awesome mojo
1.0.0

Mojo — 適合所有開發人員、AI/ML 科學家和軟體工程師的新程式語言。
精選的 Mojo 程式碼、問題解決、解決方案以及未來的程式庫、框架、軟體和資源的清單。
讓我們在這裡累積非常新的技術知識和最佳實踐。
Mojo 是一種程式語言,它將 Python 的使用者友善性與 C++ 和 Rust 的效能功能結合。此外,Mojo 使用戶能夠利用龐大的 Python 庫生態系統。
簡而言之
Mojo 是一種新的程式語言,透過將最好的 Python 語法與系統程式設計和元程式設計相結合,彌合了研究和生產之間的差距。
hello.mojo或hello.檔案副檔名可以是表情符號!
您可以閱讀更多關於為什麼 Modular 這樣做為什麼 Mojo
我們想要的是一種創新且可擴展的程式設計模型,可以針對人工智慧領域普遍存在的加速器和其他異質系統。 ……應用人工智慧系統需要解決所有這些問題,我們認為沒有理由不能只用一種語言來完成。於是,Mojo誕生了。
但 Python 已經很好地完成了它的工作 =)
我們認為沒有必要在語言文法或社群方面進行創新。所以我們選擇擁抱Python生態系統,因為它的使用如此廣泛,它受到人工智慧生態系統的喜愛,而且因為我們相信它是一門非常好的語言。
Mojo 的意思是「神奇的魅力」或「神奇的力量」。我們認為這是一個為 Python 帶來神奇力量的語言的合適名稱:python:,包括為當今人工智慧中普遍存在的加速器和其他異質系統解鎖創新的程式設計模型。
Guido van Rossum仁慈的終身獨裁者和Christopher Arthur Lattner傑出的發明家、創造者和 Mojo 的著名領導者 發音 =)
根據描述
誰知道這些程式語言會非常高興,因為 Mojo 受益於從其他語言 Rust、Swift、Julia、Zig、Nim 等中學到的大量經驗教訓。
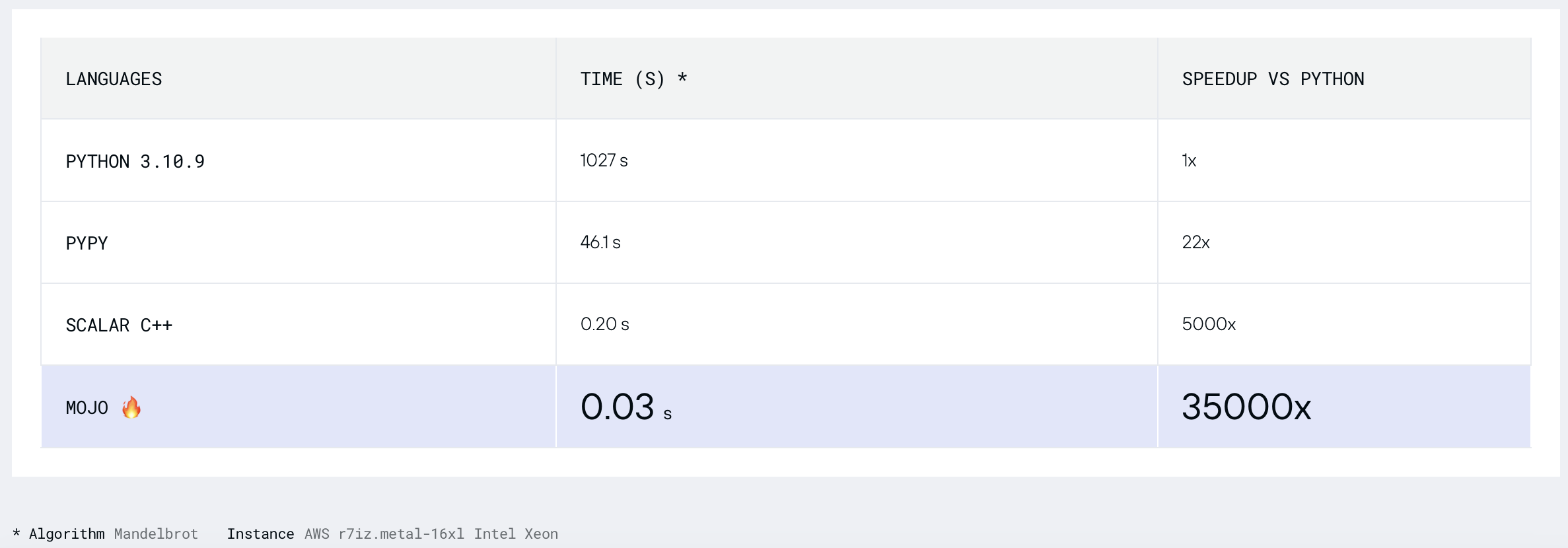
[新的]
Github 現在自動偵測 Mojo 程式碼!
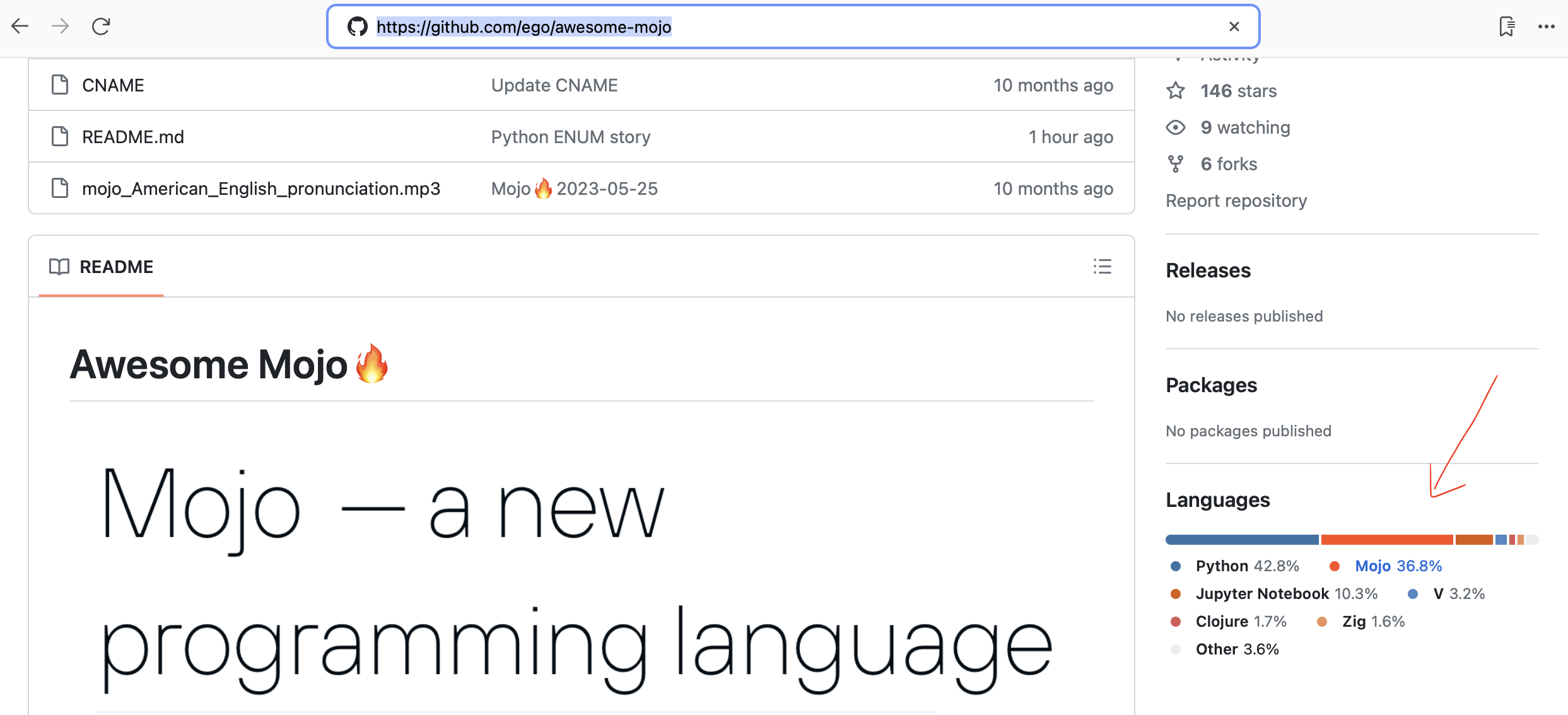
Mojo 的簡單快速 HTTP 框架!非常適合建立 Web 服務和簡單的 API。對於莫吉西安人
LLama 實作基準測試框架
自動 Python 到 Mojo 程式碼翻譯
程式語言資料庫研究
2023 年 10 月 19 日 Mojo 現已在 Mac 上推出!使用開發者控制台
Chris Lattner:程式設計與人工智慧的未來 |萊克斯·弗里德曼播客 #381
Mojo 與 Python 類型系統解釋 |克里斯·拉特納和萊克斯·弗里德曼
Mojo 可以運行 Python 程式碼嗎? |克里斯·拉特納和萊克斯·弗里德曼
從 Python 切換到 Mojo 程式語言 |克里斯·拉特納和萊克斯·弗里德曼
新的 GitHub 主題 mojo-lang。所以你可以遵循它。
Guido van Rossum 關於 Mojo = Python 與 C++/GPU 效能?
具有一些基本操作的張量結構#251
矩陣 fn 與 numpy #267
關於 mojo 中的lambda和parameter閉包以及更高階函數的更新 #244
2023 年 5 月 25 日,Python 的創建者和榮譽 BDFL 的 Guido van Rossum (gvanrossum#8415) 訪問 Mojo 公共 Discord 聊天室
等待 GitHub 上的 Mojo 語法高亮顯示
新版 Mojo 發行 2023-05-24
[老的]
莫喬
brew install hyperfinebrew install macchinapip3 install numpy matplotlib scipybrew install silicon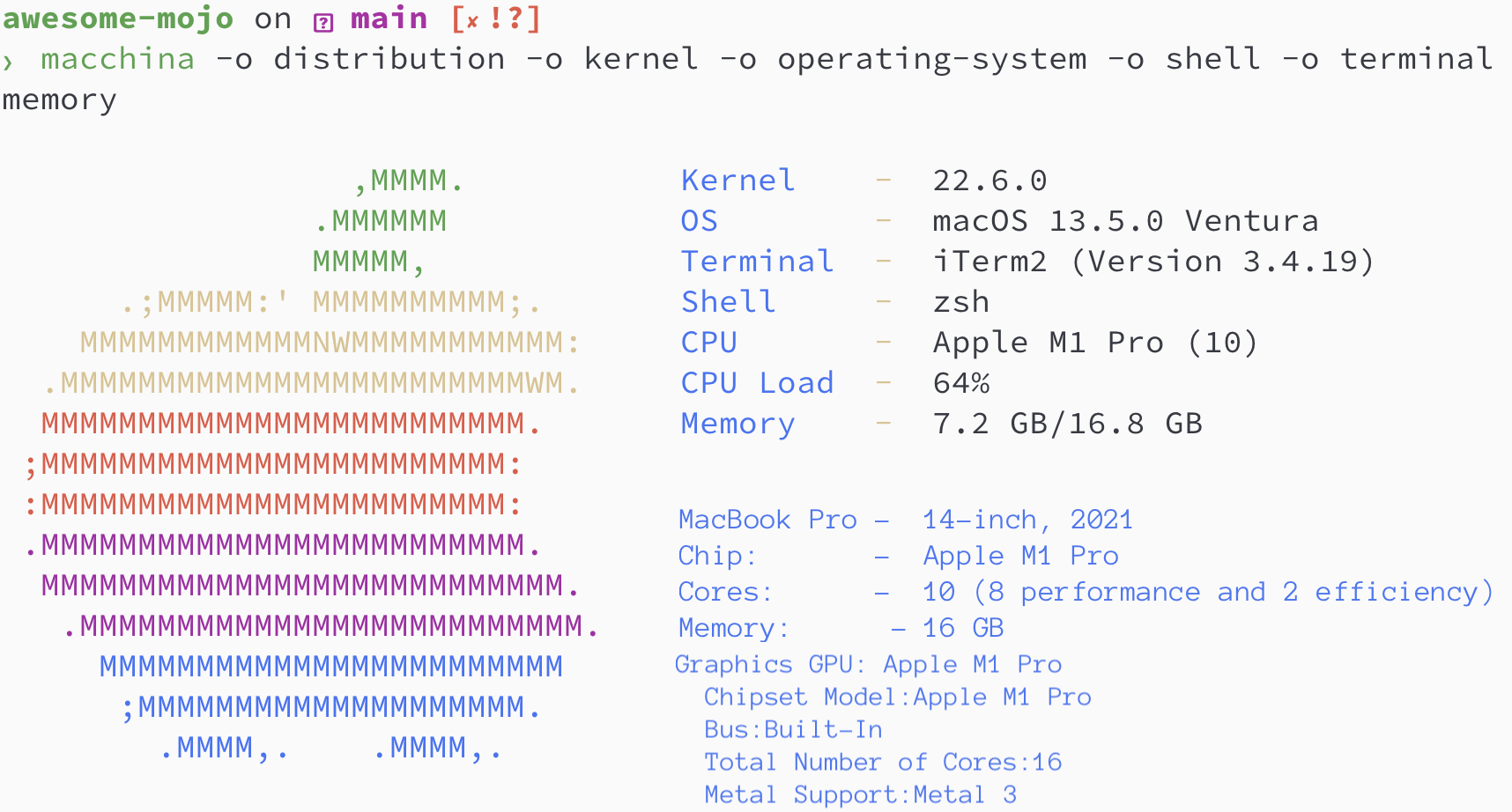
Python / Mojo / Codon / Rust 版本
> python3 --version
Python 3.11.6
> mojo --version
mojo 0.4.0 (9e33b013)
> codon --version
0.16.3
> rustc --version
rustc 1.65.0-nightly (9243168fa 2022-08-31)讓我們找出斐波那契數列
N = 100
def fibonacci_recursion ( n ):
return n if n < 2 else fibonacci_recursion ( n - 1 ) + fibonacci_recursion ( n - 2 )
fibonacci_recursion ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json python_recursion.json ' python3 benchmarks/fibonacci_sequence/python_recursion.py '結果:超時,1m 後我取消了計算
def fibonacci_iteration ( n ):
a , b = 0 , 1
for _ in range ( n ):
a , b = b , a + b
return a
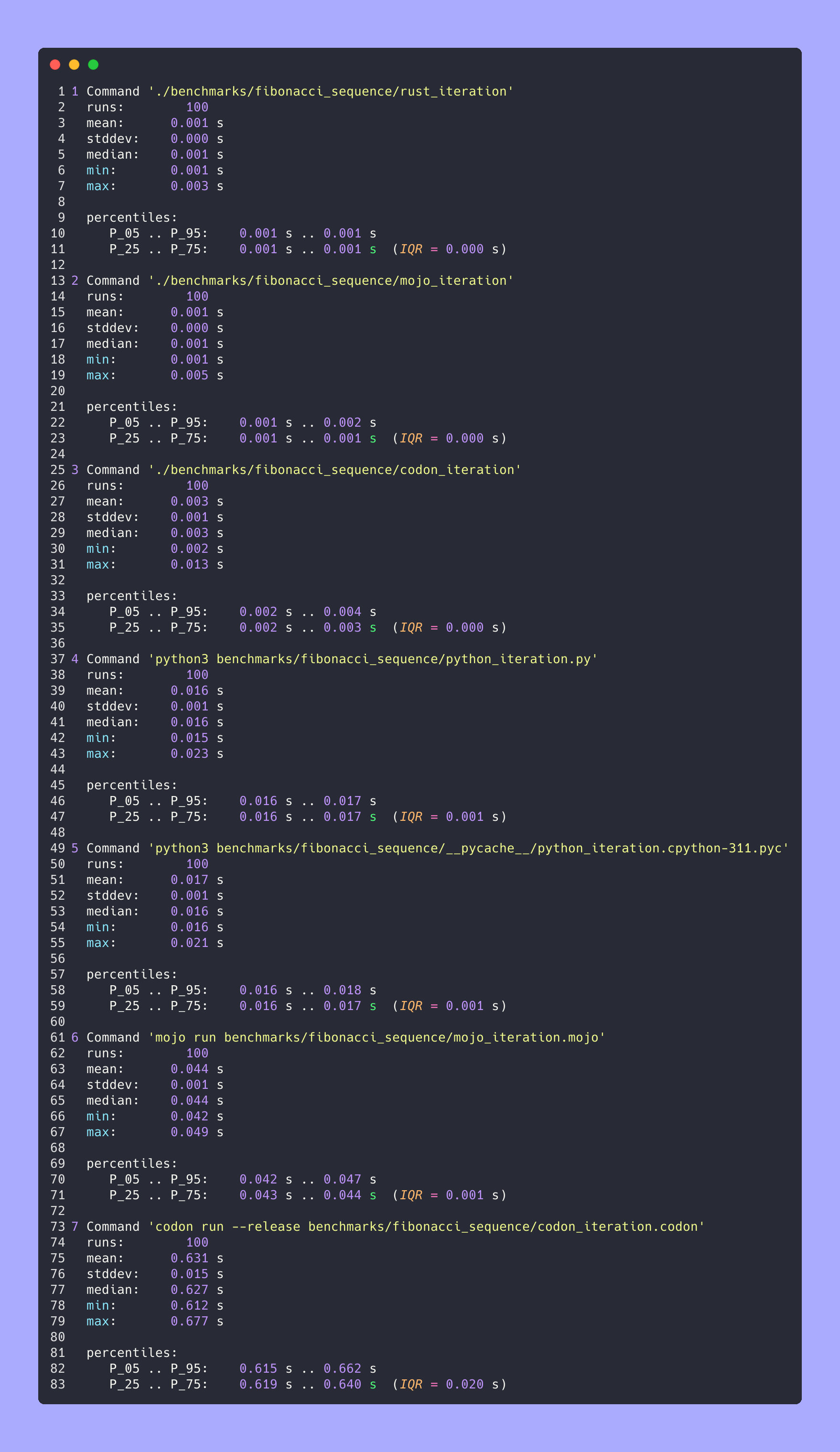
fibonacci_iteration ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.json ' python3 benchmarks/fibonacci_sequence/python_iteration.py '結果:
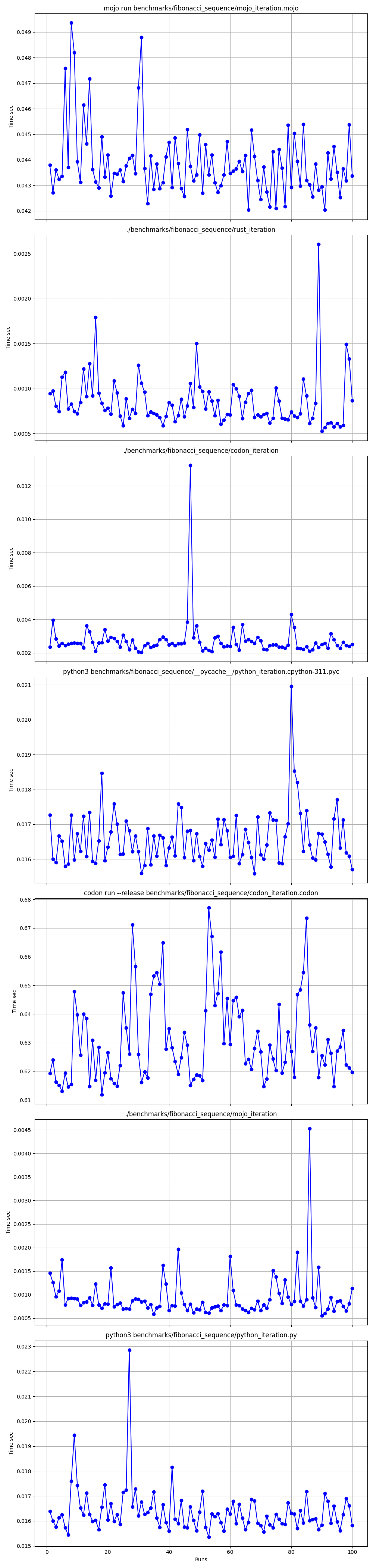
基準1:python3 benchmarks/fibonacci_sequence/python_iteration.py
時間(平均值 ± σ):16374.7 µs ± 904.0 µs [使用者:11483.5 µs,系統:3680.0 µs]
範圍(最小值 … 最大值):15361.0 µs … 22863.3 µs 100 次運行
python3 -m compileall benchmarks/fibonacci_sequence/python_recursion.py
python3 -m compileall benchmarks/fibonacci_sequence/python_iteration.pyhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_recursion.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_recursion.cpython-311.pyc '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_iteration.cpython-311.pyc '結果:
基準1:python3 benchmarks/fibonacci_sequence/ pycache /python_iteration.cpython-311.pyc
時間(平均值 ± σ):16584.6 µs ± 761.5 µs [使用者:11451.8 µs,系統:3813.3 µs]
範圍(最小值 … 最大值):15592.0 µs … 20953.2 µs 100 次運行
fn fibonacci_recursion ( n : Int) -> Int:
return n if n < 2 else fibonacci_recursion(n - 1 ) + fibonacci_recursion(n - 2 )
fn main ():
_ = fibonacci_recursion( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.json ' mojo run benchmarks/fibonacci_sequence/mojo_recursion.mojo '結果:超時,1m 後我取消了計算
fn fibonacci_iteration ( n : Int) -> Int:
var a : Int = 0
var b : Int = 1
for _ in range (n):
a = b
b = a + b
return a
fn main ():
_ = fibonacci_iteration( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.json ' mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo '結果:
基準1:mojo運行 benchmarks/fibonacci_sequence/mojo_iteration.mojo
時間(平均值 ± σ):43852.7 µs ± 1353.5 µs [使用者:38156.0 µs,系統:10407.3 µs]
範圍(最小值 … 最大值):42033.6 µs … 49357.3 µs 100 次運行
mojo build benchmarks/fibonacci_sequence/mojo_recursion.mojo
mojo build benchmarks/fibonacci_sequence/mojo_iteration.mojohyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.exe.json ' ./benchmarks/fibonacci_sequence/mojo_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.exe.json ' ./benchmarks/fibonacci_sequence/mojo_iteration '結果:
基準1:./benchmarks/fibonacci_sequence/mojo_iteration
時間(平均值 ± σ):934.6 µs ± 468.9 µs [使用者:409.8 µs,系統:247.8 µs]
範圍(最小值 … 最大值):552.7 µs … 4522.9 µs 100 次運行
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_recursion.json ' codon run --release benchmarks/fibonacci_sequence/codon_recursion.codon '結果:超時,1m 後我取消了計算
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.json ' codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon '結果:
基準1:codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon
時間(平均值 ± σ):628060.1 µs ± 10430.5 µs [使用者:584524.3 µs,系統:39358.5 µs]
範圍(最小值 … 最大值):612742.5 µs … 662716.9 µs 100 次運行
codon build --release -exe benchmarks/fibonacci_sequence/codon_recursion.codon
codon build --release -exe benchmarks/fibonacci_sequence/codon_iteration.codonhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json codon_recursion.exe.json ' ./benchmarks/fibonacci_sequence/codon_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.exe.json ' ./benchmarks/fibonacci_sequence/codon_iteration '結果:
基準1:./benchmarks/fibonacci_sequence/codon_iteration
時間(平均值 ± σ):2732.7 µs ± 1145.5 µs [使用者:1466.0 µs,系統:1061.5 µs]
範圍(最小值 … 最大值):2036.6 µs … 13236.3 µs 100 次運行
fn fibonacci_recursive ( n : i64 ) -> i64 {
if n < 2 {
return n ;
}
return fibonacci_recursive ( n - 1 ) + fibonacci_recursive ( n - 2 ) ;
}
fn main ( ) {
let _ = fibonacci_recursive ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_recursion.rs -o benchmarks/fibonacci_sequence/rust_recursion
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_recursion.json ' ./benchmarks/fibonacci_sequence/rust_recursion '結果:超時,1m 後我取消了計算
fn fibonacci_iteration ( n : usize ) -> usize {
let mut a = 1 ;
let mut b = 1 ;
for _ in 1 ..n {
let old = a ;
a = b ;
b += old ;
}
b
}
fn main ( ) {
let _ = fibonacci_iteration ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_iteration.rs -o benchmarks/fibonacci_sequence/rust_iteration
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_iteration.json ' ./benchmarks/fibonacci_sequence/rust_iteration '結果:
基準1:./benchmarks/fibonacci_sequence/rust_iteration
時間(平均值 ± σ):848.9 µs ± 283.2 µs [使用者:371.8 µs,系統:261.4 µs]
範圍(最小值 … 最大值):525.9 µs … 2607.3 µs 100 次運行
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/fibonacci_sequence/ benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/fibonacci_sequence/benchmarks.json > benchmarks/fibonacci_sequence/benchmarks.json.md
silicon benchmarks/fibonacci_sequence/benchmarks.json.md -l python -o benchmarks/fibonacci_sequence/benchmarks.json.md.png高級統計
全部在一起
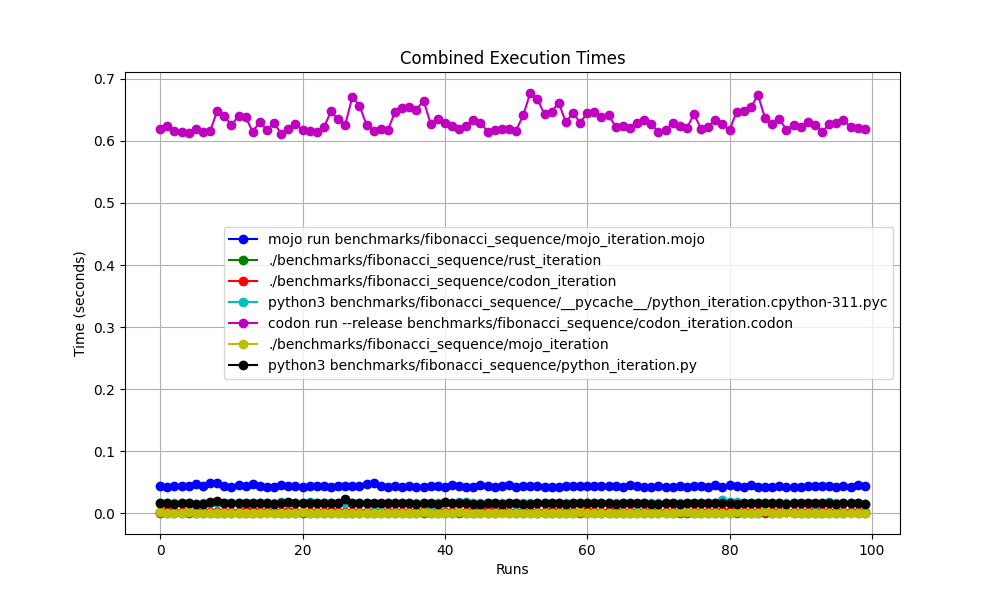
縮放
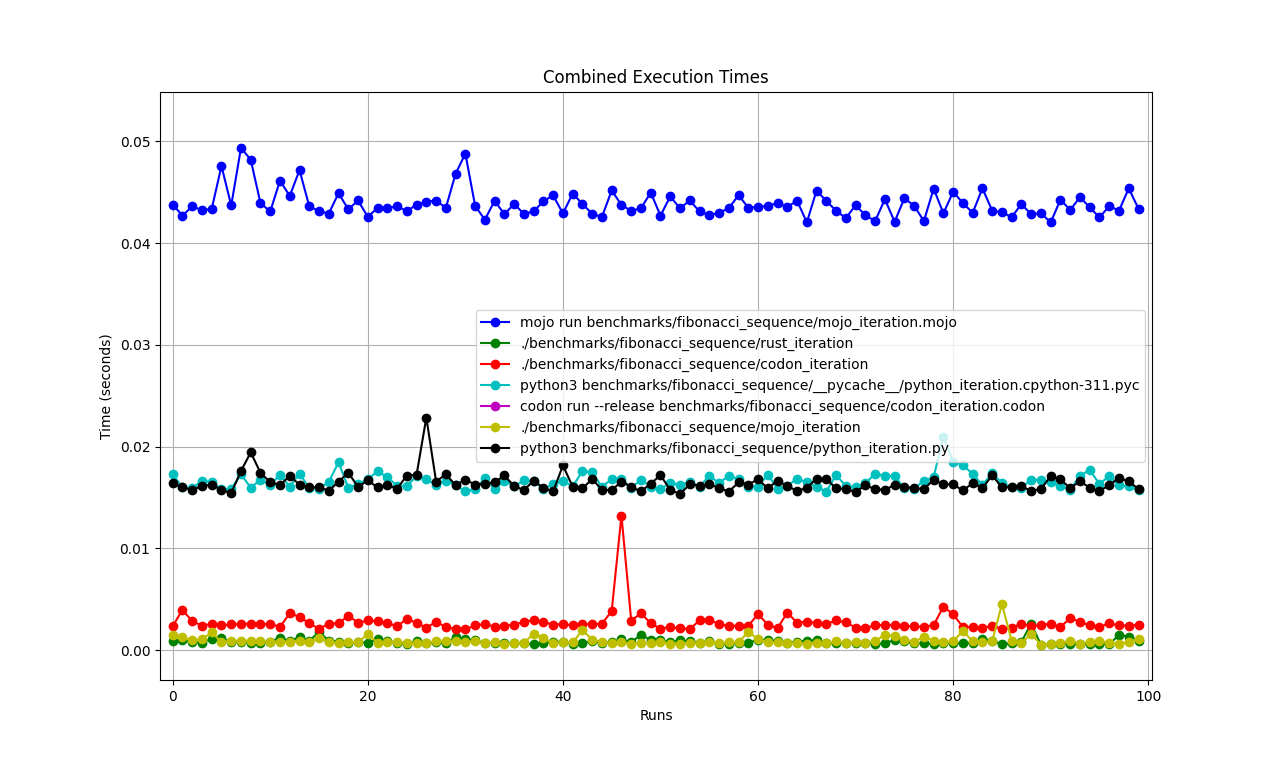
一一詳解
地點
但這裡有很多問題:
mojo run這麼慢?codon run --release這麼慢?run得更快?因此,我們可以說 Mojo 與 Mac 上的 Rust 一樣快!
讓我們在哪裡找到曼德布羅特集
寬度 = 960
高度 = 960
最大迭代數 = 200
MIN_X = -2.0
最大 X = 0.6
最小 Y = -1.5
最大Y = 1.5
def mandelbrot_kernel ( c ):
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z . real * z . real + z . imag * z . imag > 4 :
return i
return MAX_ITERS
def compute_mandelbrot ():
t = [[ 0 for _ in range ( WIDTH )] for _ in range ( HEIGHT )] # Pixel matrix
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
for row in range ( HEIGHT ):
for col in range ( WIDTH ):
t [ row ][ col ] = mandelbrot_kernel ( complex ( MIN_X + col * dx , MIN_Y + row * dy ))
return t
compute_mandelbrot ()python3 -m compileall benchmarks/multibrot_set/multibrot.py
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.cpython-311.json ' python3 benchmarks/multibrot_set/__pycache__/multibrot.cpython-311.pyc '結果:
基準測試 1:python3 benchmarks/multibrot_set/ pycache /multibrot.cpython-311.pyc
時間(平均值 ± σ):5444155.4 µs ± 23059.7 µs [使用者:5419790.1 µs,系統:18131.3 µs]
範圍(最小值 … 最大值):5408155.3 µs … 5490548.4 µs 10 次運行
Mojo 版本沒有最佳化。
# Compute the number of steps to escape.
def multibrot_kernel ( c : ComplexFloat64) -> Int:
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.squared_norm() > 4 :
return i
return MAX_ITERS
def compute_multibrot () -> Tensor[FloatType]:
# create a matrix. Each element of the matrix corresponds to a pixel
t = Tensor[FloatType]( HEIGHT , WIDTH )
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
y = MIN_Y
for row in range ( HEIGHT ):
x = MIN_X
for col in range ( WIDTH ):
t[Index(row, col)] = multibrot_kernel(ComplexFloat64(x, y))
x += dx
y += dy
return t
_ = compute_multibrot()mojo build benchmarks/multibrot_set/multibrot.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.exe.json ' ./benchmarks/multibrot_set/multibrot '結果:
基準1:./benchmarks/multibrot_set/multibrot
時間(平均值 ± σ):135880.5 µs ± 1175.4 µs [使用者:133309.3 µs,系統:1700.1 µs]
範圍(最小值 … 最大值):134639.9 µs … 137621.4 µs 10 次運行
fn mandelbrot_kernel_SIMD [
simd_width : Int
]( c : ComplexSIMD[float_type, simd_width]) -> SIMD [float_type, simd_width]:
""" A vectorized implementation of the inner mandelbrot computation. """
let cx = c.re
let cy = c.im
var x = SIMD [float_type, simd_width]( 0 )
var y = SIMD [float_type, simd_width]( 0 )
var y2 = SIMD [float_type, simd_width]( 0 )
var iters = SIMD [float_type, simd_width]( 0 )
var t : SIMD [DType.bool, simd_width] = True
for i in range ( MAX_ITERS ):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1 , iters)
return iters
fn compute_multibrot_parallelized () -> Tensor[float_type]:
let t = Tensor[float_type](height, width)
@parameter
fn worker ( row : Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector [ simd_width : Int]( col : Int):
""" Each time we operate on a `simd_width` vector of pixels. """
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
# Parallelized
parallelize[worker](height, height)
return t
def main ():
_ = compute_multibrot_parallelized()mojo build benchmarks/multibrot_set/multibrot_mojo_parallelize.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_mojo_parallelize.exe.json ' ./benchmarks/multibrot_set/multibrot_mojo_parallelize '結果:
基準1:./benchmarks/multibrot_set/multibrot_mojo_parallelize
時間(平均值 ± σ):7139.4 µs ± 596.4 µs [使用者:36535.2 µs,系統:6670.1 µs]
範圍(最小值 … 最大值):6222.6 µs … 8269.7 µs 10 次運行
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
@par(collapse=2)
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
用於測試運行或繪圖(取消文件中程式碼的註解)
CODON_PYTHON=/opt/homebrew/opt/[email protected]/Frameworks/Python.framework/Versions/3.11/lib/libpython3.11.dylib codon run --release benchmarks/multibrot_set/multibrot.codon建置並運行
codon build --release -exe benchmarks/multibrot_set/multibrot.codon -o benchmarks/multibrot_set/multibrot_codon
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon.json ' ./benchmarks/multibrot_set/multibrot_codon '結果:
基準1:./benchmarks/multibrot_set/multibrot_codon
時間(平均值 ± σ):44184.7 µs ± 1142.0 µs [使用者:248773.9 µs,系統:72935.3 µs]
範圍(最小值 … 最大值):42963.8 µs … 46456.2 µs 10 次運行
codon build --release -exe benchmarks/multibrot_set/multibrot_codon_par.codon -o benchmarks/multibrot_set/multibrot_codon_par
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon_par.json ' ./benchmarks/multibrot_set/multibrot_codon_par ' # Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/multibrot_set/ benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/multibrot_set/benchmarks.json > benchmarks/multibrot_set/benchmarks.json.md
silicon benchmarks/multibrot_set/benchmarks.json.md -l python -o benchmarks/multibrot_set/benchmarks.json.md.png高級統計
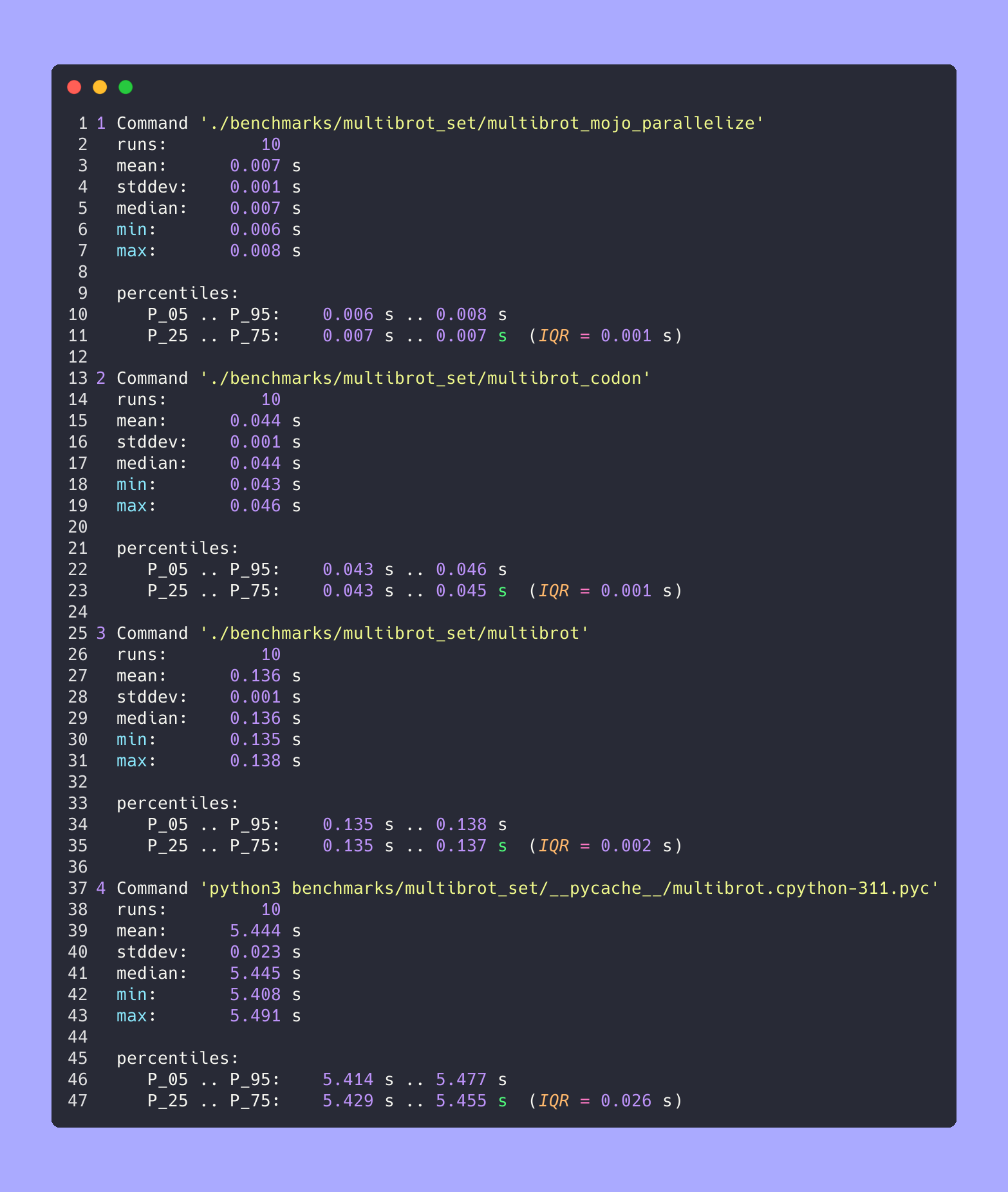
全部在一起
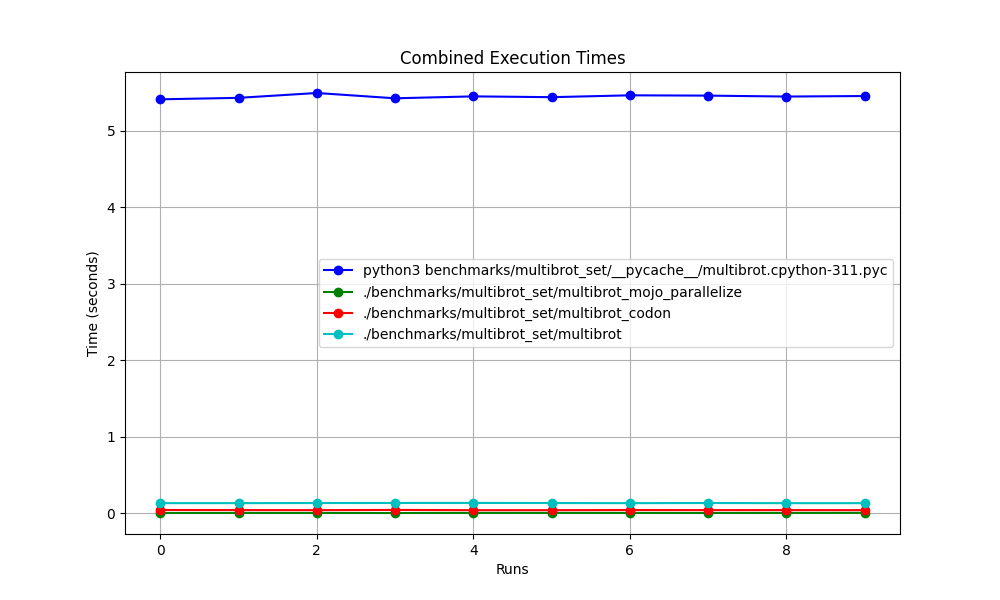
縮放
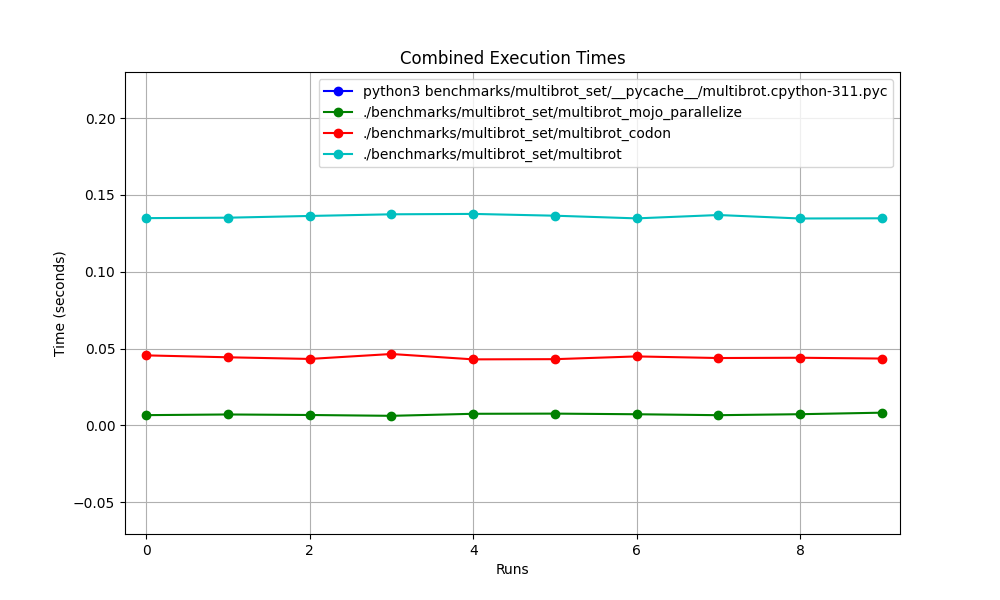
一一詳解
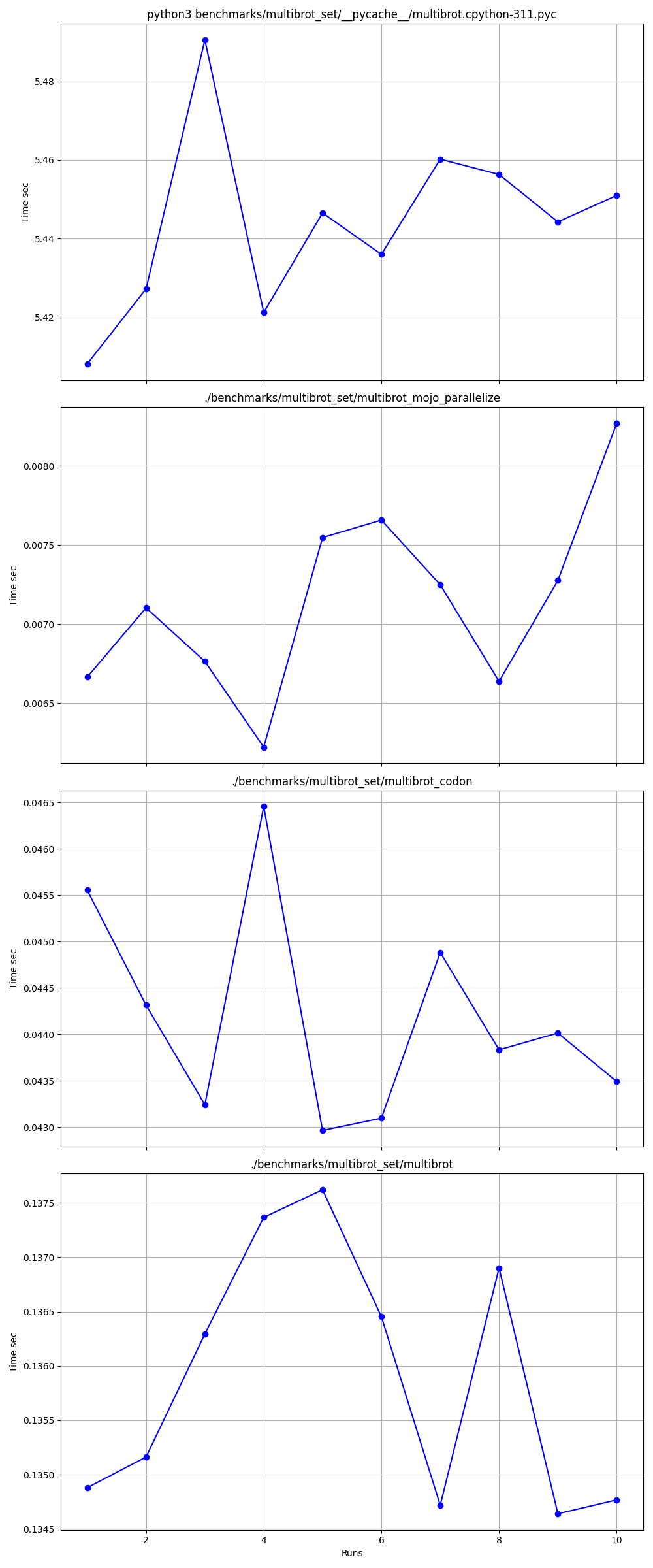
地點
連結:
Mandelbrot = Multibrot power = 2
z = z ** power + c # You can change this for different set枕頭內建 ImagingEffectMandelbrot
Mandelbrot 的 Exaloop 密碼子版本
Mandelbrot 的模組化 Mojo 版本
Mojo 複雜 squared_norm
Matplotlib 曼德布羅特
在電腦科學中,二分搜尋演算法也稱為半區間搜尋、對數搜尋或二分查找,是一種查找目標值在排序數組中的位置的搜尋演算法。
讓我們使用 Python、Mojo、Swift、V、Julia、Nim、Zig 來寫一些程式碼。
注意:對於Python和Mojo版本,我保留了一些優化並使程式碼相似以進行測量和比較。
from typing import List
import timeit
SIZE = 1000000
MAX_ITERS = 100
COLLECTION = tuple ( i for i in range ( SIZE )) # Make it aka at compile-time.
def python_binary_search ( element : int , array : List [ int ]) -> int :
start = 0
stop = len ( array ) - 1
while start <= stop :
index = ( start + stop ) // 2
pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
def test_python_binary_search ():
_ = python_binary_search ( SIZE - 1 , COLLECTION )
print (
"Average execution time of func in sec" ,
timeit . timeit ( lambda : test_python_binary_search (), number = MAX_ITERS ),
) """Implements basic binary search."""
from Benchmark import Benchmark
from Vector import DynamicVector
alias SIZE = 1000000
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn mojo_binary_search ( element : Int , array : DynamicVector [ Int ]) - > Int :
var start = 0
var stop = len ( array ) - 1
while start <= stop :
let index = ( start + stop ) // 2
let pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
@ parameter # statement runs at compile-time.
fn get_collection () - > DynamicVector [ Int ]:
var v = DynamicVector [ Int ]( SIZE )
for i in range ( SIZE ):
v . push_back ( i )
return v
fn test_mojo_binary_search () - > F64 :
fn test_closure ():
_ = mojo_binary_search ( SIZE - 1 , get_collection ())
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ test_closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
test_mojo_binary_search (),
)這是第一個在 Mojoby 社群 (@ego) 中撰寫並發佈在 mojo-chat 中的二分搜尋。
func binarySearch ( items : [ Int ] , elem : Int ) -> Int {
var low = 0
var high = items . count - 1
var mid = 0
while low <= high {
mid = Int ( ( high + low ) / 2 )
if items [ mid ] < elem {
low = mid + 1
} else if items [ mid ] > elem {
high = mid - 1
} else {
return mid
}
}
return - 1
}
let items = [ 1 , 2 , 3 , 4 , 0 ] . sorted ( )
let res = binarySearch ( items : items , elem : 4 )
print ( res ) function binarysearch (lst :: Vector{T} , val :: T ) where T
low = 1
high = length (lst)
while low ≤ high
mid = (low + high) ÷ 2
if lst[mid] > val
high = mid - 1
elseif lst[mid] < val
low = mid + 1
else
return mid
end
end
return 0
end proc binarySearch [T](a: openArray [T], key: T): int =
var b = len (a)
while result < b:
var mid = ( result + b) div 2
if a[mid] < key: result = mid + 1
else : b = mid
if result >= len (a) or a[ result ] != key: result = - 1
let res = @ [ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 12 , 14 , 16 , 18 , 20 , 22 , 25 , 27 , 30 ]
echo binarySearch (res, 10 ) const std = @import ( "std" );
fn binarySearch ( comptime T : type , arr : [] const T , target : T ) ? usize {
var lo : usize = 0 ;
var hi : usize = arr . len - 1 ;
while ( lo <= hi ) {
var mid : usize = ( lo + hi ) / 2 ;
if ( arr [ mid ] == target ) {
return mid ;
} else if ( arr [ mid ] < target ) {
lo = mid + 1 ;
} else {
hi = mid - 1 ;
}
}
return null ;
} fn binary_search (a [] int , value int ) int {
mut low := 0
mut high := a.len - 1
for low < = high {
mid := (low + high) / 2
if a[mid] > value {
high = mid - 1
} else if a[mid] < value {
low = mid + 1
} else {
return mid
}
}
return - 1
}
fn main () {
search_list := [ 1 , 2 , 3 , 5 , 6 , 7 , 8 , 9 , 10 ]
println ( binary_search (search_list, 9 ))
} fn breadth_first_search_path (graph map [ string ][] string , vertex string , target string ) [] string {
mut path := [] string {}
mut visited := [] string {init: vertex}
mut queue := [][][] string {}
queue << [[vertex], path]
for queue.len > 0 {
mut idx := queue.len - 1
node := queue[idx][ 0 ][ 0 ]
path = queue[idx][ 1 ]
queue. delete (idx)
if node == target {
path << node
return path
}
for child in graph[node] {
mut tmp := path. clone ()
if child ! in visited {
visited << child
tmp << node
queue << [[child], tmp]
}
}
}
return path
}
fn main () {
graph := map {
'A' : [ 'B' , 'C' ]
'B' : [ 'A' , 'D' , 'E' ]
'C' : [ 'A' , 'F' ]
'D' : [ 'B' ]
'E' : [ 'B' , 'F' ]
'F' : [ 'C' , 'E' ]
}
println ( 'Graph: $graph ' )
path := breadth_first_search_path (graph, 'A' , 'F' )
println ( 'The shortest path from node A to node F is: $path ' )
assert path == [ 'A' , 'C' , 'F' ]
} import timeit
SIZE = 100
MAX_ITERS = 100
def _fizz_buzz (): # Make it aka at compile-time.
res = []
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
s = "FizzBuzz"
elif n % 3 == 0 :
s = "Fizz"
elif n % 5 == 0 :
s = "Buzz"
else :
s = str ( n )
res . append ( s )
return res
DATA = _fizz_buzz ()
def fizz_buzz ():
print ( " n " . join ( DATA ))
print (
"Average execution time of Python func in sec" ,
timeit . timeit ( lambda : fizz_buzz (), number = MAX_ITERS ),
)
# Average execution time of Python func in sec 0.005334990004485007 ( import '[java.io OutputStream])
( require '[clojure.java.io :as io])
( def devnull ( io/writer ( OutputStream/nullOutputStream )))
( defmacro timeit [n expr]
`(with-out-str ( time
( dotimes [_# ~( Math/pow 1 n)]
( binding [*out* devnull]
~expr)))))
( defmacro macro-fizz-buzz [n]
`( fn []
( print
~( apply str
( for [i ( range 1 ( inc n))]
( cond
( zero? ( mod i 15 )) " FizzBuzz n "
( zero? ( mod i 5 )) " Buzz n "
( zero? ( mod i 3 )) " Fizz n "
:else ( str i " n " )))))))
( print ( timeit 100 ( macro-fizz-buzz 100 )))
; ; "Elapsed time: 0.175486 msecs"
; ; Average execution time of Clojure func in sec 0.000175486 seconds from String import String
from Benchmark import Benchmark
alias SIZE = 100
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
@ parameter # statement runs at compile-time.
fn _fizz_buzz () - > String :
var res : String = ""
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
res += "FizzBuzz"
elif n % 3 == 0 :
res += "Fizz"
elif n % 5 == 0 :
res += "Buzz"
else :
res += String ( n )
res += " n "
return res
fn fizz_buzz ():
print ( _fizz_buzz ())
fn run_benchmark () - > F64 :
fn _closure ():
_ = fizz_buzz ()
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
run_benchmark (),
)
# Average execution time of func in sec 0.000104 這是社群 (@Ego) 用 Mojo 寫的第一個 Fizz 嗡嗡聲。
我們將使用眾所周知的演算法參考書《演算法簡介 A3》中的演算法
它的名氣導致了縮寫「 CLRS 」(Cormen、Leiserson、Rivest、Stein)的普遍使用,或是在第一版中為「 CLR 」(Cormen、Leiserson、Rivest)。
第 2 章「2.3.1 分治法」。
% % python
import timeit
MAX_ITERS = 100
def merge ( A , p , q , r ):
n1 = q - p + 1
n2 = r - q
L = [ None ] * n1
R = [ None ] * n2
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
i = 0
j = 0
k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
def merge_sort ( A , p , r ):
if p < r :
q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
def run_benchmark_merge_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
merge_sort ( A , 0 , len ( A ) - 1 )
print (
"Average execution time of Python `merge_sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_merge_sort (), number = MAX_ITERS ),
)
# Average execution time of Python `merge_sort` in sec 0.019136679999064654
def run_benchmark_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
A . sort ()
print (
"Average execution time of Python builtin `sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_sort (), number = MAX_ITERS ),
)
# Average execution time of Python builtin `sort` in sec 0.00019922800129279494 from Benchmark import Benchmark
from Vector import DynamicVector
from StaticTuple import StaticTuple
from Sort import sort
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn merge ( inout A : DynamicVector [ Int ], p : Int , q : Int , r : Int ):
let n1 = q - p + 1
let n2 = r - q
var L = DynamicVector [ Int ]( n1 )
var R = DynamicVector [ Int ]( n2 )
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
var i = 0
var j = 0
var k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
fn merge_sort ( inout A : DynamicVector [ Int ], p : Int , r : Int ):
if p < r :
let q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
@ parameter
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ MAX_ITERS , Int ]( 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
fn run_benchmark_merge_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo `merge_sort` in sec " ,
run_benchmark_merge_sort (),
)
# Average execution time of Mojo `merge_sort` in sec 1.1345999999999999e-05
fn run_benchmark_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
sort ( A )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo builtin `sort` in sec " ,
run_benchmark_sort (),
)
# Average execution time of Mojo builtin `sort` in sec 2.988e-06您可以像這樣使用它:
# Usage: merge_sort
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
print ( len ( A ))
print ( A [ 0 ], A [ 99 ])內建的from Sort import sort快速排序比我們的實作要快一點,但是我們可以在深入的語言中優化它,並像往常一樣使用演算法 =) 和程式設計範例。
| 郎 | 秒 |
|---|---|
| Python 合併排序 | 0.019136679 |
| Python 內建排序 | 0.000199228 |
| Mojo合併排序 | 0.000011346 |
| Mojo 內建排序 | 0.000002988 |
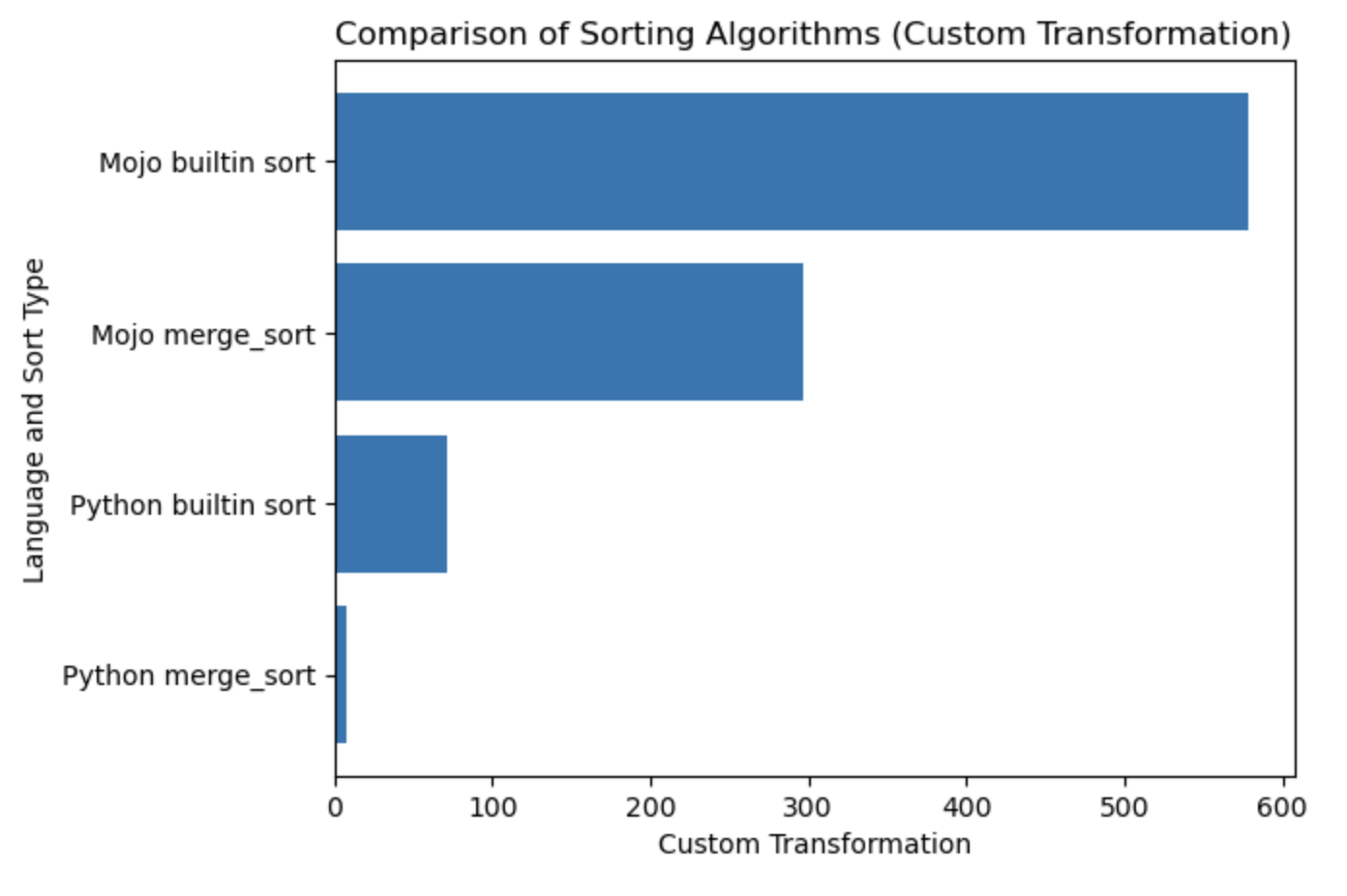
讓我們為該表繪製一個圖。
#%%python
import matplotlib . pyplot as plt
import numpy as np
languages = [ 'Python merge_sort' , 'Python builtin sort' , 'Mojo merge_sort' , 'Mojo builtin sort' ]
seconds = [ 0.019136679 , 0.000199228 , 0.000011346 , 0.000002988 ]
# Apply a custom transformation to the values
transformed_seconds = [ np . sqrt ( 1 / x ) for x in seconds ]
plt . barh ( languages , transformed_seconds )
plt . xlabel ( 'Custom Transformation' )
plt . ylabel ( 'Language and Sort Type' )
plt . title ( 'Comparison of Sorting Algorithms (Custom Transformation)' )
plt . show ()情節筆記,越多越好、越快。
我強烈建議從這裡 HelloMojo 開始,並在這裡了解[參數]和[參數表達式]參數化。就像這個例子:
fn concat [ len1 : Int , len2 : Int ]( lhs : MySIMD [ len1 ], rhs : MySIMD [ len2 ]) - > MySIMD [ len1 + len2 ]:
let result = MySIMD [ len1 + len2 ]()
for i in range ( len1 ):
result [ i ] = lhs [ i ]
for j in range ( len2 ):
result [ len1 + j ] = rhs [ j ]
return result
let a = MySIMD [ 2 ]( 1 , 2 )
let x = concat [ 2 , 2 ]( a , a )
x . dump ()編譯時【參數】: fn concat[len1: Int, len2: Int] 。
運行時(參數) : fn concat(lhs: MySIMD, rhs: MySIMD) 。
參數 PEP695 語法位於方[]括號中。
現在在Python中:
def func ( a : _T , b : _T ) -> _T :
...現在在Mojo:
def func [ T ]( a : T , b : T ) -> T :
... [參數]的命名和類型與 Mojo 程式中的普通值類似,但parameters[]是在編譯時評估的。
運行時程式可以使用[參數]的值 - 因為參數在運行時程式需要它們之前在編譯時解析 - 但編譯時參數表達式可能不使用運行時值。
PEP673 中的Self鍵入
fn __sub__ ( self , rhs : Self ) - > Self :
let result = MySIMD [ size ]()
for i in range ( size ):
result [ i ] = self [ i ] - rhs [ i ]
return result在文件中,您可以找到「欄位」一詞,它在 Python 中又稱為「類別屬性」 。
所以,你用dot來稱呼它們。
from DType import DType
let bool_type = DType . bool from DType import DType
DType . si8 from DType import DType
from SIMD import SIMD , SI8
alias MY_SIMD_DType_si8 = SIMD [ DType . si8 , 1 ]
alias MY_SI8 = SI8
print ( MY_SIMD_DType_si8 == MY_SI8 )
# true from DType import DType
from SIMD import SIMD , SI8
from Vector import DynamicVector
from String import String
alias a = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias b = DynamicVector [ SI8 ]
print ( a == b )
print ( a == String )
print ( b == String )
# all true所以String只是DynamicVector[SIMD[DType.si8, 1]]之類的別名。
VariadicList from List import VariadicList
fn destructuring_arguments ( * args : Int ):
let my_var_list = VariadicList ( args )
for i in range ( len ( my_var_list )):
print ( "argument" , i , ":" , my_var_list [ i ])
destructuring_arguments ( 1 , 2 , 3 , 4 )它對於創建初始集合非常有用。我們可以這樣寫:
from Vector import DynamicVector
from StaticTuple import StaticTuple
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ 4 , Int ]( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])
# or
from List import VariadicList
fn create_vertor () - > DynamicVector [ Int ]:
let var_list = VariadicList ( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( len ( var_list ))
for i in range ( len ( var_list )):
v . push_back ( var_list [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])閱讀有關函數 def 和 fn 的更多信息
from String import String
# String concatenation
print ( String ( "'" ) + String ( 1 ) + "' n " )
# Python's join
print ( String ( "|" ). join ( "a" , "b" , "c" ))
# String format
from IO import _printf as print
let x : Int = 1
print ( "'%i' n " , x . value )對於字串,您可以使用內建切片,格式為字串 slice[start:end:step]。
from String import String
let hello_mojo = String ( "Hello Mojo!" )
print ( "Till the end:" , hello_mojo [ 0 ::])
print ( "Before last 2 chars:" , hello_mojo [ 0 : - 2 ])
print ( "From start to the end with step 2:" , hello_mojo [ 0 :: 2 ])
print ( "From start to the before last with step 3:" , hello_mojo [ 0 : - 1 : 3 ])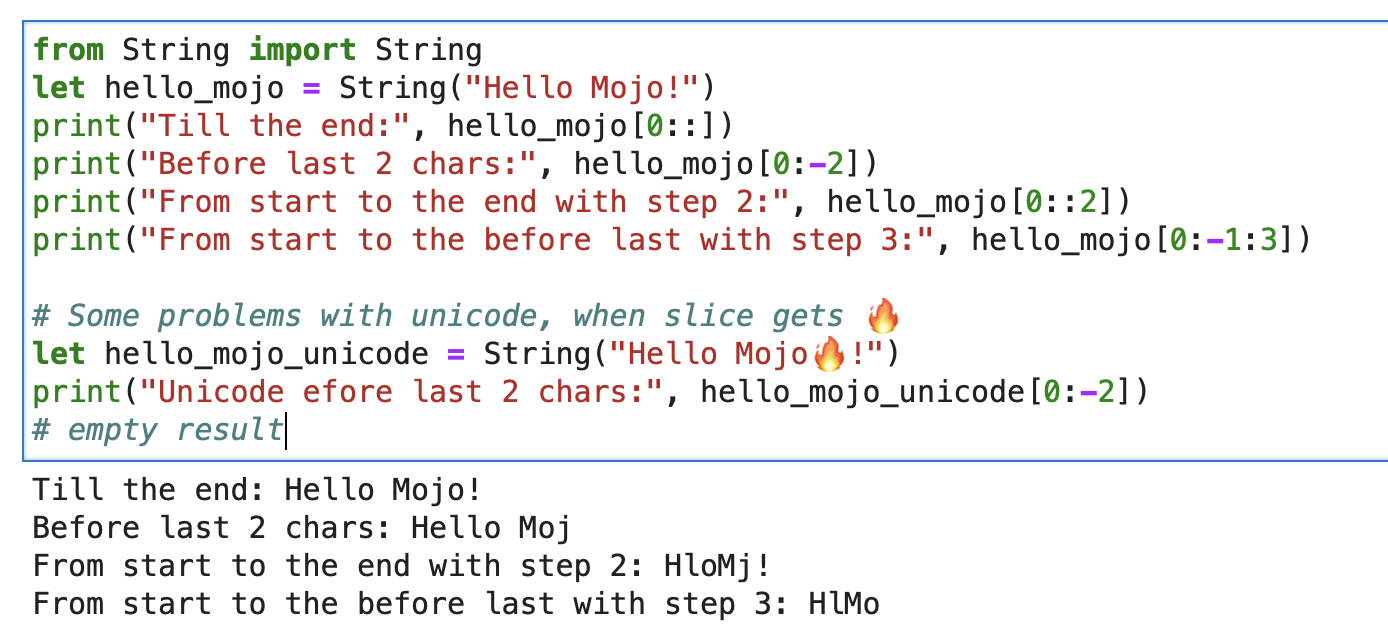
切片時 unicode 存在一些問題:
let hello_mojo_unicode = String ( "Hello Mojo!" )
print ( "Unicode efore last 2 chars:" , hello_mojo_unicode [ 0 : - 2 ])
# no result, silents這是一個解釋和一些討論。
mbstowcs - 將多位元組字串轉換為寬字元字串
struct裝飾器又稱為 Python @dataclass 。它會自動為您產生方法__init__ 、 __copyinit__ 、 __moveinit__ 。
@ value
struct dataclass :
var name : String
var age : Int請注意, @value裝飾器僅適用於成員copyable和/或movable類型。
瑣碎的類型。這個裝飾器告訴 Mojo 該類型應該是可複製的__copyinit__和可移動的__moveinit__ 。它還告訴 Mojo 更喜歡傳遞 CPU 暫存器中的值。允許structs選擇在register中傳遞而不是透過memory傳遞。
@ register_passable ( "trivial" )
struct Int :
var value : __mlir_type . `!pop.scalar<index>`提供對編譯器最佳化的完全控制的裝飾器。指示編譯器在呼叫函數時始終內聯該函數。
@ always_inline
fn foo ( x : Int , y : Int ) - > Int :
return x + y
fn bar ( z : Int ):
let r = foo ( z , z ) # This call will be inlined它可以放置在捕獲運行時值的巢狀函數上,以建立“參數”捕獲閉包。它允許捕獲運行時值的閉包作為參數值傳遞。
@ always_inline
@ parameter
fn test (): return 一些鑄造範例
s : StringLiteral
let p = DTypePointer [ DType . si8 ]( s . data ()). bitcast [ DType . ui8 ]()
var result = 0
result += (( p . simd_load [ 64 ]( offset ) >> 6 ) != 0b10 ). cast [ DType . ui8 ](). reduce_add (). to_int ()
let rest_p : DTypePointer [ DType . ui8 ] = stack_allocation [ simd_width , UI8 , 1 ]()
from Bit import ctlz
s : String
i : Int
let code = s . buffer . data . load ( i )
let byte_length_code = ctlz ( ~ code ). to_int ()DTypePointer - 儲存具有給定 DType 的位址,可讓您透過方便地存取 SIMD 操作來指派、載入和修改資料。
from Pointer import DTypePointer
from DType import DType
from Random import rand
from Memory import memset_zero
# `heap`
var my_pointer_on_heap = DTypePointer [ DType . ui8 ]. alloc ( 8 )
memset_zero ( my_pointer_on_heap , 8 )
# `stack or register`
var data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
rand ( my_pointer_on_heap , 4 )
# `data` does not contain a reference to the `heap`, so load the data again
data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
# simd_load and simd_store
var half = my_pointer_on_heap . simd_load [ 4 ]( 0 )
half = half + 1
my_pointer_on_heap . simd_store [ 4 ]( 4 , half )
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Pointer move back
my_pointer_on_heap -= 1
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Mast free memory
my_pointer_on_heap . free ()struct可以透過限制scoup來最小化指標的潛在危險。
Mojo Dojo 部落格上關於 DTypePointer 的優秀文章在這裡
加上他的範例 Matrix Struct 和 DTypePointer
指標將位址儲存到任何register_passable type ,並將其中n位址指派給heap 。
from Pointer import Pointer
from Memory import memset_zero
from String import String
@ register_passable # for syntaxt like `let coord = p1[0]` and let it be passed through registers.
struct Coord : # memory-only type
var x : UI8
var y : UI8
var p1 = Pointer [ Coord ]. alloc ( 2 )
memset_zero ( p1 , 2 )
var coord = p1 [ 0 ] # is an identifier to memory on the stack or in a register
print ( coord . x )
# Store the value
coord . x = 5
coord . y = 5
print ( coord . x )
# We need to store the data.
p1 . store ( 0 , coord )
print ( p1 [ 0 ]. x )
# Mast free memory
p1 . free ()關於指針的完整文章
再加上指針和結構體的例子
模組化內在,它是某種執行後端:
Mojo-> MLIR 方言 -> 具有最佳化程式碼和架構的執行後端。
MLIR 是一個編譯器基礎設施,可為不同的程式語言和體系結構實現各種轉換和最佳化流程。
MLIR 本身並不會直接提供與作業系統系統呼叫互動的功能。
它們是作業系統服務的低階接口,通常在目標程式語言或作業系統本身的層級進行處理。 MLIR 被設計為與語言和目標無關,其主要重點是提供用於執行最佳化的中間表示。要在 MLIR 中執行作業系統系統調用,我們需要使用特定於目標的後端。
但有了這些execution backends ,基本上,我們就可以存取作業系統系統呼叫。我們擁有 C/LLVM/Python 的整個世界。
讓我們在實踐中快速了解:
from OS import getenv
print ( getenv ( "PATH" ))
print ( getenv ( StringRef ( "PATH" )))
# or like this
from SIMD import SI8
from Intrinsics import external_call
var path1 = external_call [ "getenv" , StringRef ]( StringRef ( "PATH" ))
print ( path1 . data )
var path2 = external_call [ "getenv" , StringRef ]( "PATH" )
print ( path2 . data )
let abs_10 = external_call [ "abs" , SI8 , Int ]( - 10 )
print ( abs_10 )在這個簡單的範例中,我們使用external_call來取得具有 Mojo 和 libc 函數之間的轉換類型的作業系統環境變數。很酷,是啊!
我對這個主題有很多想法,我熱切地等待著盡快實現它們的機會。採取行動可以帶來驚人的結果 =)
讓我們做一些有趣的事情 - 呼叫libc function gethostname。
函數具有此介面int gethostname (char *name, size_t size) 。
為此,我們可以使用Intrinsics模組中的輔助函數 external_call 或編寫自己的 MLIR。
我們來寫程式碼吧:
from Intrinsics import external_call
from SIMD import SIMD , SI8
from DType import DType
from Vector import DynamicVector
from DType import DType
from Pointer import DTypePointer , Pointer
# We can use `from String import String` but for clarification we will use a full form.
# DynamicVector[SIMD[DType.si8, 1]] == DynamicVector[SI8] == String
# Compile time stuff.
alias cArrayOfStrings = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias capacity = 1024
var c_pointer_to_array_of_strings = DTypePointer [ DType . si8 ]( cArrayOfStrings ( capacity ). data )
var c_int_result = external_call [ "gethostname" , Int , DTypePointer [ DType . si8 ], Int ]( c_pointer_to_array_of_strings , capacity )
let mojo_string_result = String ( c_pointer_to_array_of_strings . address )
print ( "C function gethostname result code:" , c_int_result )
print ( "C function gethostname result value:" , star_hostname ( mojo_string_result ))
@ always_inline
fn star_hostname ( hostname : String ) - > String :
# [Builtin Slice](https://docs.modular.com/mojo/MojoBuiltin/BuiltinSlice.html)
# string slice[start:end:step]
return hostname [ 0 : - 1 : 2 ]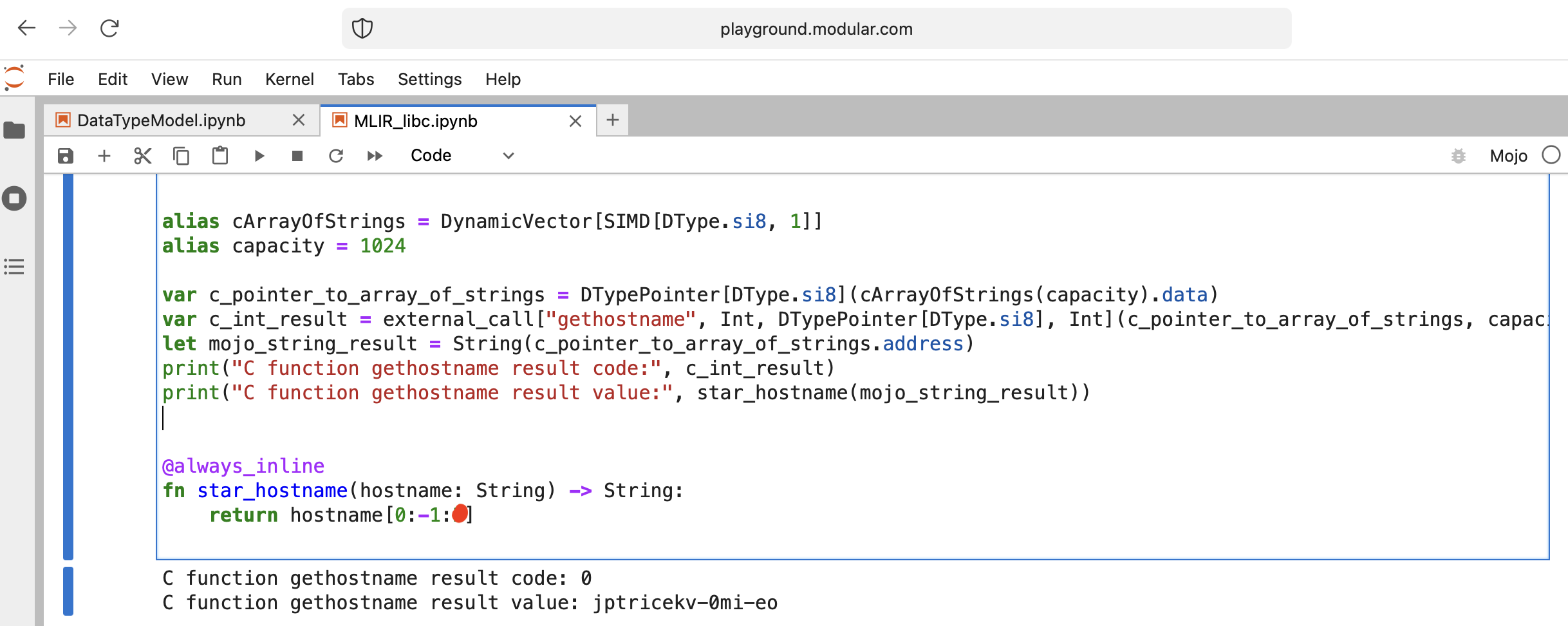
讓我們用 Mojo 為 WEB 做一些事情。我們無法存取 Playground.modular.com,但我們可以在一台機器上做一些有趣的事情,例如 TCP。
讓我們使用 PythonInterface 在 Mojo 中編寫第一個 TCP 用戶端-伺服器程式碼
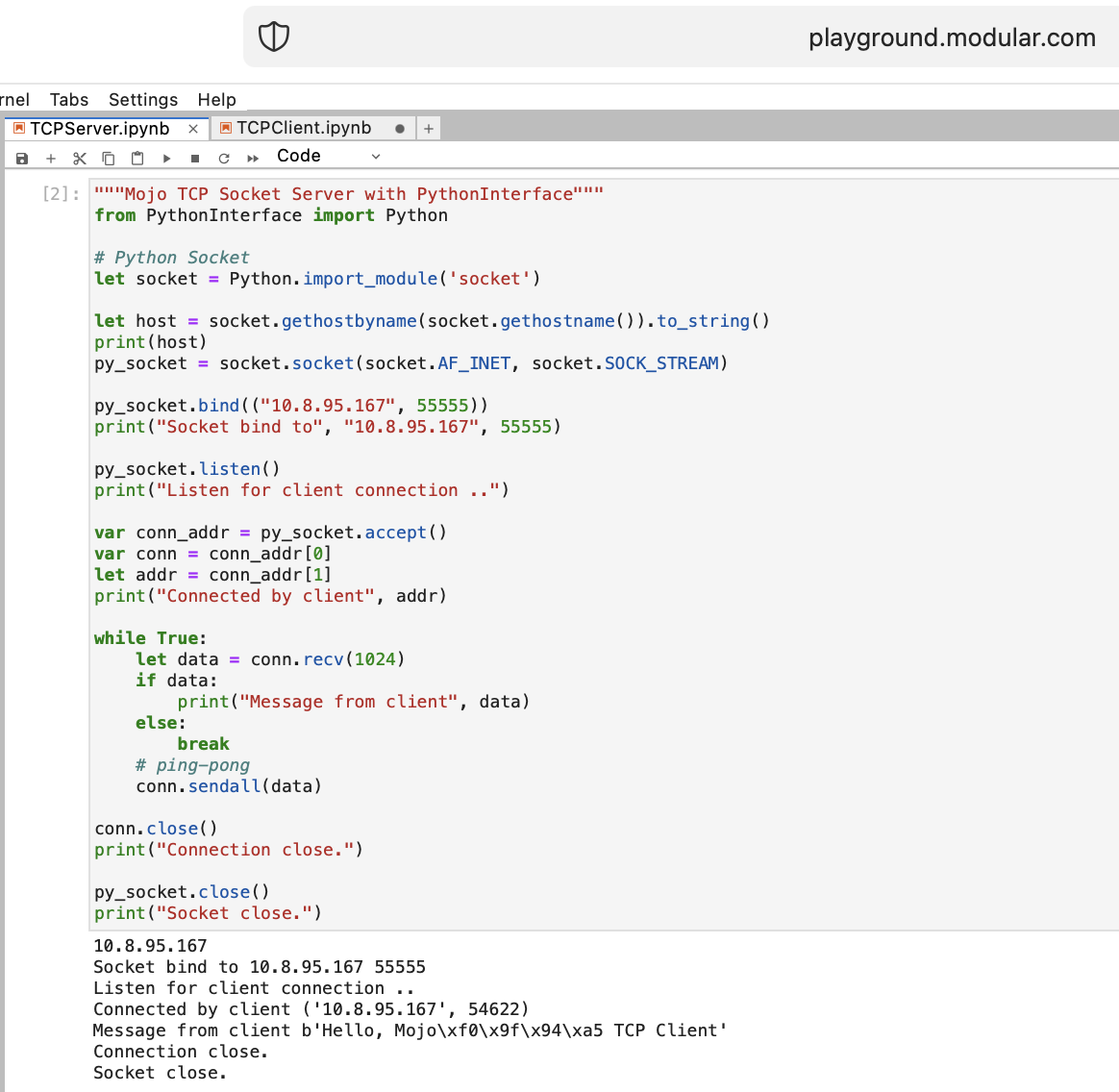
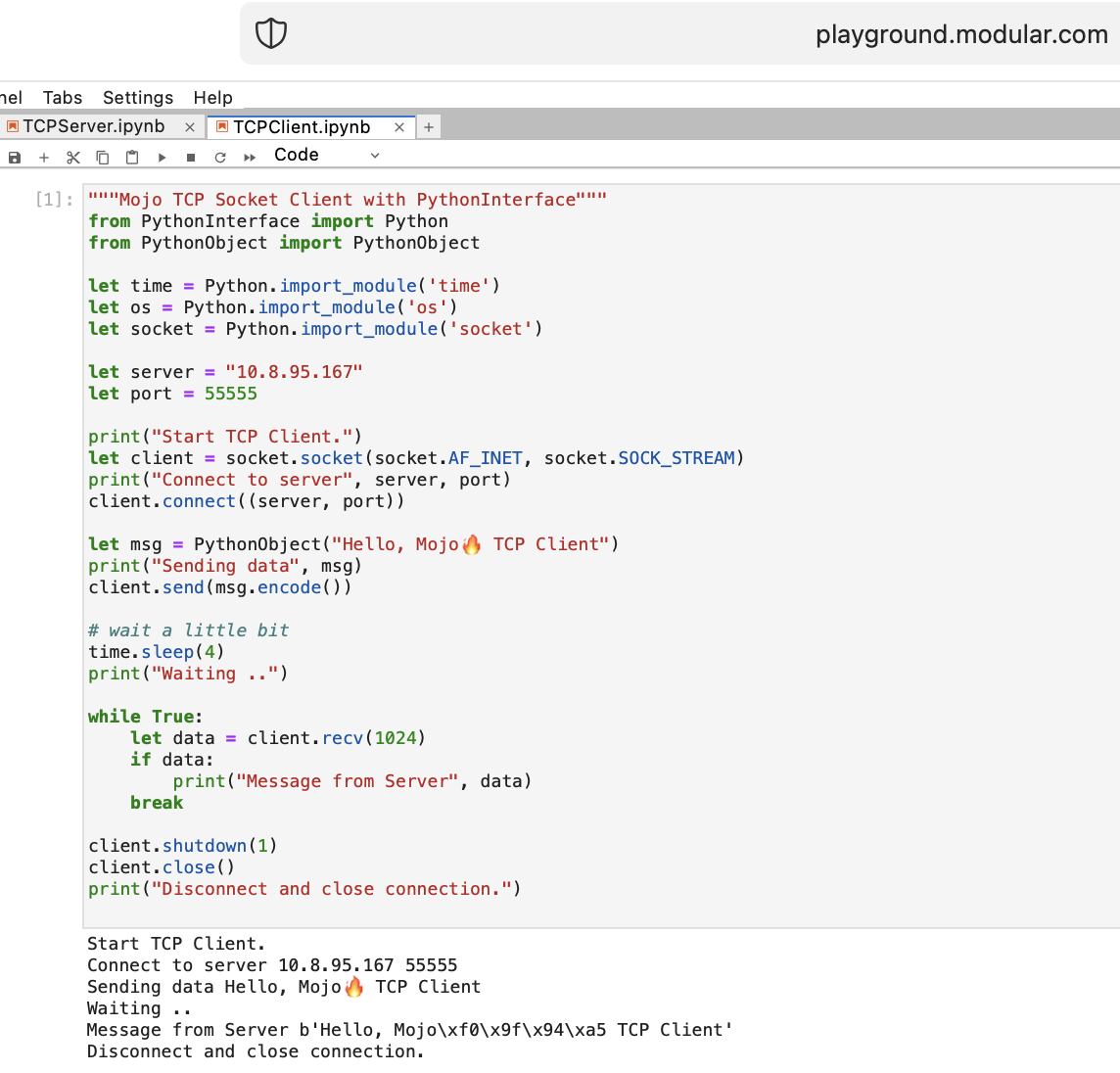
您應該建立兩個單獨的筆記本,並首先執行TCPSocketServer然後執行TCPSocketClient 。
此程式碼的Python 版本幾乎相同,除了:
with文法let分配a, b = (1, 2)這樣的解構在 Mojo 中的 TCP 伺服器之後我們將繼續前進 =)
這很瘋狂,但讓我們嘗試使用 Mojo 運行現代 Python Web 伺服器 FastAPI!
我們需要將 FastAPI 程式碼上傳到 Playground。所以,在你的本地機器上做
pip install --target=web fastapi uvicorn
tar -czPf web.tar.gz web並透過Web介面將web.tar.gz上傳到playground。
然後我們需要install它,只需放入適當的資料夾即可:
% % python
import os
import site
site_packages_path = site . getsitepackages ()[ 0 ]
# install fastapi
os . system ( f"tar xzf web.tar.gz -C { site_packages_path } " )
os . system ( f"cp -r { site_packages_path } /web/* { site_packages_path } /" )
os . system ( f"ls { site_packages_path } | grep fastapi" )
# clean packages
os . system ( f"rm -rf { site_packages_path } /web" )
os . system ( f"rm web.tar.gz" ) from PythonInterface import Python
# Python fastapi
let fastapi = Python . import_module ( "fastapi" )
let uvicorn = Python . import_module ( "uvicorn" )
var app = fastapi . FastAPI ()
var router = fastapi . APIRouter ()
# tricky part
let py = Python ()
let py_code = """lambda: 'Hello Mojo!'"""
let py_obj = py . evaluate ( py_code )
print ( py_obj )
router . add_api_route ( "/mojo" , py_obj )
app . include_router ( router )
print ( "Start FastAPI WEB Server" )
uvicorn . run ( app )
print ( "Done" ) from PythonInterface import Python
let http_client = Python . import_module ( "http.client" )
let conn = http_client . HTTPConnection ( "localhost" , 8000 )
conn . request ( "GET" , "/mojo" )
let response = conn . getresponse ()
print ( response . status , response . reason , response . read ())像往常一樣,您應該建立兩個單獨的筆記本,並先執行FastAPI ,然後執行FastAPIClient 。
有很多懸而未決的問題,但基本上我們實現了目標。
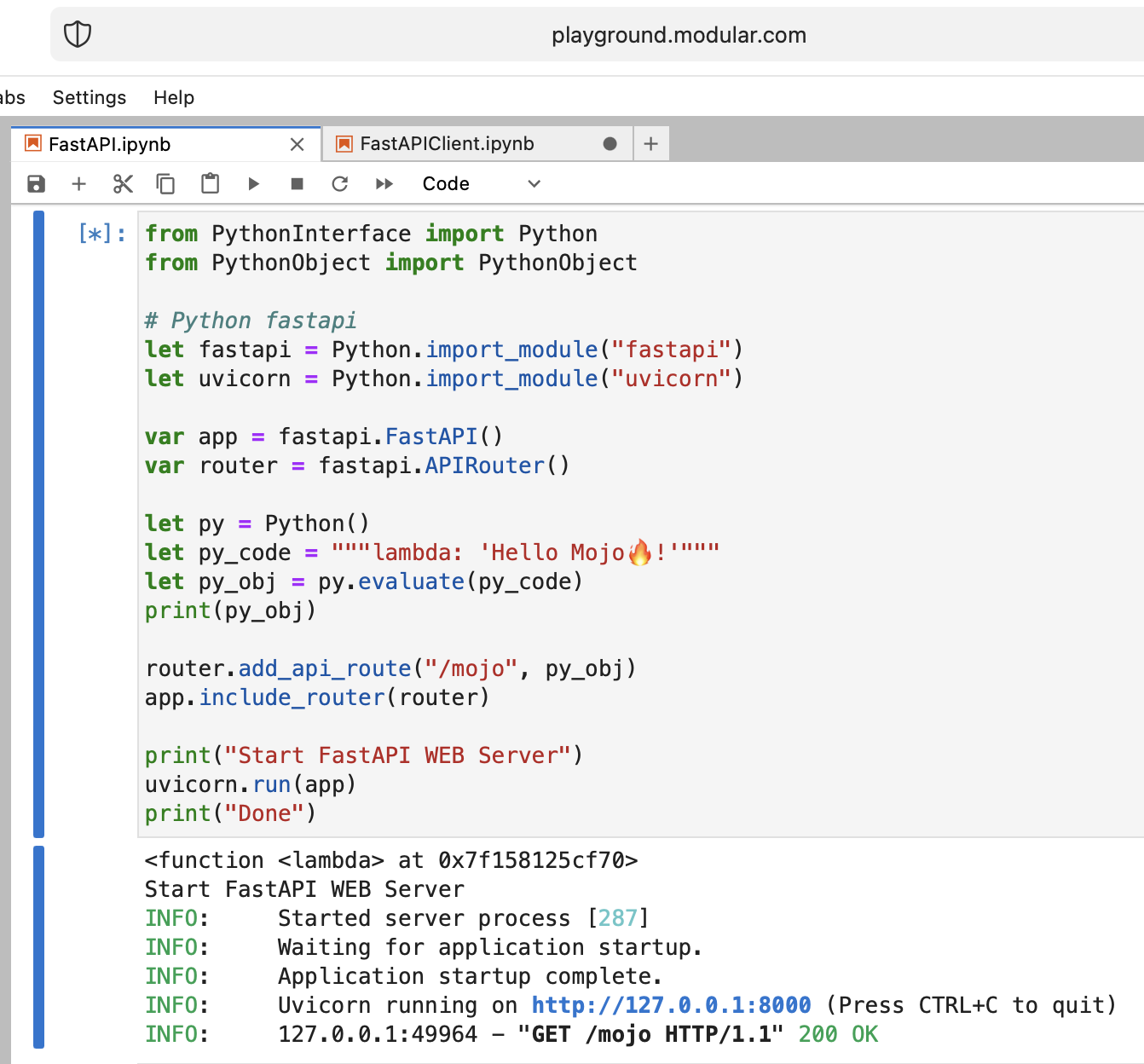
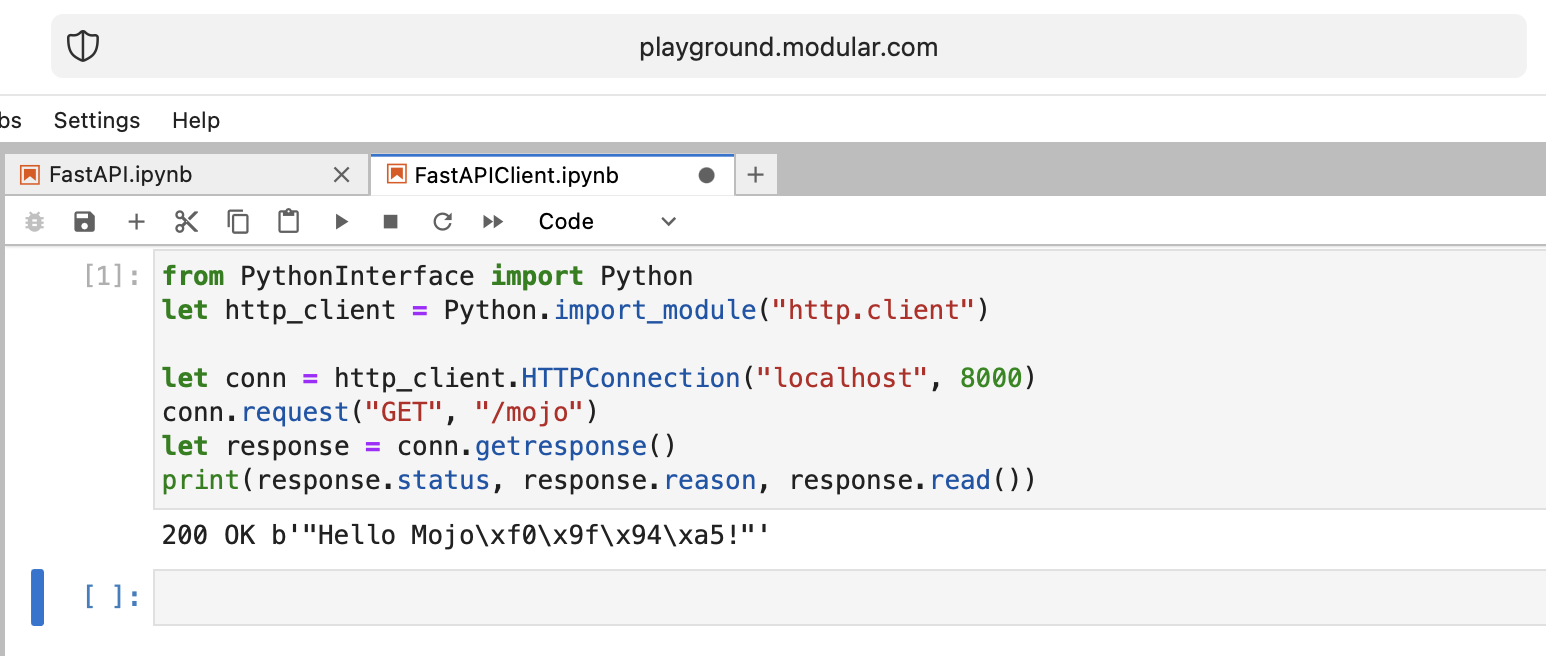
莫喬幹得好!
一些開放性問題:
from PythonInterface import Python
let pyfn = Python . evaluate ( "lambda x, y: x+y" )
let functools = Python . import_module ( "functools" )
print ( functools . reduce ( pyfn , [ 1 , 2 , 3 , 4 ]))
# How to, without Mojo pyfn.so?
def pyfn ( x , y ):
retyrn x + y未來看起來非常樂觀!
連結:
Nick Wogan 的基準 Mojo 與 Numba
時間實用程式 Samay Kapadia @Zalando
從 VSCode 或 DataSpell 連線到您的 mojo Playground
通過馬克西姆·扎克斯
from String import String
from PythonInterface import Python
let pathlib = Python . import_module ( 'pathlib' )
let txt = pathlib . Path ( 'nfl.csv' ). read_text ()
let s : String = txt . to_string ()libc 實作
from DType import DType
from Buffer import Buffer
from Pointer import Pointer
from String import String , chr
let hello = "hello"
let pointer = Pointer ( hello . data ())
print ( "variant 1" )
var result = String ()
for i in range ( len ( hello )):
result += chr ( pointer . bitcast [ Int8 ](). offset ( i ). load (). to_int ())
print ( result )
print ( "variant 2" )
print ( StringRef ( hello . data ()))
print ( "variant 3" )
print ( StringRef ( pointer . address ))
print ( "variant 4" )
let pm : Pointer [ __mlir_type . `!pop.scalar<si8>` ] = Pointer ( hello . data ())
print ( StringRef ( pm . address ))
print ( "variant 5" )
print ( String ( pointer . address ))
print ( "variant 6" )
let x = Buffer [ 8 , DType . int8 ]( pointer )
let array = x . simd_load [ 10 ]( 0 )
var result = String ()
for i in range ( len ( array )):
result += chr ( array [ i ]. to_int ())
print ( result )right click資源管理器中的文件,然後按Open With > Editorselect all並copy.ipynbGithub 正確地呈現了它,然後如果有人想在他們的 Playground 中嘗試程式碼,他們可以複製貼上原始程式碼。
這是我個人的觀點,所以不要太嚴厲地評價我。
我不能說 Mojo 是一種易於學習的程式語言,就像 Python 一樣。
它需要對任何其他程式語言有大量的理解、耐心和經驗。
如果你想建造一些不平凡的東西,那會很困難但很有趣!
距離我踏上這段旅程已經兩週了,我很高興地告訴大家,我現在已經熟悉了Mojo。
它錯綜複雜的結構和文法已經開始在我眼前解開,我充滿了新的理解。
我很自豪地說,我現在可以自信地用這種語言編寫程式碼,使我能夠將各種各樣的想法變成現實。
Mojo 是一種 Modular Inc 程式語言。為什麼我們在這裡討論Mojo 。關於這家公司我們了解較少,但它有一個很酷的名字Modular ,可以參考:
“換句話說:Mojo 不是魔法,它是模組化的。”
關於計算、程式設計、AI/ML 的所有內容。一個非常好的域名,準確地描述了公司的含義。
還有一些關於 Modular 品牌故事和透過品牌幫助 Modular 實現 AI 人性化的附加資料
今天想講一個關於Python Enum 問題的故事。作為軟體工程師我們經常在WEB中遇到它。假設我們有這個資料庫模式(PostgreSQL),狀態enum :
CREATE TYPE public .status_type AS ENUM (
' FIRST ' ,
' SECOND '
);在 Python 程式碼中,我們需要字串形式的名稱和值(假設我們在前端使用具有某種 ENUM 類型的 GraphQL),並且我們需要維護它們的順序並能夠比較這些枚舉:
order2.status > order1.status > 'FIRST'
所以這對大多數常見語言來說都是一個問題 =) 但我們可以使用一個little-known Python 功能並覆寫枚舉類別方法: __new__ 。
MALE -> 1 , FEMALE -> 2 ,就像 PostgreSQL 那樣。len函數計算其成員即可! import enum
from functools import total_ordering
@ total_ordering
@ enum . unique
class BaseUniqueSortedEnum ( enum . Enum ):
"""Base unique enum class with ordering."""
def __new__ ( cls , * args , ** kwargs ):
obj = object . __new__ ( cls )
obj . index = len ( cls . __members__ ) + 1 # This code line is a piece of advice, an insight and a tip!
return obj
# and then boring Python's magic methods as usual...
def __hash__ ( self ) -> int :
return hash (
f" { self . __module__ } _ { self . __class__ . __name__ } _ { self . name } _ { self . value } "
)
def __eq__ ( self , other ) -> bool :
self . _check_type ( other )
return super (). __eq__ ( other )
def __lt__ ( self , other ) -> bool :
self . _check_type ( other )
return self . index < other . index
def _check_type ( self , other ) -> None :
if type ( self ) != type ( other ):
raise TypeError ( f"Different types of Enum: { self } != { other } " )
class Dog ( BaseUniqueSortedEnum ):
# THIS ORDER MATTERS!
BLOODHOUND = "BLOODHOUND"
WEIMARANER = "WEIMARANER"
SAME = "SAME"
class Cat ( BaseUniqueSortedEnum )
# THIS ORDER MATTERS!
BRITISH = "BRITISH"
SCOTTISH = "SCOTTISH"
SAME = "SAME"
# and some tests
assert Dog . BLOODHOUND < Dog . WEIMARANER
assert Dog . BLOODHOUND <= Dog . WEIMARANER
assert Dog . BLOODHOUND != Dog . WEIMARANER
assert Dog . BLOODHOUND == Dog . BLOODHOUND
assert Dog . WEIMARANER == Dog . WEIMARANER
assert Dog . WEIMARANER > Dog . BLOODHOUND
assert Dog . WEIMARANER >= Dog . BLOODHOUND
assert Cat . BRITISH < Cat . SCOTTISH
assert Cat . BRITISH <= Cat . SCOTTISH
assert Cat . BRITISH != Cat . SCOTTISH
assert Cat . BRITISH == Cat . BRITISH
assert Cat . SCOTTISH == Cat . SCOTTISH
assert Cat . SCOTTISH > Cat . BRITISH
assert Cat . SCOTTISH >= Cat . BRITISH
assert hash ( Dog . BLOODHOUND ) == hash ( Dog . BLOODHOUND )
assert hash ( Dog . WEIMARANER ) == hash ( Dog . WEIMARANER )
assert hash ( Dog . BLOODHOUND ) != hash ( Dog . WEIMARANER )
assert hash ( Dog . SAME ) != hash ( Cat . SAME )
# raise TypeError
Dog . SAME <= Cat . SAME
Dog . SAME < Cat . SAME
Dog . SAME > Cat . SAME
Dog . SAME >= Cat . SAME
Dog . SAME != Cat . SAME故事的結局。並使用這個Python ENUM見解來進行良好的編碼!


