Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript嗎?Browser大多數網站的網頁抓取可能相對容易。本教程已詳細介紹了該主題。然而,有許多網站無法使用相同的方法進行抓取。原因是這些網站使用 JavaScript 動態載入內容。
該技術也稱為 AJAX(非同步 JavaScript 和 XML)。從歷史上看,該標準包括建立XMLHttpRequest物件以從 Web 伺服器檢索 XML,而無需重新載入整個頁面。如今,這個物件很少被直接使用。通常,像 jQuery 這樣的包裝器用於檢索 JSON、部分 HTML 甚至圖像等內容。
要抓取常規網頁,至少需要兩個庫。 requests庫下載頁面。一旦頁面作為 HTML 字串可用,下一步就是將其解析為 BeautifulSoup 物件。然後可以使用此 BeautifulSoup 物件來尋找特定資料。
下面是一個簡單的範例腳本,它列印id設定為firstHeading h1元素內的文字。
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert Einstein請注意,我們正在使用 Beautiful Soup 庫的版本 4。早期版本已停產。您可能會看到 beautiful soup 4 被寫成 Beautiful Soup、BeautifulSoup 甚至 bs4。它們都引用同一個美麗的湯4庫。
如果網站是動態的,則相同的程式碼將不起作用。例如,同一網站在https://quotes.toscrape.com/js/上有一個動態版本(請注意此 URL 末尾的js )。
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output原因是第二個站點是動態的,其中的資料是使用JavaScript產生的。
有兩種方法可以處理此類網站。
本教程詳細介紹了這兩種方法。
然而,首先,我們需要了解如何確定網站是否是動態的。
這是使用 Chrome 或 Edge 來確定網站是否動態的最簡單方法。 (這兩個瀏覽器都在底層使用 Chromium)。
按F12鍵開啟開發人員工具。確保焦點位於開發人員工具上,然後按CTRL+SHIFT+P組合鍵開啟指令選單。
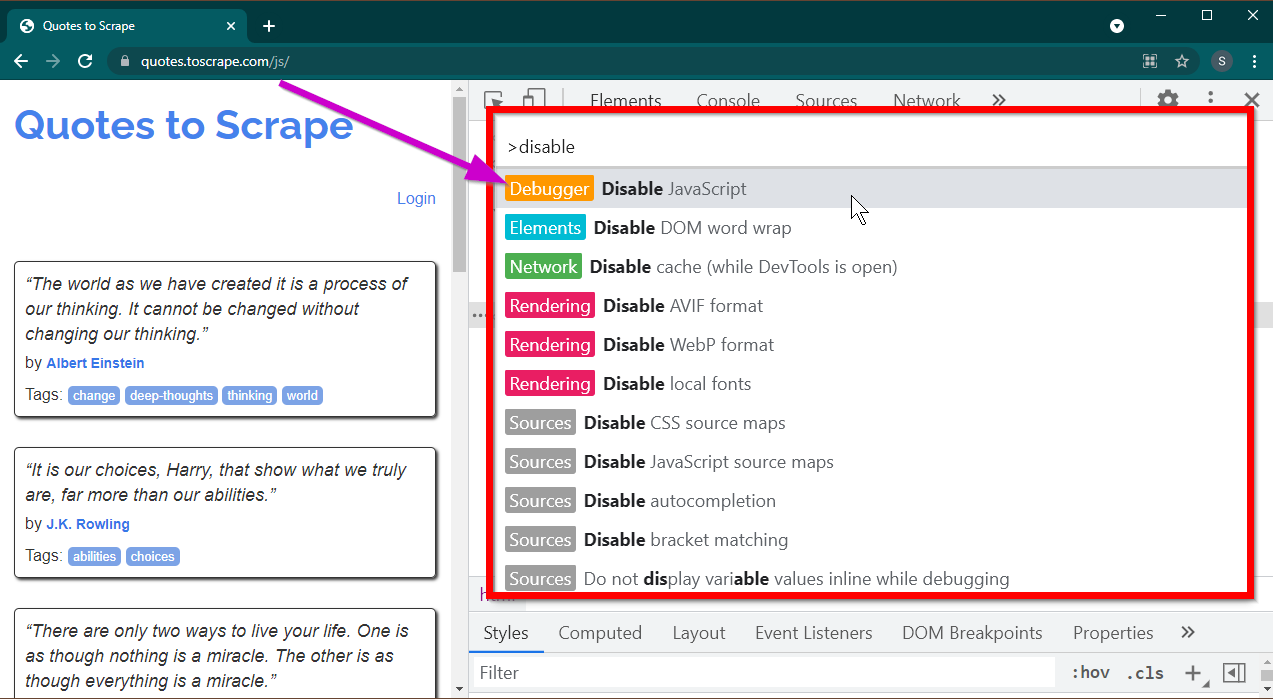
它將顯示很多命令。開始輸入disable ,命令將被過濾以顯示Disable JavaScript 。選擇此選項可停用JavaScript 。
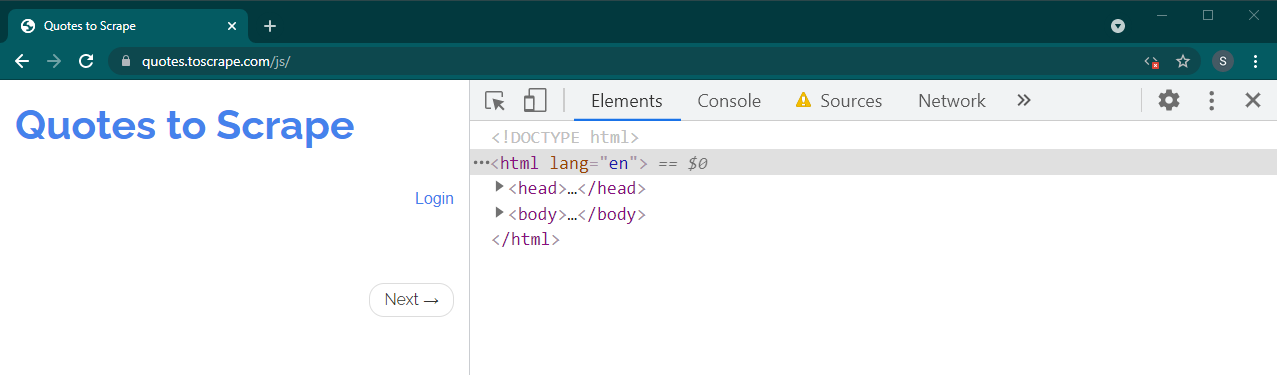
現在按Ctrl+R或F5重新載入此頁面。頁面將重新載入。
如果這是一個動態站點,很多內容將會消失:
在某些情況下,網站仍會顯示數據,但會回退到基本功能。例如,這個網站有一個無限滾動。如果 JavaScript 已停用,它會顯示常規分頁。
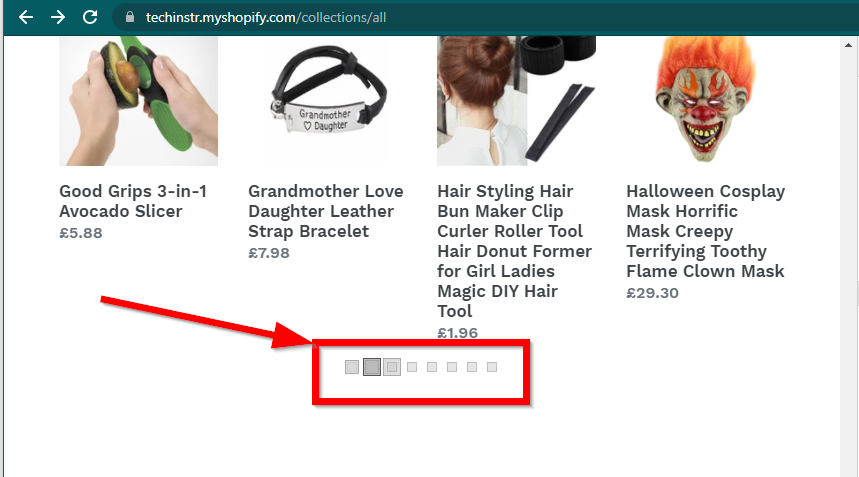 | 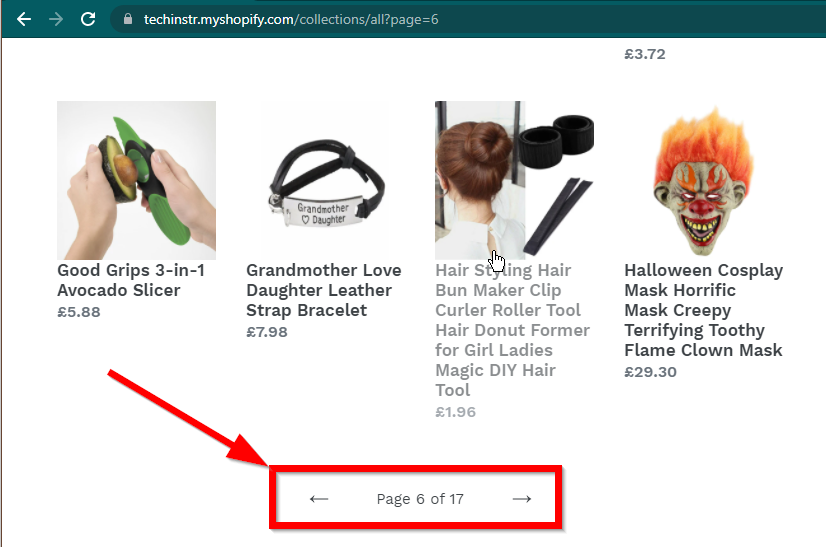 |
|---|---|
| 啟用 JavaScript | JavaScript 已停用 |
下一個需要回答的問題是BeautifulSoup的能力。
JavaScript嗎?簡短的回答是否定的。
理解解析和渲染等詞很重要。解析只是將 Python 物件的字串表示形式轉換為實際物件。
那什麼是渲染呢?渲染本質上是將 HTML、JavaScript、CSS 和圖像解釋為我們在瀏覽器中看到的內容。
Beautiful Soup 是一個用於從 HTML 檔案中提取資料的 Python 庫。這涉及將 HTML 字串解析為 BeautifulSoup 物件。為了進行解析,首先我們需要 HTML 作為字串。動態網站不直接擁有 HTML 中的資料。這意味著 BeautifulSoup 無法與動態網站一起使用。
Selenium 庫可以在 Chrome 或 Firefox 等瀏覽器中自動載入和渲染網站。儘管 Selenium 支援從 HTML 中提取數據,但也可以提取完整的 HTML 並使用 Beautiful Soup 來提取數據。
讓我們先使用 Selenium 開始使用 Python 進行動態網頁抓取。
安裝 Selenium 涉及安裝三件事:
您選擇的瀏覽器(您已經擁有):
您的瀏覽器的驅動程式:
Python 硒包:
pip install seleniumconda-forge頻道安裝。 conda install -c conda-forge selenium 啟動瀏覽器、載入頁面然後關閉瀏覽器的 Python 腳本的基本框架很簡單:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()現在我們可以在瀏覽器中載入頁面,讓我們看看提取特定元素。提取元素的方法有兩種—硒和美麗湯。
本例中我們的目標是找到作者元素。
在 Chrome 中載入網站https://quotes.toscrape.com/js/ ,右鍵點擊作者姓名,然後點擊「檢查」。這應該會載入開發者工具,並突出顯示作者元素,如下所示:
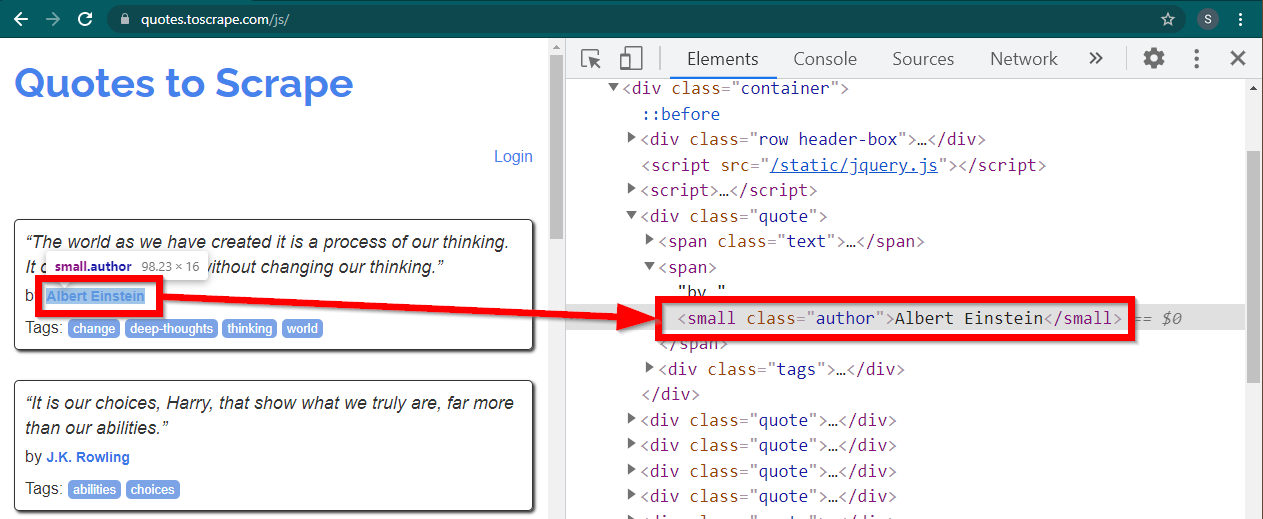
這是一個small元素,其class屬性設定為author 。
< small class =" author " > Albert Einstein </ small >Selenium 允許使用各種方法來定位 HTML 元素。這些方法是驅動程式物件的一部分。此處有用的一些方法如下:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )還有一些其他方法,可能對其他場景有用。這些方法如下:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" )也許最有用的方法是find_element(By.CSS_SELECTOR)和find_element(By.XPATH) 。這兩種方法中的任何一種都應該能夠選擇大部分場景。
我們修改一下程式碼,以便可以列印第一作者。
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()如果你想列印所有作者怎麼辦?
所有find_element方法都有一個對應的方法 - find_elements 。注意複數形式。要查找所有作者,只需更改一行:
elements = driver . find_elements ( By . CLASS_NAME , "author" )這將返回一個元素列表。我們可以簡單地運行一個循環來列印所有作者:
for element in elements :
print ( element . text )注意:完整的程式碼位於 selenium_example.py 程式碼檔案中。
但是,如果您已經熟悉 BeautifulSoup,則可以建立 Beautiful Soup 物件。
正如我們在第一個範例中看到的,Beautiful Soup 物件需要 HTML。對於網頁抓取靜態站點,可以使用requests庫檢索 HTML。下一步是將此 HTML 字串解析為 BeautifulSoup 物件。
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )讓我們了解如何使用 BeautifulSoup 抓取動態網站。
以下部分與前面的範例保持不變。
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )頁面的渲染 HTML 可在屬性page_source中找到。
soup = BeautifulSoup ( driver . page_source , "lxml" )一旦 soup 物件可用,所有 Beautiful Soup 方法都可以照常使用。
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )註:完整的原始碼在selenium_bs4.py中
Browser一旦腳本準備就緒,腳本運行時瀏覽器就不需要可見。瀏覽器可以隱藏,腳本仍然可以正常運作。瀏覽器的這種行為也稱為無頭瀏覽器。
若要讓瀏覽器無頭,請匯入ChromeOptions 。對於其他瀏覽器,可以使用它們自己的選項類別。
from selenium . webdriver import ChromeOptions現在,建立該類別的一個對象,並將headless屬性設為 True。
options = ChromeOptions ()
options . headless = True最後,在建立 Chrome 實例時傳送該物件。
driver = Chrome ( ChromeDriverManager (). install (), options = options )現在,當您運行腳本時,瀏覽器將不可見。有關完整的實現,請參閱 selenium_bs4_headless.py 檔案。
載入瀏覽器的成本很高——它會佔用其實不需要的 CPU、RAM 和頻寬。當網站被抓取時,資料很重要。所有這些 CSS、圖像和渲染並不是真正需要的。
使用Python抓取動態網頁最快、最有效的方法是定位資料的實際位置。
此數據可以位於兩個地方:
<script>標記中讓我們來看幾個例子。
在 Chrome 中開啟 https://quotes.toscrape.com/js。頁面載入後,按 Ctrl+U 查看原始碼。按Ctrl+F調出搜尋框,搜尋Albert。
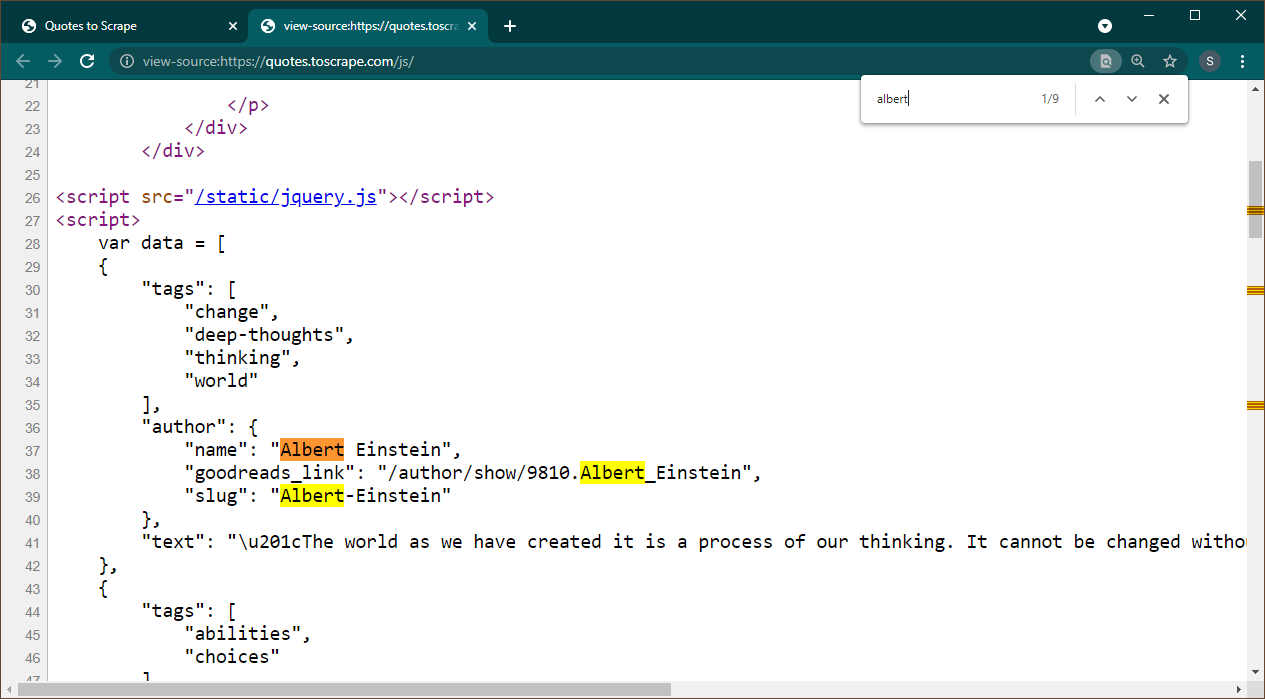
我們可以立即看到資料作為 JSON 物件嵌入到頁面上。另請注意,這是腳本的一部分,其中該資料被分配給變數data 。
在這種情況下,我們可以使用Requests庫來取得頁面,並使用Beautiful Soup來解析頁面並取得腳本元素。
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" )請注意,有多個<script>元素。包含我們需要的資料的資料沒有src屬性。讓我們用它來提取腳本元素。
script_tag = soup . find ( "script" , src = None )請記住,除了我們感興趣的資料之外,該腳本還包含其他 JavaScript 程式碼。
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )資料變數是一個包含一項的清單。現在我們可以使用 JSON 函式庫將此字串資料轉換為 python 物件。
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )輸出將是 python 物件:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................該清單無法根據需要轉換為任何格式。另請注意,每個項目都包含指向作者頁面的連結。這意味著您可以閱讀這些連結並創建一個蜘蛛來從所有這些頁面獲取數據。
完整的程式碼包含在 data_in_same_page.py 中。
網頁抓取動態網站可以遵循完全不同的路徑。有時資料會完全載入到單獨的頁面上。 Librivox 就是這樣的一個例子。
開啟開發人員工具,前往網路標籤並按 XHR 進行過濾。現在打開此連結或搜尋任何書籍。您將看到資料是嵌入在 JSON 中的 HTML。
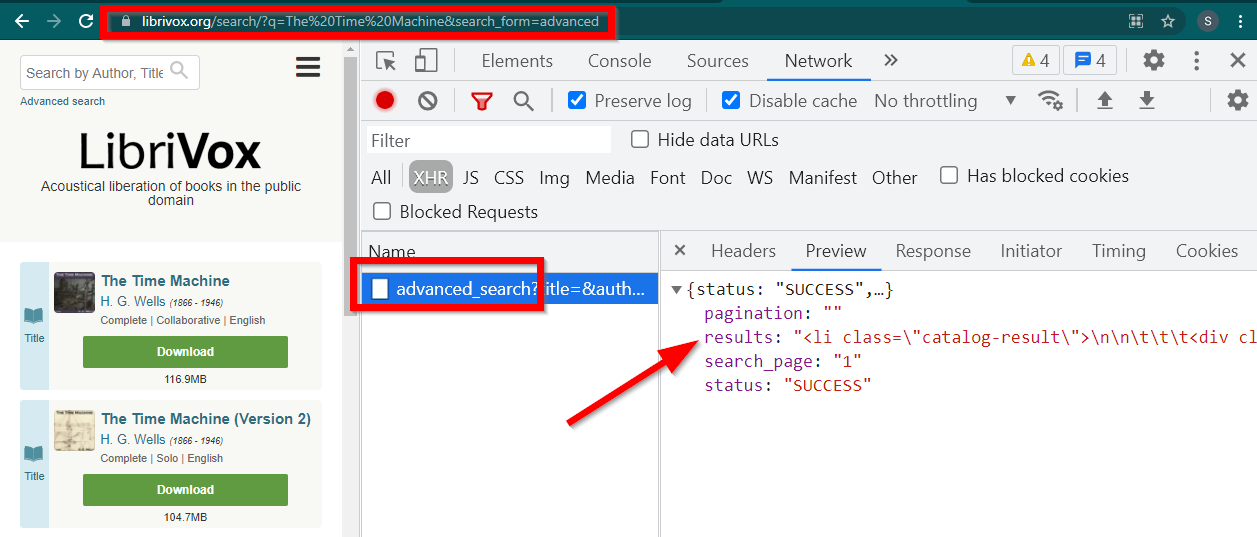
注意幾點:
瀏覽器顯示的 URL 為https://librivox.org/search/?q=...
數據位於https://librivox.org/advanced_search?....
如果你查看 headers,你會發現 advance_search 頁面發送了一個特殊的 header X-Requested-With: XMLHttpRequest
這是提取此數據的片段:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )完整的程式碼包含在 librivox.py 檔案中。


