YAYI UIE
1.0.0

[README] [?HF Repo] [?網頁端]
中文| English
[2024.03.28] 所有模式和資料上魔術搭社群。
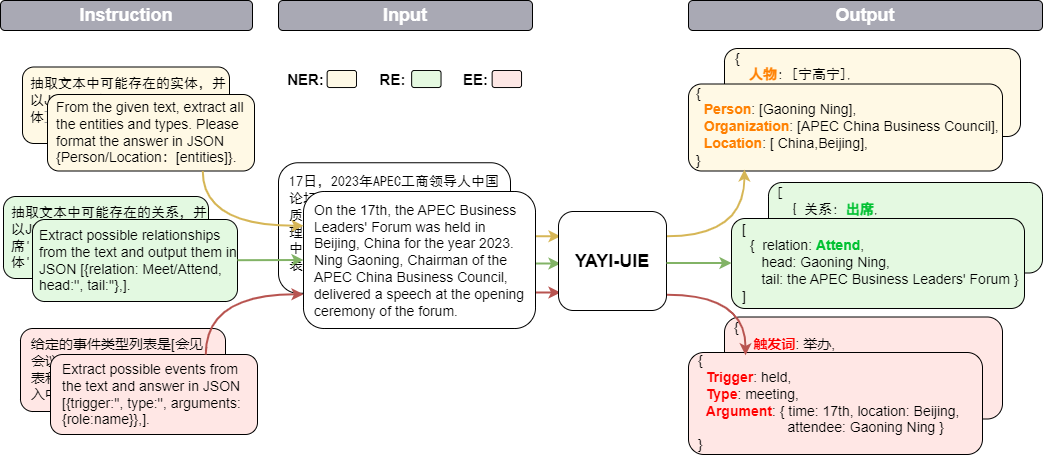
雅意資訊抽取統一大模型(YAYI-UIE)在百萬級人工構造的高品質資訊抽取資料上進行指令微調,統一訓練資訊抽取任務包括命名實體辨識(NER),關係抽取(RE)和事件抽取( EE),實現通用、安全、金融、生物、醫療、商業、個人、車輛、電影、工業、餐廳、科學等場景下結構化抽取。
透過雅意UIE大模型的開源為促進中文預訓練大模型開源社群的發展,貢獻自己的一份力量,透過開源,與每位合作夥伴共建雅意大模型生態。更多技術細節,歡迎閱讀我們的技術報告YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction。
| 名稱 | ? HF模型標識 | 下載地址 | 魔搭模型標識 | 下載地址 |
|---|---|---|---|---|
| YAYI-UIE | wenge-research/yayi-uie | 模型下載 | wenge-research/yayi-uie | 模型下載 |
| YAYI-UIE Data | wenge-research/yayi_uie_sft_data | 資料集下載 | wenge-research/yayi_uie_sft_data | 資料集下載 |
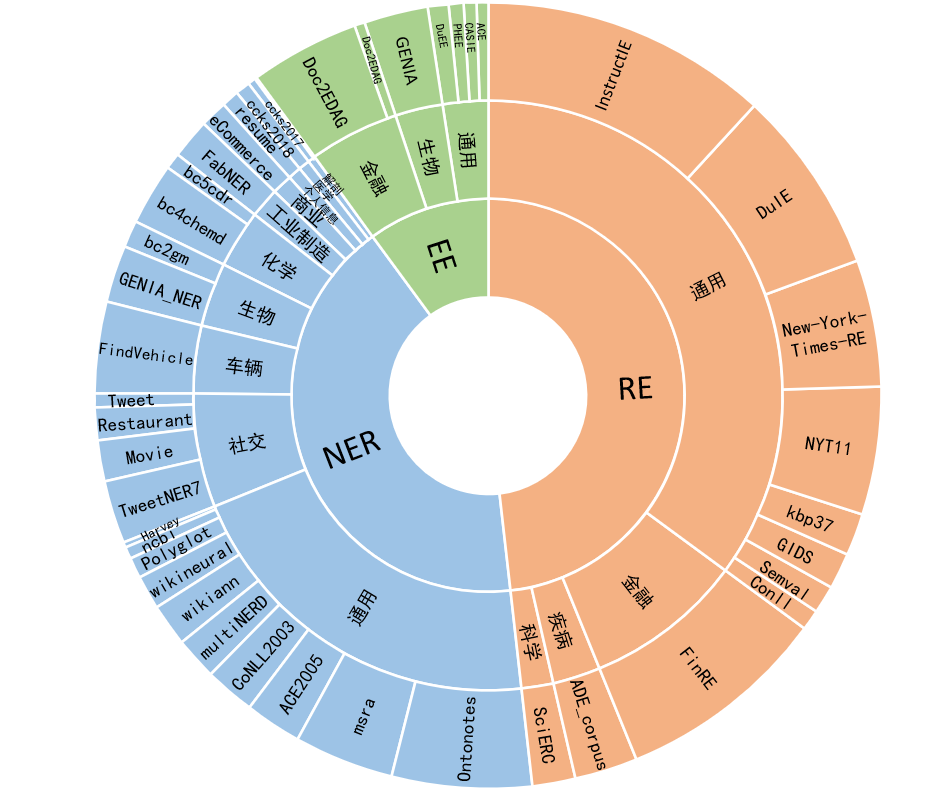
百萬級語料中文54%,英文46%;其中資料集包括12個領域包括金融,社會,生物,商業,工業製造,化學,車輛,科學,疾病醫療,個人生活,安全和通用。覆蓋數百個場景
git clone https://github.com/wenge-research/yayi-uie.git
cd yayi-uieconda create --name uie python=3.8
conda activate uiepip install -r requirements.txt其中torch和transformers版本不建議低於建議版本。
模型已在我們的Huggingface 模型倉庫開源,歡迎下載使用。以下是一個簡單呼叫YAYI-UIE進行下游任務推理的範例程式碼,可在單張A100/A800 等GPU運行,使用bf16精度推理時約佔用33GB 記憶體:
> >> import torch
> >> from transformers import AutoModelForCausalLM , AutoTokenizer
> >> from transformers . generation . utils import GenerationConfig
> >> tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi-uie" , use_fast = False , trust_remote_code = True )
> >> model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi-uie" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
> >> generation_config = GenerationConfig . from_pretrained ( "wenge-research/yayi-uie" )
> >> prompt = "文本:氧化锆陶瓷以其卓越的物理和化学特性在多个行业中发挥着关键作用。这种材料因其高强度、高硬度和优异的耐磨性,广泛应用于医疗器械、切削工具、磨具以及高端珠宝制品。在制造这种高性能陶瓷时,必须遵循严格的制造标准,以确保其最终性能。这些标准涵盖了从原材料选择到成品加工的全过程,保障产品的一致性和可靠性。氧化锆的制造过程通常包括粉末合成、成型、烧结和后处理等步骤。原材料通常是高纯度的氧化锆粉末,通过精确控制的烧结工艺,这些粉末被转化成具有特定微观结构的坚硬陶瓷。这种独特的微观结构赋予氧化锆陶瓷其显著的抗断裂韧性和耐腐蚀性。此外,氧化锆陶瓷的热膨胀系数与铁类似,使其在高温应用中展现出良好的热稳定性。因此,氧化锆陶瓷不仅在工业领域,也在日常生活中的应用日益增多,成为现代材料科学中的一个重要分支。 n抽取文本中可能存在的实体,并以json{制造品名称/制造过程/制造材料/工艺参数/应用/生物医学/工程特性:[实体]}格式输出。"
> >> # "<reserved_13>" is a reserved token for human, "<reserved_14>" is a reserved token for assistant
>> > prompt = "<reserved_13>" + prompt + "<reserved_14>"
> >> inputs = tokenizer ( prompt , return_tensors = "pt" ). to ( model . device )
> >> response = model . generate ( ** inputs , max_new_tokens = 512 , temperature = 0 )
> >> print ( tokenizer . decode ( response [ 0 ], skip_special_tokens = True ))註:
文本:xx
【实体抽取】抽取文本中可能存在的实体,并以json{人物/机构/地点:[实体]}格式输出。
文本:xx
【关系抽取】已知关系列表是[注资,拥有,纠纷,自己,增持,重组,买资,签约,持股,交易]。根据关系列表抽取关系三元组,按照json[{'relation':'', 'head':'', 'tail':''}, ]的格式输出。
文本:xx
抽取文本中可能存在的关系,并以json[{'关系':'会见/出席', '头实体':'', '尾实体':''}, ]格式输出。
文本:xx
已知论元角色列表是[时间,地点,会见主体,会见对象],请根据论元角色列表从给定的输入中抽取可能的论元,以json{角色:论元}格式输出。
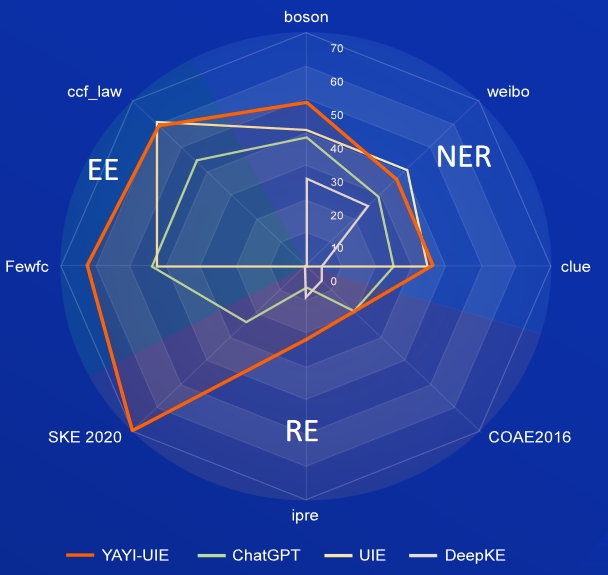
AI,Literature,Music,Politics,Science為英文資料集,boson,clue,weibo為中文資料集
| 模型 | AI | Literature | Music | Politics | Science | 英文平均 | boson | clue | 中文平均 | |
|---|---|---|---|---|---|---|---|---|---|---|
| davinci | 2.97 | 9.87 | 13.83 | 18.42 | 10.04 | 11.03 | - | - | - | 31.09 |
| ChatGPT 3.5 | 54.4 | 54.07 | 61.24 | 59.12 | 63 | 58.37 | 38.53 | 25.44 | 29.3 | |
| UIE | 31.14 | 38.97 | 33.91 | 46.28 | 41.56 | 38.37 | 40.64 | 34.91 | 40.79 | 38.78 |
| USM | 28.18 | 56 | 44.93 | 36.1 | 44.09 | 41.86 | - | - | - | - |
| InstructUIE | 49 | 47.21 | 53.16 | 48.15 | 49.3 | 49.36 | - | - | - | - |
| KnowLM | 13.76 | 20.18 | 14.78 | 33.86 | 9.19 | 18.35 | 25.96 | 4.44 | 25.2 | 18.53 |
| YAYI-UIE | 52.4 | 45.99 | 51.2 | 51.82 | 50.53 | 50.39 | 49.25 | 36.46 | 36.78 | 40.83 |
FewRe,Wiki-ZSL為英文資料集, SKE 2020,COAE2016,IPRE為中文資料集
| 模型 | FewRel | Wiki-ZSL | 英文平均 | SKE 2020 | COAE2016 | IPRE | 中文平均 |
|---|---|---|---|---|---|---|---|
| ChatGPT 3.5 | 9.96 | 13.14 | 11.55 24.47 | 19.31 | 6.73 | 16.84 | |
| ZETT(T5-small) | 30.53 | 31.74 | 31.14 | - | - | - | - |
| ZETT(T5-base) | 33.71 | 31.17 | 32.44 | - | - | - | - |
| InstructUIE | 39.55 | 35.2 | 37.38 | - | - | - | - |
| KnowLM | 17.46 | 15.33 | 16.40 | 0.4 | 6.56 | 9.75 | 5.57 |
| YAYI-UIE | 36.09 | 41.07 | 38.58 | 70.8 | 19.97 | 22.97 | 37.91 |
commodity news為英文資料集,FewFC,ccf_law為中文資料集
EET(事件類型判別)
| 模型 | commodity news | FewFC | ccf_law | 中文平均 |
|---|---|---|---|---|
| ChatGPT 3.5 | 1.41 | 16.15 | 0 | 8.08 |
| UIE | - | 50.23 | 2.16 | 26.20 |
| InstructUIE | 23.26 | - | - | - |
| YAYI-UIE | 12.45 | 81.28 | 12.87 | 47.08 |
EEA(事件論元抽取)
| 模型 | commodity news | FewFC | ccf_law | 中文平均 |
|---|---|---|---|---|
| ChatGPT 3.5 | 8.6 | 44.4 | 44.57 | 44.49 |
| UIE | - | 43.02 | 60.85 | 51.94 |
| InstructUIE | 21.78 | - | - | - |
| YAYI-UIE | 19.74 | 63.06 | 59.42 | 61.24 |
基於目前資料和基礎模型訓練所得的SFT模型,在效果上仍有以下問題:
基於上述模型局限性,我們要求開發者僅將我們開源的程式碼、資料、模型及後續用此專案產生的衍生物用於研究目的,不得用於商業用途,以及其他會對社會帶來危害的用途。請謹慎辨別並使用雅意大模型產生的內容,請勿將產生的有害內容傳播至網路。若產生不良後果,由傳播者自負。 本專案僅可應用於研究目的,專案開發者不承擔任何因使用本專案(包含但不限於資料、模型、程式碼等)而導致的危害或損失。詳細請參考免責聲明。
本專案中的程式碼和資料依照Apache-2.0 協定開源,社群使用YAYI UIE模型或其衍生性商品請遵循Baichuan2的社群協議和商用協議。
如果您在您的作品中使用了我們的模型,可以引用我們的論文:
@article{YAYI-UIE,
author = {Xinglin Xiao, Yijie Wang, Nan Xu, Yuqi Wang, Hanxuan Yang, Minzheng Wang, Yin Luo, Lei Wang, Wenji Mao, Dajun Zeng}},
title = {YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction},
journal = {arXiv preprint arXiv:2312.15548},
url = {https://arxiv.org/abs/2312.15548},
year = {2023}
}


