liuli
v0.2.0
簡單解釋一下:
採集者:監控各自關注的公眾號、書籍或部落格來源等自訂閱讀來源,以統一標準格式流入Liuli作為輸入來源;
處理器:對目標內容進行自訂處理,例如基於歷史廣告數據,利用機器學習實現一個廣告分類器自動打標籤,或引入鉤子函數在相關節點執行等;
分發器:依靠介面層進行資料請求&回應,為使用者提供個人化配置,然後根據配置自動進行分發,將乾淨的文章流向微信、釘釘、TG、RSS客戶端甚至自建網站;
備份器:將處理後的文章進行備份,例如持久化到資料庫或GitHub等。
這樣做就實現了乾淨閱讀環境的構建,衍生一下,基於獲取的數據,可做的事情有很多,大家不妨發散一下思路。
開發進度看板:
v0.2.0: 實作基礎功能,確保常規場景解決方案可套用
v0.3.0: 實作擷取器自定義,使用者所見即可擷取
為了提升模型的辨識準確率,我希望大家能盡力貢獻一些廣告樣本,請看樣本文件:.files/datasets/ads.csv,我設定格式如下:
| title | url | is_process |
|---|---|---|
| 廣告文章標題 | 廣告文章連接 | 0 |
字段說明:
title:文章標題
url:文章鏈接,如果微信文章想、請先驗證是否失效
is_process:表示是否進行樣本處理,預設填0即可
來個實例:
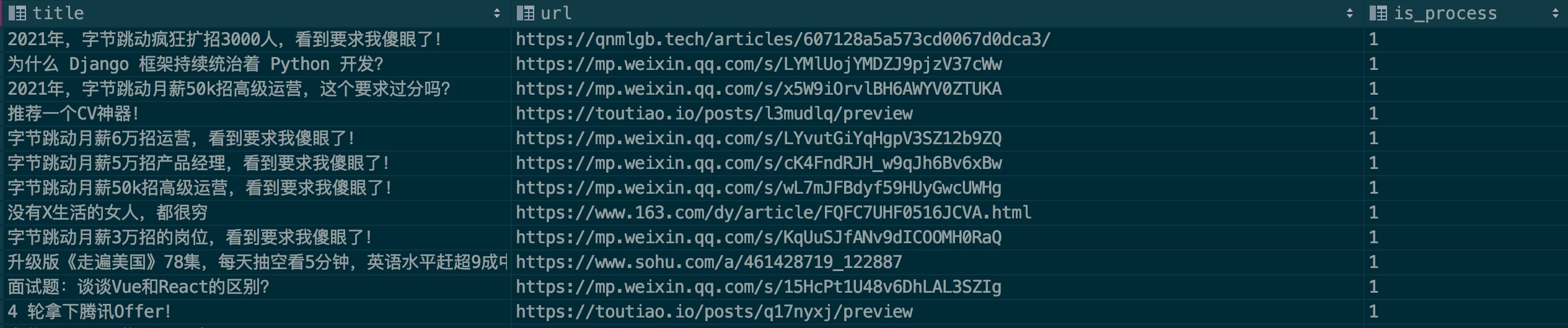
一般廣告會重複在多個公眾號投放,填寫的時候麻煩查一下是否存在此筆記錄,希望大家能一起合力貢獻,親,來個PR 貢獻你的力量吧!
感謝以下開源專案:
Flask: web框架
Vue: 漸進式JavaScript框架
Ruia: 非同步爬蟲框架(自研自用)
playwright: 使用瀏覽器進行資料抓取
以上僅列出比較核心的開源依賴,更多第三方依賴請見Pipfile檔案。
您任何PR都是對Liuli專案的大力支持,非常感謝以下開發者的貢獻(排名不分先後):
歡迎一起交流(關注入群):


