linformer pytorch
version
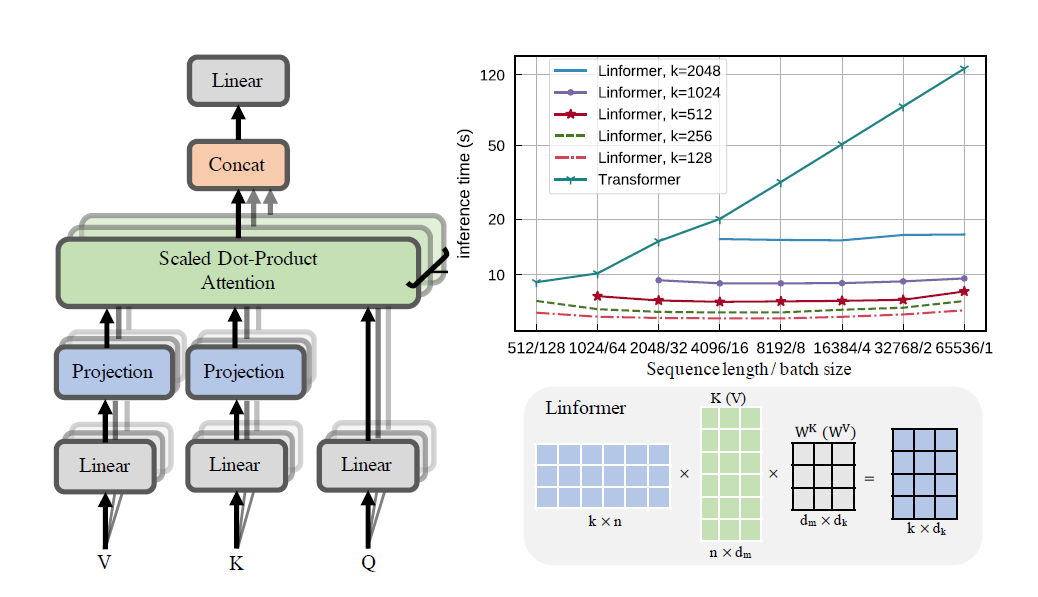
Linformer 論文的實際實作。這是僅具有 n 線性複雜度的關注,允許在現代硬體上關注非常長的序列長度(1mil+)。
這個倉庫是一個 Attention Is All You Need 風格的轉換器,配有編碼器和解碼器模組。這裡的新穎之處在於,現在可以讓注意力頭線性。看看下面如何使用它。
這正在 wikitext-2 上進行驗證。目前,它的性能與其他稀疏注意力機制(如 Sinkhorn Transformer)相同,但仍需找到最佳超參數。
頭部的可視化也是可能的。要查看更多信息,請查看下面的可視化部分。
我不是這篇論文的作者。
123 萬個代幣
pip install linformer-pytorch
或者,
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
Linformer 語言模型
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Linformer 自註意力, MHAttention和FeedForward的堆疊
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Linformer 多頭注意力
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)線性注意力頭,論文的新穎之處
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)編碼器/解碼器模組。
注意:對於因果序列,可以在LinformerLM中設定causal=True標誌來屏蔽(n,k)注意力矩陣的右上角。
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000)取得E和F矩陣的簡單方法可以透過呼叫get_EF函數來完成。例如,對於n為1000且k為100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 )透過method標誌,可以設定 linformer 執行下採樣的方法。目前支援三種方式:
learnable :這種下取樣方法創造了一個可學習的n,k nn.Linear模組。convolution :此下取樣方法可建立 1d 卷積,其步幅長度和內核大小n/k 。no_params :這將建立一個固定的n,k矩陣,其值來自 N(0,1/k)將來我可能會加入池化或其他東西。但就目前而言,這些都是存在的選擇。
作為進一步引入記憶體節省的嘗試,引入了檢查點層級的概念。目前的三個檢查點等級是C0 、 C1和C2 。當提升檢查點等級時,人們會犧牲速度來節省記憶體。也就是說,檢查點等級C0最快,但佔用 GPU 上的空間最多,而C2最慢,但佔用 GPU 上的空間最少。每個檢查點層級的詳細資訊如下:
C0 :無檢查點。模型運行的同時將所有註意力頭和 ff 層保留在 GPU 記憶體中。C1 :檢查每個 MultiHead 注意力以及每個 ff 層。這樣,增加depth對記憶的影響應該是最小的。C2 :除了C1等級的最佳化外,還會對每個 MultiHead Attention 層中的每個頭部進行檢查點。這樣,增加nhead對記憶體的影響應該較小。然而,將頭部與torch.cat連接在一起仍然會佔用大量內存,這有望在未來得到最佳化。效能細節仍然未知,但對於想要嘗試的使用者來說,該選項是存在的。
論文中引入記憶體節省的另一個嘗試是引入投影之間的參數共享。論文第 4 節提到了這一點;特別是,作者討論了 4 種不同類型的參數共享,並且所有類型都已在此儲存庫中實現。第一個選項佔用最多的內存,每個選項都會減少必要的內存需求。
none :這不是參數共享。對於每個頭和每一層,為每層的每個頭計算一個新的E和一個新的F矩陣。headwise :每層都有唯一的E和F矩陣。該層中的所有頭共享該矩陣。kv :每層都有唯一的投影矩陣P ,且每層E = F = P 。所有頭共享該投影矩陣P 。layerwise :有一個投影矩陣P ,每一層的每個頭都使用E = F = P 。如本文開始的,這意味著對於 12 層、12 頭的網絡,將分別有288 、 24 、 12和1不同的投影矩陣。
請注意,使用k_reduce_by_layer選項時, layerwise選項將無效,因為它將使用第一層的k維度。因此,如果k_reduce_by_layer值大於0 ,則很可能不使用layerwise共用選項。
另外,請注意,根據作者的說法,在圖 3 中,這種參數共享實際上並沒有對最終結果產生太大影響。因此,最好堅持對所有內容進行layerwise共享,但用戶也可以嘗試。
Linformer 目前實作的一個小問題是序列長度必須與模型的input_size標誌相符。 Padder 填入輸入大小,以便張量可以饋送到網路中。一個例子:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 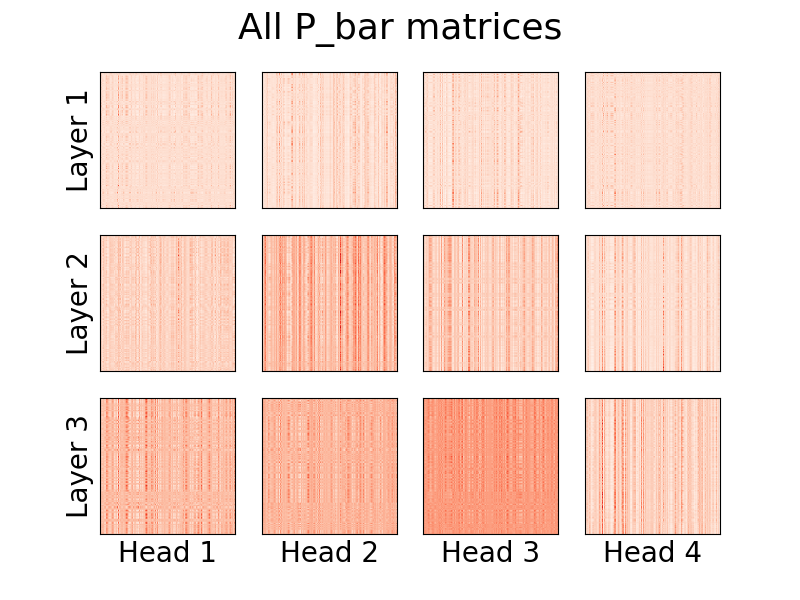
從版本0.8.0開始,現在可以視覺化 linformer 的注意力頭了!若要查看實際情況,只需匯入Visualizer類,然後執行plot_all_heads()函數即可查看每個層級的所有註意力頭的圖片,大小為 (n,k)。確保在前向傳遞中指定visualize=True ,因為這會保存P_bar矩陣,以便Visualizer類別可以正確地視覺化頭部。
下面可以找到該程式碼的工作範例,並且可以在./examples/example_vis.py中找到相同的程式碼:
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)這些頭的含義的詳細解釋可以在 #15 中找到。
與 Reformer 類似,我將嘗試製作一個編碼器/解碼器模組,以便簡化訓練。這就像 2 個LinformerLM類別一樣。每個參數都可以單獨調整,編碼器的所有超參數都具有enc_前綴,解碼器以類似的方式具有dec_前綴。到目前為止,實現的是:
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )我計劃有一種方法為此生成文字序列。
ff_intermediate調整現在,中間層的模型維度可以不同。此變更適用於 ff 模組,並且僅適用於編碼器。現在,如果標誌ff_intermediate不是 None,則圖層將如下所示:
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
相對於
channels -> ff_dim -> channels (For all layers)
input_size和dim_k進行編輯。apex這樣的庫應該可以使用它,但是,在實踐中,它還沒有經過測試。input_size 、 k= dim_k和 d= dim_d 。 LinformerEncDec課程這是我第一次從論文中複製結果,所以有些事情可能是錯的。如果您發現問題,請提出問題,我將嘗試解決它。
感謝 lucidrains,他們的其他稀疏注意力儲存庫幫助我設計了這個 Linformer Repo。
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}“專心聽…”


