meshgpt pytorch
1.8.1
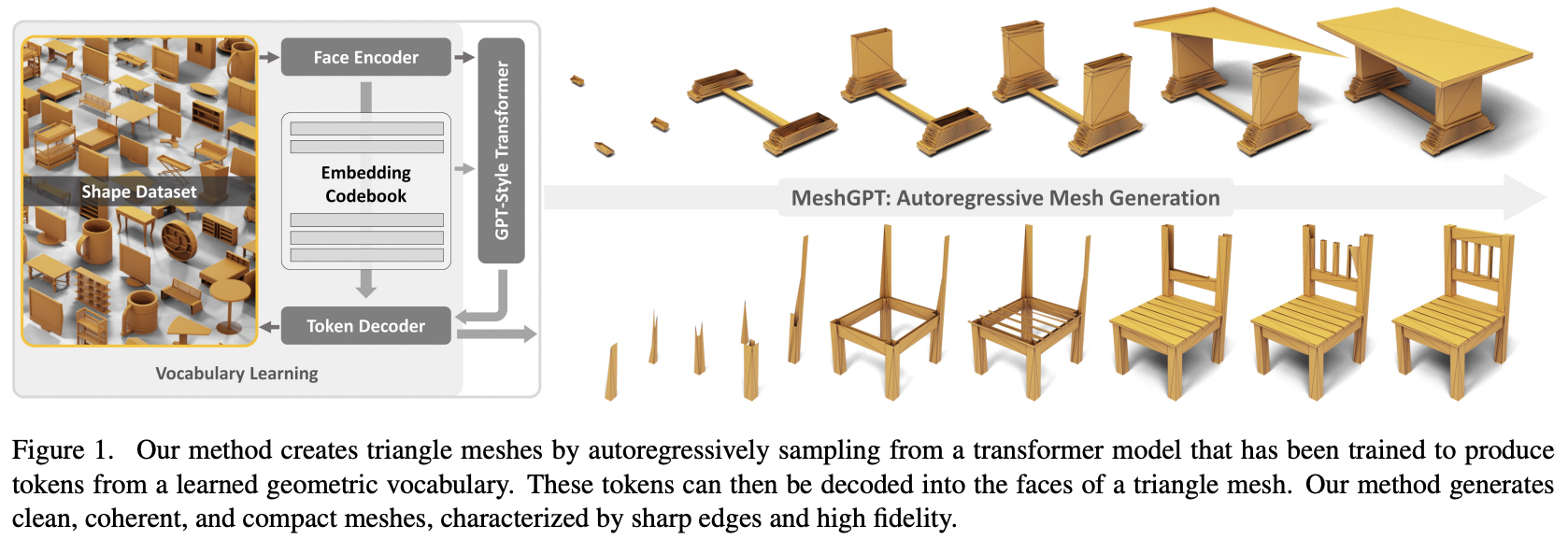
在 Pytorch 中使用 Attention 實作 MeshGPT、SOTA 網格生成
還將添加文字調節,以實現最終的文本轉 3D 資源
如果您有興趣與其他人合作複製這項工作,請加入
更新:馬庫斯已經訓練了一個工作模型並將其上傳到?抱臉!
StabilityAI、A16Z 開源 AI 資助計劃,以及?感謝慷慨的贊助,以及我的其他贊助商,為我提供了開源當前人工智慧研究的獨立性
Einops 讓我的生活變得輕鬆
Marcus 負責初始程式碼審查(指出一些缺失的派生功能)以及運行第一個成功的端到端實驗
馬庫斯首次成功訓練了以標籤為條件的一組形狀
Quexi Ma 透過自動 eos 處理發現了大量錯誤
Yingtian 發現空間標籤平滑位置高斯模糊的錯誤
馬庫斯再次運行實驗來驗證可以將系統從三角形擴展到四邊形
馬庫斯(Marcus)發現了文字調節問題並進行了所有導致該問題解決的實驗
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d asset對於文字條件 3D 形狀合成,只需在MeshTransformer上設定condition_on_text = True ,然後將描述清單作為texts關鍵字參數傳遞
前任。
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
)如果您想要對網格進行標記,以便在多模態轉換器中使用,只需在自動編碼器上調用.tokenize (或在自動編碼器訓練器實例上調用指數平滑模型的相同方法)
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) 在專案根目錄下,執行
$ cp .env.sample .env自動編碼器
face_edges 變壓器
具有高頻加速功能的訓練器包裝器
使用自己的 CFG 庫進行文字調節
分層變壓器(使用 RQ 變壓器)
修復其他儲存庫中簡單門環層中的緩存
當地關注
修復兩層分層變壓器的 kv 快取 - 現在快 7 倍,比原始非分層變壓器更快
修復門環層的緩存
允許客製化精細與粗略注意力網路的模型維度
弄清楚自動編碼器是否真的有必要 - 有必要,論文中有消融
提高變壓器效率
推測解碼選項
花一天時間研究文檔
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

