automata
v0.0.4
automata的靈感來自於這樣的理論:程式碼本質上是一種記憶形式,當配備正確的工具時,人工智慧可以進化出即時能力,這有可能導致通用人工智慧的誕生。 automata一詞源自希臘語αὐτόματος,表示“自我行動、自我意志、自我移動”, automata理論是對抽象機器和automata以及可以使用它們解決的計算問題的研究。
更多資訊如下。
請依照以下步驟設定automata環境
# Clone the repository
git clone [email protected]:emrgnt-cmplxty/ automata .git && cd automata /
# Initialize git submodules
git submodule update --init
# Install poetry and the project
pip3 install poetry && poetry install
# Configure the environment and setup files
poetry run automata configure拉取 Docker 映像:
$ docker pull ghcr.io/emrgnt-cmplxty/ automata :latest運行 Docker 映像:
$ docker run --name automata _container -it --rm -e OPENAI_API_KEY= < your_openai_key > -e GITHUB_API_KEY= < your_github_key > ghcr.io/emrgnt-cmplxty/ automata :latest這將啟動一個安裝了automata Docker 容器,並開啟一個互動式 shell 供您使用。
Windows 使用者可能需要透過 Visual Studio 的「使用 C++ 進行桌面開發」來安裝 C++ 支援以取得某些依賴項。
此外,可能需要更新至 gcc-11 和 g++-11。這可以透過執行以下命令來完成:
# Adds the test toolchain repository, which contains newer versions of software
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
# Updates the list of packages on your system
sudo apt update
# Installs gcc-11 and g++-11 packages
sudo apt install gcc-11 g++-11
# Sets gcc-11 and g++-11 as the default gcc and g++ versions for your system
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-11 60 --slave /usr/bin/g++ g++ /usr/bin/g++-11執行automata搜尋需要 SCIP 索引。這些索引用於建立程式碼圖,該程式碼圖透過程式碼庫中的依賴關係來關聯符號。 automata程式碼庫會定期產生和上傳新索引,但如果本機開發需要,程式設計師必須手動產生它們。如果您遇到問題,我們建議您參考此處的說明。
# Install dependencies and run indexing on the local codebase
poetry run automata install-indexing # Refresh the code embeddings (after making local changes)
poetry run automata run-code-embedding
# Refresh the documentation + embeddings
poetry run automata run-doc-embedding --embedding-level=2
以下命令說明如何使用簡單的指令來運行系統。建議您進行此類初始運行,以確保系統按預期工作。
# Run a single agent w/ trivial instruction
poetry run automata run-agent --instructions= " Return true " --model=gpt-3.5-turbo-0613
# Run a single agent w/ a non-trivial instruction
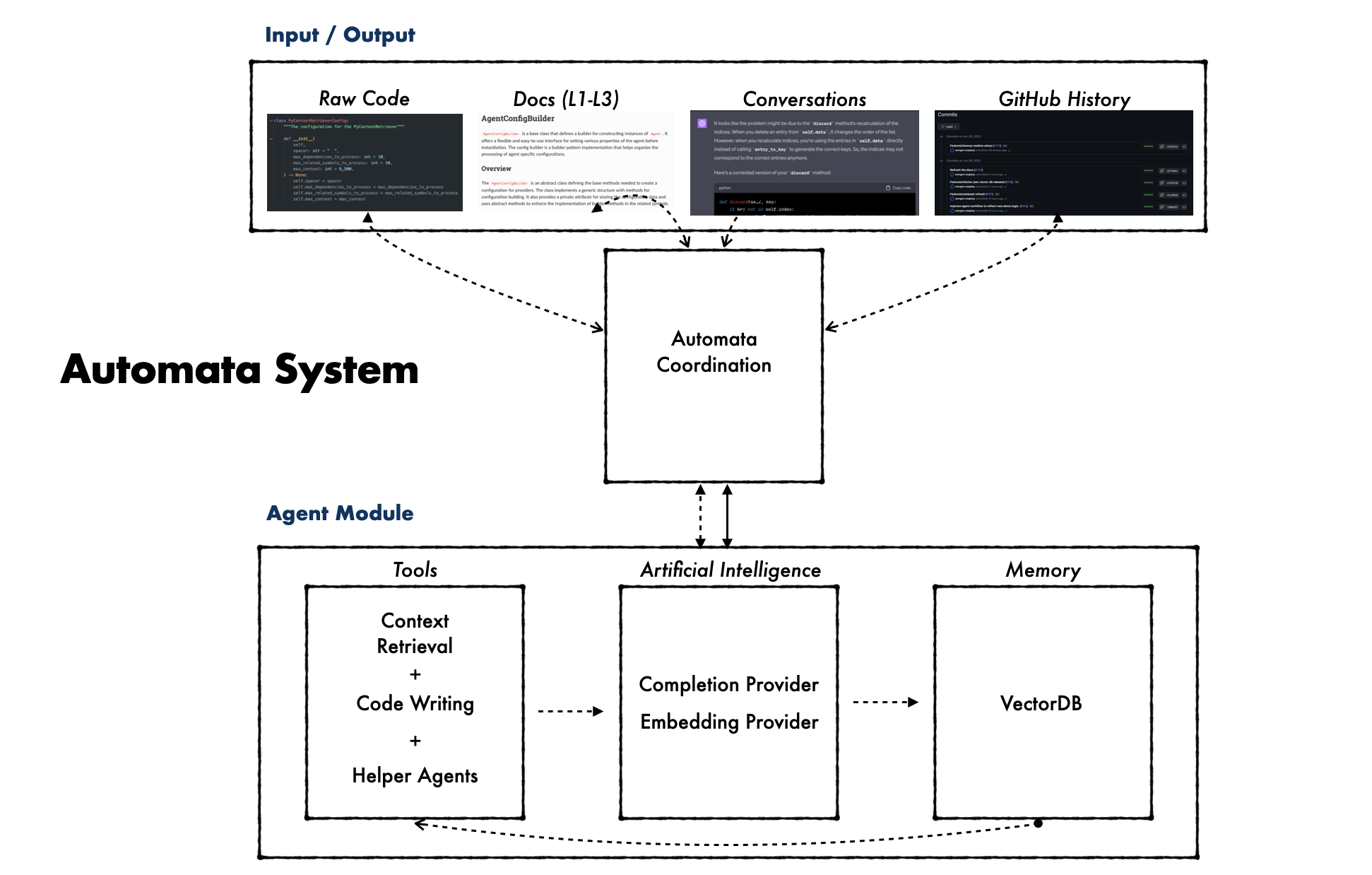
poetry run automata run-agent --instructions= " Explain what automata Agent is and how it works, include an example to initialize an instance of automata Agent. " automata工作原理是將大型語言模型(例如 GPT-4)與向量資料庫結合,形成一個能夠記錄、搜尋和編寫程式碼的整合系統。這個過程從產生全面的文檔和程式碼實例開始。這與搜尋功能結合,構成了automata自編碼潛力的基礎。
automata採用下游工具來執行高階編碼任務,並不斷建構其專業知識與自主性。這種自編碼方法反映了自主工匠的工作,其中工具和技術根據回饋和累積的經驗不斷完善。
有時,理解複雜系統的最佳方法是從理解基本範例開始。以下範例說明如何運行您自己的automata代理程式。代理程式將使用一條簡單的指令進行初始化,然後嘗試編寫程式碼來完成指令。然後代理將返回其嘗試的結果。
from automata . config . base import AgentConfigName , OpenAI automata AgentConfigBuilder
from automata . agent import OpenAI automata Agent
from automata . singletons . dependency_factory import dependency_factory
from automata . singletons . py_module_loader import py_module_loader
from automata . tools . factory import AgentToolFactory
# Initialize the module loader to the local directory
py_module_loader . initialize ()
# Construct the set of all dependencies that will be used to build the tools
toolkit_list = [ "context-oracle" ]
tool_dependencies = dependency_factory . build_dependencies_for_tools ( toolkit_list )
# Build the tools
tools = AgentToolFactory . build_tools ( toolkit_list , ** tool_dependencies )
# Build the agent config
agent_config = (
OpenAI automata AgentConfigBuilder . from_name ( " automata -main" )
. with_tools ( tools )
. with_model ( "gpt-4" )
. build ()
)
# Initialize and run the agent
instructions = "Explain how embeddings are used by the codebase"
agent = OpenAI automata Agent ( instructions , config = agent_config )
result = agent . run ()此程式碼庫中的嵌入由SymbolCodeEmbedding和SymbolDocEmbedding等類別表示。這些類別儲存有關符號及其各自嵌入的信息,嵌入是表示高維空間中符號的向量。
這些類別的範例有: SymbolCodeEmbedding用於儲存與符號代碼相關的嵌入的類別。 SymbolDocEmbedding一個用於儲存與符號文件相關的嵌入的類別。
建立“SymbolCodeEmbedding”實例的程式碼範例:
import numpy as np
from automata . symbol_embedding . base import SymbolCodeEmbedding
from automata . symbol . parser import parse_symbol
symbol_str = 'scip-python python automata 75482692a6fe30c72db516201a6f47d9fb4af065 ` automata .agent.agent_enums`/ActionIndicator#'
symbol = parse_symbol ( symbol_str )
source_code = 'symbol_source'
vector = np . array ([ 1 , 0 , 0 , 0 ])
embedding = SymbolCodeEmbedding ( symbol = symbol , source_code = source_code , vector = vector )建立“SymbolDocEmbedding”實例的程式碼範例:
from automata . symbol_embedding . base import SymbolDocEmbedding
from automata . symbol . parser import parse_symbol
import numpy as np
symbol = parse_symbol ( 'your_symbol_here' )
document = 'A document string containing information about the symbol.'
vector = np . random . rand ( 10 )
symbol_doc_embedding = SymbolDocEmbedding ( symbol , document , vector )如果您想為automata做出貢獻,請務必查看貢獻指南。該項目遵守automata的行為準則。透過參與,您應該遵守此準則。
我們使用 GitHub issues 來追蹤請求和錯誤,請參閱automata討論以了解一般問題和討論,並請直接提出具體問題。
automata專案致力於遵守開源軟體開發中普遍接受的最佳實踐。
automata專案的最終目標是達到能夠獨立設計、編寫、測試和完善複雜軟體系統的熟練程度。這包括理解和導航大型程式碼庫、推理軟體架構、最佳化效能,甚至在必要時發明新演算法或資料結構的能力。
雖然完全實現這一目標可能是一項複雜且長期的努力,但朝著這一目標邁出的每一步不僅有可能顯著提高人類程式設計師的生產力,而且有可能揭示人工智慧和電腦的基本問題科學。
automata根據 Apache License 2.0 獲得許可。
該專案是 emrgnt-cmplxty 和 maks-ivanov 之間從該儲存庫開始的初始工作的擴展。


