存儲庫由在Pytorch實施並在MNIST數據集中培訓的VQ-VAE組成。
VQ-VAE遵循與變量自動編碼器(VAE)背後相同的基本概念。 VQ-VAE使用離散的潛在嵌入對於變量自動編碼器,即z(潛在向量)的每個維度是一個離散的整數,而不是編碼輸入時通常使用的連續正態分佈。
VAE由3個部分組成:
好吧,您可能會詢問VQ-VAE帶來的差異。讓我們列出它們:
許多重要的現實對像是離散的。例如,在圖像中,我們可能有“貓”,“汽車”等類別的類別,而在這些類別之間插入可能是沒有意義的。離散表示也更容易建模。
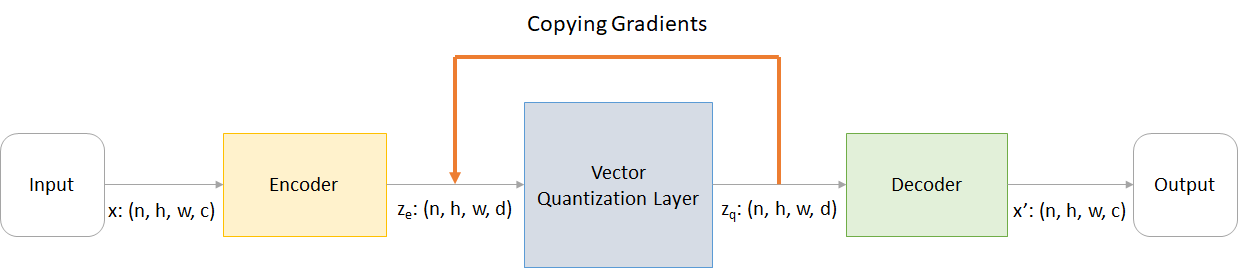
在哪裡:
n :批次大小h :圖像高度w :圖像寬度c :輸入圖像中的通道數d :隱藏狀態處的頻道數量這是VQ-VAE網絡工作的簡要概述:
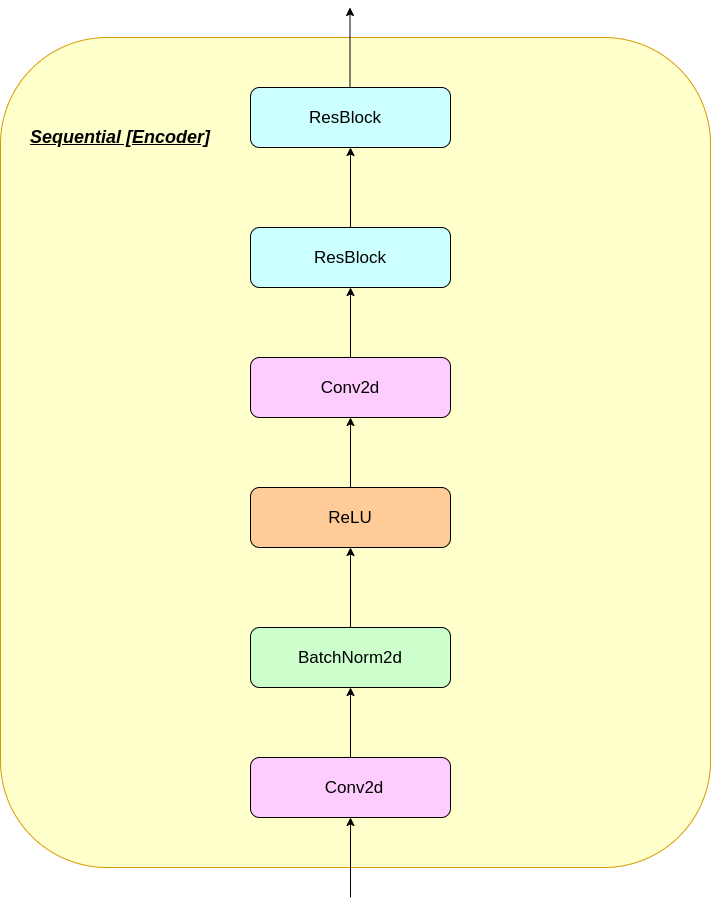
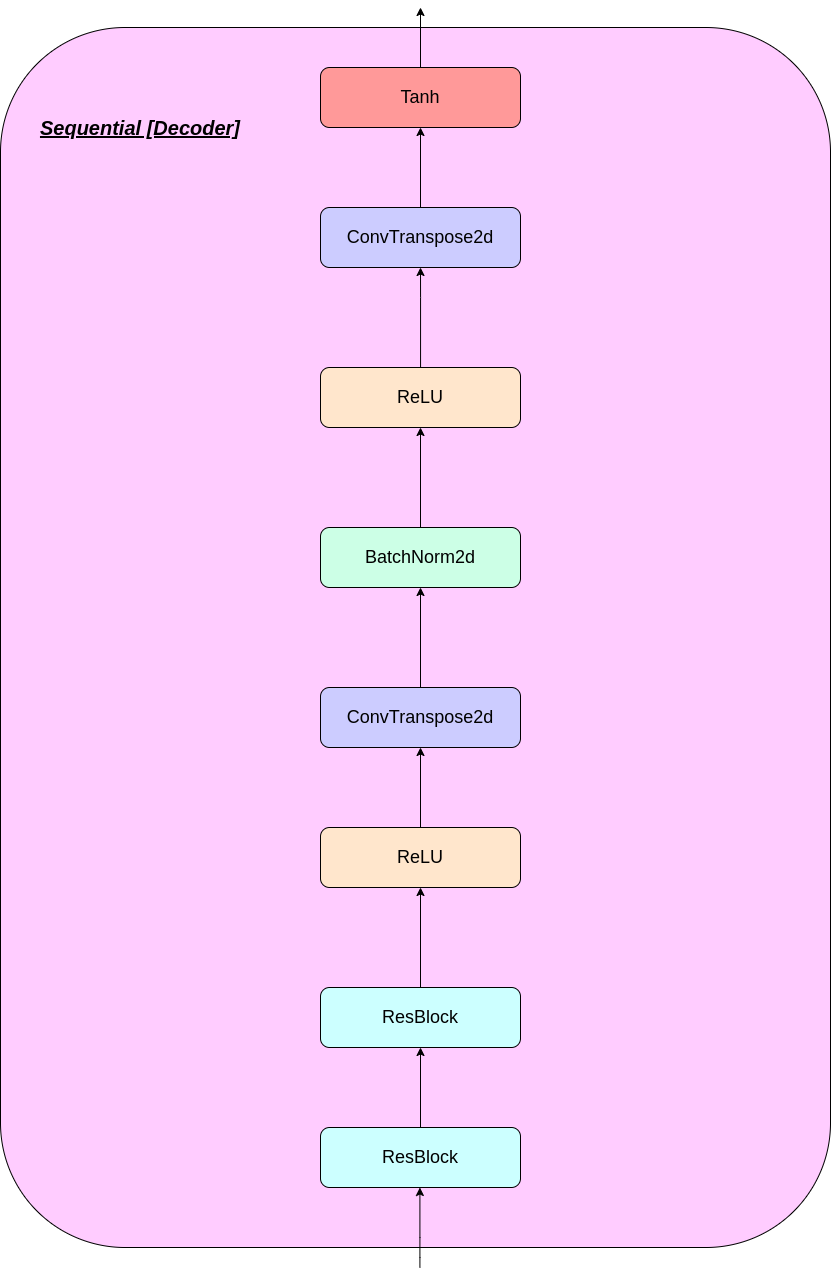
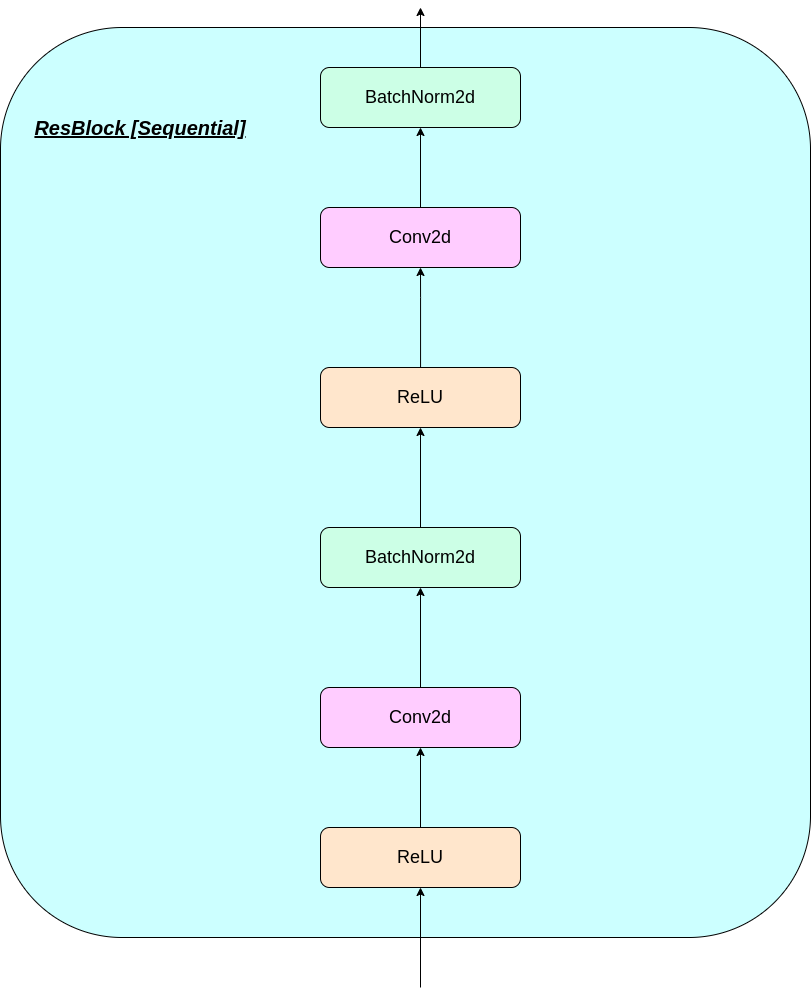
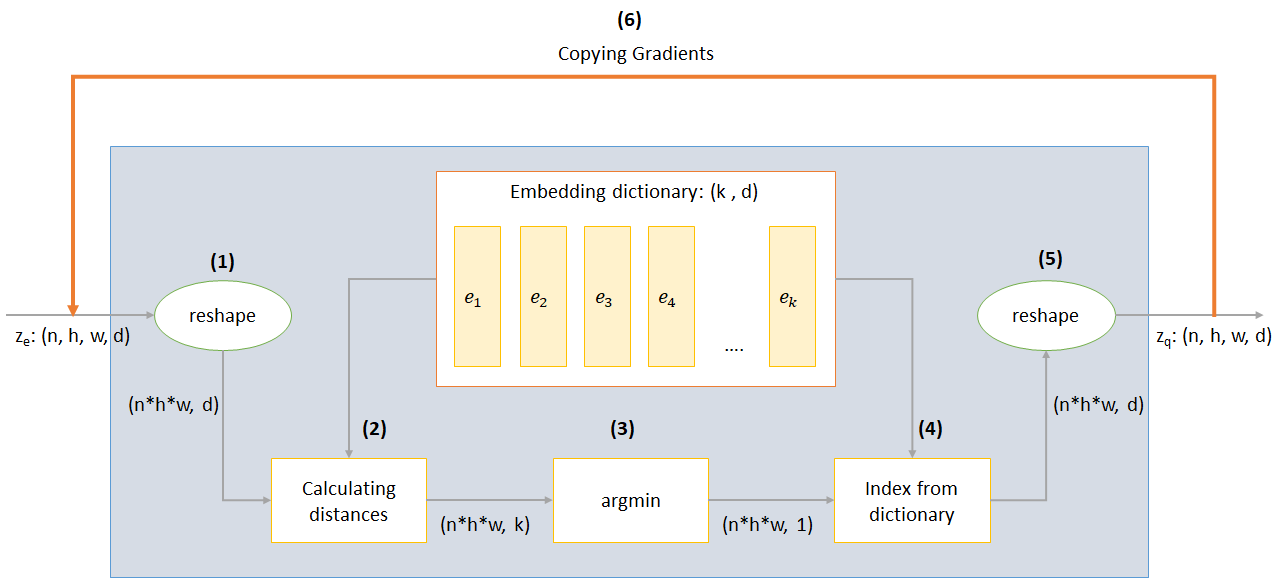
VQ層的工作可以用六個步驟來解釋:圖中的編號:
VQ-VAE使用3個損失來計算訓練期間的總損失:
重建損失:將解碼器和編碼器優化為VAE,即輸入圖像和重建之間的差異:
reconstruction_loss = -log( p(x|z_q) )
代碼書丟失:由於梯度繞過嵌入嵌入,使用L2錯誤將嵌入向量E_I移至編碼器輸出的詞典學習算法。
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG表示停止梯度操作員,這意味著沒有梯度流過任何應用的梯度)
承諾損失:由於嵌入空間的體積是無尺寸的,因此如果嵌入E_I訓練不如Encoder參數訓練,則可以任意增長,因此添加了承諾損失以確保編碼器承諾嵌入嵌入。
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β是一種超參數,可以控制我們要與其他組件相比,要權衡承諾損失的程度)
您可以通過在CMD提示中運行以下操作來下載回購或克隆
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
您可以通過以下命令(在Google Colab中)從頭開始訓練模型
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - 數據文件夾的名稱data-folder - 數據文件夾的名稱device - 設置設備(CPU或CUDA,默認:CPU)hidden-size - 潛在向量的大小(默認:40)k潛在向量的數量(默認值:512)batch-size - 批量尺寸(默認:128)num-epochs - 時期數(默認值:10)lr亞當優化器的學習率(默認:2E -4)beta承諾損失的貢獻,在0.1到2.0之間(默認:1.0)num-workers - 軌跡採樣的工人數量(默認:cpu_count() - 1)該程序會自動下載MNIST數據集並將其保存到PATH_TO_MNIST_dataset文件夾中(您需要創建此文件夾)。這只會發生一次。
它還創建了一個logs文件夾和models文件夾,並且內部創建了一個文件夾,其中傳遞的名稱分別保存了內部的日誌和模型檢查點。
要從單位高斯運行以下命令(在Google colab中)隨機生成z採樣的新圖像:
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - 包含模型的文件名input -MNIST或隨機device - 設置設備(CPU或CUDA,默認:CPU)hidden-size - 潛在向量的大小(默認:40)k潛在向量的數量(默認值:512)filename - 要保存哪個文件的名稱它生成了10*10個圖像網格,這些圖像保存在名為generatedImages文件夾中。
您可以通過從model.txt中的鏈接下載預先訓練的模型。
存儲庫包含以下文件
modules.py包含用於製作模型的不同模塊VQ-VAE.py包含訓練我們的VQ-VAE模型的功能和代碼vector_quantizer.py此文件中定義了向量量化類generate-py從預訓練的模型中生成新圖像model.txt包含指向預訓練模型的鏈接README.md redme概述了倉庫references.txtreadme_images有多種圖像的讀數MNIST包含Zipped MNIST數據集(儘管需要在需要時自動下載)Training track for VQ-VAE.txt - 包含在我們的VQ-VAE模型訓練期間的損失值logs_VQ-VAE包含我們VQ-VAE模型的拉鍊張板日誌(程序自動創建)testers.py包含一些測試我們定義的模塊的功能命令運行張量板(在Google Colab中):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
訓練圖像
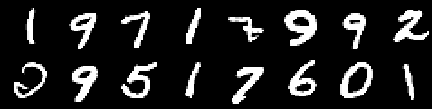
來自0個時代的圖像

來自第二個時期的圖像
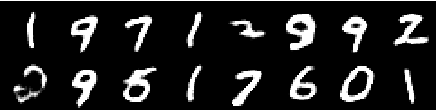
來自第四個時代的圖像
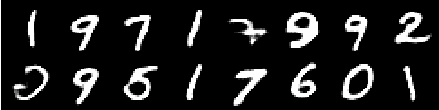
來自6個時代的圖像
來自8個時代的圖像
來自第10個時代的圖像
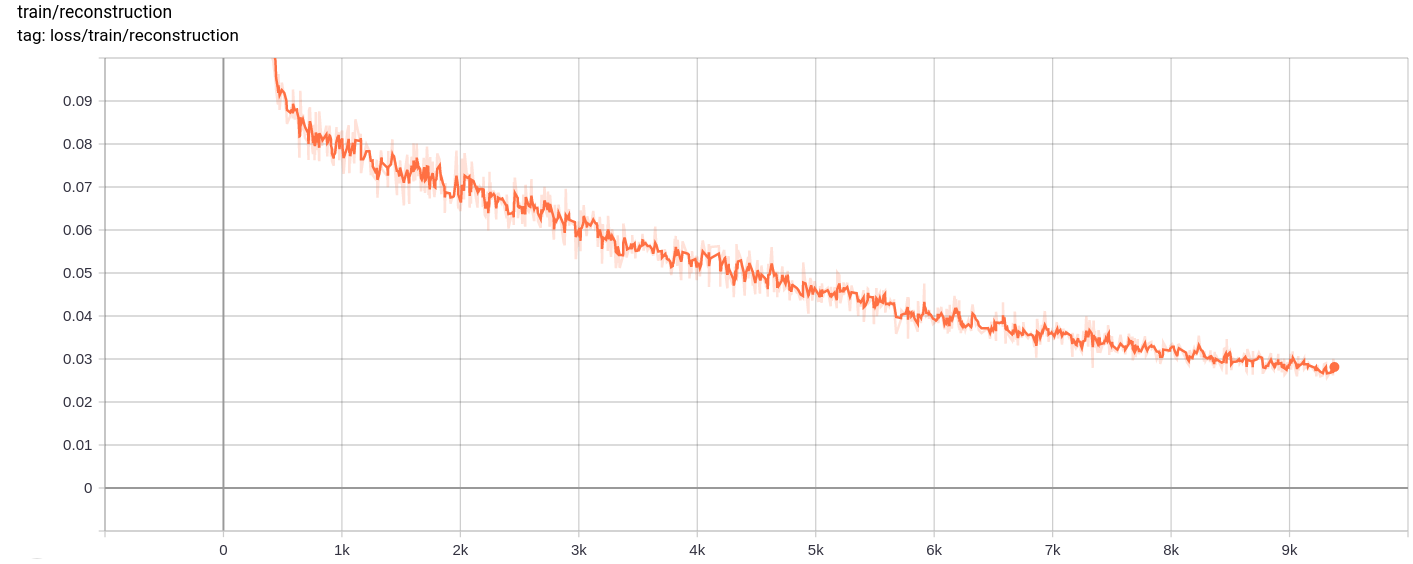
重建不斷改進,最後幾乎類似於訓練_SET圖像,這反映在損失值(在Training track for VQ-VAE.txt )。
重建損失
量化損失
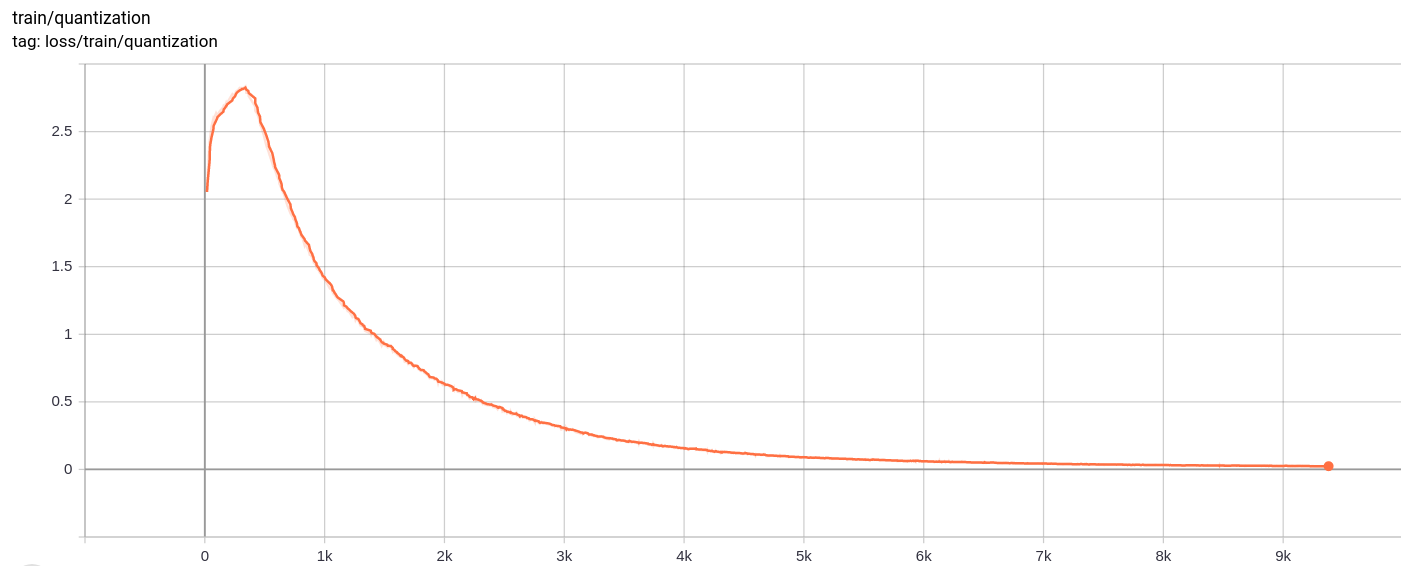
total_loss
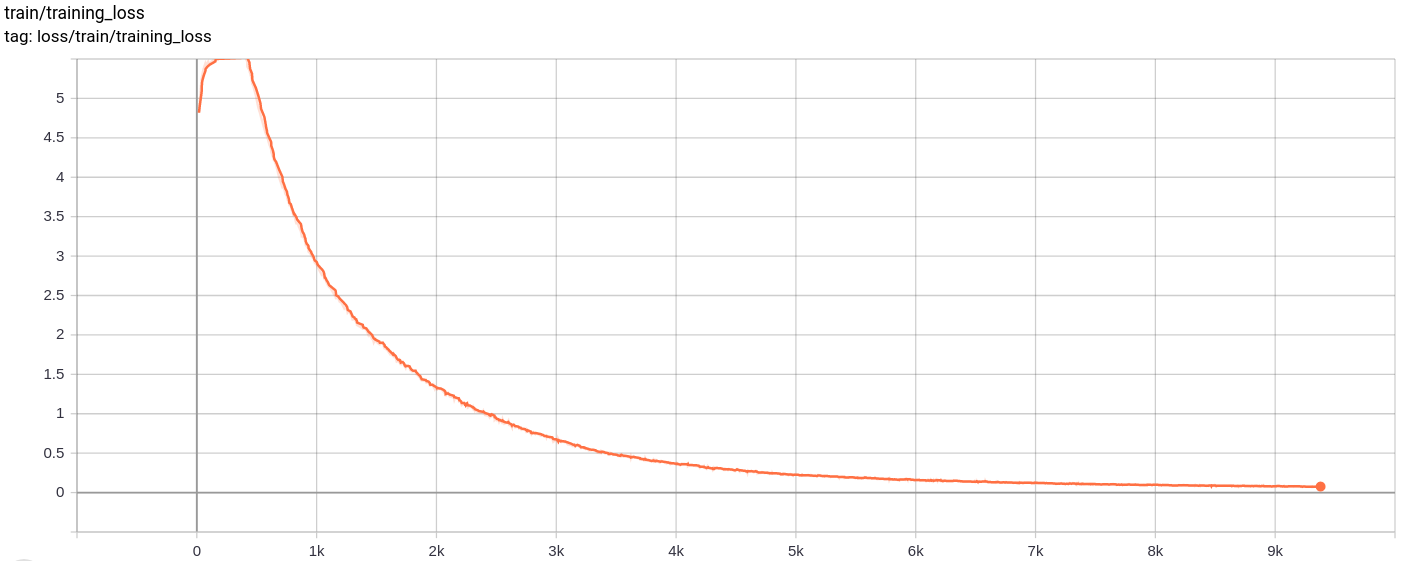
按預期,總損失,重建損失和量化損失均勻減少。
testing_loss
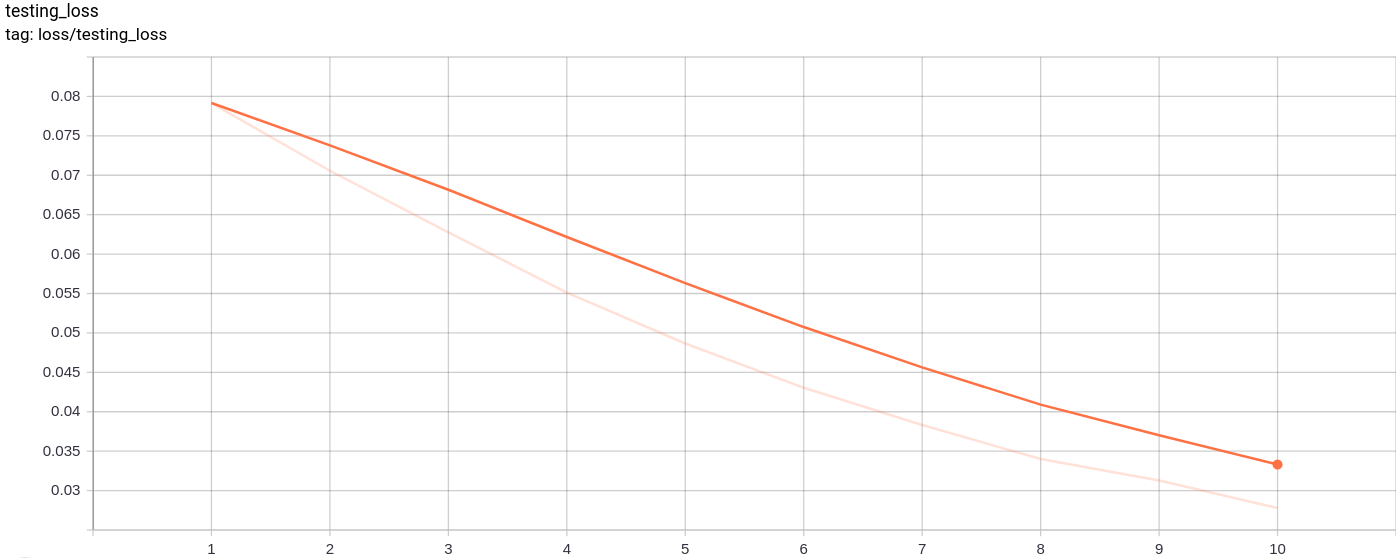
測試損失按預期均勻減少。
以下圖像網格是在將MNIST圖像作為輸入傳遞後生成的:

這一代很好。
通過從單位高斯作為輸入的AZ採樣後,生成以下圖像網格,然後通過解碼器。


圖像看起來並不完美。調整潛在空間的尺寸,嵌入向量的數量等可以幫助生成更好的隨機圖像。
該模型在Google Colab上接受了10個時期的培訓,其中批量尺寸為128。
訓練後,模型能夠很好地重建輸入圖像,並且還能夠生成新圖像,儘管生成的圖像不太好。
訓練以及測試損失也幾乎單調地減少。
我觀察到,訓練模型為10-20個時期訓練產生了結果,這表明模型中可能有過度擬合的跡象。另外,我嘗試了LatedNT空間的不同維度,最終dimension = 40產生了最佳結果。最佳維度範圍是16-42之間。
以下資源有助於使這個存儲庫


