algebraic nnhw
1.0.0
該儲存庫包含ML 硬體架構的源代碼,該架構需要近一半數量的乘法器單元才能實現相同的性能,透過執行替代內積演算法,將近一半的乘法換成廉價的低位寬加法,同時仍然產生相同的輸出作為常規內積。這增加了機器學習加速器的理論吞吐量和運算效率限制。有關完整詳細信息,請參閱以下期刊出版物:
TE Pogue 和 N. Nicolici,“深度神經網路加速器的快速內積演算法和架構”,載於 IEEE 計算機學報,卷。 73、沒有。 2,第 495-509 頁,2024 年 2 月,doi:10.1109/TC.2023.3334140。
文章網址:https://ieeexplore.ieee.org/document/10323219
開放取用版本:https://arxiv.org/abs/2311.12224
摘要:我們介紹了一種稱為自由管道快速內積 (FFIP) 的新演算法及其硬體架構,該演算法改進了 Winograd 於 1968 年提出的尚未探索的快速內積演算法 (FIP)。 FIP 適用於所有主要可分解為矩陣乘法的機器學習(ML) 模型層,包括全連接層、卷積層、循環層和注意力/變換器層。我們首次在 ML 加速器中實作 FIP,然後介紹我們的 FFIP 演算法和通用架構,這些演算法和通用架構本質上提高了 FIP 的時脈頻率,從而提高了類似硬體成本的吞吐量。最後,我們為 FIP 和 FFIP 演算法和架構提供特定於 ML 的最佳化。我們證明,FFIP 可以無縫整合到傳統定點脈動陣列ML 加速器中,以一半數量的乘法累加(MAC) 單元實現相同的吞吐量,或者它可以將最大脈動陣列尺寸加倍,以適應具有以下功能的設備:固定的硬體預算。我們針對具有 8 至 16 位元定點輸入的非稀疏 ML 模型的 FFIP 實現實現了比同類計算平台上同類最佳的現有解決方案更高的吞吐量和計算效率。
下圖顯示了此原始程式碼中實現的機器學習加速器系統的概述:
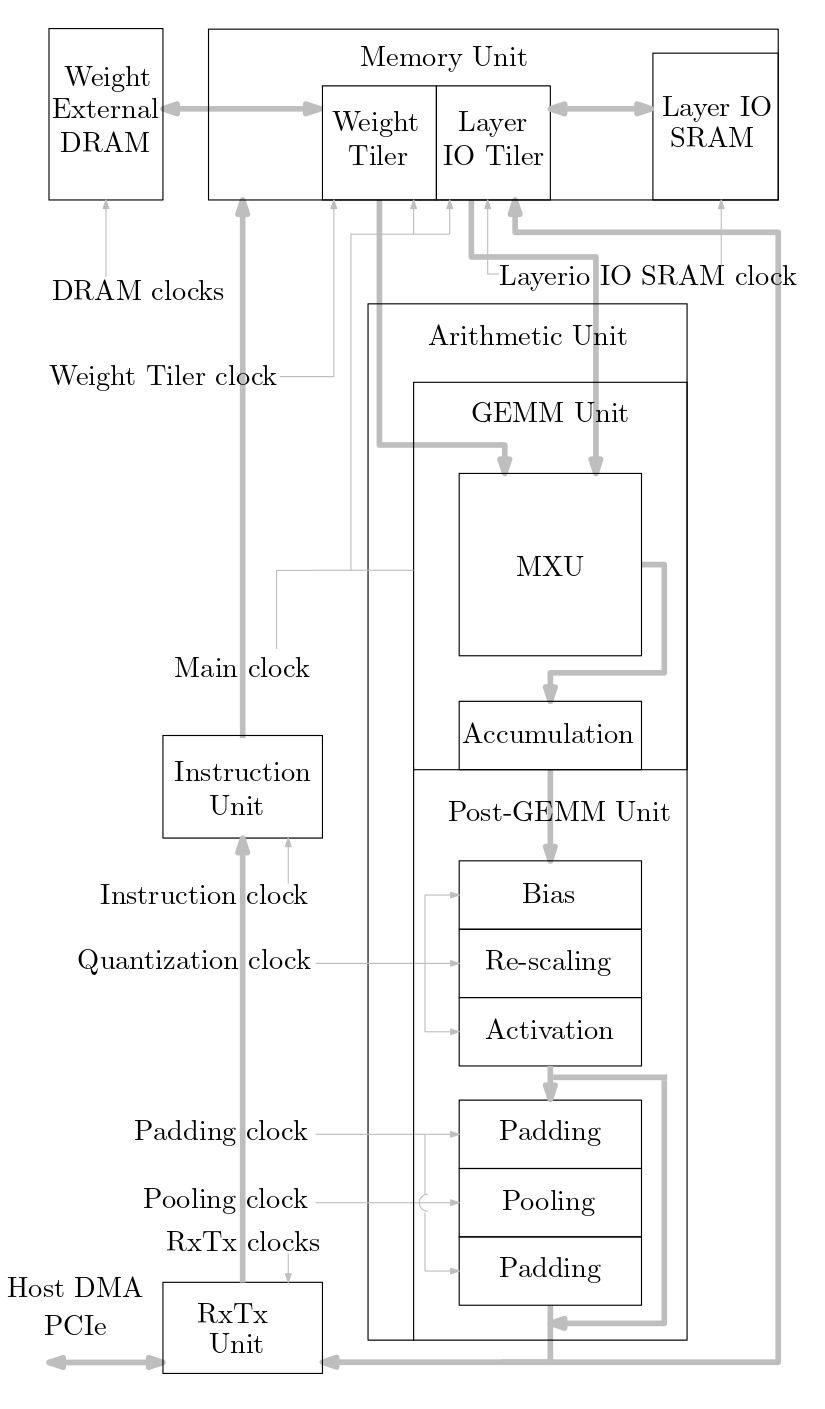
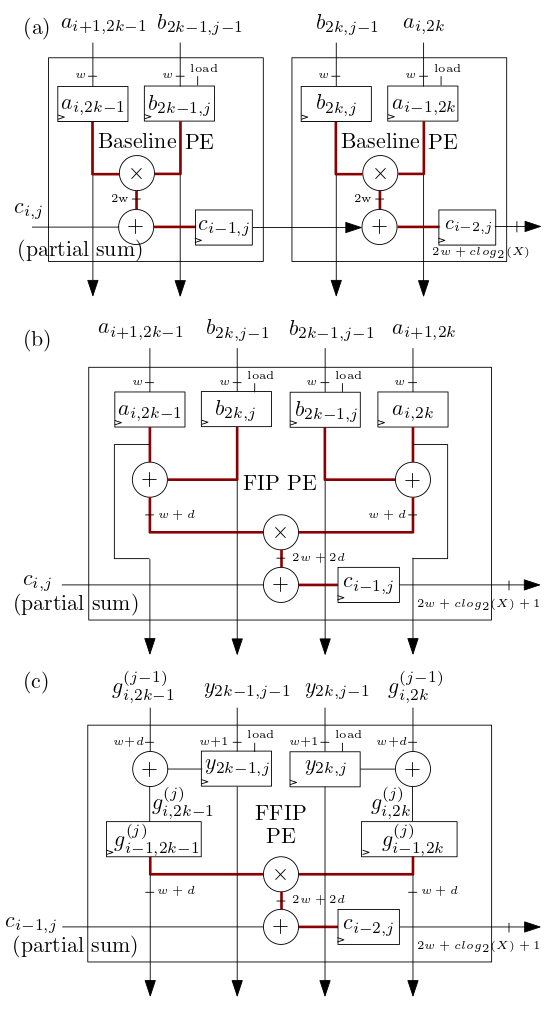
下面(b) 和(c) 所示的FIP 和FFIP 脈動陣列/MXU 處理元件(PE) 實作FIP 和FFIP 內積演算法,並且每個單獨提供與(b) 和(c) 所示的兩個基線PE 相同的有效運算能力。
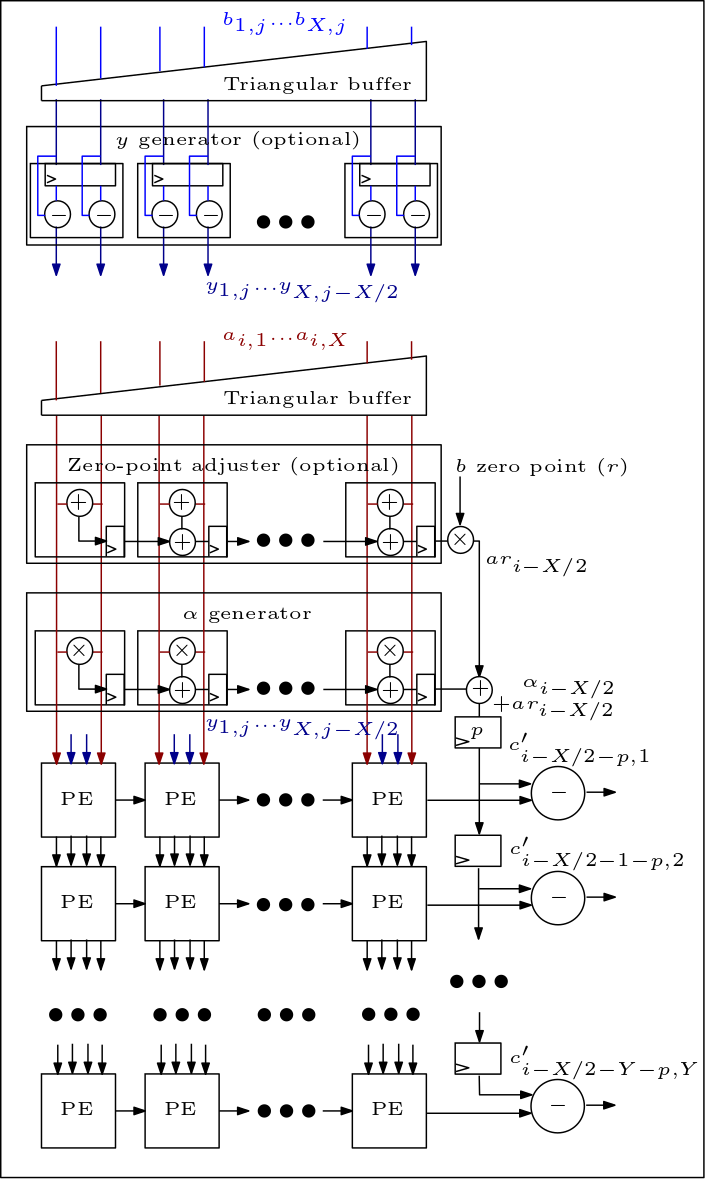
下圖是 MXU/脈動陣列的示意圖,顯示了 PE 的連接方式:
原始碼組織如下:
檔案 rtl/top/define.svh 和 rtl/top/pkg.sv 包含許多可設定參數,例如 Define.svh 中的 FIP_METHOD 定義脈動陣列類型(基線、FIP 或 FFIP),SZI 和 SZJ 定義脈動陣列高度/寬度,以及定義輸入位寬的LAYERIO_WIDTH/WEIGHT_WIDTH。
目錄 rtl/arith 包含 mxu.sv 和 mac_array.sv,其中包含基線、FIP 和 FFIP 脈動陣列架構的 RTL(取決於參數 FIP_METHOD 的值)。


