py spider for wechat
1.0.0
歡迎二次開發,提交PR ?
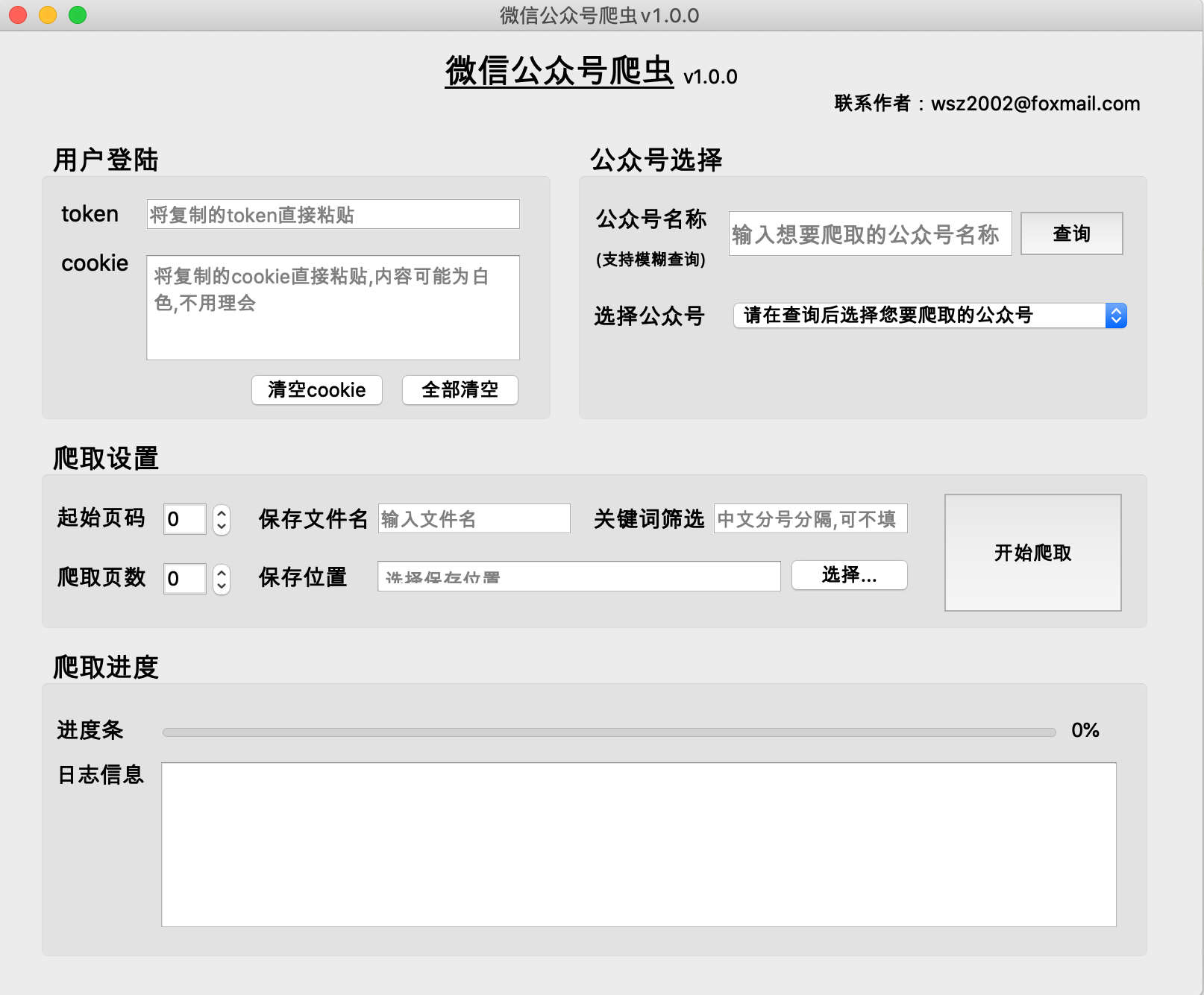
利用python建構爬蟲,爬取指定公眾號歷史文章及內容,同時支持利用關鍵字篩選文章。
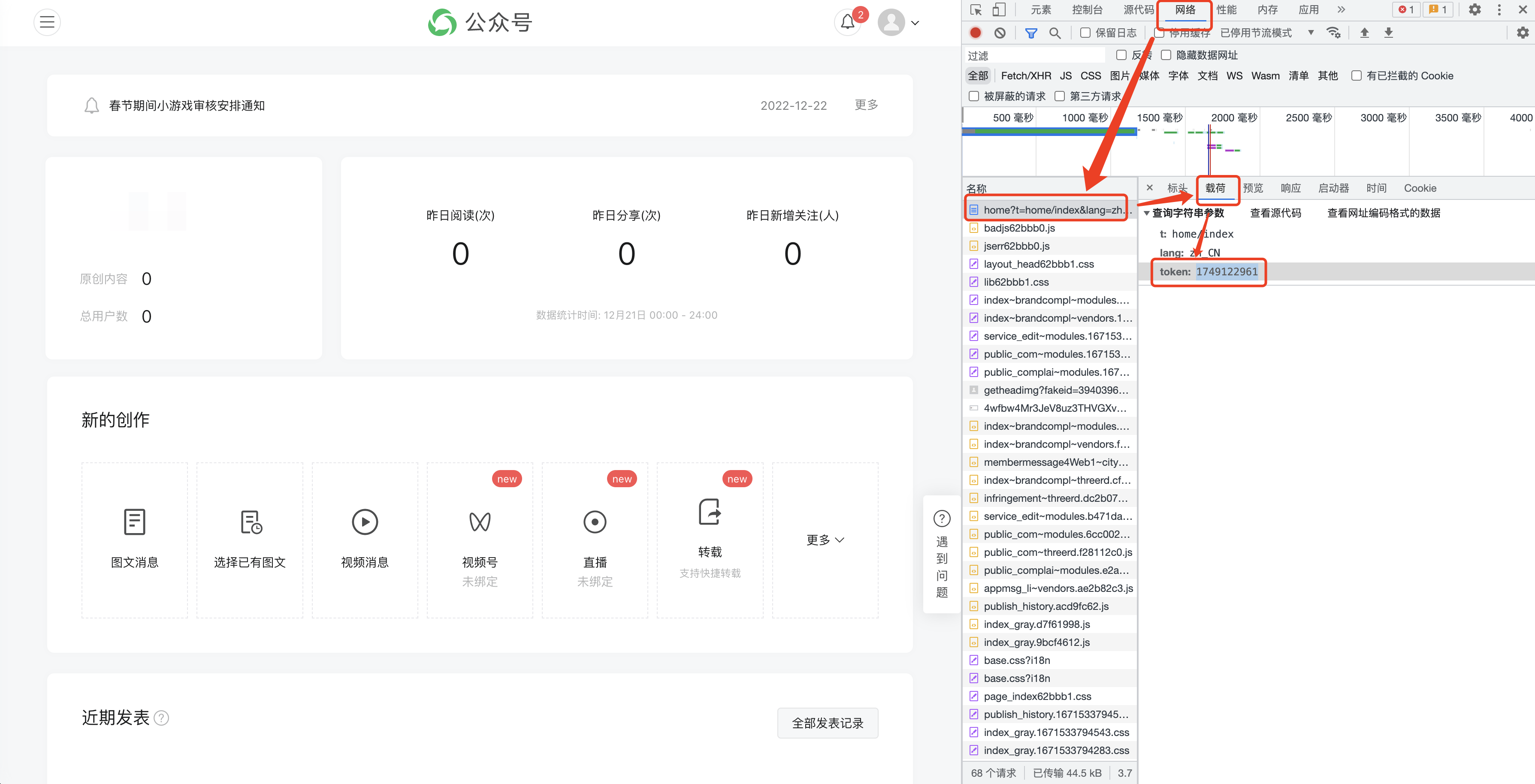
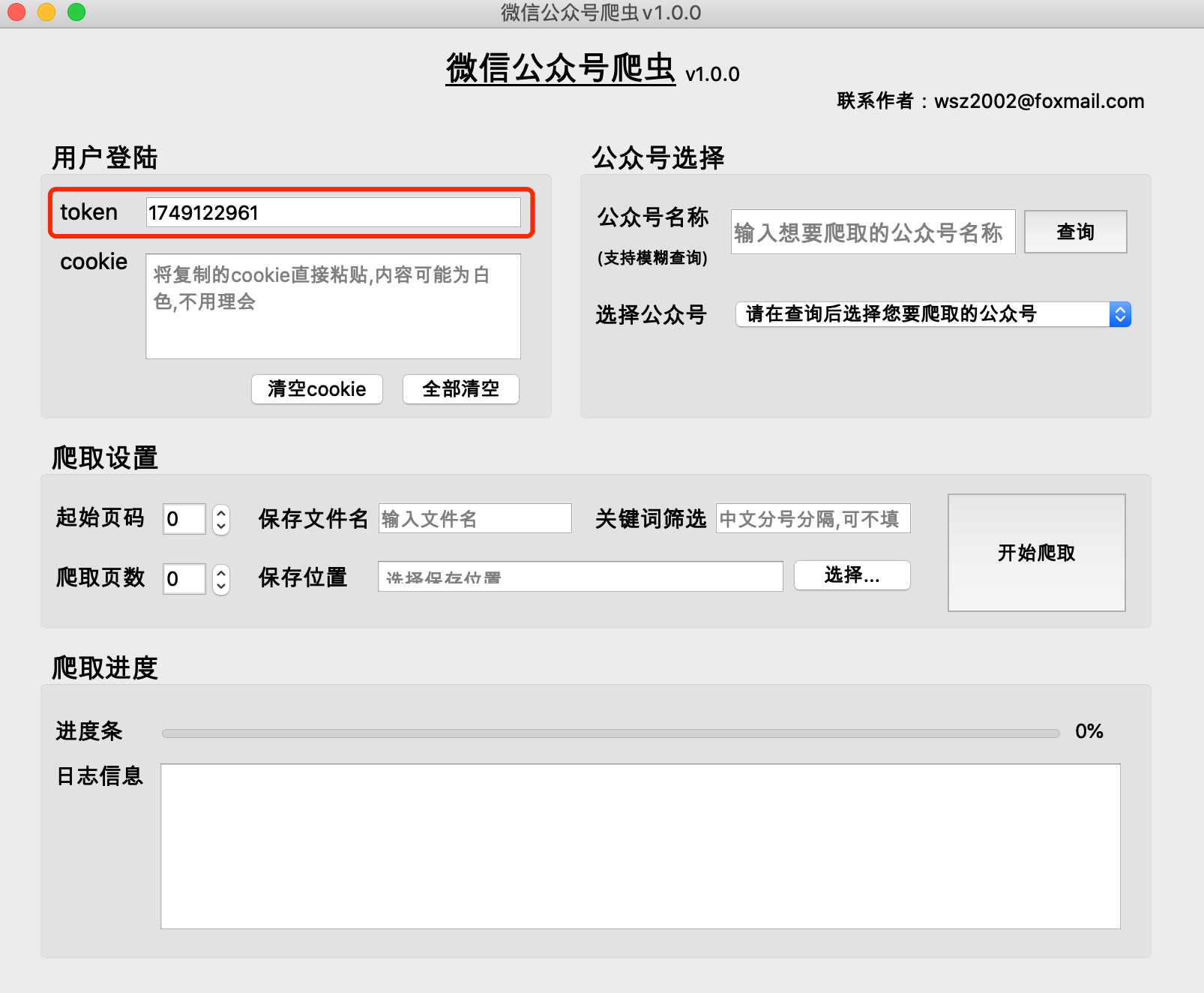
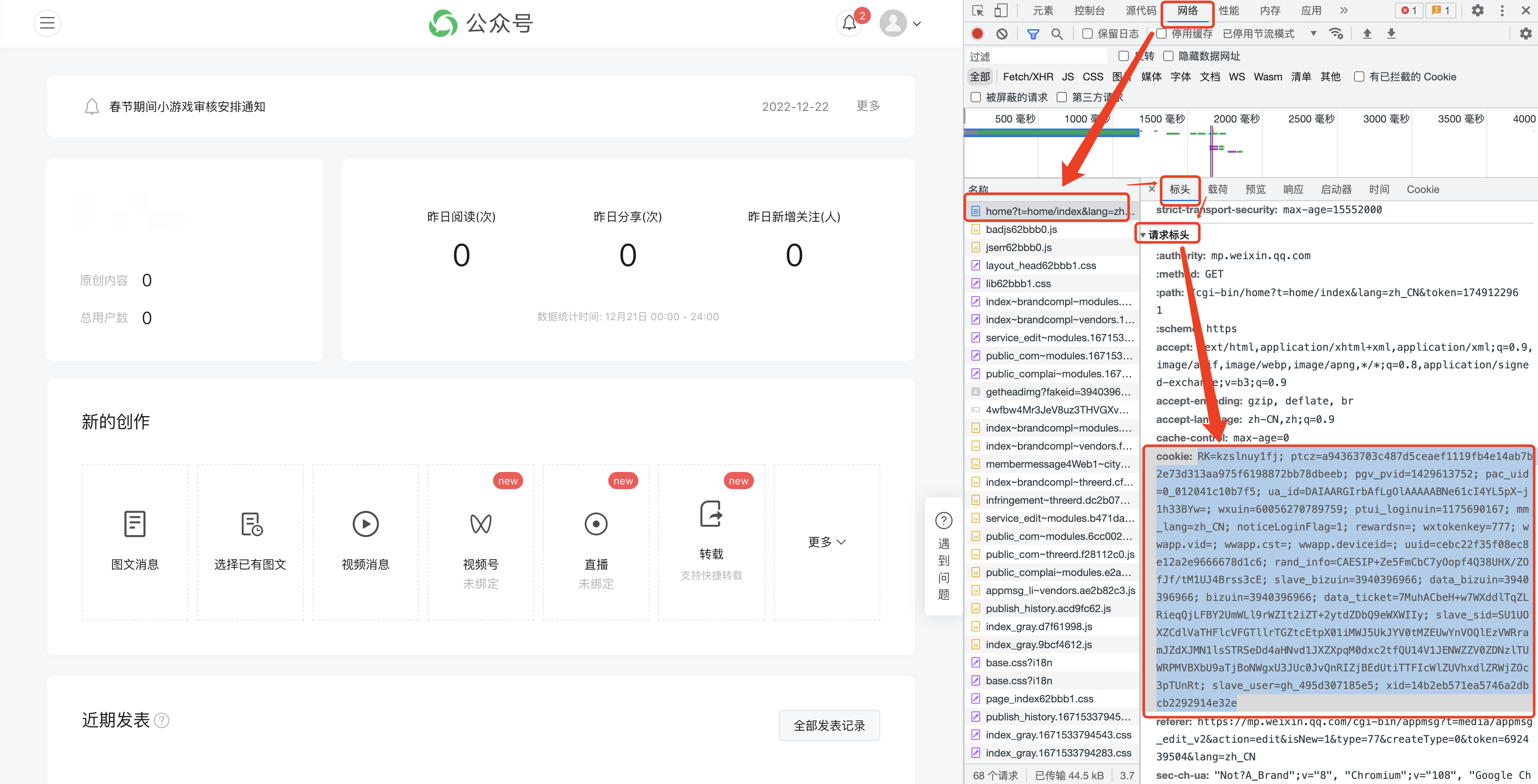
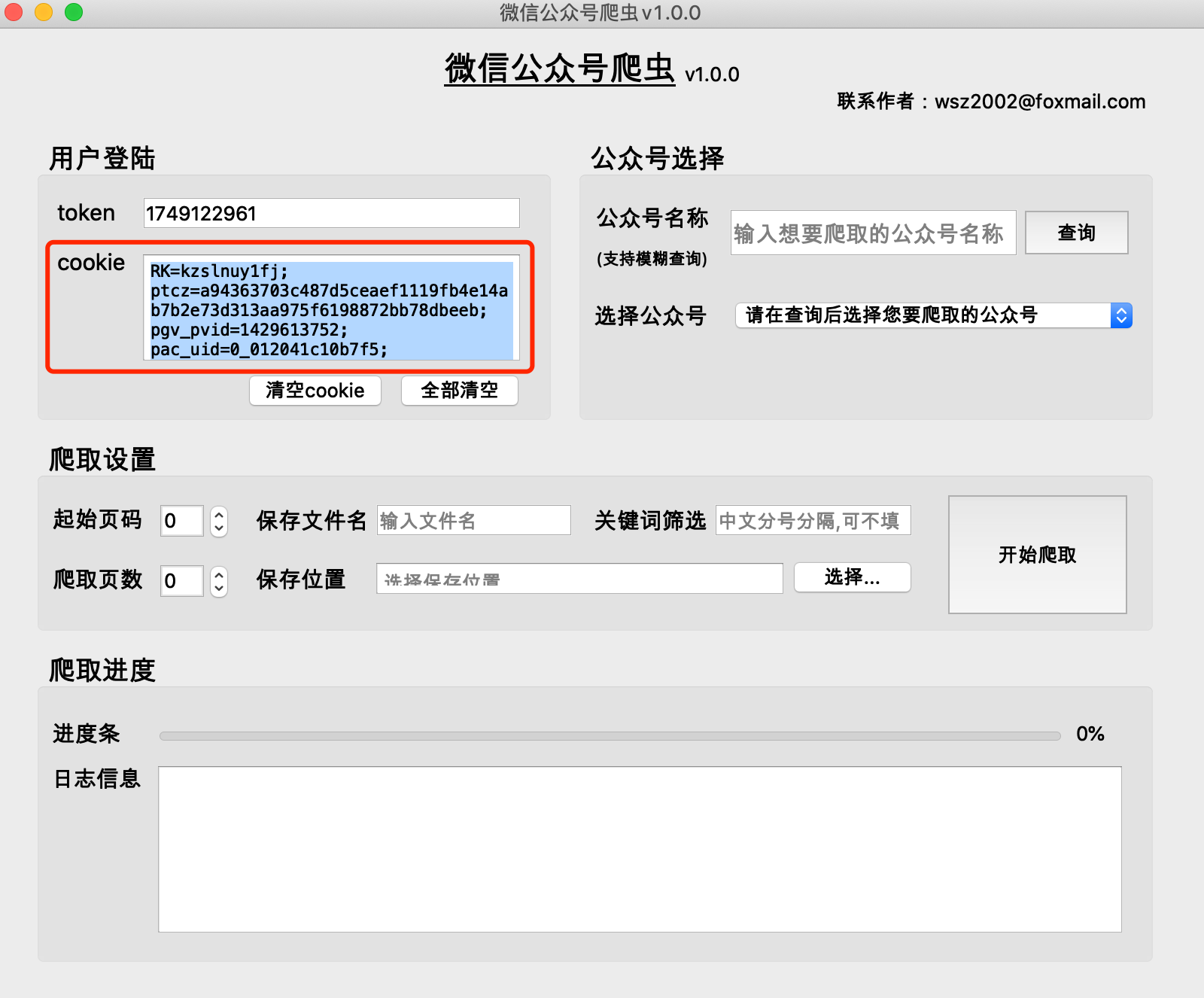
F12開啟以下介面,並切換至【網路】 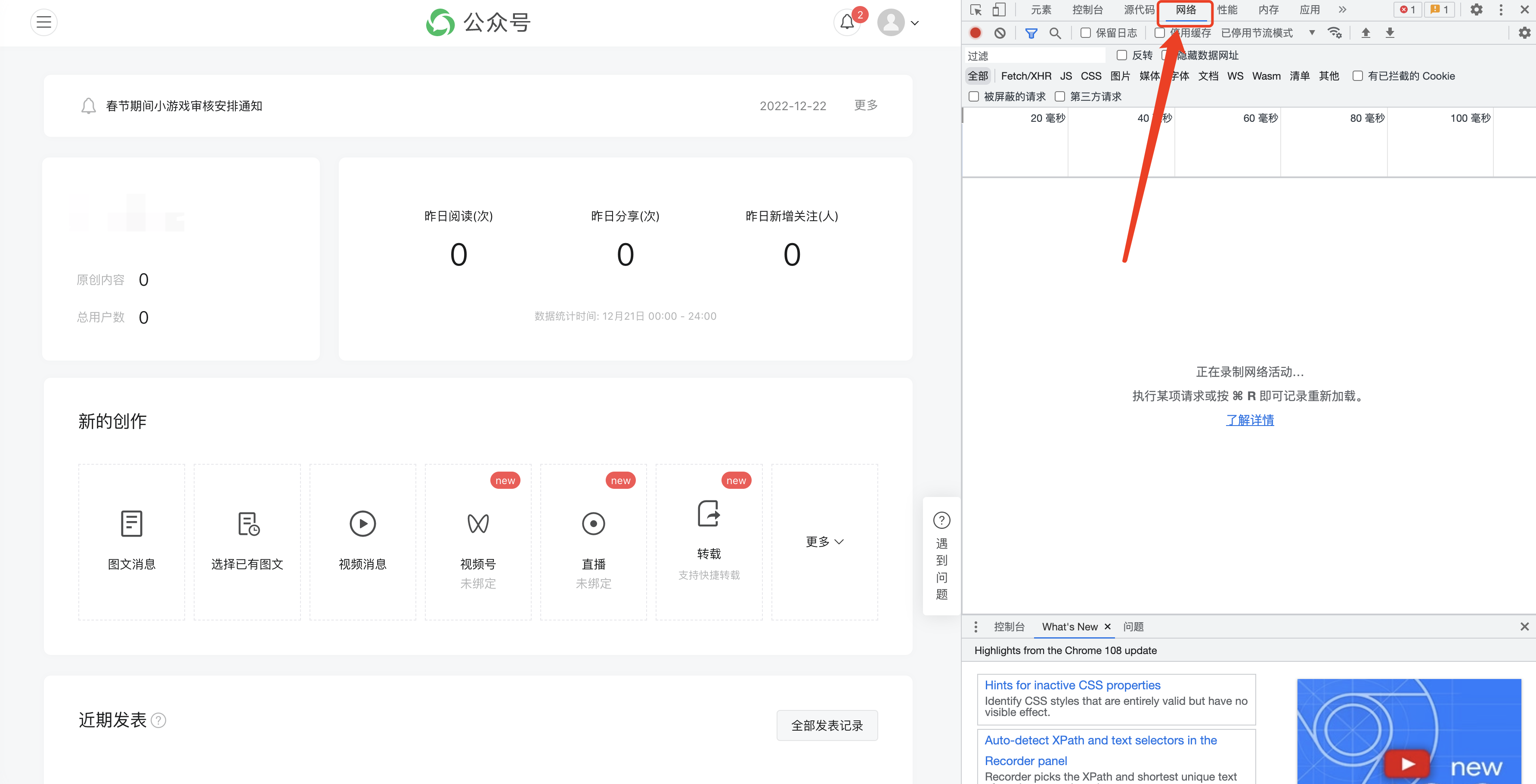
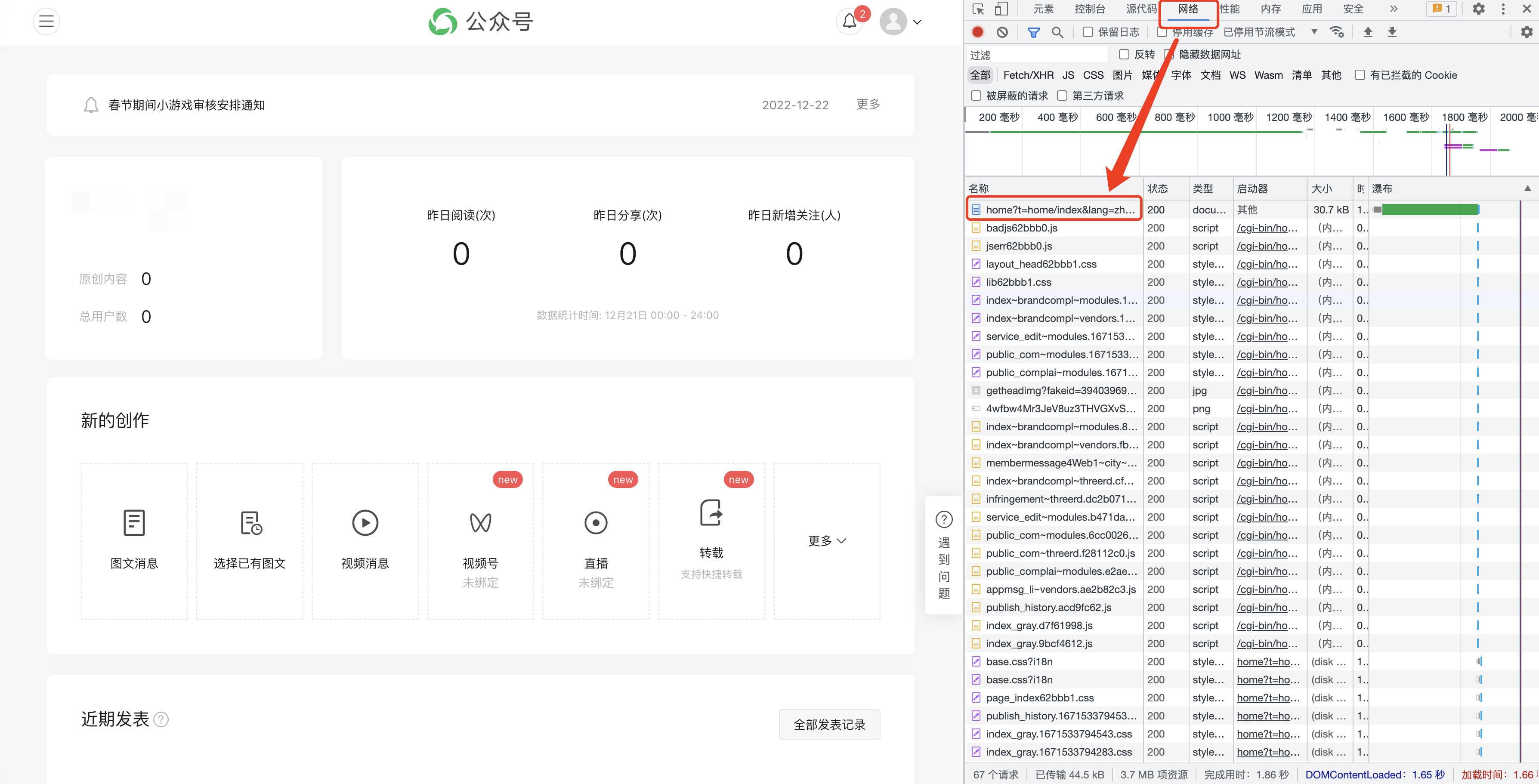
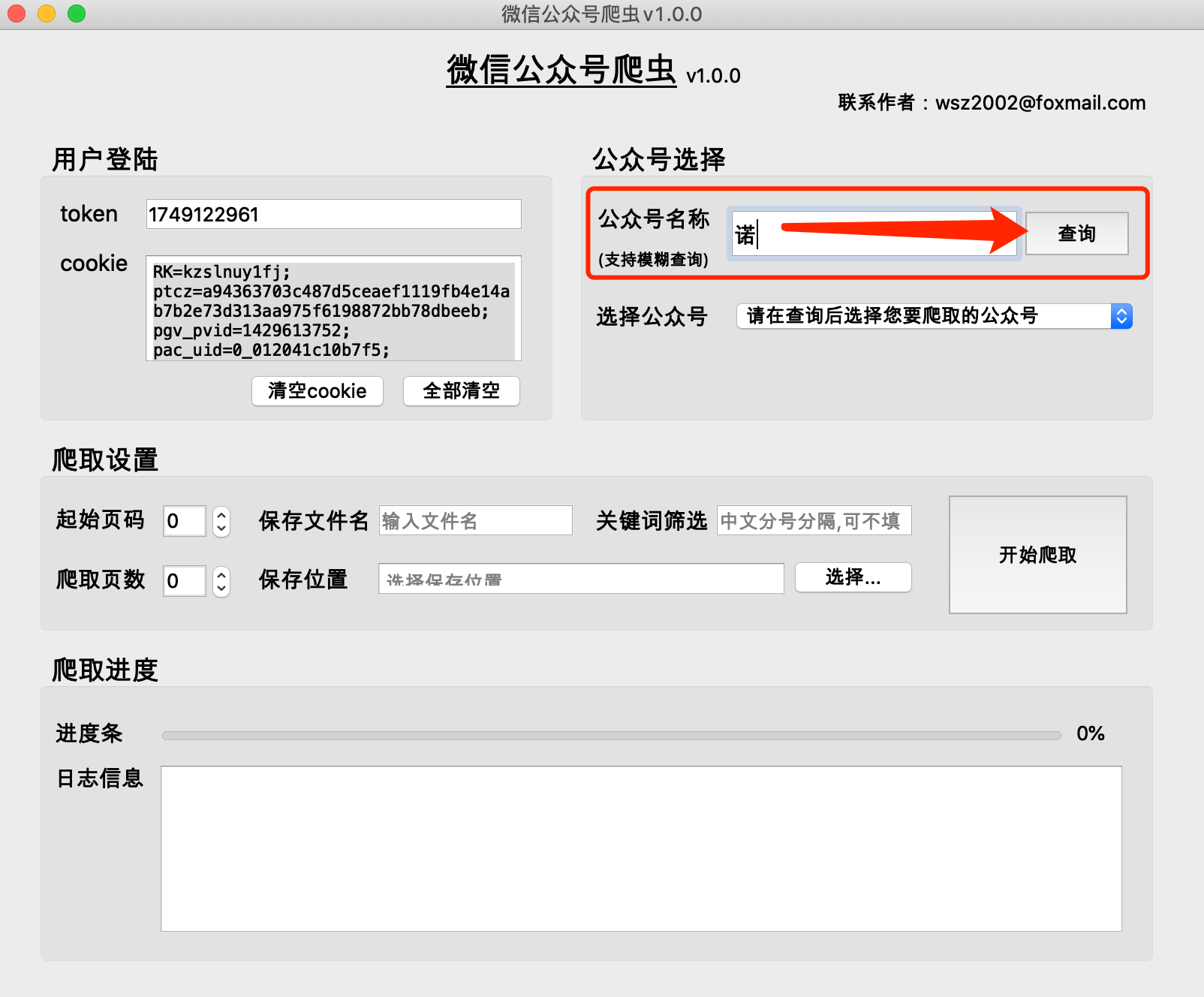
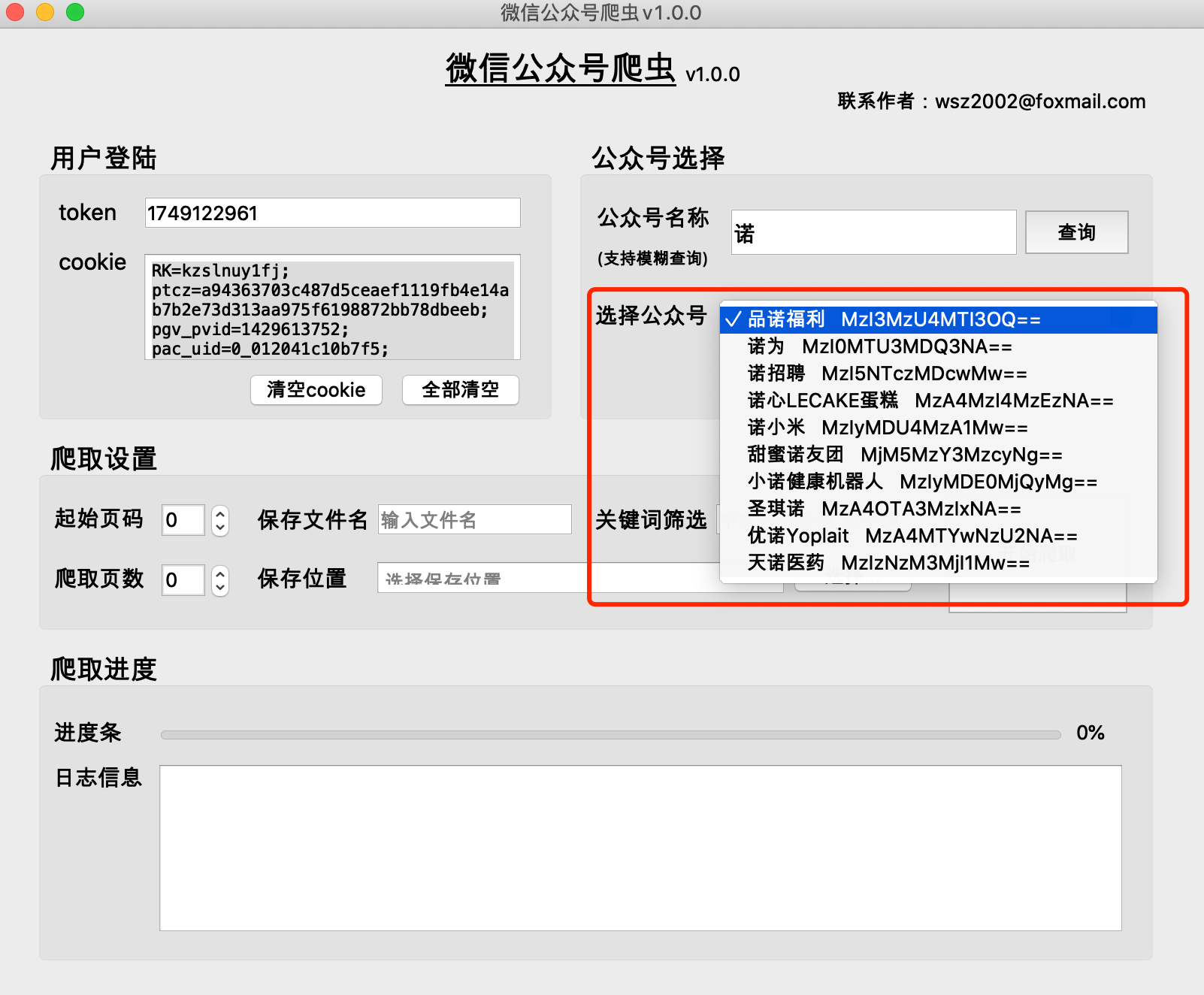
(1)公眾號歷史文章是分頁取得的,一般一頁有5-10篇文章
(2)公眾號歷史文章頁數越小,時間越新,第0頁儲存的是最新文章
(3)推薦起始頁碼從0開始
(4)爬取頁數不能為0,否則爬取結果為空
輸入正確的檔案名,選擇檔案位置即可
(1)功能:用於根據關鍵字篩選文章,取得文章標題中包含關鍵字的文章。如果不填寫,則獲取所有文章。
(2)格式:关键词1;关键词2;关键词3
用【中文分號】隔開,最後一個關鍵字後面不加分號
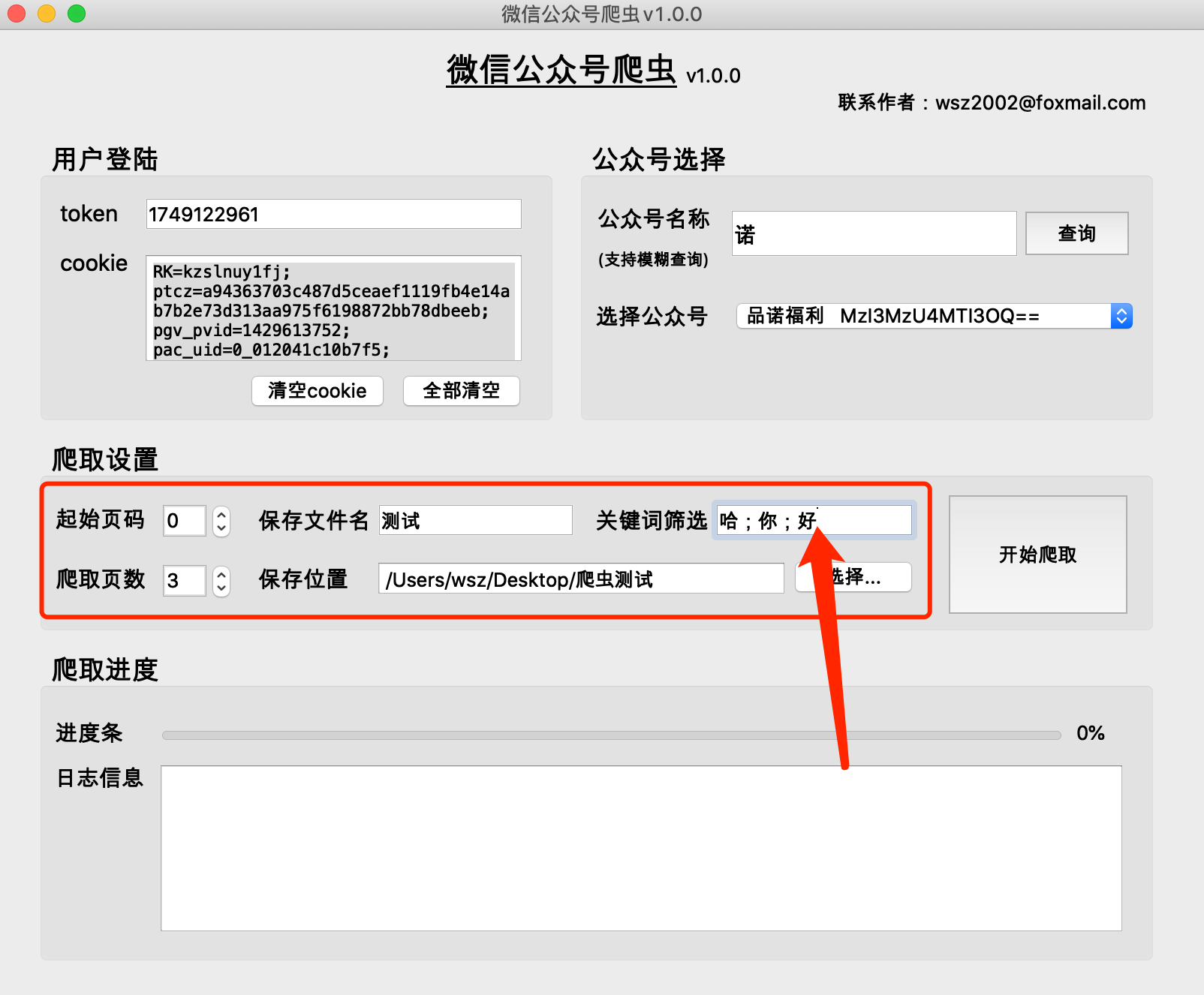
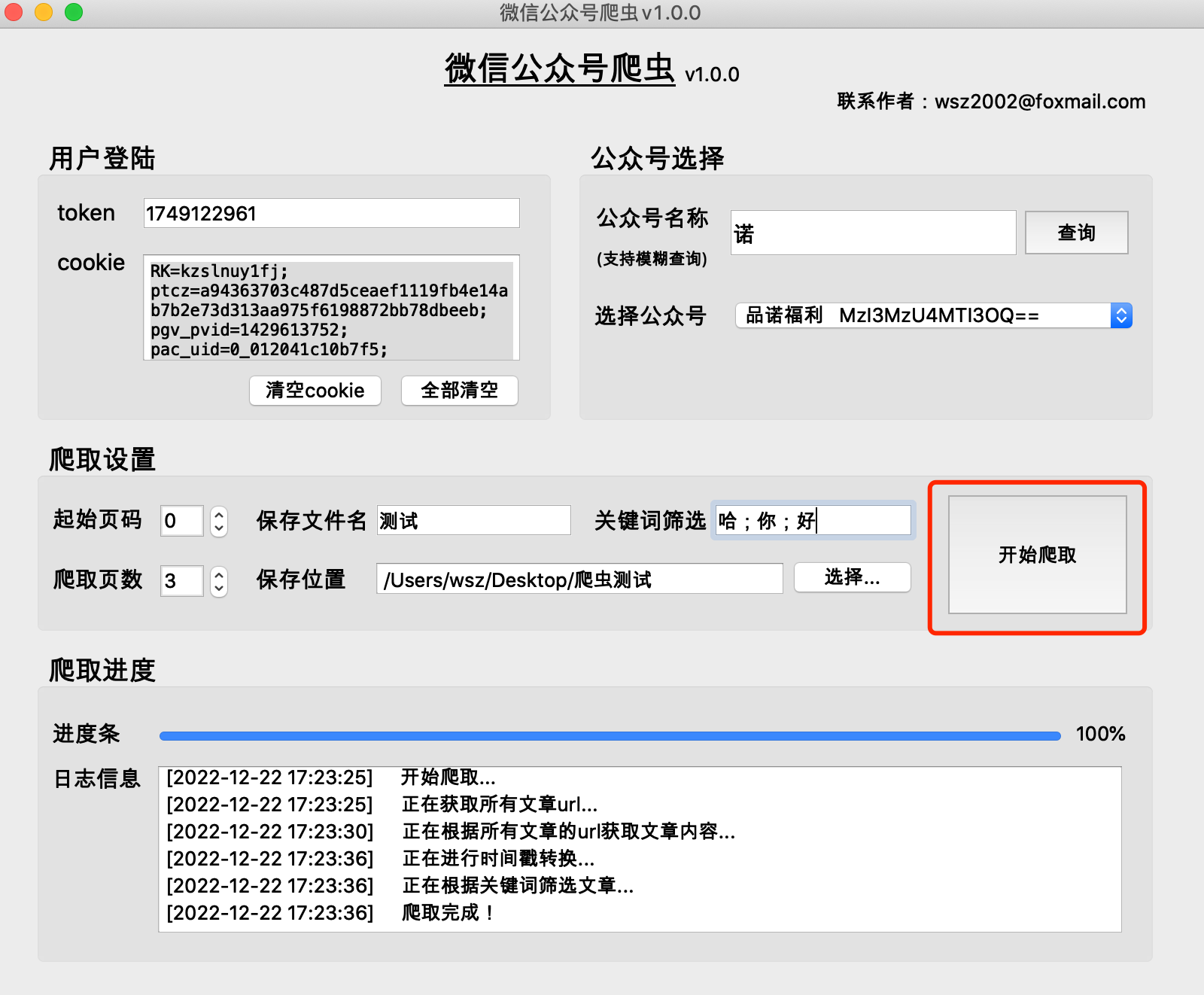
(1)程式會在選取的檔案儲存位置目錄下,產生一個保存文件名_当日日期的資料夾,並在該資料夾下儲存爬取內容
(2) raw資料夾裡的內容,是爬取過程中產生的快取文件,可以刪除