eye in the sky
1.0.0
衛星影像分類,InterIIT Techmeet 2018,IIT 孟買。
團隊:Manideep Kolla、Aniket Mandle、Apoorva Kumar
該儲存庫包含兩種演算法的實現,即 U-Net:用於生物醫學影像分割的捲積網路和針對衛星影像分類問題進行修改的金字塔場景解析網路。
main_unet.py :用於使用 U-Net 架構訓練演算法的 Python 程式碼,包括基本事實的編碼。unet.py :包含我們對 U-Net 層的實作。test_unet.py :用於測試、計算精度、計算訓練和驗證的混淆矩陣以及保存 U-Net 模型對訓練、驗證和測試圖像的預測的程式碼。Inter-IIT-CSRE :包含所有訓練、驗證和測試資料。Comparison_Test.pdf :將測試資料與 U-Net 模型對資料的預測進行並排比較。train_predictions :U-Net 模型對訓練和驗證影像的預測。plots :U-Net 架構訓練和驗證的準確性和損失圖。Test_images 、 Test_outputs :包含測試影像及其 U-Net 模型的預測。class_masks 、 compare_pred_to_gt 、 images_for_doc :包含用於文件的多個影像。PSPNet :包含用於實現衛星影像分類 PSPNet 演算法的訓練檔案。 克隆儲存庫,將目前工作目錄變更為克隆的目錄。建立名為train_predictions和test_outputs的資料夾,以保存訓練和測試影像上的模型預測輸出(現在不需要,因為儲存庫已包含這些資料夾)
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
要訓練 U-Net 模型並節省權重,請執行以下命令
$ python3 main_unet.py
測試 U-Net 模型,計算準確性,計算訓練和驗證的混淆矩陣,並保存模型對訓練、驗證和測試圖像的預測。
$ python3 test_unet.py
運行我們的程式碼時,您可能會收到錯誤xrange is not defined 。這個錯誤不是由於我們的程式碼中的錯誤引起的,而是由於名為libtiff的python 套件不是最新的(該套件的源代碼的某些部分在python2 中,一些在python3 中),我們用來讀取資料集,其中影像為 .tif 格式。我們無法使用 openCV 或 PIL 等其他函式庫來讀取影像,因為它們無法正確支援讀取 4 通道 .tif 影像。
可以透過編輯libtiff庫的源代碼來解決此錯誤。
轉到出現錯誤的程式庫原始程式碼中的檔案(顯示錯誤時檔案名稱將顯示在終端機中)並將檔案中的所有xrange() (python2) 函數替換為range() (python3)。
我們在這裡提供了一些相當好的預訓練權重,以便用戶不需要從頭開始訓練。
| 描述 | 任務 | 數據集 | 模型 |
|---|---|---|---|
| UNet架構 | 衛星影像分類 | IITB 資料集(請參閱Inter-IIT-CSRE資料夾) | 下載(.h5) |
若要使用預先訓練的權重,請變更test_unet.py中提到的 .h5(權重檔案)檔案的名稱,以符合您在需要時下載的權重檔案的名稱。
現在我們來討論一下
1. 這個專案是關於什麼的,
2.我們使用和試驗過的架構
3. 我們在專案中使用的一些新穎的訓練策略
遙感是從遠處(通常是從飛機或衛星)獲取有關物體或區域資訊的科學。
我們將衛星影像分類問題理解為語義分割問題,並在深度學習中建立了語義分割演算法來解決這個問題。
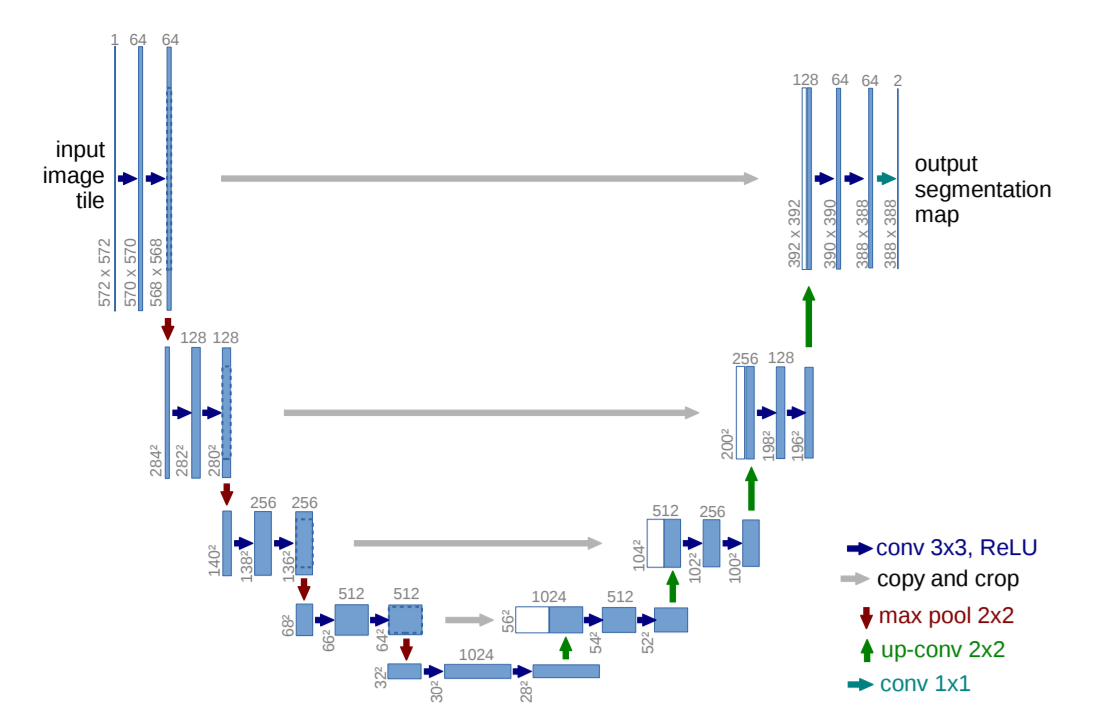
U-Net:用於生物醫學影像分割的捲積網絡
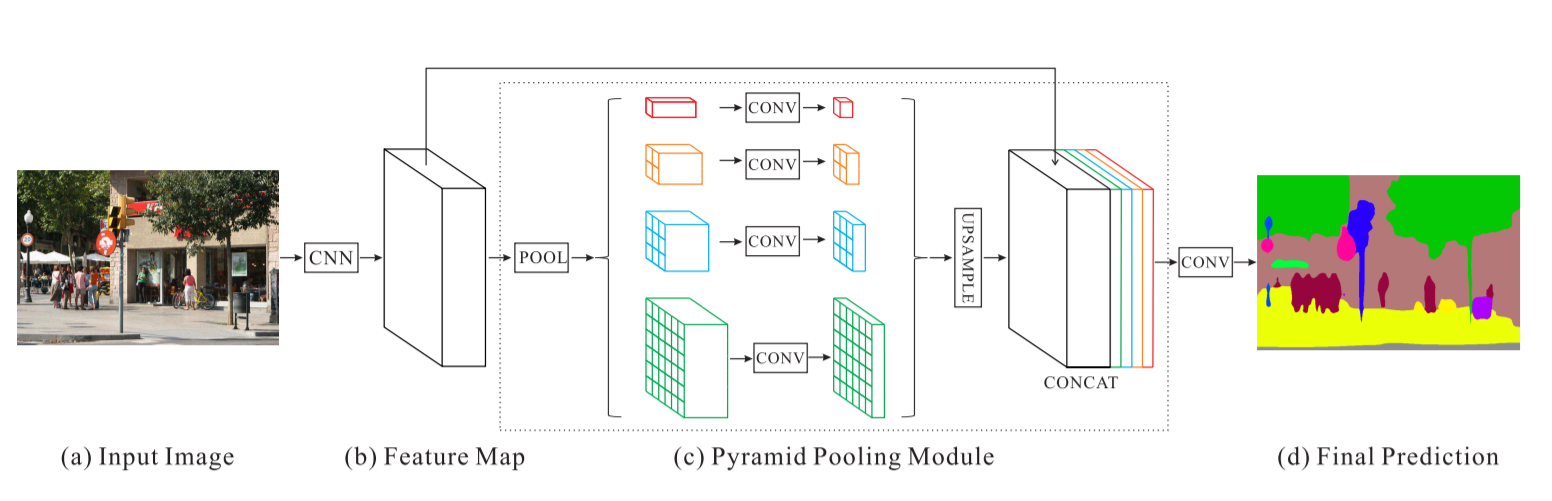
金字塔場景解析網路 - PSPNet
提供的基本事實是 3 通道 RGB 影像。在目前資料集中,基本事實中只有 9 個唯一的 RGB 值,因為有 9 個類別需要分類。這 9 個不同的 RGB 值經過 one-hot 編碼,產生 9 通道編碼的基本事實,每個通道代表一個特定類別。
下面是編碼方案
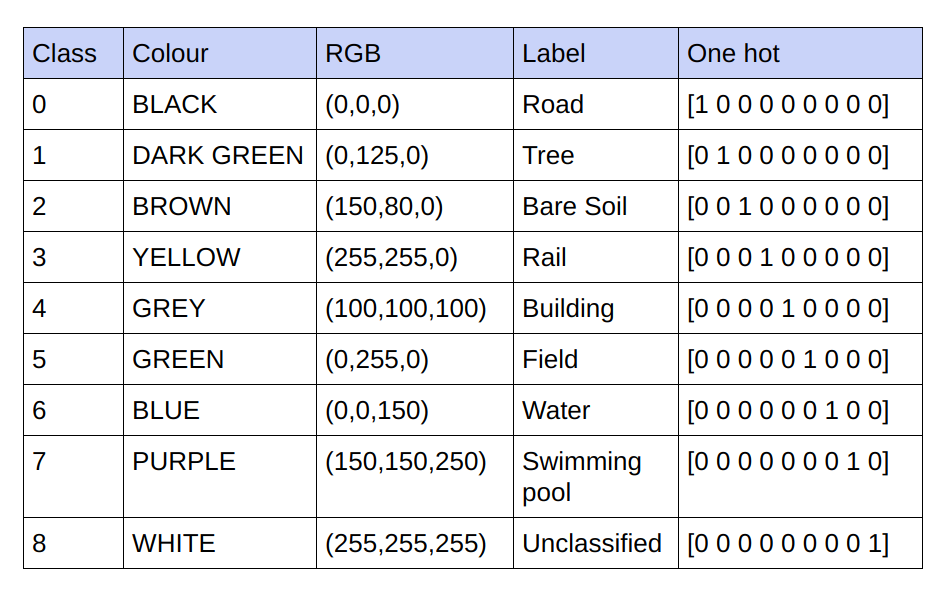
將編碼的地面實況中的每個通道實作為一個類

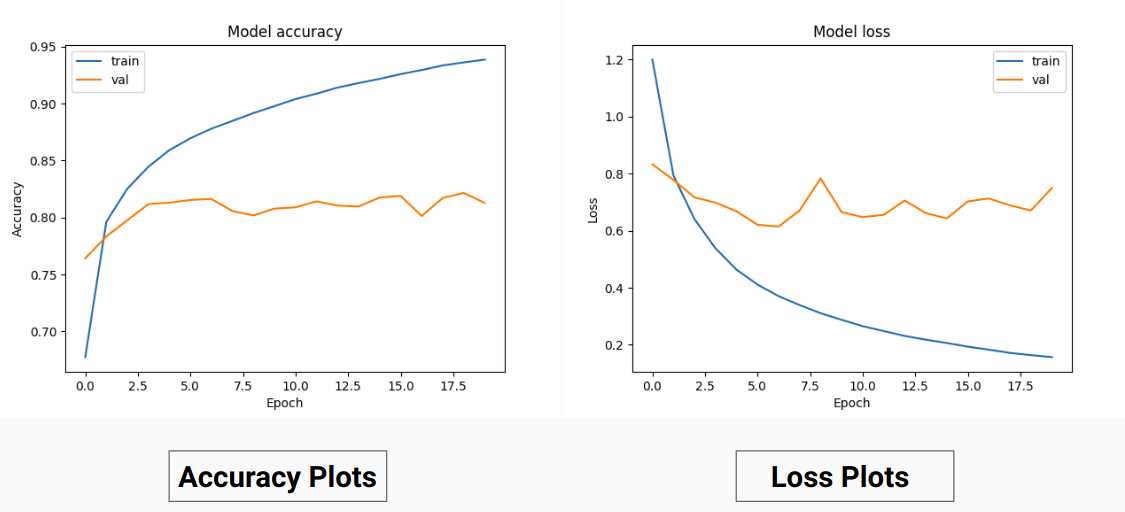
因此,我們沒有對真實值的 RGB 值進行訓練,而是將它們轉換為不同類別的 one-hot 值。這種方法使我們的驗證準確率達到 85%,訓練準確率達到 92%,而當我們使用 RGB 真實值進行訓練時,驗證準確度為 71%,訓練準確度為 65%。
這可能是由於訓練資料的基本事實的變異數和平均值減少,因為它充當了有效的標準化技術。這種訓練技術的更好性能也因為模型給出了帶有9 個特徵圖的輸出,每個圖指示一個類,即,這種訓練技術的作用就好像模型在某種程度上分別在9個類別中的每一個上進行訓練(但在這裡,對應於特定類別的一個通道的預測肯定取決於其他通道) 。
我們在 PSPNet 上進行衛星影像分類的結果:
訓練準確度 - 49% 驗證準確度 - 60%
理由:
U網:
修改後的U-Net:
為了進行訓練和驗證,我們使用了Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset資料夾中的 14 個「.tif」影像。
為了進行訓練,我們使用了資料集中的前 13 張圖像,為了驗證,我們使用了第 14 張圖像。
sat資料夾中的每個衛星影像包含 4 個通道,分別為 R(波段 1)、G(波段 2)、B(波段 3)和 NIR(波段 4)。
gt目錄中的地面真實圖像是 RGB 圖像,描繪了 8 個類別 - 道路、建築物、樹木、草地、裸土、水、鐵路和游泳池
我們只考慮一張圖像(第 14 張圖像)作為驗證集的原因是它是資料集中最小的圖像之一,而且我們不想留下更少的資料用於訓練,因為資料集非常小。我們考慮的驗證集(第 14 張圖像)中不存在具有相當高訓練精度的 3 個類別(裸土、鐵路、游泳民意調查)。如果我們考慮一張包含所有類別的影像(資料集中沒有影像包含所有類,所有影像中至少缺少一個類別),驗證準確性會更好。
跨步裁剪:
為了從給定的高清影像中獲得足夠的訓練數據,需要進行裁剪來訓練分類器,該分類器具有 U-Net 實現的約 31M 參數。我們發現 64x64 的裁切尺寸對各個類別的代表性不足,且物件的幾何形狀和連續性遺失,從而減少了卷積的視野。
使用 128x128 像素的裁切窗口,步幅為 32,產生 15887 個訓練 414 個驗證影像。
圖片尺寸:
在裁切之前,訓練影像的尺寸會轉換為步幅的倍數,以方便跨步裁切。
對於沒有的情況。作物的數量不是我們最初嘗試零填充的圖像尺寸的倍數,我們意識到添加填充會在訓練和測試圖像中以黑色像素的形式添加不需要的偽影,從而導致對錯誤數據和圖像邊界進行訓練。
或者,我們透過在圖像的最右側和底部添加額外的像素來正確更改圖像尺寸。因此,我們將圖像最左側的差異填充到其右側的缺陷端,圖像的頂部和底部也是如此。
訓練範例 1:訓練資料中的圖像“2.tif”
訓練範例 2:訓練資料中的影像“4.tif”
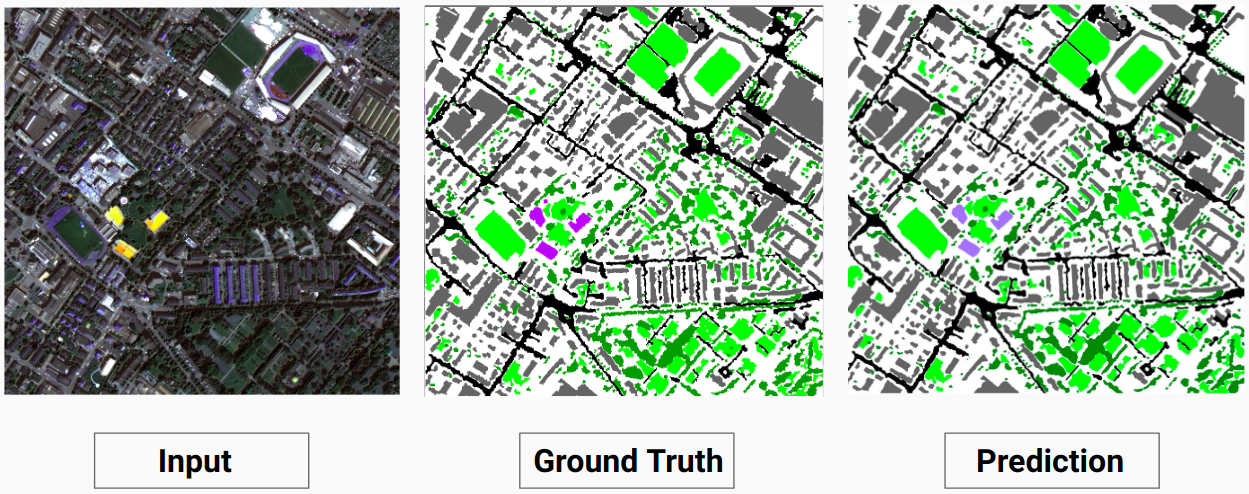
驗證範例:資料集中的影像“14.tif”

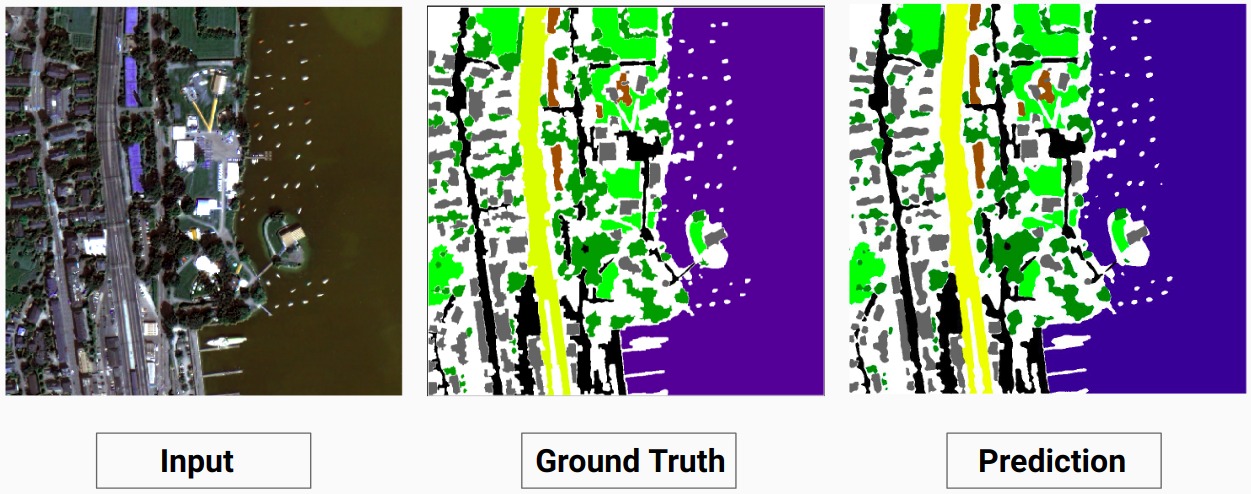
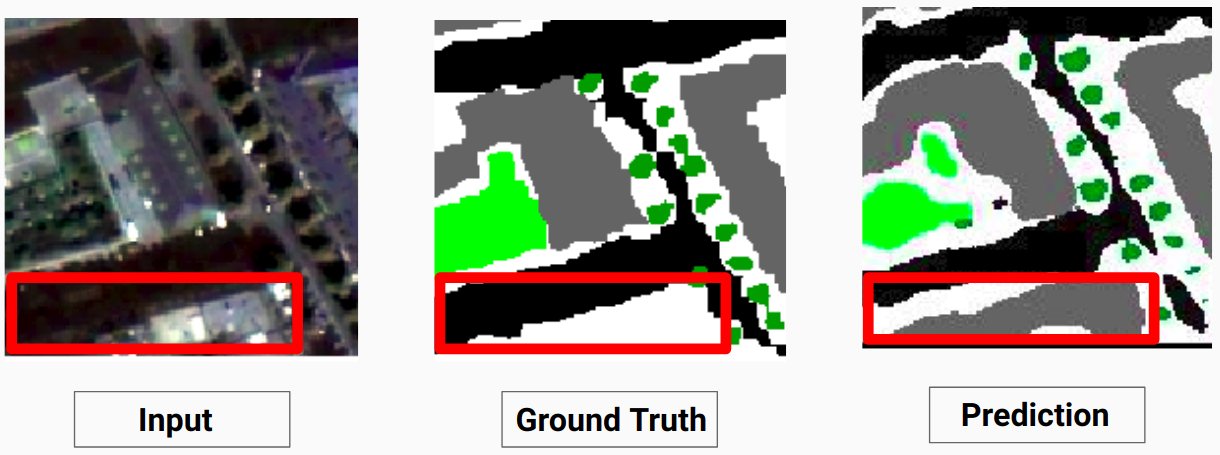
我們的模型能夠預測人類註釋者無法預測的一些類別。影像中無法辨識的類別被人類註釋者標記為白色像素。我們的模型能夠將其中一些白色像素正確預測為某個類別,但這會導致整體精度下降,因為模型將白色像素視為單獨的類別。
這裡,模型能夠將白色像素預測為建築物,這是正確的並且可以在輸入圖像中清楚地看到
查看Comparison_Test.pdf以比較測試影像與模型預測的輸出
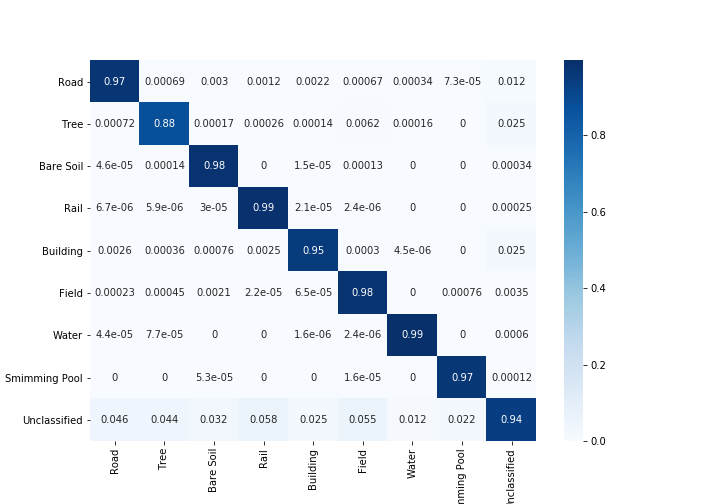
考慮和不考慮未分類像素的 Kappa 係數
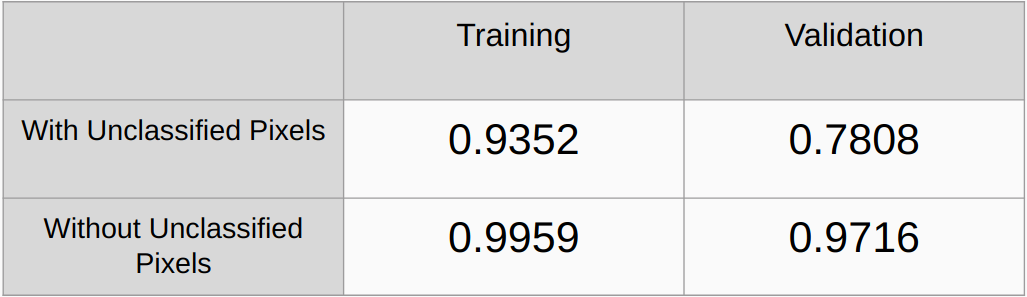
考慮和不考慮未分類像素的總體精度
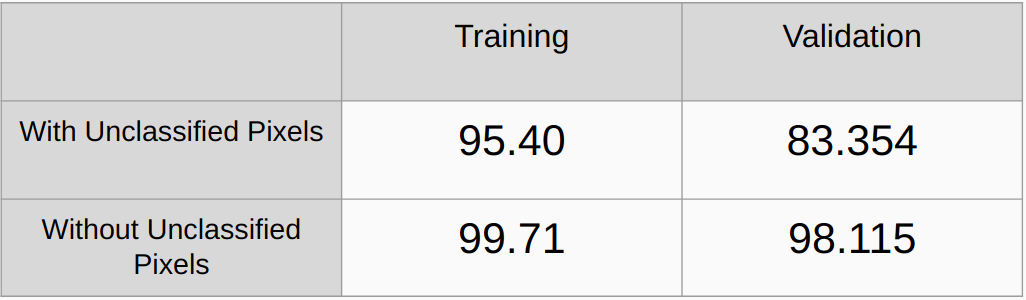
需要添加L2正則化和dropout等正則化方法並檢查性能
實作一種演算法來自動偵測基本事實中的所有唯一 RGB 值並對它們進行 onehot 編碼,而不是手動尋找 RGB 值。
[1] U-Net:用於生物醫學影像分割的捲積網絡,Olaf Ronneberger、Philipp Fischer 和 Thomas Brox
[2] 金字塔場景解析網絡,趙恆雙,石建平,齊小娟,王小剛,賈佳雅
[3] 2017 年深度學習語意分割指南,Sasank Chilamkurthy


