block recurrent transformer pytorch
0.4.4
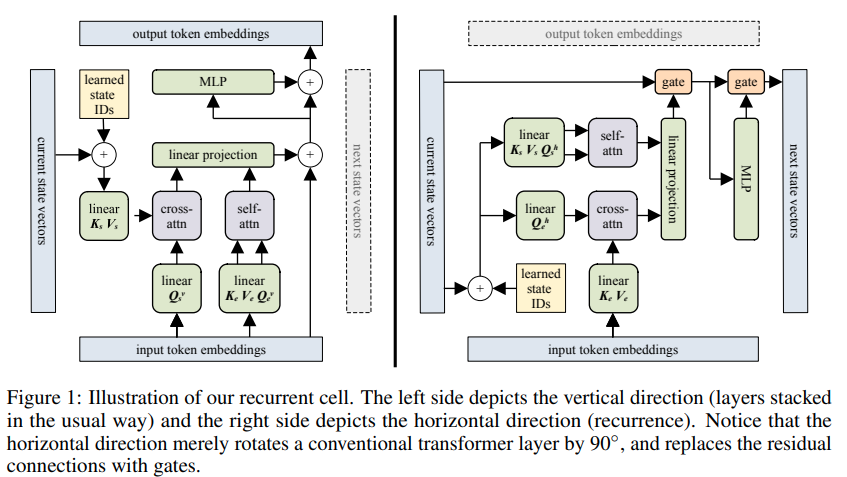
塊循環變壓器的實作 - Pytorch。這篇論文的亮點在於它能夠記住多達 60k 個標記之前的內容。
該設計是針對循環變壓器研究線的 SOTA。
它還將包括 Flash Attention 以及使用本文中的想法的多達 250k 令牌的路由記憶
$ pip install block-recurrent-transformer-pytorch import torch
from block_recurrent_transformer_pytorch import BlockRecurrentTransformer
model = BlockRecurrentTransformer (
num_tokens = 20000 , # vocab size
dim = 512 , # model dimensions
depth = 6 , # depth
dim_head = 64 , # attention head dimensions
heads = 8 , # number of attention heads
max_seq_len = 1024 , # the total receptive field of the transformer, in the paper this was 2 * block size
block_width = 512 , # block size - total receptive field is max_seq_len, 2 * block size in paper. the block furthest forwards becomes the new cached xl memories, which is a block size of 1 (please open an issue if i am wrong)
num_state_vectors = 512 , # number of state vectors, i believe this was a single block size in the paper, but can be any amount
recurrent_layers = ( 4 ,), # where to place the recurrent layer(s) for states with fixed simple gating
use_compressed_mem = False , # whether to use compressed memories of a single block width, from https://arxiv.org/abs/1911.05507
compressed_mem_factor = 4 , # compression factor of compressed memories
use_flash_attn = True # use flash attention, if on pytorch 2.0
)
seq = torch . randint ( 0 , 2000 , ( 1 , 1024 ))
out , mems1 , states1 = model ( seq )
out , mems2 , states2 = model ( seq , xl_memories = mems1 , states = states1 )
out , mems3 , states3 = model ( seq , xl_memories = mems2 , states = states2 )首先pip install -r requirements.txt ,然後
$ python train.py使用動態位置偏差
添加增強復發
設定局部注意力塊,如論文所示
用於培訓的包裝變壓器類
在RecurrentTrainWrapper中處理循環生成
在訓練期間的每個分段步驟中加入刪除整個記憶和狀態的能力
在 enwik8 上本地測試整個系統並消除狀態和記憶並直接查看效果
確保注意也允許單頭鍵/值
在常規變壓器中進行一些固定門控實驗 - 不起作用
整合閃光注意力
快取注意力掩碼+旋轉嵌入
加入壓縮記憶
重溫記憶形成者
嘗試使用坐標下降路由長達 250k 的長距離記憶體(Wright 等人)
@article { Hutchins2022BlockRecurrentT ,
title = { Block-Recurrent Transformers } ,
author = { DeLesley S. Hutchins and Imanol Schlag and Yuhuai Wu and Ethan Dyer and Behnam Neyshabur } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2203.07852 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Ainslie2023CoLT5FL ,
title = { CoLT5: Faster Long-Range Transformers with Conditional Computation } ,
author = { Joshua Ainslie and Tao Lei and Michiel de Jong and Santiago Ontan'on and Siddhartha Brahma and Yury Zemlyanskiy and David Uthus and Mandy Guo and James Lee-Thorp and Yi Tay and Yun-Hsuan Sung and Sumit Sanghai } ,
year = { 2023 }
}記憶是時間中的注意力——亞歷克斯·格雷夫斯


