ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot是基於OpenAI官方API利用對話模型實現的一種類chatGPT機器人,並透過Wechaty框架將其部署在微信端,從而實現機器人聊天。
ChatGPT WechatBot is a kind of chatGPT robot based on the OpenAI official API and using the dialogue model. It is deployed on WeChat through the Wechat framework to achieve robot chat.
註:本項目是本地Win10實現,不需要伺服器部署(如果需要伺服器部署,可以將docker部署到伺服器即可)
(1)、Windows10
(2)、Docker 20.10.21
(3)、Python3.9
(4)、Wechaty 0.10.7
1.下載Docker
https://www.docker.com/products/docker-desktop/ 下載Docker
2、開啟Win10虛擬化
cmd輸入control開啟控制面板,進入程序,如下圖所示:
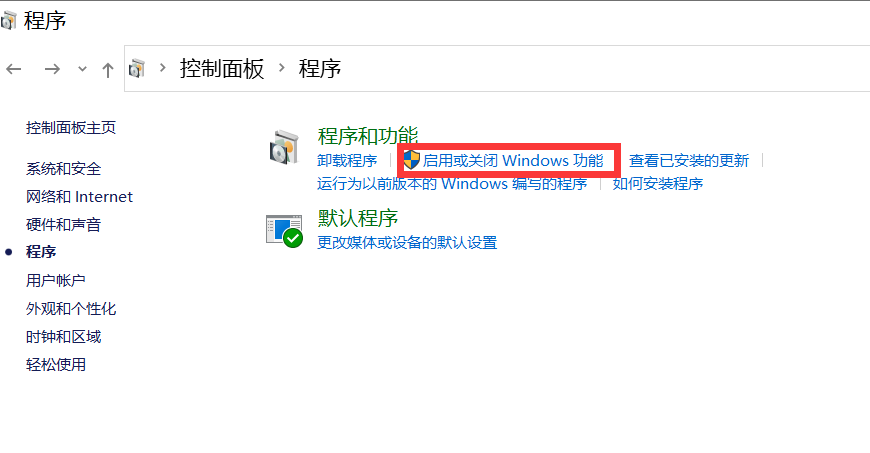
進入啟用或關閉Windows功能,開啟Hyper-V
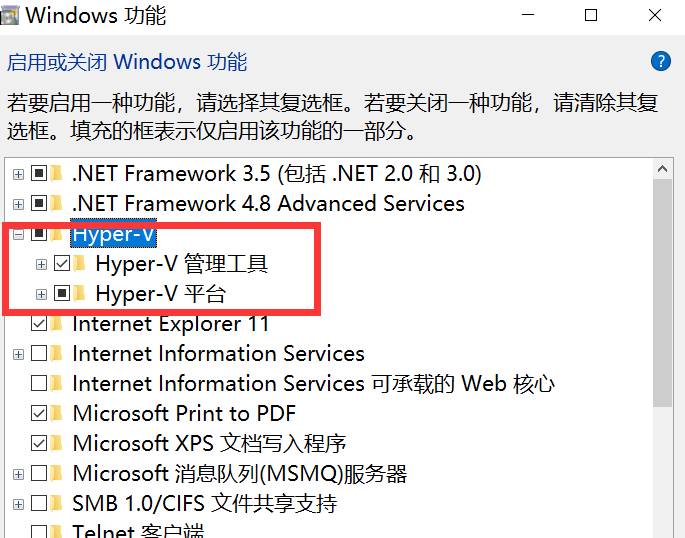
註:如果電腦沒有Hyper-V,需要執行以下操作:
建立一個文字文檔,並填入以下程式碼,再命名為Hyper.cmd
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL然後以管理員身分執行此文件,待腳本運行完,重開機後便有Hyper-V節點
3、運行Docker
註:如果第一次執行Docker出現以下情況:
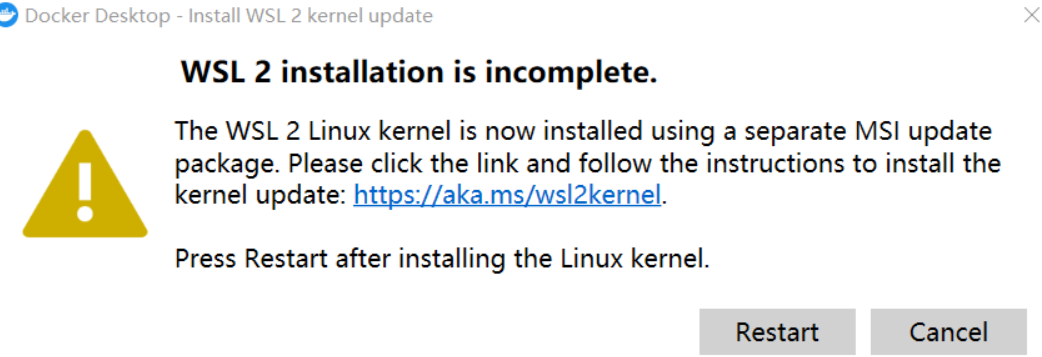
需要下載最新的WSL 2包
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
更新後便可進入主頁面,然後更改docker engine裡面的設置,將鏡像換成阿里雲的國內鏡像:
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}這樣拉去鏡像速度較快(國內)
4.拉去Wechaty鏡像:
docker pull wechaty:0 . 65因為測試時發現0.65版本的wechaty最穩定
拉去鏡像後:
Puppet :想使用wechaty開發微信機器人,需要使用一個中間件Puppet來控制微信的操作,官方把Puppet翻譯為傀儡,目前有多種Puppet可以使用,不同版本的Puppet區別是可以實現的機器人功能不同。例如你想讓你的機器人將用戶踢出群組聊天,那就需要使用Pad協定下的Puppet。
申請連結:http://pad-local.com/#/login
註:申請帳號後會獲得7天時間的token
申請token後在cmd窗口執行以下命令:
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
參數說明:
WECHATY_PUPPET_PADLOCAL_TOKEN :申請好的token
**WECHATY_TOKEN **:隨機寫一個保證唯一的字串即可
WECHATY_PUPPET_SERVER_PORT :docker服務端端口
wechaty/wechaty:0.65 :wechaty鏡像的版本
註: - “8080:8080”* 是你本機以及docker服務端的端口,注意docker服務端端口要和WECHATY_PUPPET_SERVER_PORT保持一致
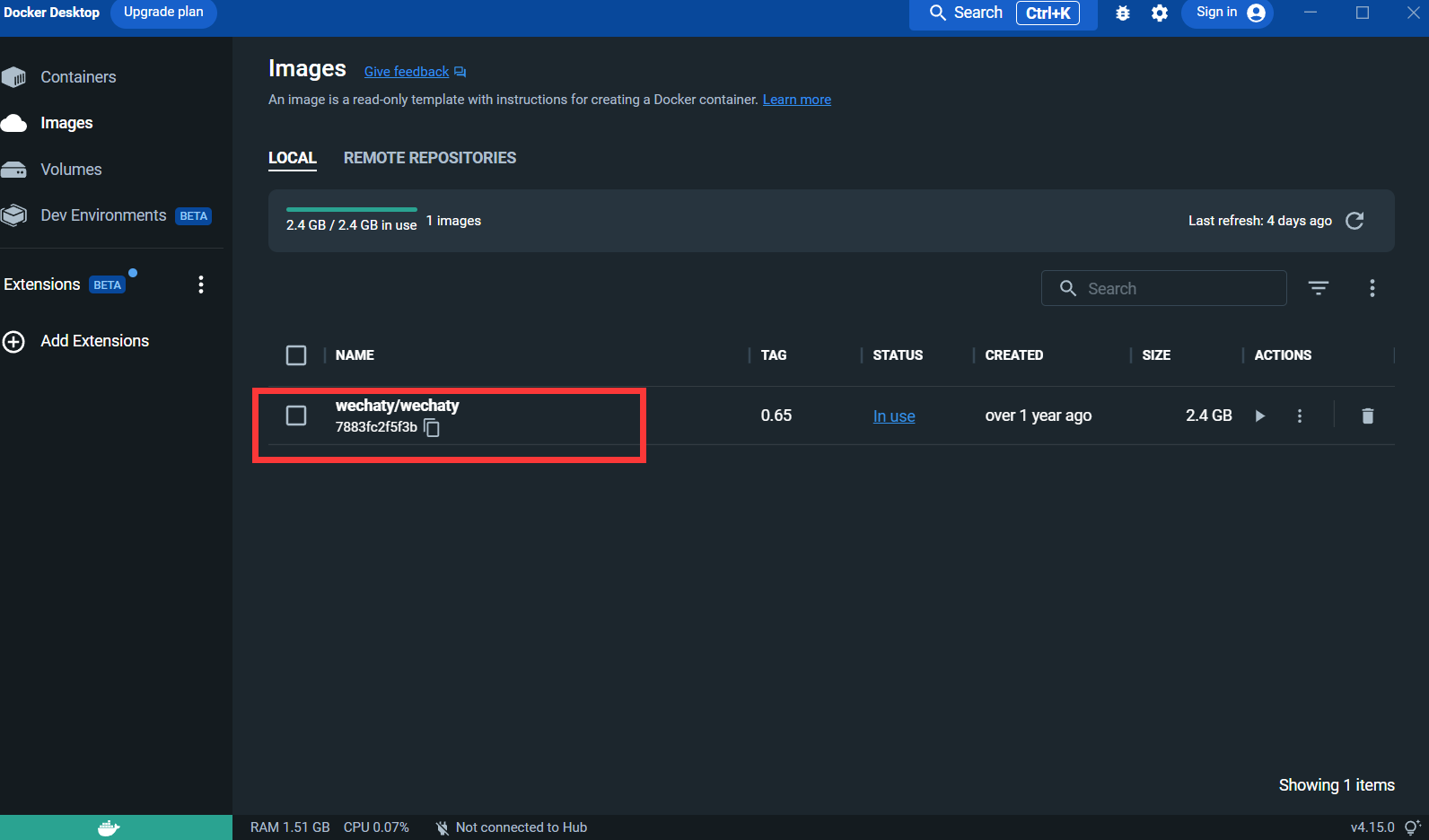
運行之後,便在docker desktop的面板中看容器:
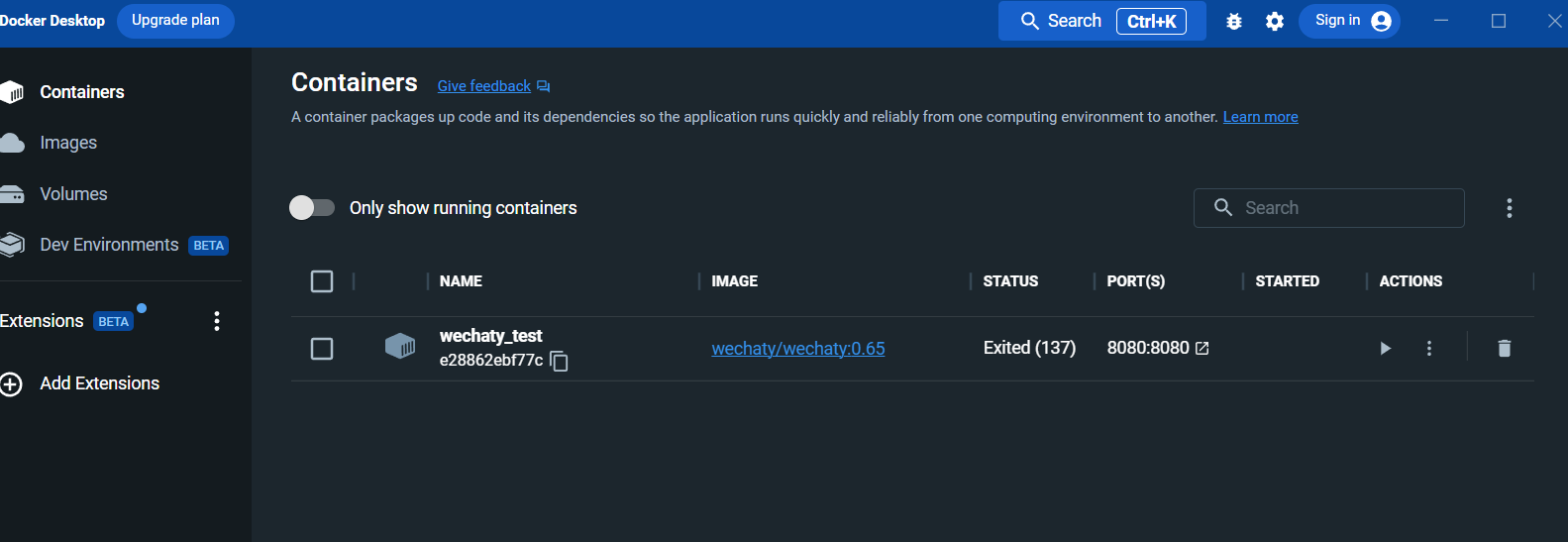
進入日誌介面:
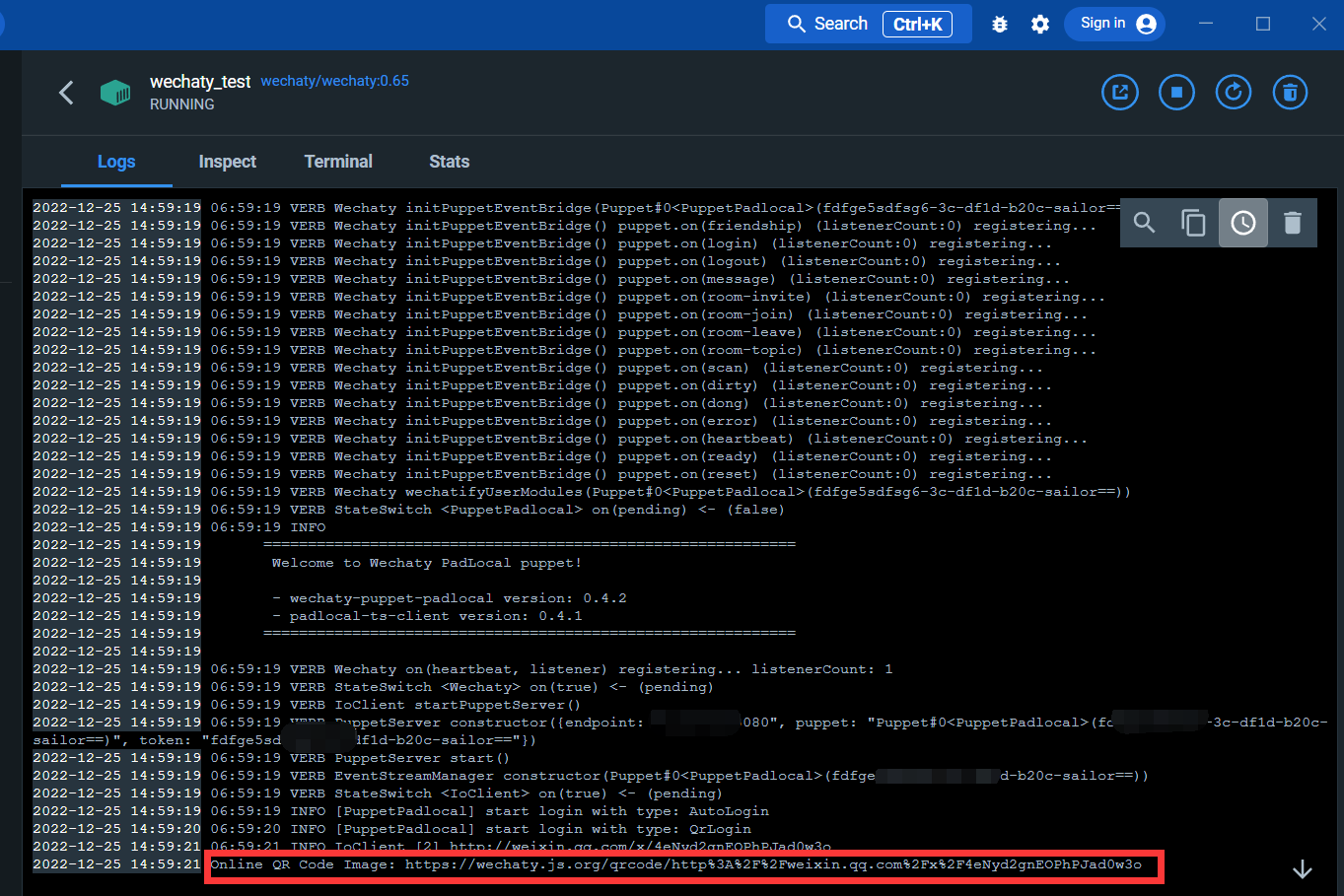
透過下方的鏈接,便可以掃碼登入微信
登入之後,docker的服務變搭建完成
安裝wechaty和openai庫
開啟cmd,執行以下命令:
pip install wechaty
pip install openai登入openAI
https://beta.openai.com/
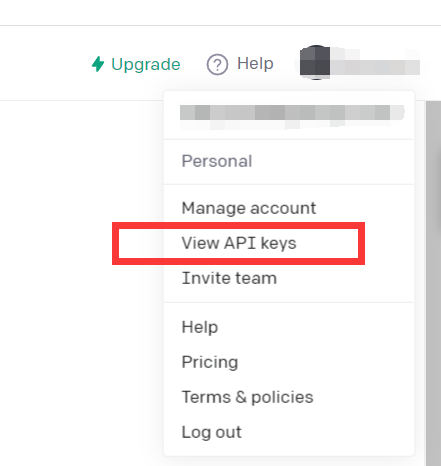
點選View API keys
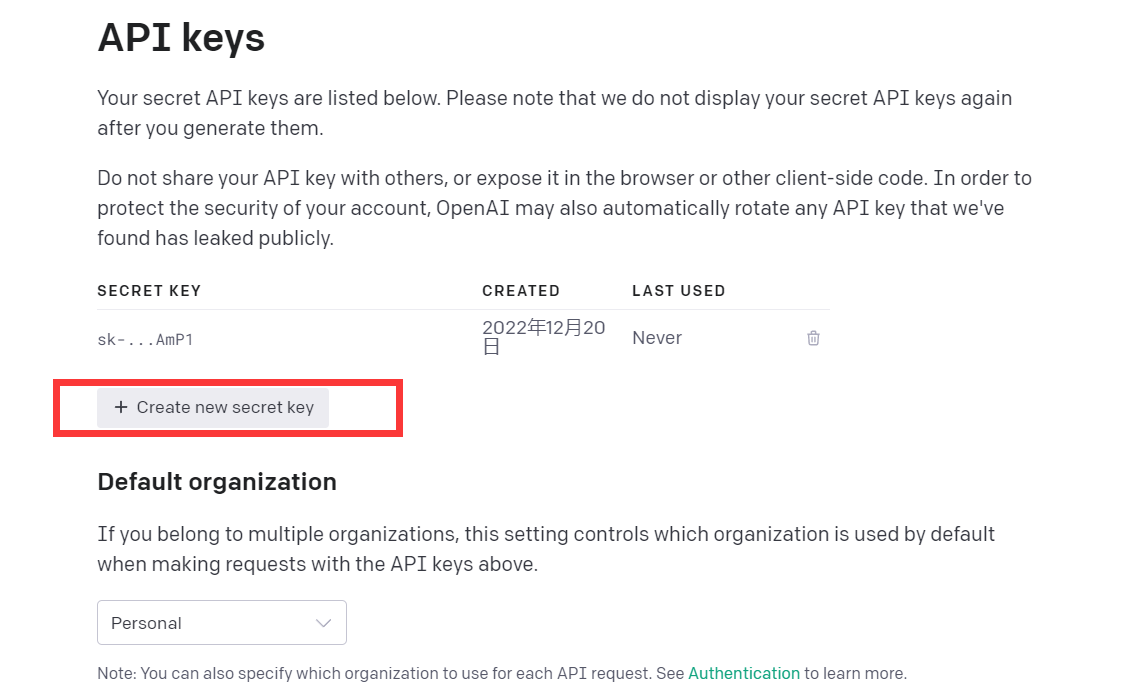
獲得API kyes即可
至此,環境已建完畢
可以嘗試閱讀這段demo程式碼
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
這段程式碼調用的是與chatGPT一樣模型的CPT-3模型,回答效果也不錯
openAI的GPT-3模型介紹如下:
Our GPT-3 models can understand and generate natural language. We offer four main models with different levels of power suitable for different tasks. Davinci is the most capable model, and Ada is the fastest.
| LATEST MODEL | DESCRIPTION | MAX REQUEST | TRAINING DATA |
|---|---|---|---|
| text-davinci-003 | Most capable GPT-3 model. Can do any task the other models can do, often with higher quality, longer output and better instruction-following. Also supports inserting completions within text. | 4,000 tokens | Up to Jun 2021 |
| text-curie-001 | Very capable, but faster and lower cost than Davinci. | 2,048 tokens | Up to Oct 2019 |
| text-babbage-001 | Capable of straightforward tasks, very fast, and lower cost. | 2,048 tokens | Up to Oct 2019 |
| text-ada-001 | Capable of very simple tasks, usually the fastest model in the GPT-3 series, and lowest cost. | 2,048 tokens | Up to Oct 2019 |
While Davinci is generally the most capable, the other models can perform certain tasks extremely well with significant speed or cost advantages. For example, Curie can perform many of the same taskss. For example, Curie can perform many of the same tasks butas Da , 1000, 10
We recommend using Davinci while experimenting since it will yield the best results. Once you've got things working, we encourage trying the other models to see if you can get the same results with other model the see if you can。 models' performance by fine-tuning them on a specific task.
簡言之,功能最強大的GPT-3 模型。可以完成其他模型可以完成的任何任務,通常具有更高的品質、更長的輸出和更好的指令遵循。也支援在文字中插入補全。
雖然直接使用text-davinci-003模型,可以達到chatGPT單輪對話的效果;但是為了更好實現與chatGPT一樣的多輪對話的效果,可以設計一個對話模型。
基本原理:告訴text-davinci-003模型當前對話的背景
實作方法:設計對話記憶佇列,用於保存目前對話的前k輪對話,並在提問前告訴text-davinci-003模型,前k輪對話的內容,然後再透過text-davinci-003模型獲得當前回答的內容
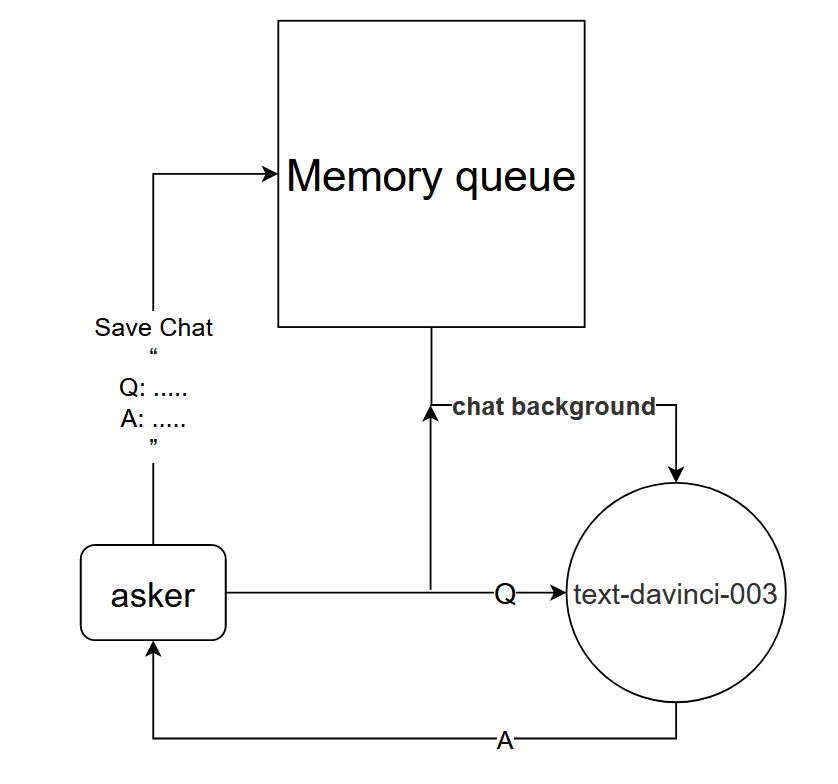
這種方法的效果竟然出奇的好!給出部分chat的記錄
可見,目前透過chat-backgroud還可以讓AI完成情境學習
不但如此,還可以實現和chatGPT一樣的引導式寫文章
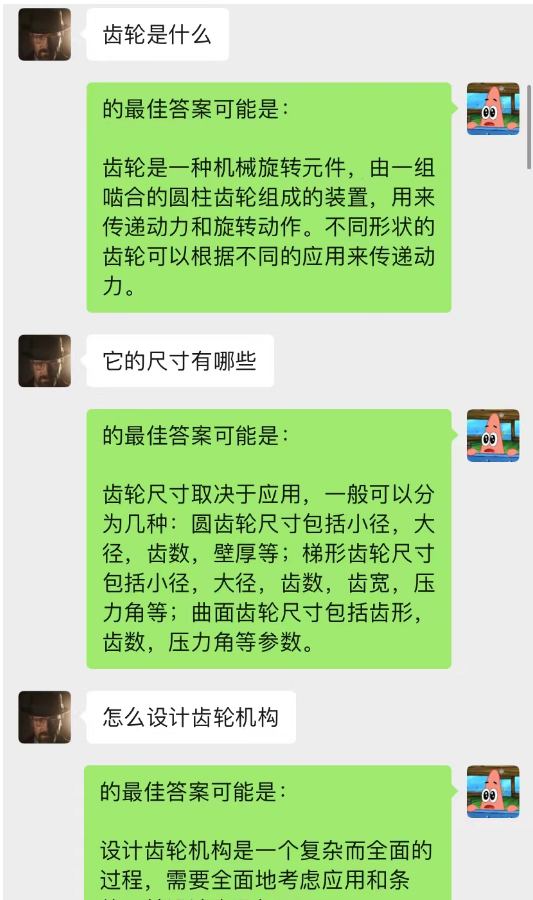
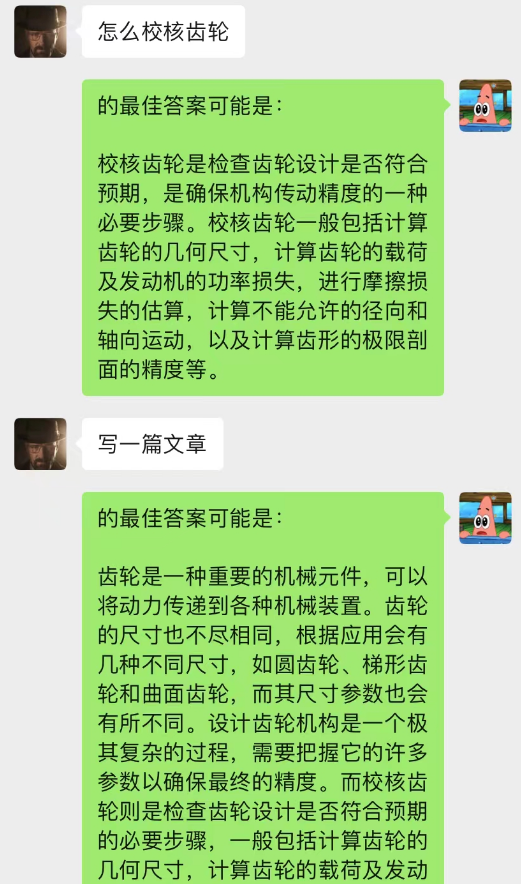
這個模型是我目前構思的最佳化chat-backgroud對話模型的一種方法,其基本邏輯和N-gram語言模型一樣,只不將N是動態變化的,加上馬爾科夫性,就可以預測當前對話與脈絡之間的關係,從而判斷chat-backgroud中那段是最為重要的,從而根據最重要的記憶對話內容,再結合目前問題利用text-davinci-003模型,給出答案(相當於讓AI在聊天中做到,利用之前的聊天內容)
這個模型的實作需要大量資料進行訓練,程式碼還沒完成
------挖坑:程式碼實現後,更新這部分詳細步驟
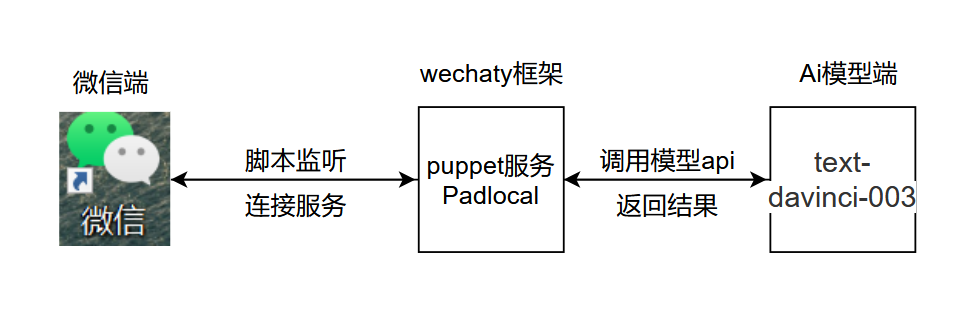
專案基本邏輯,如下圖所示:
 .py,在圖示位置新增開啟chatGPT.py,在圖示位置新增秘鑰和設定環境變量
.py,在圖示位置新增開啟chatGPT.py,在圖示位置新增秘鑰和設定環境變量

代碼解釋:
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
運行成功
1.在docker中登錄,不要使用python中wechaty的登錄
2.在程式碼中設定time.sleep() ,模擬人回覆訊息的速度
3.最好測試時不要使用大號,建議創建ai專用小號測試
此專案中的內容僅供技術研究與科普,不作為任何結論性依據,不提供任何商業化應用授權,不為任何行為負責
~~email:[email protected]


