Dropout NeuralNetworks
1.0.0
在這個研究計畫中,我將重點放在改變輟學率對 MNIST 資料集的影響。我的目標是用研究論文中使用的資料重現下圖。這個專案的目的是了解機器學習圖形是如何產生的。具體來說,了解更改/不更改丟失機率時對分類錯誤的影響。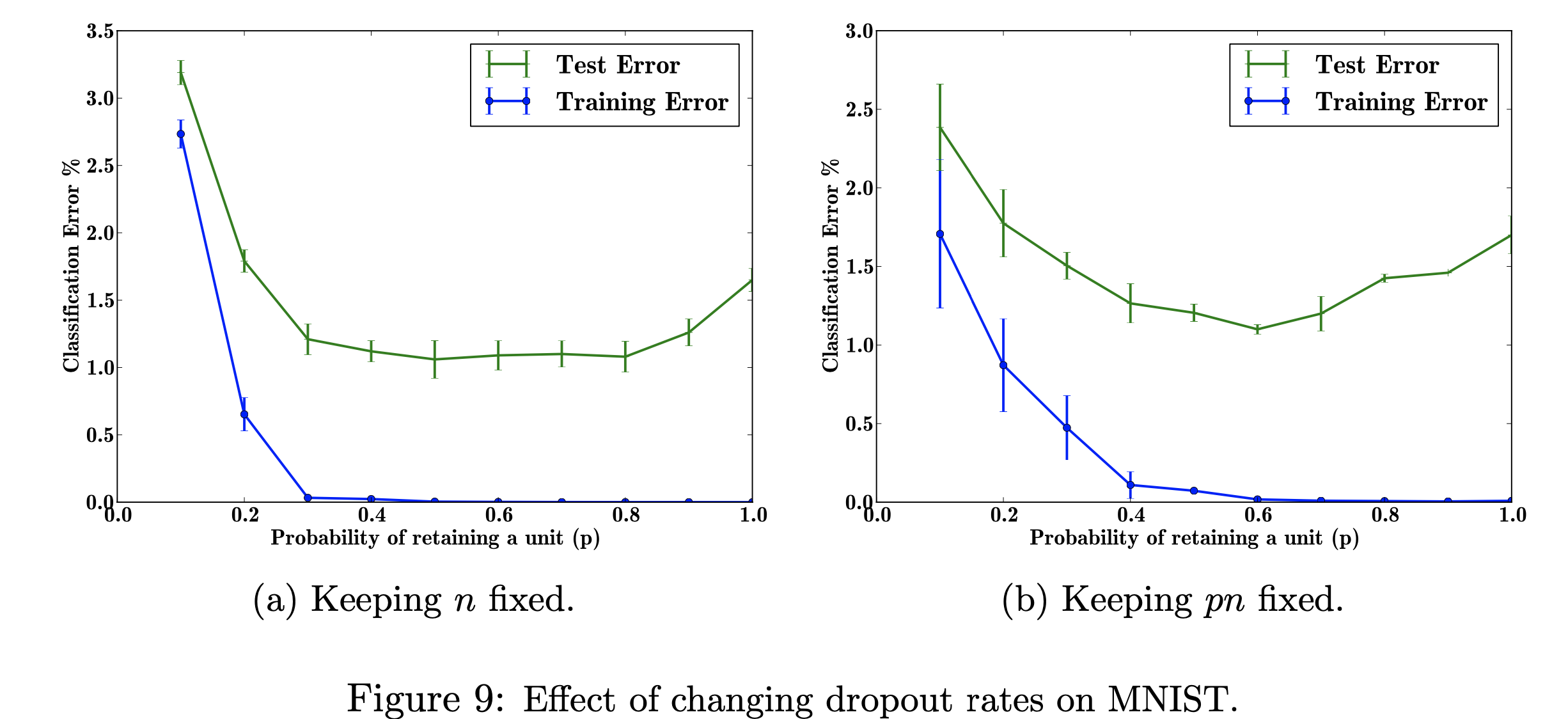 圖參考自:Srivastava, N.、Hinton, G.、Krizhevsky, A.、Krizhevsky, I.、Salakhutdinov, R.,Dropout:防止神經網路過度擬合的簡單方法,圖 9
圖參考自:Srivastava, N.、Hinton, G.、Krizhevsky, A.、Krizhevsky, I.、Salakhutdinov, R.,Dropout:防止神經網路過度擬合的簡單方法,圖 9
我使用 TensorFlow 在 MNIST 資料集上運行 dropout,使用 Matplotlib 來幫助重新建立論文中的圖形。我還使用內建的 Decimal 庫來計算 p 的不同值,從 0.0 到 1.0。匯入庫「csv」用於將先前執行的資料新增至 CSV 檔案中,以節省計算已計算的 p 值的時間。導入 Numpy 是為了讓繪圖在 x 軸和 y 軸上具有相同的步長。最後,我導入了“os”,這樣我就可以消除由於使用 CPU 而不是 GPU 導致的錯誤。
探索可調超參數「p」(在網路中保留單元的機率)和隱藏層數量「n」的不同值對錯誤率的影響。當 p 和 n 的乘積固定時,我們可以看到,與保持隱藏層數量不變(圖 9b)相比,小 p 值的誤差幅度有所減少(圖 9a)。
由於訓練資料有限,輸入/輸出之間的許多複雜關係將是採樣雜訊的結果。它們將存在於訓練集中,但不會存在於真實的測試資料中,即使它是從相同的分佈中提取的。這種複雜性會導致過度擬合,這是有助於防止這種情況發生的演算法之一。此圖的輸入是手寫數字的資料集,添加 dropout 後的輸出是描述應用 dropout 方法的結果的不同值。總而言之,添加 dropout 後錯誤會減少。
這可以適用的一個現實世界問題是谷歌搜索,有人可能正在搜索電影標題,但他們可能只是在尋找圖像,因為他們是更多的視覺學習者。因此,刪除文字部分或簡短的解釋將幫助您專注於圖像特徵。文章指出了他們從何處檢索資料 (http://yann.lecun.com/exdb/mnist/)。每個影像都是 28x28 數位表示。 y 標籤似乎是圖像資料列。
我重現該圖的目標是測試/訓練資料並計算每個機率 p(在網路中保留單元的機率)的分類誤差。我的目標是讓 p 隨著誤差的下降而增加,以表明我的實現是有效的,並且我將調整這個超參數以獲得相同的結果。我將透過使用 784-2048-2048-2048-10 架構循環遍歷所有訓練和測試資料來完成此操作,並保持 n 固定,然後更改 pn 進行固定。然後我會將資料收集/寫入 csv 檔案。然後,該 csv 檔案將包含輸出圖形所需的所有資料。在這個專案中,我將了解丟失率如何有利於神經網路中的整體誤差。
點擊查看


