offensive ai compilation
1.0.0
涵蓋進攻性人工智慧的有用資源的精選清單。
利用人工智慧模型的漏洞。
對抗性機器學習負責評估其弱點並提供對策。
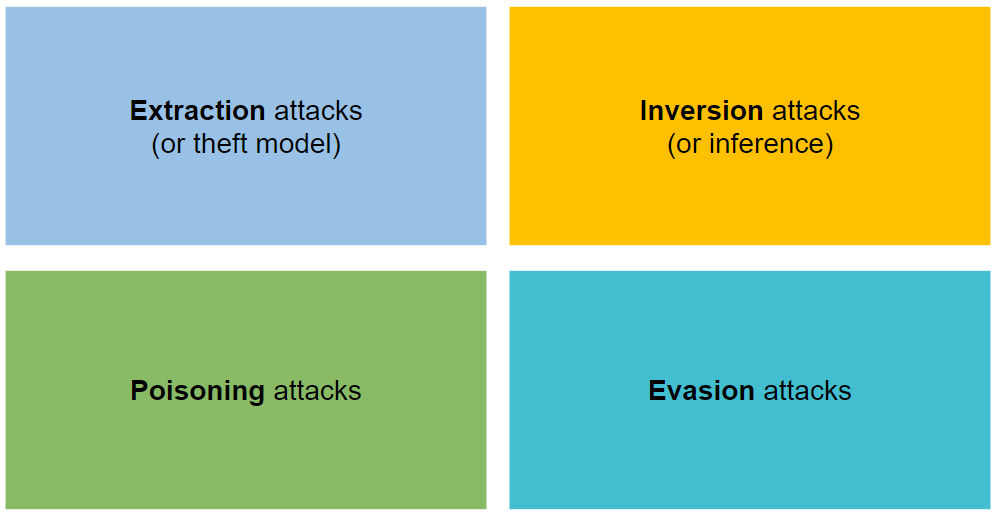
它分為四種類型的攻擊:提取、反轉、中毒和逃脫。
它試圖透過發出最大化資訊提取的請求來竊取模型的參數和超參數。
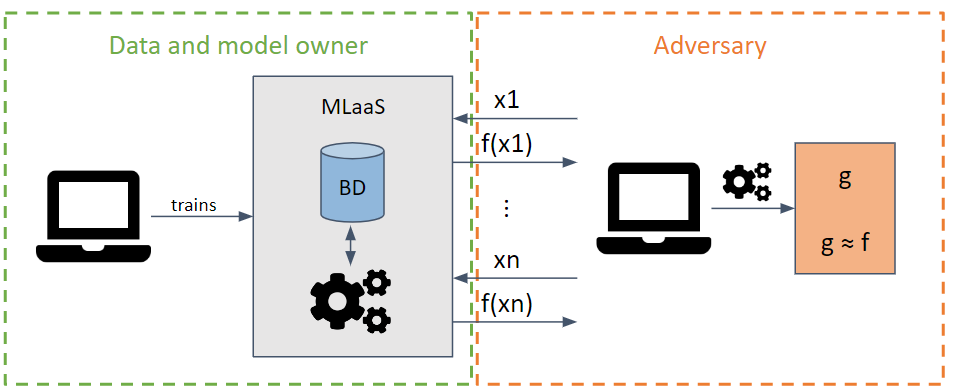
根據對手模型的了解,可以執行白盒和黑盒攻擊。
在最簡單的白盒情況下(當對手完全了解模型,例如 sigmoid 函數時),人們可以創建一個易於求解的線性方程組。
在一般情況下,如果對模型的了解不足,則使用替代模型。該模型根據對原始模型的請求進行訓練,以模仿與原始模型相同的功能。
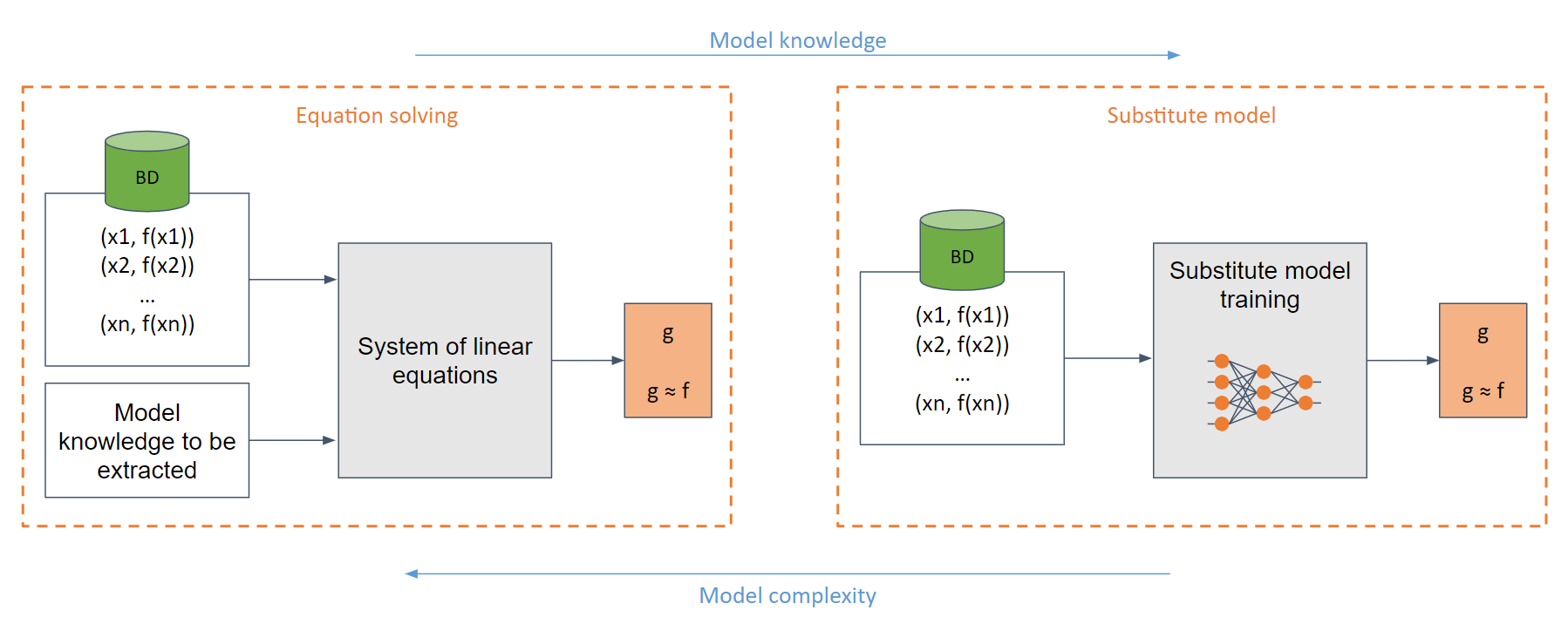
訓練替代模型(在許多情況下)相當於從頭開始訓練模型。
計算量非常大。
攻擊者在被發現之前對請求數量有限制。
輸出值的捨入。
使用差異隱私。
使用合奏。
使用特定的防禦措施
它們的目的是扭轉機器學習模型的資訊流。
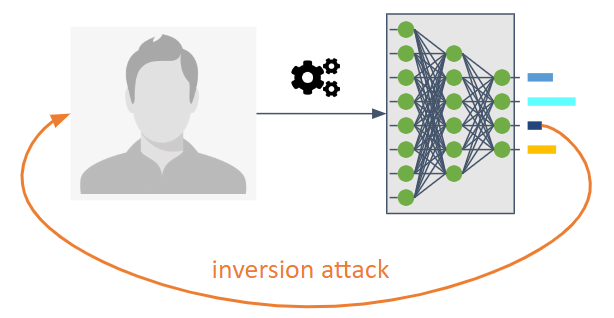
它們使對手能夠知道未明確打算共享的模型。
它們使我們能夠了解訓練資料或資訊作為模型的統計屬性。
可能有三種類型:
成員推理攻擊 (MIA) :攻擊者試圖確定樣本是否被用作訓練的一部分。
屬性推斷攻擊(PIA) :攻擊者旨在提取在訓練階段未明確編碼為特徵的統計屬性。
重建:對手試圖從訓練集中和/或其對應的標籤重建一個或多個樣本。也稱為倒轉。
使用先進的密碼學。對策包括差分隱私、同態密碼學和安全多方計算。
由於過度訓練和隱私的關係,使用了Dropout等正規化技術。
模型壓縮已被提議作為對重建攻擊的防禦。
他們的目的是透過導致機器學習模型降低其準確性來破壞訓練集。
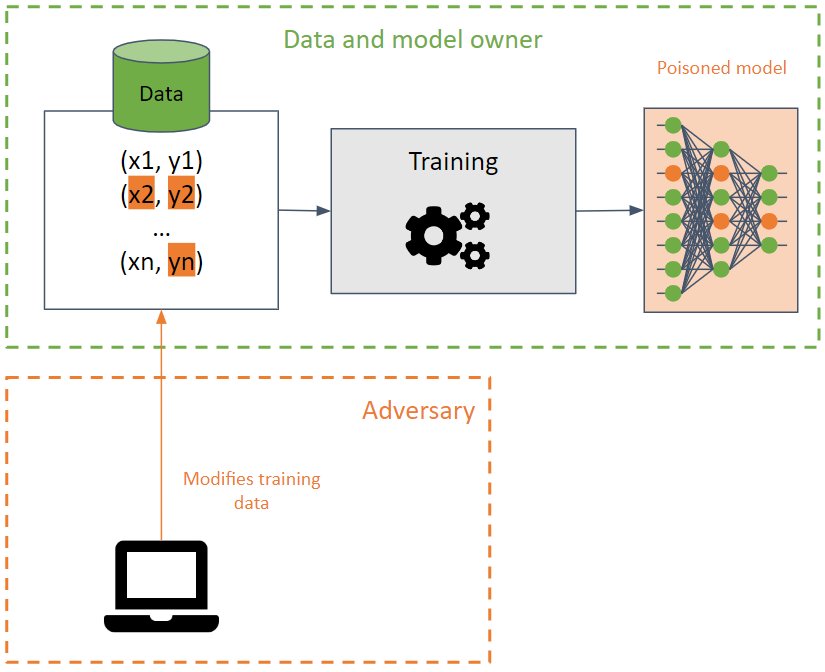
在訓練資料上執行這種攻擊時很難檢測到,因為攻擊可以使用相同的訓練資料在不同模型之間傳播。
攻擊者試圖透過修改決策邊界來破壞模型的可用性,從而產生錯誤的預測或在模型中建立後門。在後者中,模型在大多數情況下表現正確(返回所需的預測),但對手專門創建的某些輸入會產生不良結果。對手可以操縱預測結果並發動未來的攻擊。
BadNet 是機器學習模型中最簡單的後門類型。此外,BadNet 能夠保留在模型中,即使它們再次針對與原始模型不同的任務(遷移學習)進行重新訓練。
需要注意的是,公共預訓練模型可能包含後門。
檢測中毒資料並使用資料清理。
健全的培訓方法。
具體防禦。
對手在機器學習模型的輸入中加入一個小的擾動(以雜訊的形式),使其分類錯誤(範例對手)。
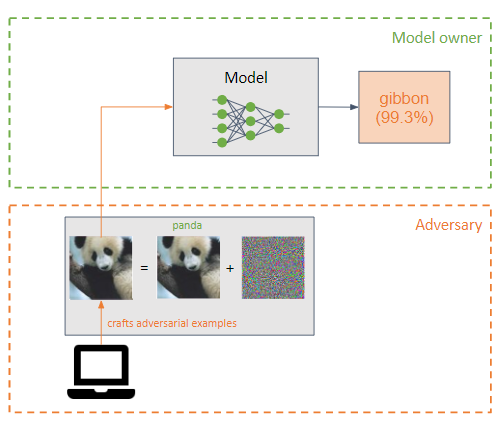
它們與投毒攻擊類似,但主要區別在於逃避攻擊試圖利用模型在推理階段的弱點。
對手的目標是讓對手的例子無法被人類察覺。
根據對手所需的輸出,可以執行兩種類型的攻擊:
有針對性:對手的目的是獲得對其選擇的預測。
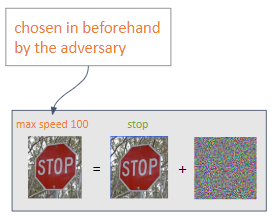
無目標:對手意圖實現錯誤分類。

最常見的攻擊是白盒攻擊:
對抗性訓練,包括在訓練期間製作對抗性範例,使模型能夠學習對抗性範例的特徵,從而使模型對此類攻擊更加穩健。
輸入的轉換。
梯度掩蔽/正則化。不太有效。
防禦薄弱。
即時注射防禦:針對即時注射的每一種實際且建議的防禦措施。
Lakera PINT 基準:即時注入測試 (PINT) 基準提供了一種中立的方法來評估即時注入偵測系統(如 Lakera Guard)的效能,而無需依賴這些工具可用於優化評估效能的已知公共資料集。
Devil's Inference:一種透過觀察特定輸入時頭部注意力分佈來對抗性評估 Phi-3 Instruct 模型的方法。這種方法促使模型採用“魔鬼心態”,使其能夠產生暴力性質的輸出。
| 姓名 | 類型 | 支援的演算法 | 支援的攻擊類型 | 攻擊/防禦 | 支援的框架 | 人氣 |
|---|---|---|---|---|---|---|
| 克萊弗漢斯 | 影像 | 深度學習 | 閃避 | 攻擊 | 張量流、Keras、JAX | |
| 傻瓜箱 | 影像 | 深度學習 | 閃避 | 攻擊 | 張量流、PyTorch、JAX | |
| 藝術 | 任何類型(圖像、表格資料、音訊…) | 深度學習、SVM、LR等 | 任意(提取、推理、中毒、逃避) | 兩個都 | Tensorflow、Keras、Pytorch、Scikit Learn | |
| 文字攻擊 | 文字 | 深度學習 | 閃避 | 攻擊 | Keras,擁抱臉 | |
| 廣告燈 | 影像 | 深度學習 | 閃避 | 兩個都 | --- | |
| 廣告框 | 影像 | 深度學習 | 閃避 | 兩個都 | PyTorch、張量流、MxNet | |
| 深穩健 | 圖像、圖表 | 深度學習 | 閃避 | 兩個都 | 火炬 | |
| 仿製品 | 任何 | 任何 | 閃避 | 攻擊 | --- | |
| 對抗性音訊範例 | 聲音的 | 深度語音 | 閃避 | 攻擊 | --- |
Adversarial Robustness Toolbox 縮寫為 ART,是一個開源的 Adversarial Machine Learning 函式庫,用於測試機器學習模型的穩健性。

它採用Python開發,實現提取、反轉、投毒和規避攻擊與防禦。
ART 支援最受歡迎的框架:Tensorflow、Keras、PyTorch、MxNet 和 ScikitLearn 等。
它不僅限於使用使用圖像作為輸入的模型,還支援其他類型的數據,例如音訊、視訊、表格數據等。
使用 ART 學習對抗性機器學習的研討會?
Cleverhans 是一個用於執行逃避攻擊並測試圖像模型上的深度學習模型的穩健性的函式庫。

它是用 Python 開發的,並與 Tensorflow、Torch 和 JAX 框架整合。
它實施多種攻擊,例如 L-BFGS、FGSM、JSMA、C&W 等。
人工智慧用於完成惡意任務並增強經典攻擊。
米格爾·埃爾南德斯 | 何塞·伊格納西奧·埃斯克里巴諾 |


