icl selective annotation
1.0.0
論文程式碼選擇性註釋使語言模型更好少樣本學習者
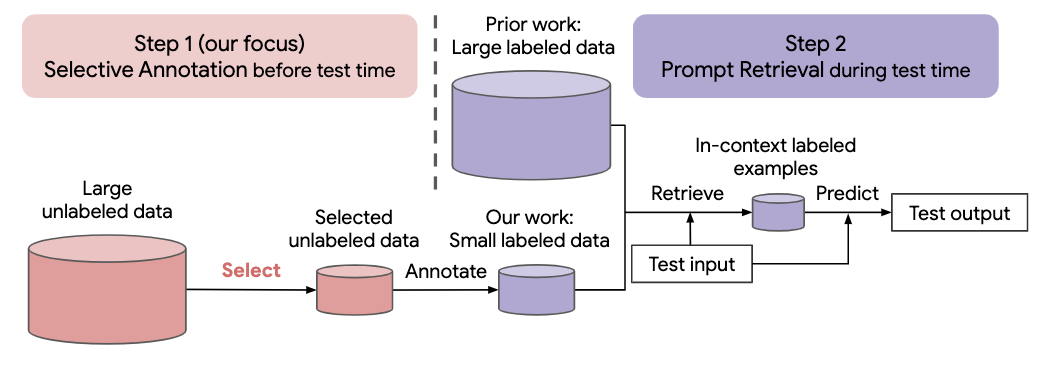
最近許多自然語言任務的方法都是建立在大型語言模型的卓越能力之上的。大型語言模型可以執行上下文學習,從一些任務演示中學習新任務,而無需任何參數更新。這項工作研究了情境學習對於為新的自然語言任務創建資料集的影響。與最近的上下文學習方法不同,我們制定了一個高效註釋的兩步驟框架:選擇性註釋,提前從未標記的資料中選擇一個範例池進行註釋,然後進行提示檢索,從註釋池中檢索任務範例測試時間。基於這個框架,我們提出了一種無監督的、基於圖的選擇性註釋方法, vote-k ,來選擇多樣化的、有代表性的示例進行註釋。對 10 個資料集(涵蓋分類、常識推理、對話和文字/程式碼生成)的廣泛實驗表明,我們的選擇性註釋方法大幅提高了任務效能。平均而言,與隨機選擇範例進行註釋相比,vote-k 在 18/100 的註釋預算下實現了12.9%/11.4% 的相對增益。與最先進的監督微調方法相比,它在 10 個任務中產生相似的效能,但註釋成本降低了 10-100 倍。我們進一步分析了我們的框架在各種場景中的有效性:不同大小的語言模型、替代的選擇性註釋方法以及存在測試資料域轉移的情況。隨著大型語言模型越來越多地應用於新任務,我們希望我們的研究能夠成為資料註釋的基礎
運行以下命令來克隆此存儲庫
git clone https://github.com/HKUNLP/icl-selective-annotation
若要建立環境,請在 shell 中執行以下程式碼:
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
這將創建我們使用的環境selective_annotation。
透過運行激活環境
conda activate selective_annotation
GPT-J作為情境學習模型,DBpedia作為任務,vote-k作為選擇性標註方法(1個GPU,40GB記憶體)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
如果您發現我們的工作有幫助,請引用我們
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


