q transformer
0.3.0
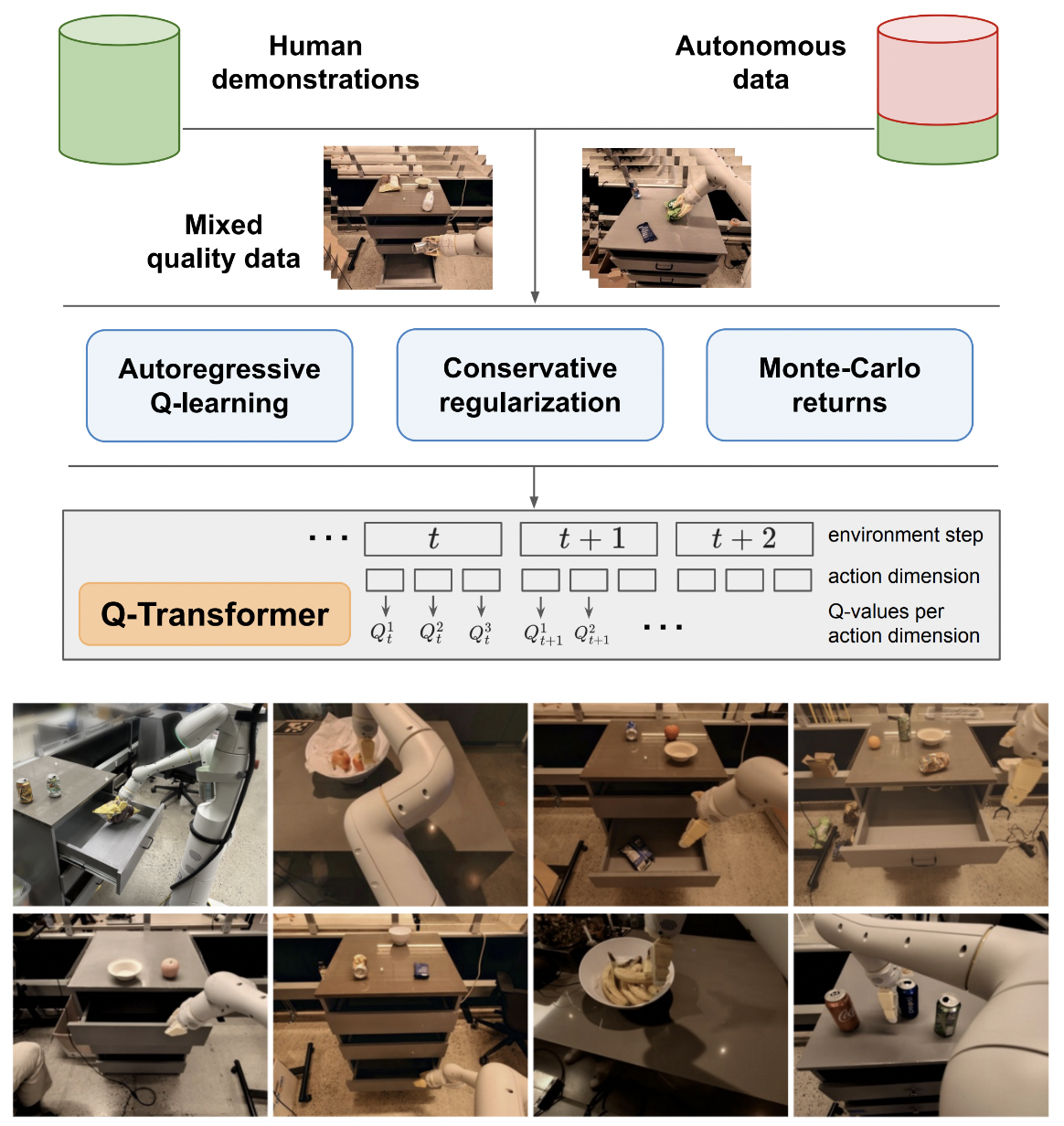
Q-Transformer 的實現,透過自回歸 Q-Functions 進行可擴展離線強化學習,來自 Google Deepmind
我將保留單一動作 Q 學習的邏輯,只是為了與提議的多個動作自回歸 Q 學習進行最終比較。也作為對我自己和公眾的教育。
Kotb 等人複製了自迴歸 Q 學習公式。
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )實現單一行動支援的第一個工作方式
提供 maxvit 的無批量規範變體,如 SOTA 天氣模型 metnet3 中所做的那樣
添加可選的深度決鬥架構
加入n步Q學習
建立保守正規化
在論文中建立主要提案(自回歸離散動作直到最後一個動作,僅在最後給出獎勵)
即興設計解碼器頭變體,而不是在幀+學習令牌階段連接先前的動作。換句話說,使用經典的編碼器-解碼器
重做 maxvit,使用軸向旋轉嵌入 + s 形門控,無需關注任何內容。透過此變更啟用 maxvit 的 flash 注意
建立一個簡單的資料集建立器類,取得環境和模型並傳回ReplayDataset可以接受的資料夾
ReplayDataset 正確處理多條指令
顯示一個簡單的端對端範例,其樣式與所有其他儲存庫相同
不處理任何指令,利用 CFG 函式庫中的 null 調節器
用於動作解碼的快取 kv
為了進行探索,允許精細隨機化操作的子集,而不是同時隨機化所有操作
諮詢一些密集學習專家,看看在解決妄想偏見方面是否有新的進展
弄清楚是否可以使用隨機的動作順序進行訓練 - 順序可以作為在註意層之前連接或求和的條件發送
簡單的波束搜尋功能可實現最佳操作
即興交叉關注過去的動作和時間步狀態,transformer-xl 時尚(帶結構化記憶丟失)
看看本文的主要想法是否適用於這裡的語言模型
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

