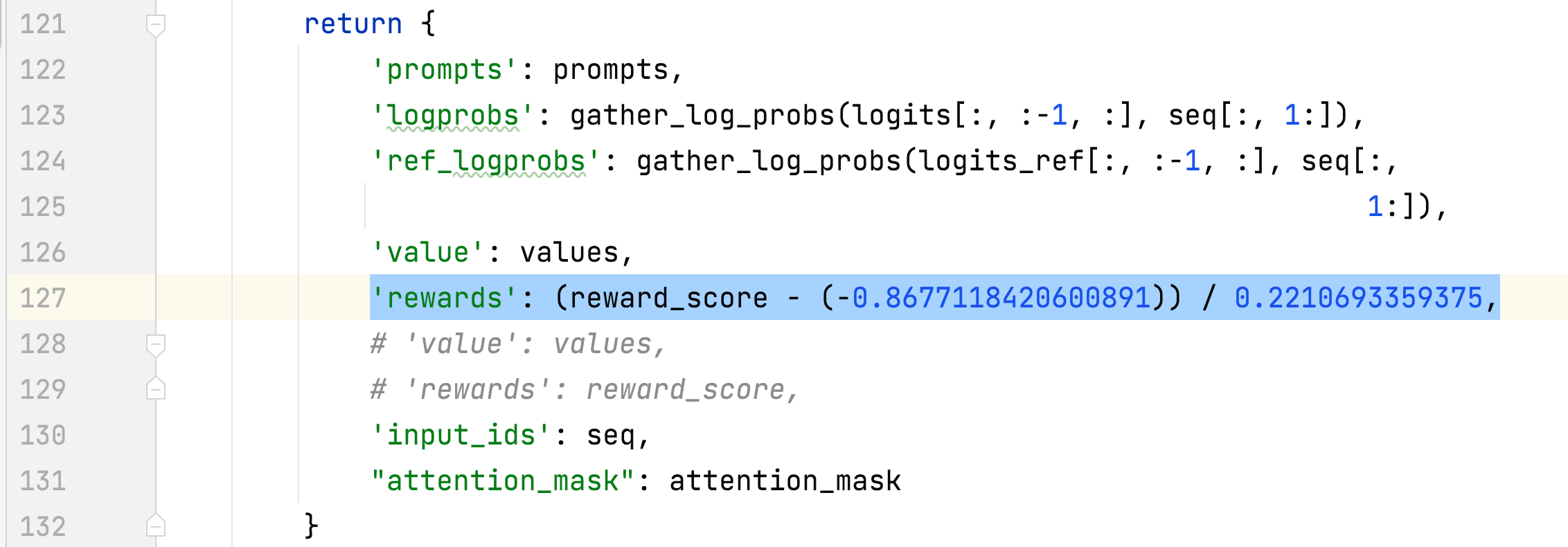
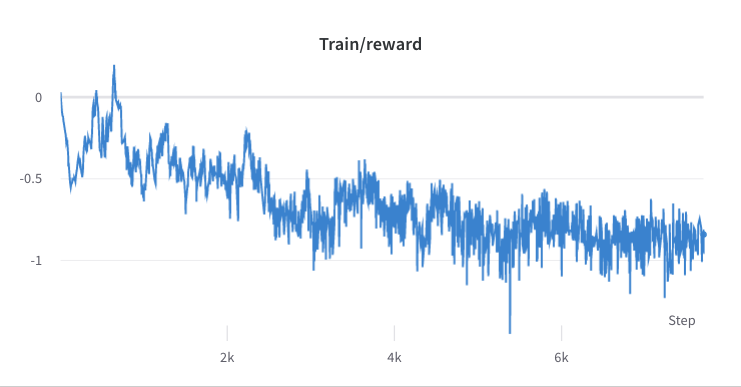
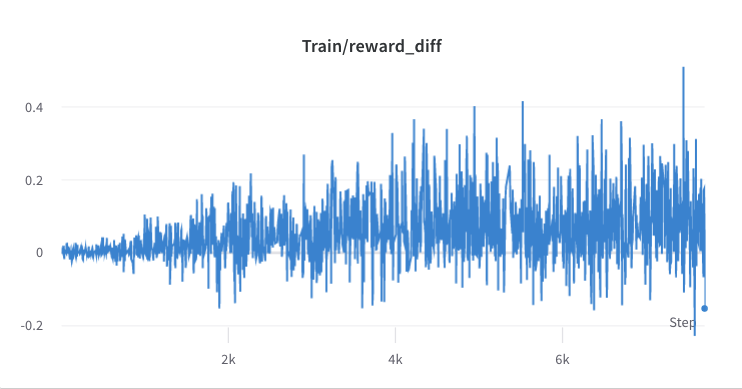
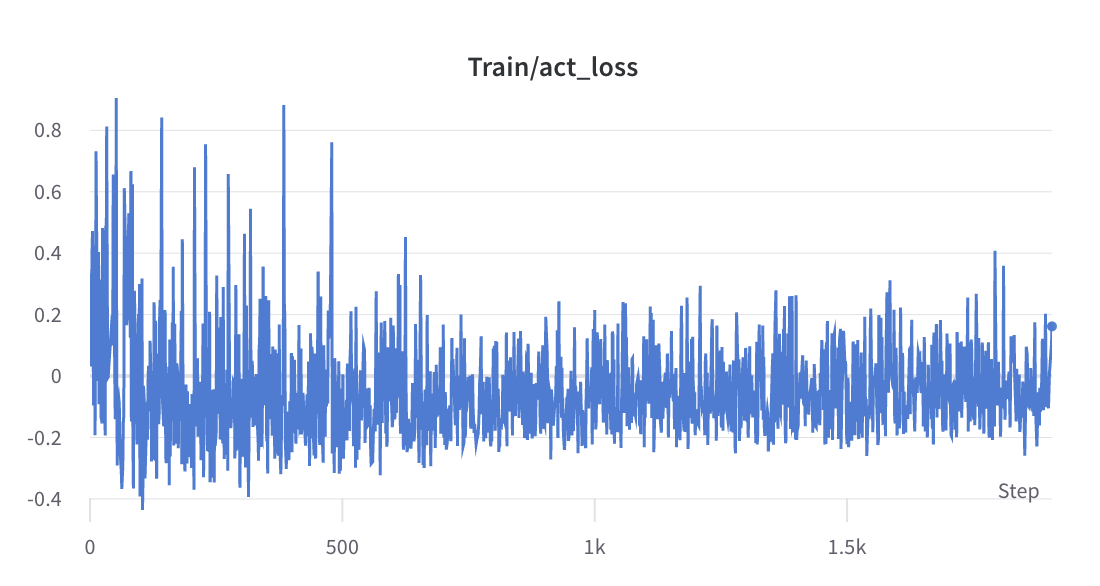
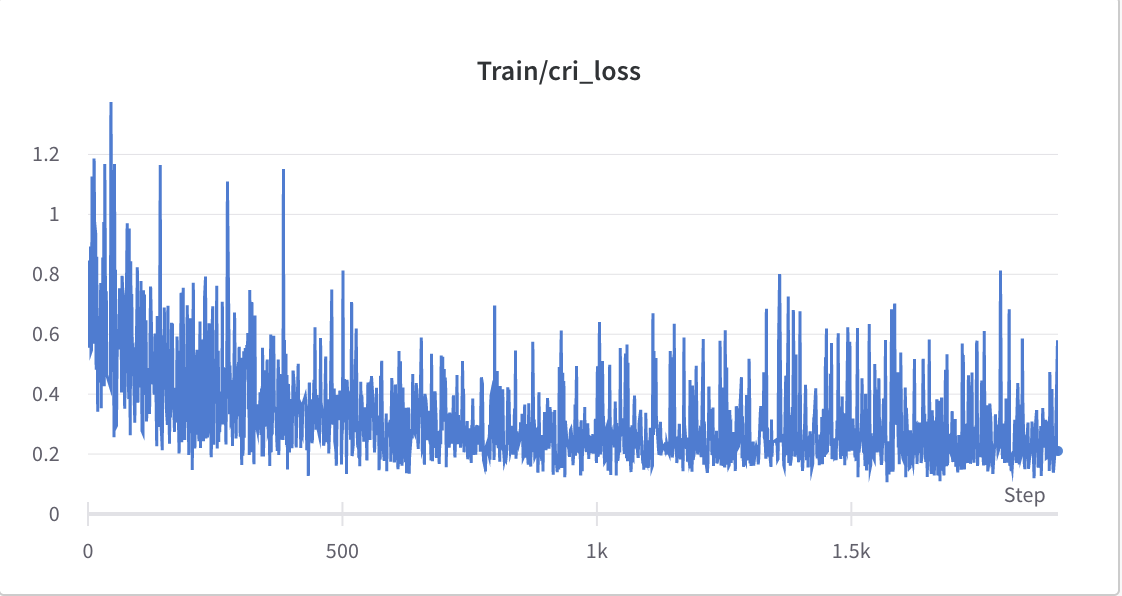
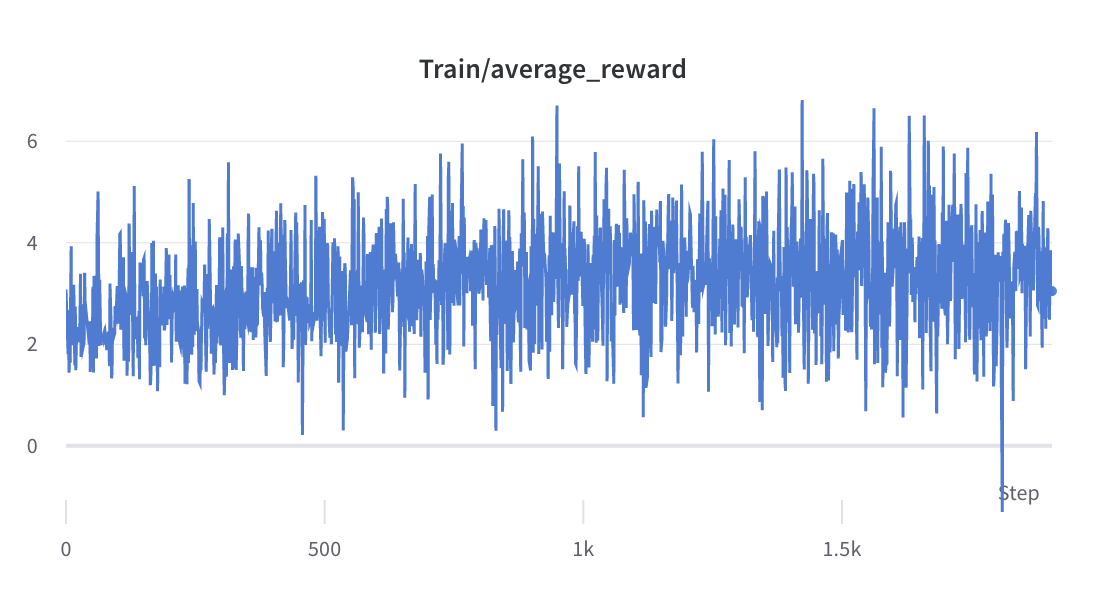
- 步驟2的訓練過程
- 收集所選回應的獎勵的平均值和標準差,並用於標準化步驟 3 中的獎勵。 #DeepSpeedPPOTrainer#generate_experience 方法:'獎勵':(reward_score - (-0.8677118420600891)) / 0.2210693359375。
- 步驟3: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/dl_/tmp/smpus_mpdeld_path / rlhf/actor/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 200000 _m-fperk-_perning_fperning_fper _perning_fperin_fperk _perning _perning_fper _perning_fper; _mini_train_batch_size 4 - -ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_projnamentic_lora_dim 8 --actor_lora_module_name q_projname, 8,8,0 optimize_lora --output_dir /root / autodl-tmp/rlhf/最終
- 推理
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
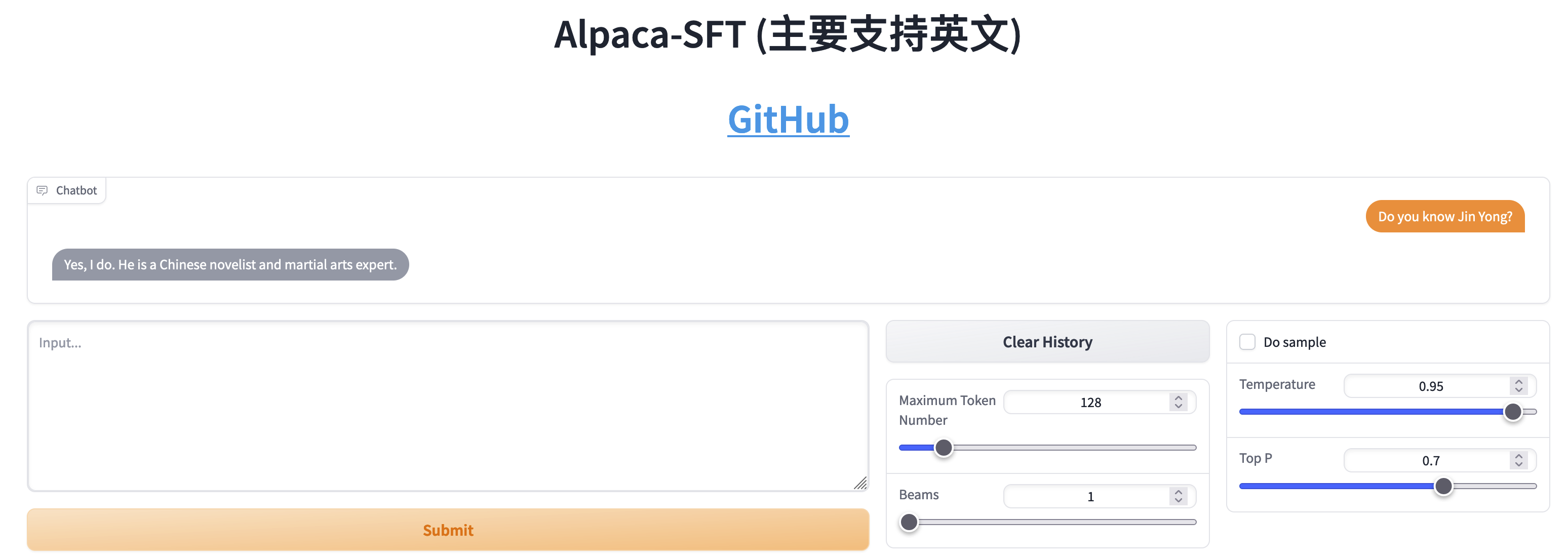
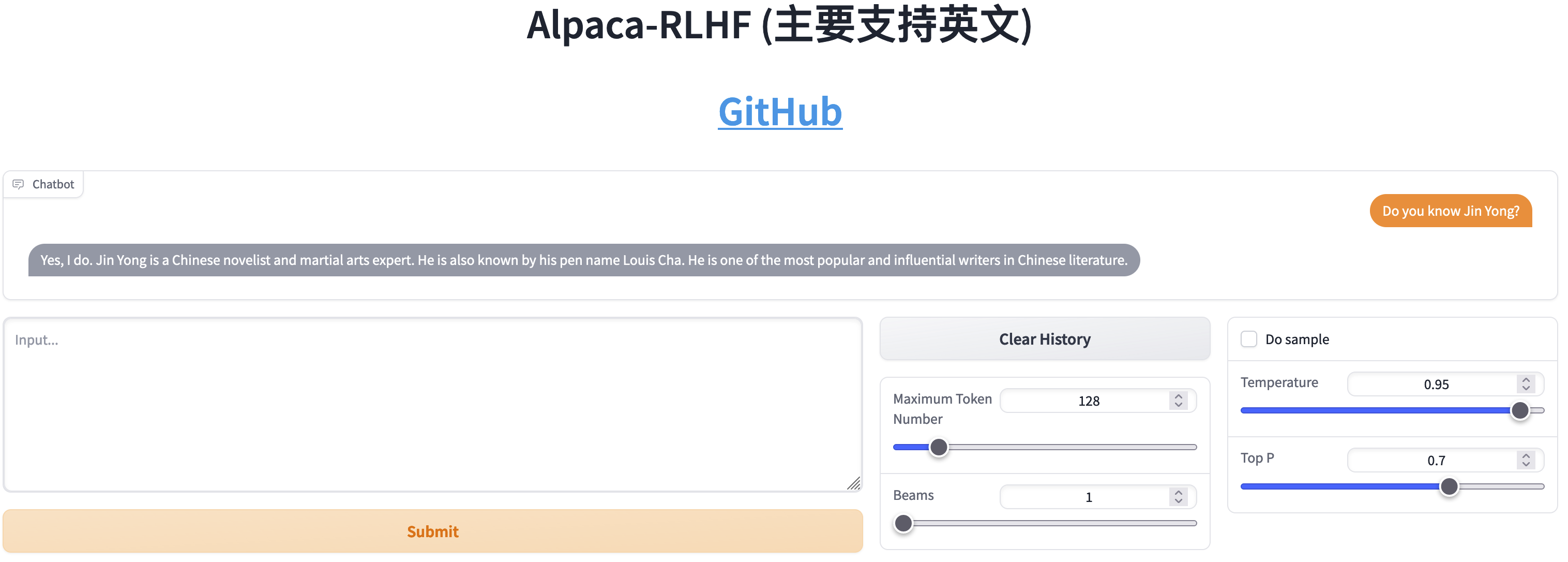
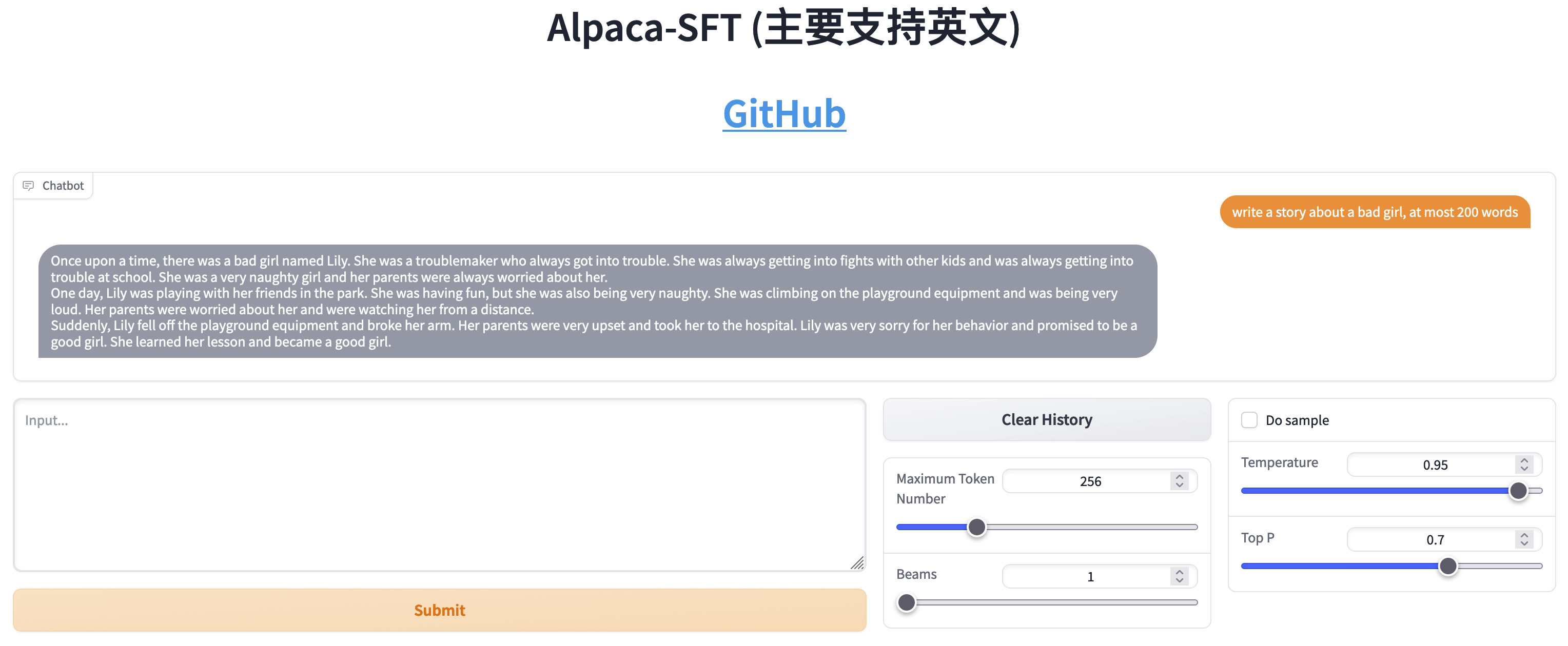
SFT與RLHF的比較
參考
文章
- 如何正確指示GPT / RLHF?
- 影響PPO演算法效能的10個關鍵技巧(附PPO演算法簡潔Pytorch實作)
來源
工具
數據集
- 史丹佛人類偏好資料集 (SHP)
- HH-RLHF
- hh-rlhf
- 透過人類回饋的強化學習來訓練一個有用且無害的助手 [論文]
- 達霍斯/靜態-hh
- 達霍斯/rm-靜態
- GPT-4-法學碩士
- 打開助手
相關儲存庫