perfusion pytorch
0.1.23
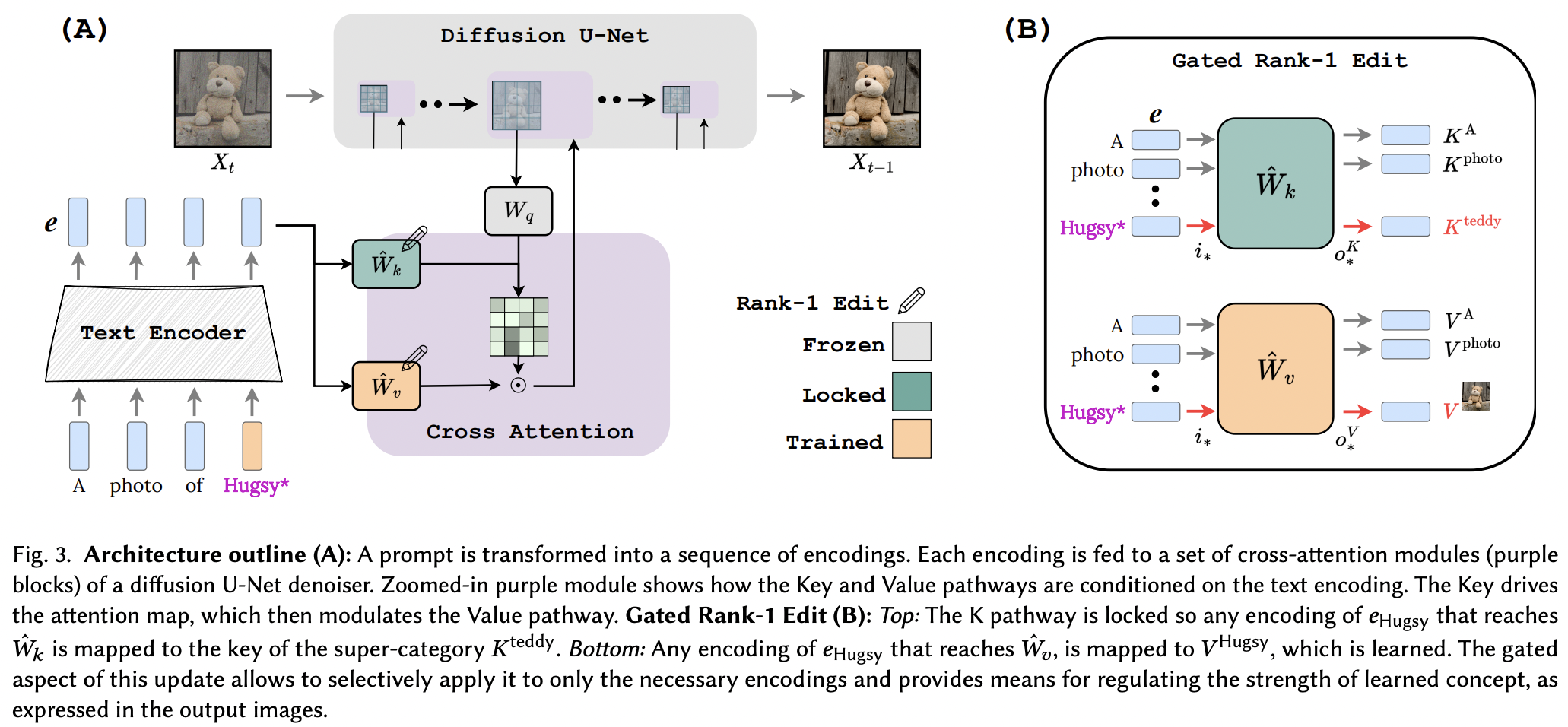
鎖鍵一級編輯的實作。專案頁面
本文的賣點是每個新增概念的額外參數極低,低至 100kb。
他們似乎成功地應用了 LLM 記憶編輯論文中的 Rank-1 編輯技術,並進行了一些改進。他們還發現鍵決定新概念的“位置”,而值決定“什麼”,並提出將本地/全局鍵鎖定到超類別概念(同時學習值)。
對於那裡的研究人員來說,如果這篇論文通過,這個存儲庫中的工具應該適用於任何其他使用交叉注意調節的文本到<insert modality>網絡。只是一個想法
StabilityAI 以及我的其他贊助商的慷慨贊助
Yoad Tewel 負責多次程式碼審查和澄清電子郵件
Brad Vidler 預先計算穩定擴散 1.5 中使用的 CLIP 的協方差矩陣!
OpenClip 的所有維護者,感謝他們的 SOTA 開源對比學習文字圖像模型
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc )該儲存庫還包含一個EmbeddingWrapper ,可以輕鬆訓練新概念(並最終對多個概念進行推理)
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask如果您可以識別穩定擴散實例中的CLIP實例,您也可以將其直接傳遞到OpenClipEmbedWrapper以獲得交叉注意層向前所需的一切
前任。
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) 連接 SD 1.5,從 xiao's dreambooth-sd 開始
在自述文件中顯示範例以進行多個概念的推理
如果未為make_key_value_proj_rank1_edit_modules_函數指定,則自動推斷鍵和值投影的位置
嵌入包裝器應注意用超類別令牌 id 進行替換並傳回超類別嵌入
回顧多個概念 - 感謝 Yoad
提供連結交叉注意力的功能
在推理時在一個提示中處理多個概念 - sigmoid 項 + 輸出的求和
提供一種將多個Rank1EditModule中單獨學習的概念組合成一個以進行推理的方法
Rank1EditModule的功能加入論文中提出的概念的零樣本掩蔽
處理接收資料集和文字編碼器並預先計算 1 級更新所需的協方差矩陣的函數
不用讓研究人員擔心不同的學習率,而是提供其他論文中的分數梯度技巧(學習概念嵌入)
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

