LLaMA Omni
1.0.0
作者:Qingkai Fang,Shoutao Guo,Yan Zhou,Zhengrui MA,Shaolei Zhang,Yang Feng*
Llama-Omni是基於Llama-3.1-8B教學的語音語言模型。它支持低延遲和高質量的語音互動,同時根據語音說明產生文本和語音回答。
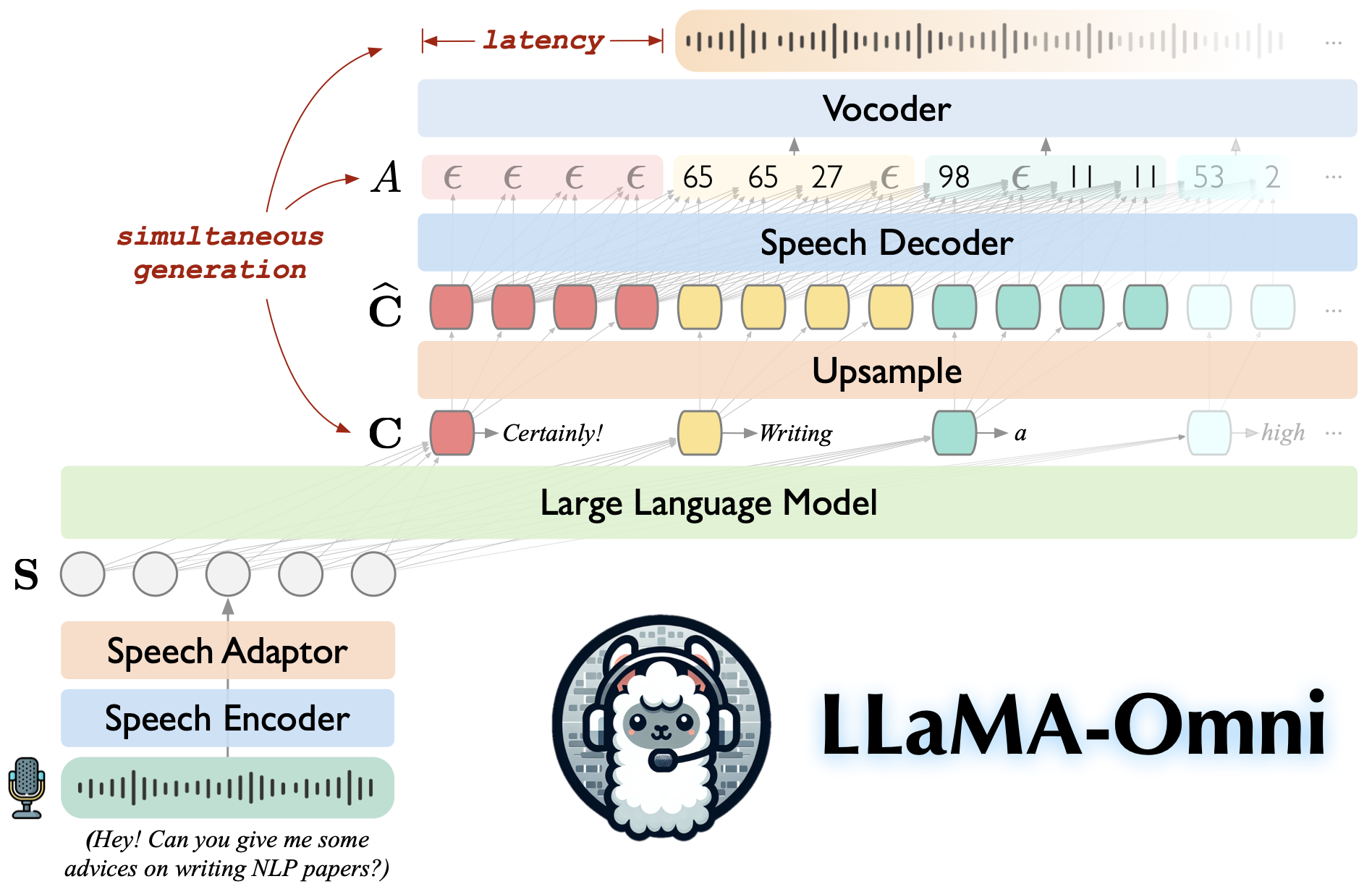
建立在Llama-3.1-8B-Instruct上,確保高質量的反應。
低延遲語音相互作用,潛伏期低至226ms。
同時產生文本和語音回答。
♻️在不到3天的時間內使用4 GPU培訓。
克隆這個存儲庫。
git克隆https://github.com/ictnlp/llama-omnicd llama-omni
安裝軟件包。
conda create -n Llama -omni Python = 3.10 conda激活駱駝 - 莫尼 PIP安裝PIP == 24.0 PIP安裝-e。
安裝fairseq 。
git克隆https://github.com/pytorch/fairseqcd fairseq PIP安裝-e。 - 非建造式
安裝flash-attention 。
pip安裝flash-attn-不建立隔離
從HuggingFace下載Llama-3.1-8B-Omni模型。
下載Whisper-large-v3型號。
導入耳語 型號= whisper.load_model(“ groun-v3”,download_root =“型號/secement_encoder/”)
下載基於單元的Hifi-Gan Vocoder。
WGET https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_400k_layer11_km1000_km1000_lj/g_00500000 -p votoder/ wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_400k_layer11_km1000_km1000_lj/config.json -pocoder/pocoder/pocoder/pocoder/
啟動控制器。
python -m omni_speech.serve.controller-主機0.0.0.0-port 10000
啟動Gradio Web服務器。
python -M omni_speech.serve.gradio_web_server -controller http:// localhost:10000 -port 8000 -model-list-mode reload-vocoder-vocoder vocoder/g_00500000 -
啟動模型工人。
python -m omni_speech.serve.model_worker - 霍斯特0.0.0.0- controller http:// localhost:10000 -port 40000 - worker http:// localhost:40000-model-model-path llama-3.1-3.1-8B- 8B-8B-8B-8B-8B-8B-8B-omni -Model-name Llama-3.1-8b-omni -S2S
訪問http:// localhost:8000/,並與Llama-3.1-8b-omni互動!
注意:由於Gradio中流音頻播放的不穩定,我們僅在不啟用自動播放的情況下實現了流音頻綜合。如果您有一個好的解決方案,請隨時提交PR。謝謝!
要在本地運行推斷,請根據omni_speech/infer/examples目錄中的格式組織語音說明文件,然後參考以下腳本。
bash omni_speech/peash/run.sh omni_speech/peash/示例
我們的代碼在Apache-2.0許可下發布。我們的模型僅用於學術研究目的,不得用於商業目的。
您可以在學術環境中自由使用,修改和分發此模型,只要滿足以下條件:
非商業用途:該模型不得用於任何商業目的。
引用:如果您在研究中使用此模型,請引用原始工作。
有關任何商業用途查詢或獲得商業許可證,請聯繫[email protected] 。
Llava:我們構建的代碼庫。
SLAM-LLM:我們藉一些有關語音編碼器和語音適配器的代碼。
如果您有任何疑問,請隨時提交問題或聯繫[email protected] 。
如果我們的工作對您有用,請引用:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

