flash attention
v2.7.0
該存儲庫提供了以下論文的官方實施閃存和Flashattention-2。
閃存:具有IO意識的快速和記憶力精確的關注
Tri Dao,Daniel Y. Fu,Stefano Ermon,Atri Rudra,ChristopherRé
論文:https://arxiv.org/abs/2205.14135
IEEE Spectrum文章關於我們使用Flashingtention提交給MLPERF 2.0基準的文章。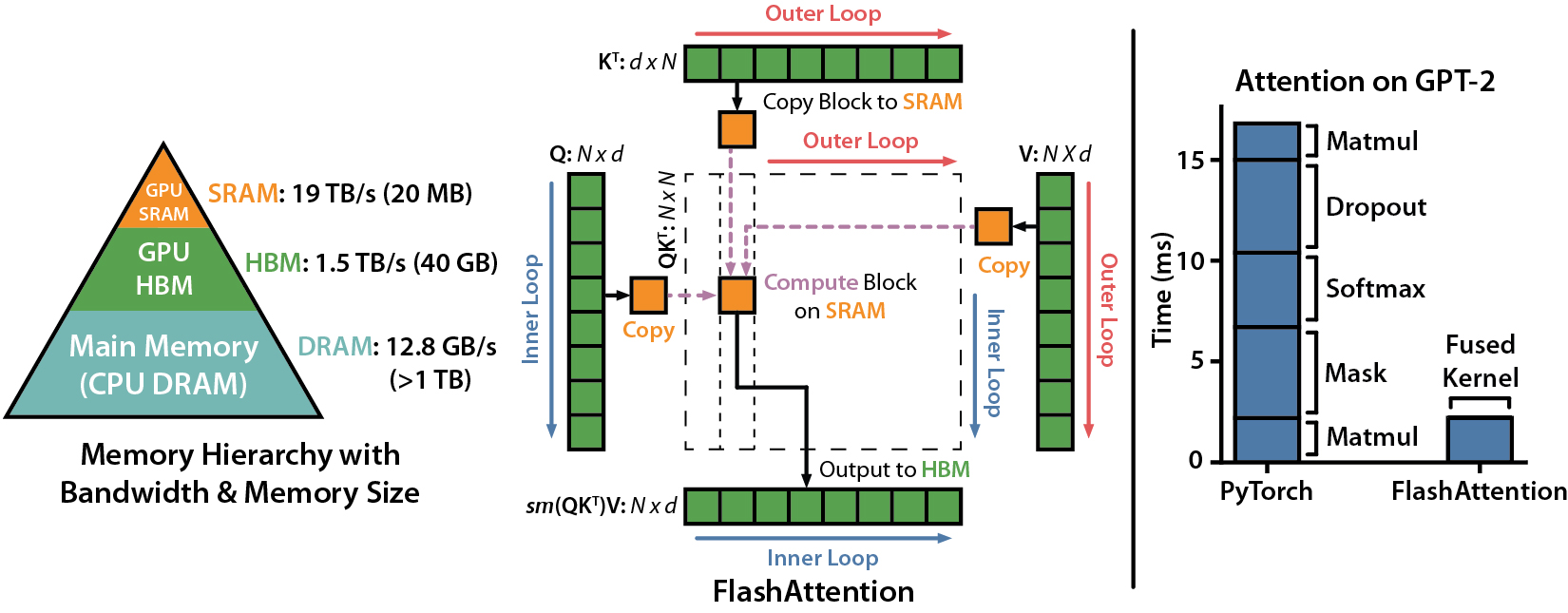
flashattention-2:更快地關注和更好的平行性和工作劃分
Tri Dao
論文:https://tridao.me/publications/flash2/flash2.pdf

我們很高興看到FlashEntion在發布後的短時間內被廣泛採用。此頁麵包含了使用閃光的部分列表。
flashertention和flashattention-2可以免費使用和修改(請參閱許可證)。如果您使用的話,請引用和信用閃存。
Flashattention-3用於Hopper GPU(例如H100)。
Blogpost:https://tridao.me/blog/2024/flash3/
論文:https://tridao.me/publications/flash3/flash3.pdf
在將其與其他存儲庫集成之前,這是用於測試 /基準測試的Beta版本。
目前發布:
要求:H100 / H800 GPU,CUDA> = 12.3。
目前,我們強烈建議CUDA 12.3提高最佳性能。
安裝:
cd hopper
python setup.py install進行測試:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.py要求:
packaging Python軟件包( pip install packaging )ninja Python軟件包( pip install ninja ) * *確保安裝了ninja並正確工作(例如ninja --version ,然後echo $?應該返回出口代碼0)。如果不是(有時是ninja --version ,則echo $?返回非零退出代碼),請卸載,然後重新安裝ninja ( pip uninstall -y ninja && pip install ninja )。沒有ninja ,編譯可能需要很長時間(2H),因為它不使用多個CPU內核。使用CUDA工具包,使用ninja彙編需要3-5分鐘。
安裝:
pip install flash-attn --no-build-isolation或者,您可以從來源進行編譯:
python setup.py install如果您的機器的RAM不到96GB和許多CPU內核, ninja可能會運行太多的平行編譯作業,無法耗盡RAM的數量。為了限制並行彙編作業的數量,您可以設置環境變量MAX_JOBS :
MAX_JOBS=4 pip install flash-attn --no-build-isolation接口: src/flash_attention_interface.py
要求:
我們建議來自NVIDIA的Pytorch容器,該容器具有安裝閃存的所有必需工具。
flashattention-2與CUDA目前支持:
ROCM版本使用Composable_kernel作為後端。它提供了Flashattention-2的實現。
要求:
我們建議來自ROCM的Pytorch容器,該容器具有安裝閃存的所有必需工具。
flashattention-2與ROCM當前支持:
主函數實施縮放點產品的關注(softmax(q @ k^t * softmax_scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""要查看如何在多頭注意層(包括QKV投影,輸出投影)中使用這些功能,請參見MHA實現。
從閃存(1.x)升級到flashattention-2
這些功能已重命名:
flash_attn_unpadded_func > flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func > flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func > flash_attn_varlen_kvpacked_func如果輸入在同一批處理中具有相同的序列長度,則使用這些功能更簡單,更快:
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )如果seqlen_q!= seqlen_k和Causal = true,則將因果面具對齊到注意矩陣的右下角,而不是左上角。
例如,如果seqlen_q = 2 and seqlen_k = 5,則因果面具(1 = keep,0 =蒙版out)為:
v2.0:
1 0 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
如果seqlen_q = 5和seqlen_k = 2,則因果面具為:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
如果掩碼的行全部為零,則輸出為零。
當查詢的序列長度很小(例如查詢序列長度= 1)時,針對推理(迭代解碼)進行優化。這裡的瓶頸是盡可能快地加載KV高速緩存,我們將加載跨不同的螺紋塊分開,並帶有單獨的內核來結合結果。
請參閱功能flash_attn_with_kvcache具有推理功能的更多功能(執行旋轉嵌入,更新KV Cache Inplaph)。
感謝Xformers團隊,尤其是Daniel Haziza的合作。
實現滑動窗口的關注(即,本地關注)。感謝Mistral AI,尤其是TimothéeLacroix的這一貢獻。滑動窗口用於Mistral 7b模型中。
實施不在場證明(Press等,2021)。感謝Kakao Brain的Sanghun Cho的這一貢獻。
實施確定性的向後傳球。感謝Meituan的工程師的這一貢獻。
支持分頁的KV緩存(即,pageDationite)。感謝@beginlner的這一貢獻。
用軟帽支持Gemma-2和Grok Models中的軟覆蓋。感謝@narsil和@lucidrains的這一貢獻。
感謝 @ani300的這一貢獻。
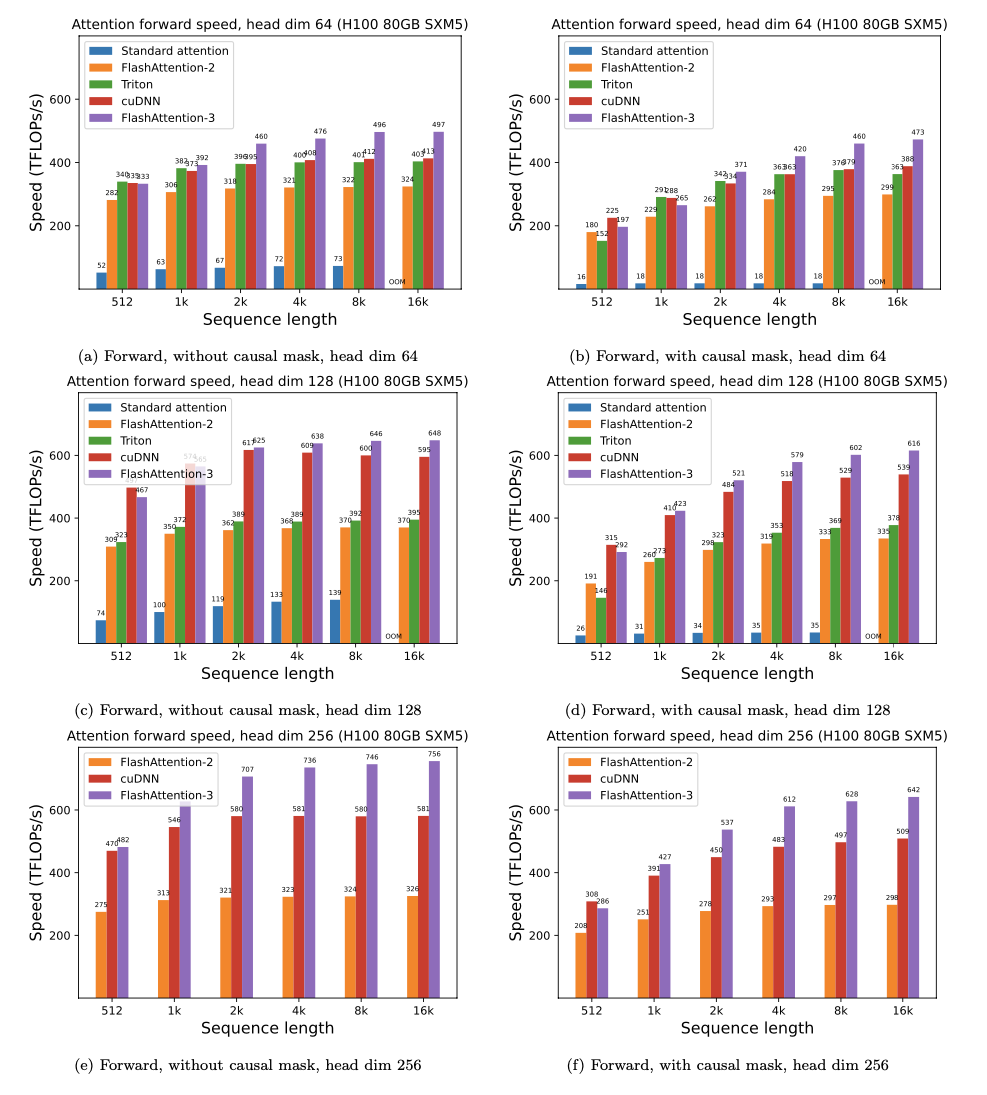
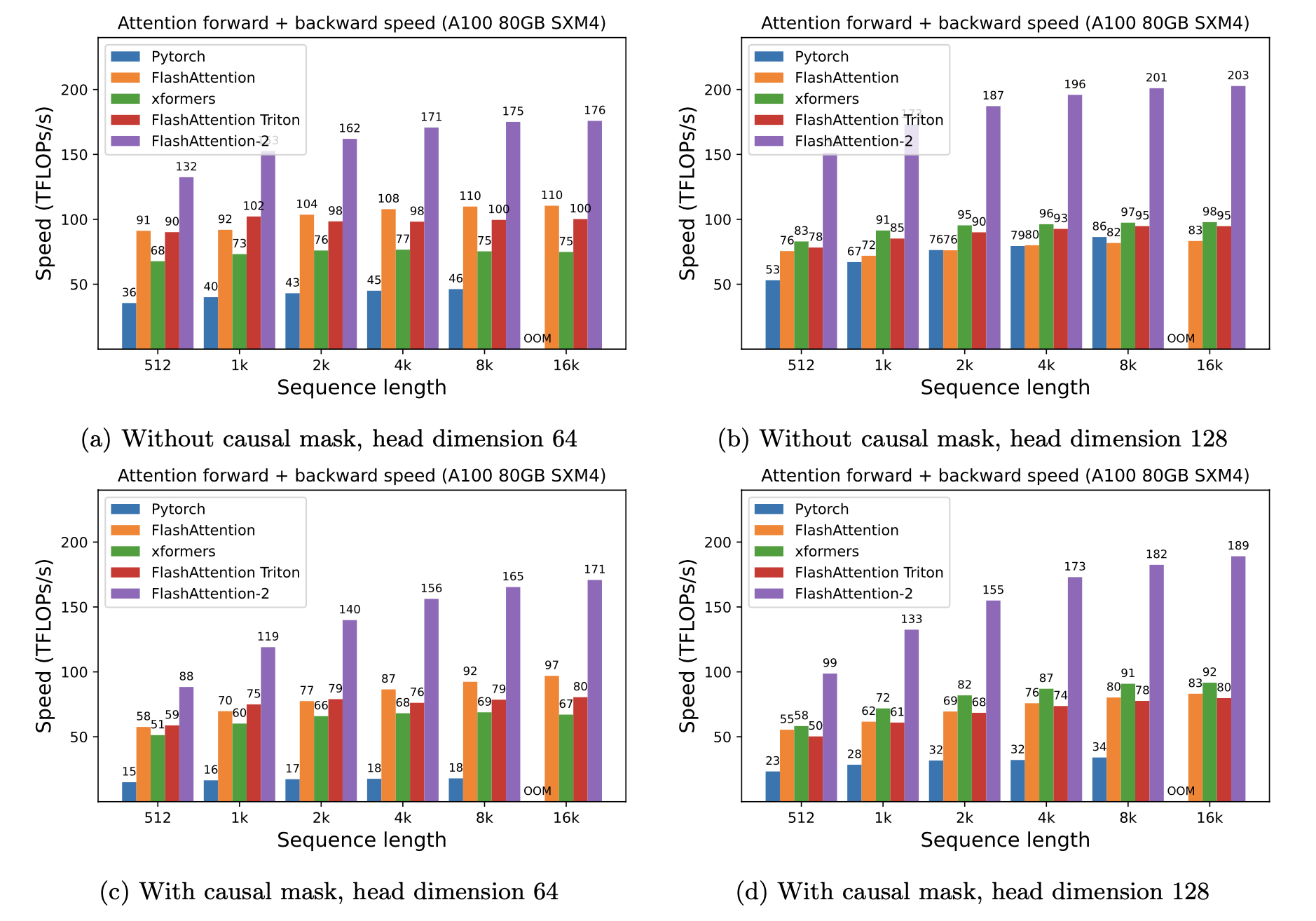
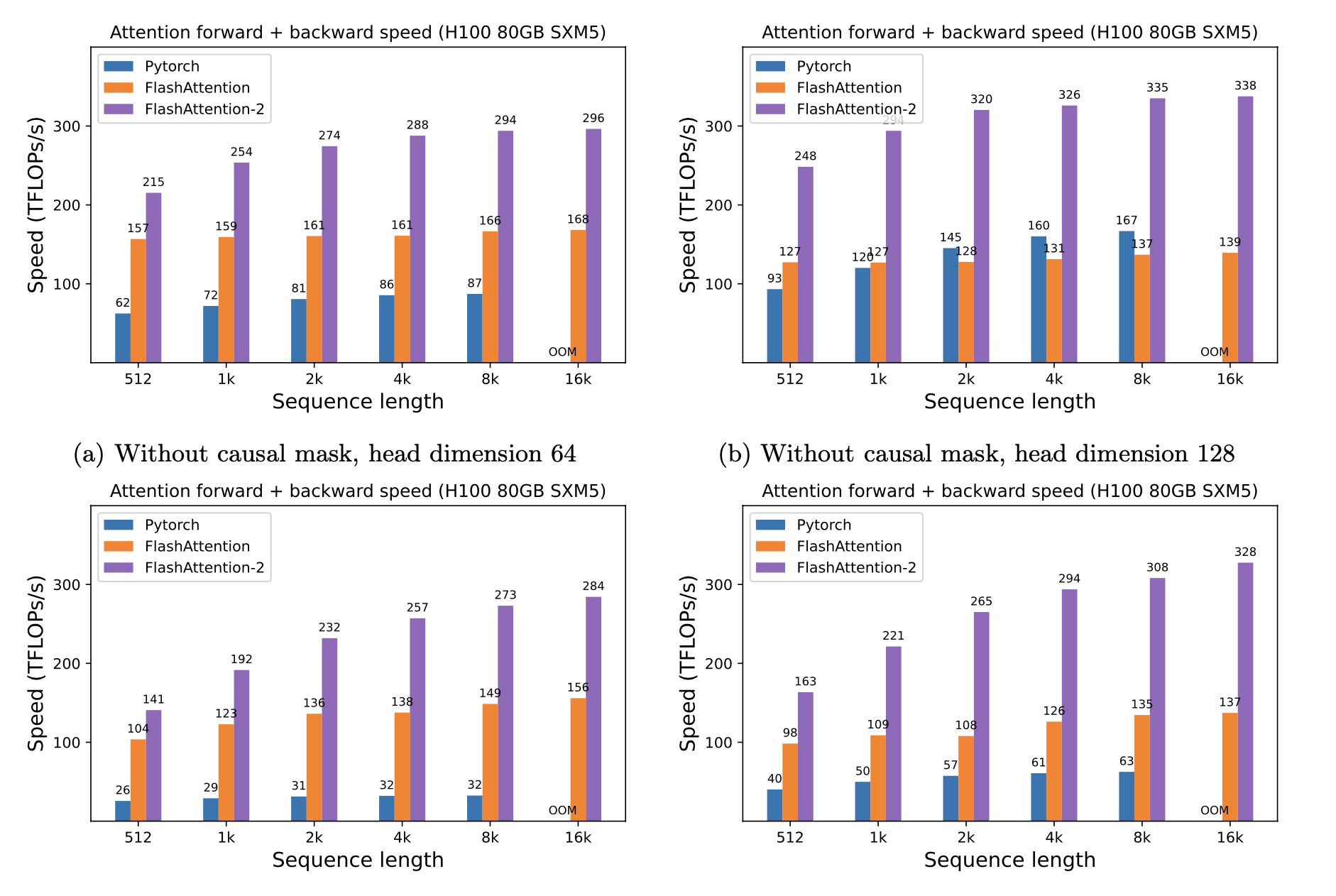
我們提出了預期的加速度(聯合向前+向後通過)和通過使用閃光燈來節省的記憶,這取決於序列長度,取決於序列長度,在不同的GPU上(加速取決於內存帶寬- 我們在較慢的GPU內存上看到了更多的加速GPU內存)。
我們目前有這些GPU的基準:
我們使用以下參數顯示閃存加速:
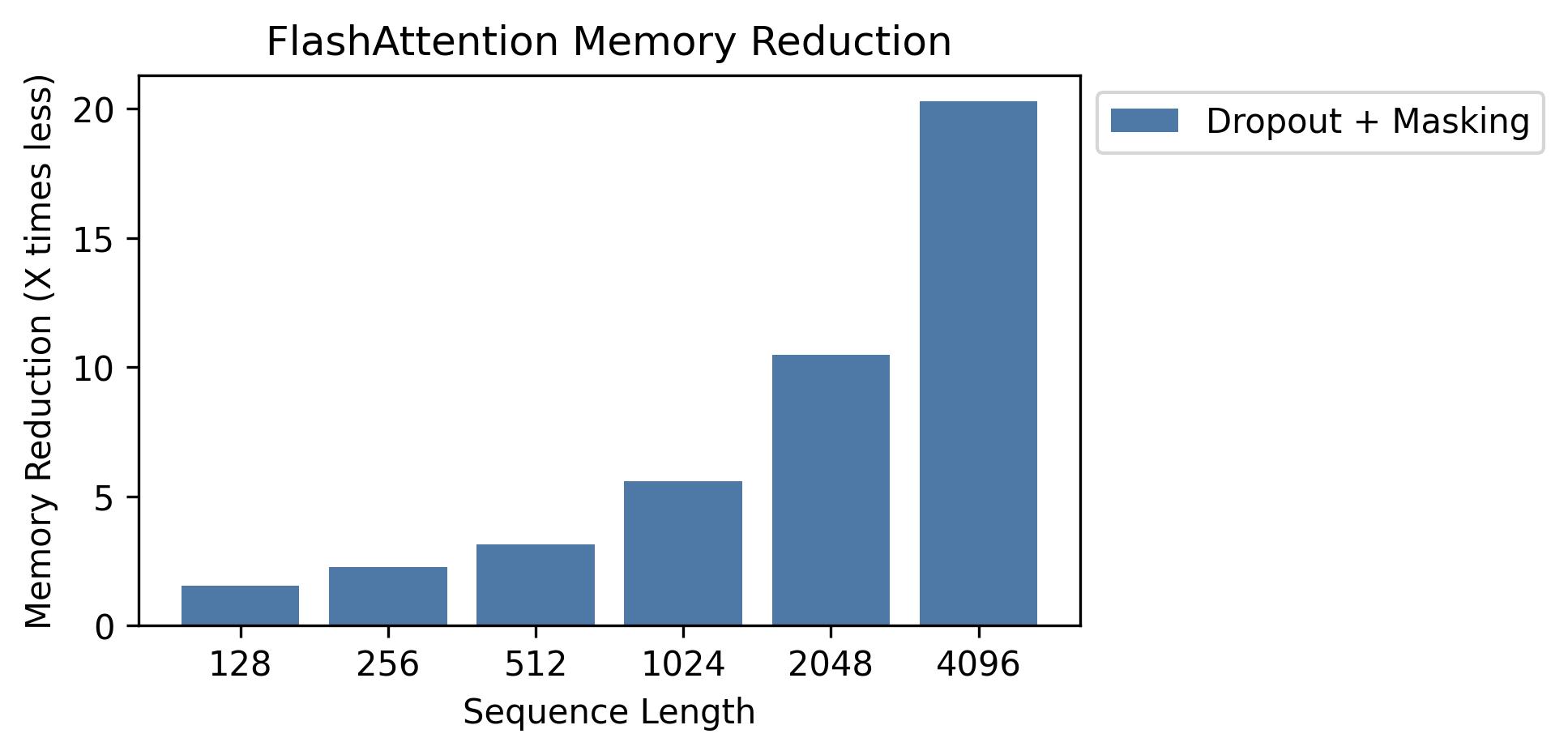
我們在此圖中顯示內存節省(請注意,無論您使用輟學還是掩蔽,內存足跡都是相同的)。存儲器節省與序列長度成正比 - 由於標準注意的內存二次序列長度,而閃存的內存線性為序列長度。我們看到以序列長度為2K的10倍存儲器節省,而在4K處節省了20倍。結果,閃存可以擴展到更長的序列長度。
我們發布了完整的GPT模型實施。我們還提供了其他層的優化實現(例如,MLP,分層,橫向滲透損失,旋轉嵌入)。總體而言,與基線實施相比,每A100的基線實施相比,這加快了3-5倍的速度,相當於72%的型號flops利用率(我們不需要任何激活檢查點)。
我們還包括一個培訓腳本,可以在OpenWebText上培訓GPT2和堆上的GPT3。
Phil Tillet(OpenAi)在Triton中具有閃光的實驗實現:https://github.com/openai/triton/blob/blob/master/python/tutorials/06-fused--Attention.py.py.py.py .py.py.py
由於特里頓(Triton)是一種比cuda更高的語言,因此可能更容易理解和實驗。 Triton實施中的符號也更接近我們論文中使用的內容。
我們還在特里頓(Triton)有一個實驗實現,該實施支持注意力偏見(例如alibi):https://github.com/dao-ailab/flash-abtention/blob/main/main/main/flash_attn /flash_attn/flash_attn_attn_triton.pypypy
我們測試Flashattention會產生與參考實現相同的輸出和梯度,並具有一定的數值公差。特別是,我們檢查閃光的最大數值誤差最多是Pytorch中基線實現的數值誤差的兩倍(對於不同的頭尺寸,輸入DTYPE,序列長度,因果 /非療法)。
進行測試:
pytest -q -s tests/test_flash_attn.pyFlashattention-2的新版本已在多種GPT風格的型號上進行了測試,主要是在A100 GPU上進行測試。
如果遇到錯誤,請打開一個GitHub問題!
進行測試:
pytest tests/test_flash_attn_ck.py如果您使用此代碼庫,或者以其他方式發現我們的工作很有價值,請引用:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


