rtdl revisiting models
1.0.0
重要的
查看新的表格 DL 模型:TabM
arXiv ? Python 套件其他表格 DL 項目
這是論文「Revisiting Deep Learning Models for Tabular Data」的正式實作。
一句話:類似 MLP 的模型仍然是很好的基線,而 FT-Transformer 是針對表格資料問題的 Transformer 架構的一種新的強大改編。
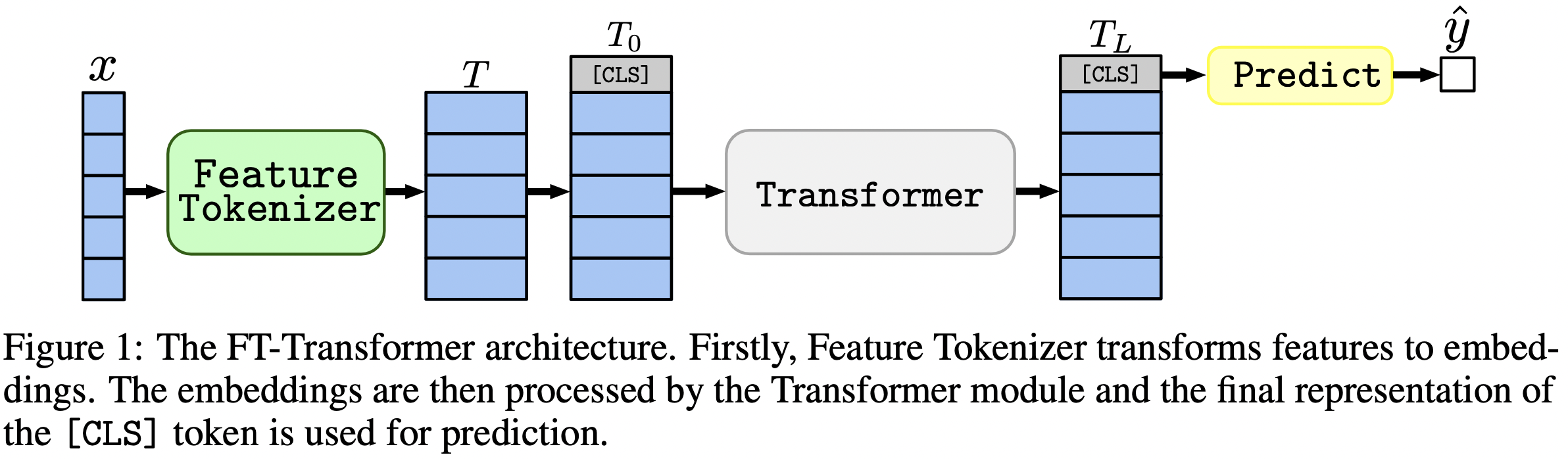
本文重點討論表格資料問題的架構。結果:
package/目錄中的 Python 套件是在實務和未來工作中使用本文的推薦方式。
文件的其餘部分:
output/目錄包含本文中使用的各種模型和資料集的大量結果和(調整的)超參數。
例如,讓我們探討一下 MLP 模型的指標。首先,讓我們載入報告( stats.json檔案):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])現在,對於每個資料集,我們計算所有隨機種子的平均測試分數:
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))輸出與論文中的表 2 完全吻合:
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
上述方法也可用於探索超參數,以直觀地了解不同演算法的典型超參數值。例如,以下是計算 MLP 模型的中位數調整學習率的方法:
筆記
對於某些演算法(例如 MLP),最近的項目提供了更多可以以類似方式探索的結果。例如,請參閱 TabR 上的這篇論文。
警告
請謹慎使用此方法。研究超參數值時:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536筆記
這一段很長。在文字編輯器中使用 GitHub 上的「大綱」功能來取得本節的概述。
程式碼組織如下:
bin :ensemble.py執行集成tune.py執行超參數調整analysis_gbdt_vs_nn.py運行實驗create_synthetic_data_plots.py建構繪圖lib包含bin中程式使用的常用工具output包含設定檔( bin中程式的輸入)和結果(指標、調整配置等)package包含本文的Python套件安裝康達
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-models僅在嘗試 TabNet 時才需要此環境。對於所有其他情況,請使用 PyTorch 環境。
這些說明與 PyTorch 環境相同(包括 PyTorch 的安裝!),但:
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt之前執行以下操作:pip install tensorflow-gpu==1.14requirements.txt中的tensorboard許可證:透過下載我們的資料集,您接受其所有元件的許可證。除了這些許可證之外,我們不會施加任何新的限制。您可以在我們論文的“參考文獻”部分找到來源列表。
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz 本節僅提供具體指令,註解很少。完成本教學後,我們建議您查看下一部分,以便更好地了解如何使用儲存庫。它還將有助於更好地理解本教程。
在本教程中,我們將在加州住房資料集上重現 MLP 的結果。我們將涵蓋:
請注意,獲得完全相同結果的機會相當低,但是,它們應該與我們的結果相差不大。在運行任何內容之前,請前往儲存庫的根目錄並明確設定CUDA_VISIBLE_DEVICES (如果您打算使用 GPU):
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0在開始之前,我們先檢查一下環境是否配置成功。以下命令應在加州住房資料集上訓練一個 MLP:
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml結果應該位於目錄draft/check_environment中。目前,結果的內容並不重要。
我們在加州住房資料集上調整 MLP 的配置位於output/california_housing/mlp/tuning/0.toml 。為了重現調整,請複製我們的配置並執行您的調整:
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml您的調整結果將位於output/california_housing/mlp/tuning/reproduced ,您可以將其與我們的進行比較: output/california_housing/mlp/tuning/0 。文件best.toml包含我們將在下一節中評估的最佳配置。
現在我們必須使用 15 個不同的隨機種子來評估調整後的配置。
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done我們的評估結果目錄就位於您的目錄旁邊,即位於output/california_housing/mlp/tuned 。
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced您的結果將位於output/california_housing/mlp/tuned_reproduced_ensemble ,您可以將其與我們的結果進行比較: output/california_housing/mlp/tuned_ensemble 。
使用此處所述的方法總結所進行的實驗的結果(相應地修改.glob(...)中的路徑過濾器: tuned -> tuned_reproduced )。
可以對所有模型和資料集執行類似的步驟。網格搜尋的調整過程略有不同:您必須執行所有所需的配置,並根據驗證效能手動選擇最佳配置。例如,請參閱output/epsilon/ft_transformer 。
您應該從儲存庫的根目錄執行 Python 腳本。大多數程式都期望設定檔作為唯一的參數。輸出將是一個與配置同名的目錄,但沒有副檔名。配置是用 TOML 編寫的。未提供程序的可能參數列表,應從腳本中推斷出來(通常,配置用腳本中的args變數表示)。如果要使用 CUDA,則必須明確設定CUDA_VISIBLE_DEVICES環境變數。例如:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.toml如果你打算一直使用CUDA,可以將環境變數保存在Conda環境中:
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " -f ( --force ) 選項將刪除現有結果並從頭開始執行腳本:
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py支援延續:
python bin/tune.py path/to/config.toml --continuestats.json和其他結果對於所有腳本, stats.json是輸出中最重要的部分。內容因節目而異。它可以包含:
通常也會保存訓練集、驗證集和測試集的預測。
現在,您知道重現所有結果並擴展此存儲庫以滿足您的需求所需的一切。現在教學也應該更加清楚了。請隨意提出問題並提出問題。
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


