byol pytorch
0.8.2
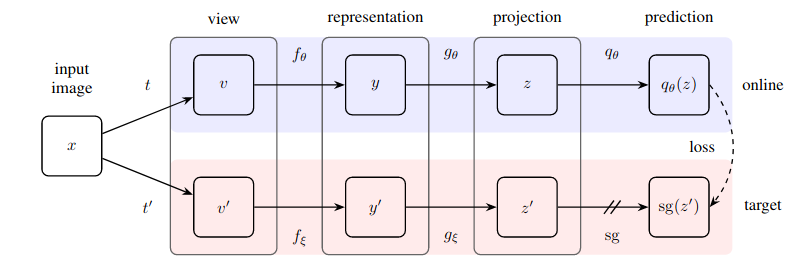
實際上實現了一種極其簡單的自監督學習方法,該方法達到了新的最先進水平(超越 SimCLR),無需對比學習,也無需指定負對。
該儲存庫提供了一個模組,可以輕鬆包裝任何基於圖像的神經網路(殘差網路、鑑別器、策略網路),以立即開始從未標記的圖像資料中受益。
更新 1:現在有新的證據表明批量歸一化是使該技術發揮良好作用的關鍵
更新 2:一篇新論文成功用組範數 + 權重標準化取代了批量範數,反駁了 BYOL 需要批量統計才能發揮作用
更新 3:最後,我們對它的工作原理做了一些分析
Yannic Kilcher 的精彩解釋
現在就讓您的組織免於付費標籤:)
$ pip install byol-pytorch只需插入您的神經網絡,指定 (1) 影像尺寸以及 (2) 隱藏層的名稱(或索引),其輸出用作自監督訓練的潛在表示。
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )差不多就這樣了。經過大量訓練後,殘差網路現在應該在其下游監督任務上表現更好。
Kaiming He 的一篇新論文提出,BYOL 甚至不需要目標編碼器是線上編碼器的指數移動平均值。我決定建立此選項,以便您可以輕鬆地使用該變體進行訓練,只需將use_momentum標誌設為False即可。如果您採取以下範例所示的路線,您將不再需要呼叫update_moving_average 。
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )雖然超參數已設定為論文發現的最佳參數,但您可以使用基本包裝類別的額外關鍵字參數來變更它們。
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
)預設情況下,該程式庫將使用 SimCLR 論文中的增強功能(BYOL 論文中也使用了該內容)。但是,如果您想指定自己的增強管道,則只需使用augment_fn關鍵字傳入您自己的自訂增強函數即可。
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)在論文中,他們似乎確保其中一種增強比另一種增強具有更高的高斯模糊機率。您也可以依照自己的喜好進行調整。
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
)要取得嵌入或投影,您只需將return_embeddings = True標誌傳遞給BYOL學習者實例
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True )該存儲庫現在提供分散式培訓?抱臉加速。您只需將自己的Dataset集傳遞到匯入的BYOLTrainer中
首先透過呼叫加速 CLI 設定分散式訓練的配置
$ accelerate config然後按照如下所示製作訓練腳本,例如./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()然後再次使用加速 CLI 啟動腳本
$ accelerate launch ./train.py如果您的下游任務涉及分段,請查看以下儲存庫,它將 BYOL 擴展到「像素」級學習。
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

