PALM E
0.0.4

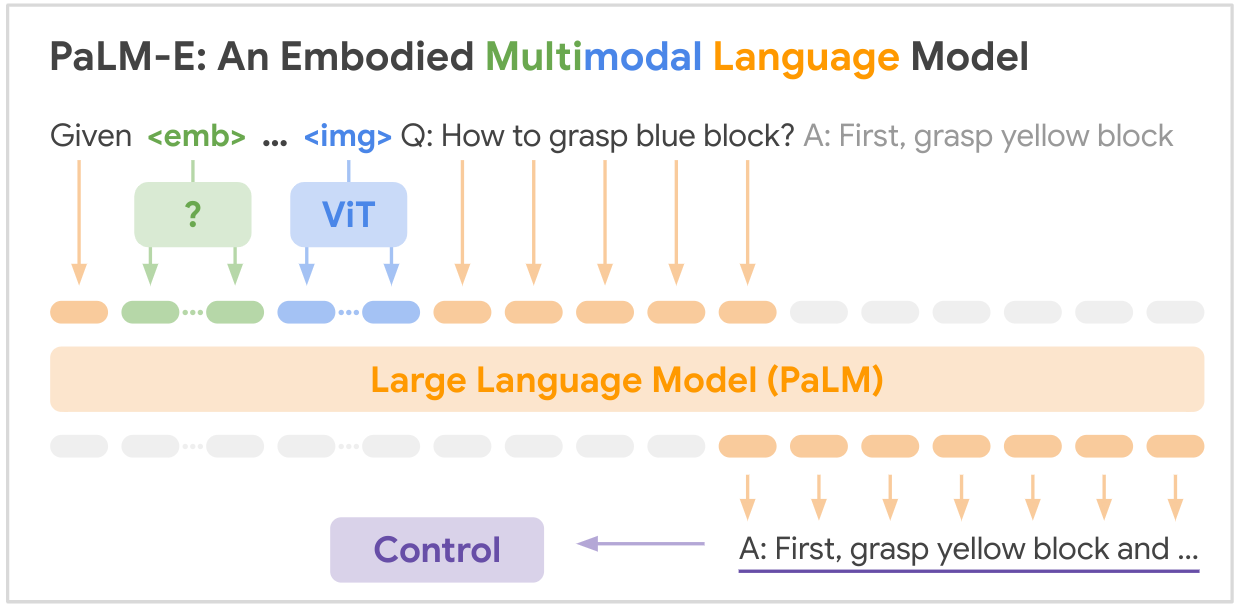
這是 Google 的 SOTA 多模態基礎模型「PALM-E:An Embodied Multimodal Language Model」的開源實現,PALM-E 是一個單一的大型體現多模態模型,可以解決各種體現推理任務,從在多個實施例上的各種觀察模式,並且進一步表現出正遷移:該模型受益於跨互聯網規模語言、視覺和視覺語言領域的多樣化聯合訓練。
論文連結:PaLM-E:一種體現的多模態語言模型
pip install palme import torch
from palme . model import PalmE
#usage
img = torch . randn ( 1 , 3 , 256 , 256 )
caption = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
model = PalmE ()
output = model ( img , caption )
print ( output . shape ) # (1, 1024, 20000)
以下是論文中提到的關鍵資料集的總結表:
| 數據集 | 任務 | 尺寸 | 關聯 |
|---|---|---|---|
| 夯 | 機器人操縱規劃,VQA | 96,000 個場景 | 自訂資料集 |
| 語言表 | 機器人操縱規劃 | 自訂資料集 | 關聯 |
| 移動操控 | 機器人導航與操縱規劃,VQA | 2912 序列 | 基於 SayCan 資料集 |
| 網路LI | 圖文檢索 | 66M 圖像標題對 | 關聯 |
| VQAv2 | 視覺問答 | 關於 COCO 影像的 110 萬個問題 | 關聯 |
| OK-VQA | 需要外在知識的視覺問答 | 關於 COCO 影像的 14,031 個問題 | 關聯 |
| 可可 | 圖片字幕 | 330K 帶字幕的圖像 | 關聯 |
| 維基百科 | 文字語料庫 | 不適用 | 關聯 |
關鍵的機器人資料集是專門為這項工作收集的,而更大的視覺語言資料集(WebLI、VQAv2、OK-VQA、COCO)是該領域的標準基準。資料集範圍從機器人領域的數萬個範例到網路規模視覺語言資料的數千萬個。
需要你的才華!加入我們,讓我們一起讓 PALM-E 更令人驚嘆:
?修復,?增強功能、文件或想法 – 歡迎所有人!讓我們攜手共創人工智慧的未來。
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

