Marketing Attribution Models
1.0.10
Python班級創建的旨在解決有關數字營銷歸因的問題。
在線瀏覽時,用戶在轉換之前具有多個接觸點,這可能會導致更長,更複雜的旅程。
如何適當的信用轉換並選擇對媒體的投資?
為此,我們應用歸因模型。
啟發式模型:
上次交互:
Gogle Analytics和其他媒體平台(例如Google Ads和Facebook Business Manager)中的默認歸因;
只有最後一個接觸點才能歸功於轉換。
上次點擊非直接:
所有直接流量都被忽略了,因此結果的100%進入了客戶在轉換之前訪問網站的最後一個渠道。
第一次交互:
結果完全歸因於第一個接觸點。
線性:
每個接觸點都同樣值得注意。
時間衰減:
最近的一個接觸點越多,獲得的信譽就越多。
位置:
在該模型中,結果的40%歸因於最後一個接觸點,第一個接觸點又歸因於第一個接觸點,其餘20%平均分佈在中途通道之間。
算法模型
沙普利價值
在遊戲理論中,此值是對合作遊戲中每個玩家的貢獻的估計。
通過將旅程的過程歸功於渠道。在每個排列中,都會給出一個通道,以估計其整體上的實質性。
例如,讓我們看一下以下四義旅程:
有機搜索> Facebook>直接> $ 19 (作為收入)
為了獲取每個頻道的沙普利價值,我們首先需要考慮此給定旅程的組件排列的所有轉換值。
有機搜索> $ 7
Facebook> 6美元
直接> $ 4
有機搜索> Facebook> 15美元
有機搜索>直接> $ 7
Facebook> Direct> 9美元
有機搜索> Facebook>直接> 19美元
組件joneys的數量呈指數增加,您擁有的較截然不同的通道:對於n通道,速率為2^n(n的功率為2)。
換句話說,有3個不同的接觸點有8個排列。例如,超過15個過程是不可行的。
默認情況下,在計算莎普利價值時,僅考慮接觸點的順序,只有它們的存在或缺乏。為此,排列數量增加。
考慮到這一點,請注意,在考慮交互的順序時,很難使用此模型。對於n個通道,不僅有給定通道I的2^n排列,而且還存在包含不同位置的所有置換。
沙普利價值的一些問題和局限性
馬爾可夫鏈是馬爾可夫鍊是一個特定的隨機過程,在該過程中,任何下一個狀態的概率分佈僅取決於當前狀態,而無視任何先前狀態及其序列。
在多通道屬性中,我們可以使用馬爾可夫鏈來計算媒體通道對與過渡矩陣之間的相互作用的概率。
關於每個通道在轉換方面的貢獻,刪除效果提出:對於每個jorney,刪除了給定的通道併計算了轉換概率。
因此,歸因於通道的值是通過轉換概率與一旦所述通道在一般概率上刪除的概率之間差的比率獲得的。
換句話說,頻道的去除效果越大,其貢獻就越大。
**使用馬爾可夫流程時,由於通道的數量或順序,沒有限制。它們的順序本身是該算法的基本組成部分。
>> pip install marketing_attribution_models from marketing_attribution_models import MAM 創建MAM對象時,兩個數據框架模板可以用作輸入,這取決於參數group_channels的值是什麼。
對於此解釋,我們將使用一個數據框架,其中尚未將旅程分組,每行都是不同的會話,沒有唯一的旅程ID。
注意: MAM類具有用於旅程ID創建的內置參數, create_journey_id_id_based_on_conversion ,如果為true ,則根據用戶ID創建ID,在group_channels_id_list參數中輸入,而列表示轉換是否有其轉換,名稱由瀏覽_WITH_CONV_COLNAME參數定義。
在這種情況下,將訂購每個不同用戶的所有會話,對於每次轉換,都會創建新的旅程ID。但是,我們強烈鼓勵此旅程ID創建是根據手頭和探索性結論的知識來定制的。例如,如果在給定的業務中註意到,平均旅行時間約為一周,則可以定義新的評論者,以便一旦任何用戶在7天內沒有任何互動,則在假設損失的假設下,旅程中斷感興趣的。
至於現在的參數,以下是它們為我們的group_ channels配置它們的方式= true方案:
attributions = MAM ( df ,
group_channels = True ,
channels_colname = 'channels' ,
journey_with_conv_colname = 'has_transaction' ,
group_channels_by_id_list = [ 'user_id' ],
group_timestamp_colname = 'visitStartTime' ,
create_journey_id_based_on_conversion = True )為了探索和理解MAM的功能,通過使用Random_DF參數設置為true來實現“隨機數據幀發生器”。
attributions = MAM ( random_df = True )創建對象MAM之後,我們可以通過添加我們的rowent_id並使用屬性“ .dataframe”來查看數據庫。
attributions . DataFrame| outhere_id | channels_agg | time_till_conv_agg | converted_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID:0_J:0 | 0.0 | 真的 | 1 | |
| 1 | ID:0_J:1 | Google搜索 | 0.0 | 真的 | 1 |
| 2 | ID:0_J:10 | Google搜索>有機>電子郵件營銷 | 72.0> 24.0> 0.0 | 真的 | 1 |
| 3 | ID:0_J:11 | 有機的 | 0.0 | 真的 | 1 |
| 4 | ID:0_J:12 | 電子郵件營銷> Facebook | 432.0> 0.0 | 真的 | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID:9_J:5 | 直接> Facebook | 120.0> 0.0 | 真的 | 1 |
| 20342 | ID:9_J:6 | Google搜索> Google搜索> Google搜索 | 48.0> 24.0> 0.0 | 真的 | 1 |
| 20343 | ID:9_J:7 | 有機>有機> Google搜索> Google搜索 | 480.0> 480.0> 288.0> 0.0 | 真的 | 1 |
| 20344 | ID:9_J:8 | 直接>有機 | 168.0> 0.0 | 真的 | 1 |
| 20345 | ID:9_J:9 | Google搜索>有機> Google搜索> EMAI ... | 528.0> 528.0> 408.0> 240.0> 0.0 | 真的 | 1 |
為生成的每個歸因模型更新此屬性。僅在啟發式模型的情況下,一個新列附加了一個包含所述模型給出的歸因值。
注意:屬性.dataframe不會干擾任何模型計算。如果使用情況會改變,則以下結果不會受到影響。
attributions . attribution_last_click ()
attributions . DataFrame| outhere_id | channels_agg | time_till_conv_agg | converted_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID:0_J:0 | 0.0 | 真的 | 1 | |
| 1 | ID:0_J:1 | Google搜索 | 0.0 | 真的 | 1 |
| 2 | ID:0_J:10 | Google搜索>有機>電子郵件營銷 | 72.0> 24.0> 0.0 | 真的 | 1 |
| 3 | ID:0_J:11 | 有機的 | 0.0 | 真的 | 1 |
| 4 | ID:0_J:12 | 電子郵件營銷> Facebook | 432.0> 0.0 | 真的 | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID:9_J:5 | 直接> Facebook | 120.0> 0.0 | 真的 | 1 |
| 20342 | ID:9_J:6 | Google搜索> Google搜索> Google搜索 | 48.0> 24.0> 0.0 | 真的 | 1 |
| 20343 | ID:9_J:7 | 有機>有機> Google搜索> Google搜索 | 480.0> 480.0> 288.0> 0.0 | 真的 | 1 |
| 20344 | ID:9_J:8 | 直接>有機 | 168.0> 0.0 | 真的 | 1 |
| 20345 | ID:9_J:9 | Google搜索>有機> Google搜索> EMAI ... | 528.0> 528.0> 408.0> 240.0> 0.0 | 真的 | 1 |
通常,使用的數據量是廣泛的,因此不切實際甚至不可能分析歸因於每次交易旅程的結果。但是,使用屬性group_by_channels_models ,所有結果都可以通過頻道進行分組。
注意:如果在兩個不同的實例中使用相同的模型,則分組結果不會互相覆蓋。它們(甚至更多)都在“ group_by_channels_models ”中顯示。
attributions . group_by_channels_models| 頻道 | attribution_last_click_heuristic |
|---|---|
| 直接的 | 2133 |
| 電子郵件營銷 | 1033 |
| 3168 | |
| Google顯示 | 1073 |
| Google搜索 | 4255 |
| 1028 | |
| 有機的 | 6322 |
| Youtube | 1093 |
與.dataframe屬性一樣,對於使用算法結果的每個模型也可以更新group_by_by_channels_models 。
attributions . attribution_shapley ()
attributions . group_by_channels_models| 頻道 | attribution_last_click_heuristic | attribution_shapley_size4_conv_rate_algorithmic | |
|---|---|---|---|
| 0 | 直接的 | 109 | 74.926849 |
| 1 | 電子郵件營銷 | 54 | 70.558428 |
| 2 | 160 | 160.628945 | |
| 3 | Google顯示 | 65 | 110.649352 |
| 4 | Google搜索 | 193 | 202.179519 |
| 5 | 64 | 72.982433 | |
| 6 | 有機的 | 315 | 265.768549 |
| 7 | Youtube | 58 | 60.305925 |
如前所述,使用屬性.dataframe和.group_by_channels_models時,所有啟發式模型都相同,如前所述,所有啟發式模型的方法的輸出返回了一個包含兩個pandas系列的元組。
attribution_first_click = attributions . attribution_first_click ()元組的第一個系列是旅程粒度的結果,類似於.dataframe屬性中觀察到的結果
attribution_first_click [ 0 ] 0 [1, 0, 0, 0, 0]
1 [1]
2 [1, 0, 0, 0, 0, 0, 0, 0, 0]
3 [1, 0]
4 [1]
...
20512 [1, 0]
20513 [1, 0, 0]
20514 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
20515 [1, 0, 0]
20516 [1, 0, 0, 0]
Length: 20517, dtype: object
第二個包含帶有通道粒度的結果,如.group_by_channels_models屬性所示。
attribution_first_click [ 1 ]| 頻道 | attribution_first_click_heuristic | |
|---|---|---|
| 0 | 直接的 | 2078 |
| 1 | 電子郵件營銷 | 1095 |
| 2 | 3177 | |
| 3 | Google顯示 | 1066 |
| 4 | Google搜索 | 4259 |
| 5 | 1007 | |
| 6 | 有機的 | 6361 |
| 7 | Youtube | 1062 |
在對象MAM中存在的所有模型中,僅上一次單擊,首先單擊和線性沒有可自定義的參數,但是group_by_channels_models ,該參數具有布爾值,該值將設置為false時,該模型不會返回通道對false的歸屬。
創建的目的是複制Google Analytics的默認屬性(上次點擊非直接),在此,如果先前的介學在給定的時間板上具有直接的特定流量來源,則直接流量被覆蓋了(默認情況下為6個月)。
如果未指定,則參數but_not_this_channel設置為“直接” ,但可以將其設置為業務的任何其他感興趣的渠道。
attributions . attribution_last_click_non ( but_not_this_channel = 'Direct' )[ 1 ]| 頻道 | attribution_last_click_non_direct_heuristic | |
|---|---|---|
| 0 | 直接的 | 11 |
| 1 | 電子郵件營銷 | 60 |
| 2 | 172 | |
| 3 | Google顯示 | 69 |
| 4 | Google搜索 | 224 |
| 5 | 67 | |
| 6 | 有機的 | 350 |
| 7 | Youtube | 65 |
該模型具有一個參數list_positions_first_middle_last ,其中每個旅程中頻道位置的權重可以根據與業務相關的決策指定。引入通道的參數的默認分佈為40% ,轉換 /最後一個通道的默認分佈為40% ,在層間通道中為20% 。
attributions . attribution_position_based ( list_positions_first_middle_last = [ 0.3 , 0.3 , 0.4 ])[ 1 ]| 頻道 | attribution_position_based_0.3_0.3_0.4_heuristic | |
|---|---|---|
| 0 | 直接的 | 95.685085 |
| 1 | 電子郵件營銷 | 57.617191 |
| 2 | 145.817501 | |
| 3 | Google顯示 | 56.340693 |
| 4 | Google搜索 | 193.282305 |
| 5 | 54.678557 | |
| 6 | 有機的 | 288.148896 |
| 7 | Youtube | 55.629772 |
有兩個可自定義的設置:衰減率,throght decay_over_time *參數,以及每個decaiment之間通過頻率參數之間的時間(小時)。
但是,值得注意的是,如果頻率間隔之間存在多個接觸點,則轉換值將平均分佈在這些通道之間。
例如:
attributions . attribution_time_decay (
decay_over_time = 0.6 ,
frequency = 7 )[ 1 ]| 頻道 | attribution_time_decay0.6_freq7_heuristic | |
|---|---|---|
| 0 | 直接的 | 108.679538 |
| 1 | 電子郵件營銷 | 54.425914 |
| 2 | 159.592216 | |
| 3 | Google顯示 | 64.350107 |
| 4 | Google搜索 | 192.838844 |
| 5 | 64.611414 | |
| 6 | 有機的 | 314.920082 |
| 7 | Youtube | 58.581845 |
uppon被稱為,該型號返回帶有四個組件的元組。前兩個(索引0和1)就像啟發式模型一樣,分別代表.dataframe和.group_by_channels_models 。至於第三組和第四個組件(索引2和3),結果是過渡矩陣和去除效應表。
首先,可以指示是否考慮相同的狀態轉換(例如直接直接)。
attribution_markov = attributions . attribution_markov ( transition_to_same_state = False )| 頻道 | attribution_markov_algorithmic | |
|---|---|---|
| 0 | 直接的 | 2305.324362 |
| 1 | 電子郵件營銷 | 1237.400774 |
| 2 | 3273.918832 | |
| 3 | Youtube | 1231.183938 |
| 4 | Google搜索 | 4035.260685 |
| 5 | 1205.949095 | |
| 6 | 有機的 | 5358.270644 |
| 7 | Google顯示 | 1213.691671 |
此配置不會影響每個通道的總體歸因結果,而是在過渡矩陣中觀察到的值。因為我們將Transition_TO_SAME_STATE設置為false ,所以表明狀態過渡到自己的對角線是無效的。
ax , fig = plt . subplots ( figsize = ( 15 , 10 ))
sns . heatmap ( attribution_markov [ 2 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )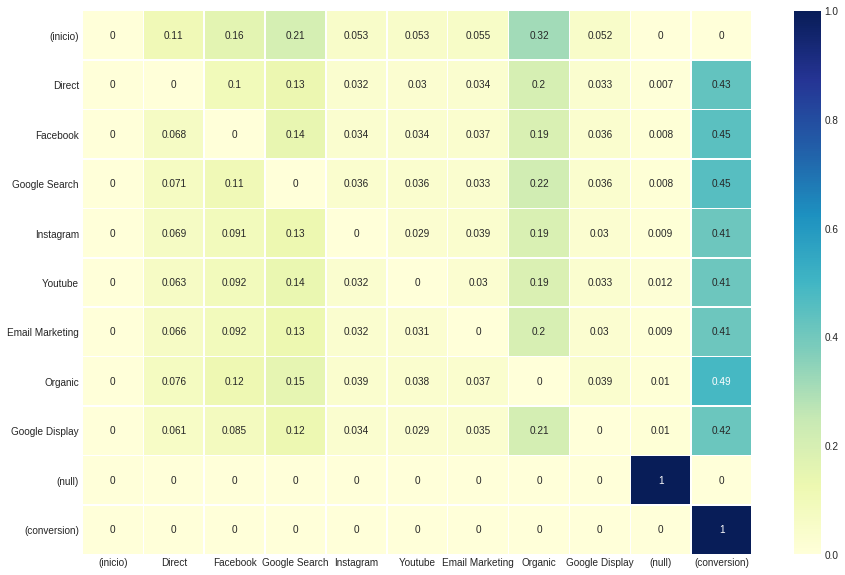
去除效果是第四屬性_Markov輸出,是通過轉換概率與一度概率之間的差異的比率獲得的,曾經在一般概率上刪除了該通道。
ax , fig = plt . subplots ( figsize = ( 2 , 5 ))
sns . heatmap ( attribution_markov [ 3 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )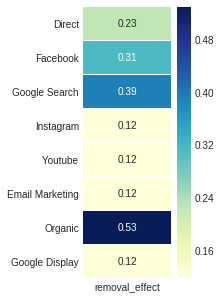
最後, MAM的第二個算法模型來自遊戲理論。這裡的目的是在使用有或沒有給定渠道的旅程組合計算的合作遊戲中分發每個玩家(在我們的情況下)的貢獻(在我們的情況下)。
參數大小定義了每次旅程中一系列通道鏈的限制。默認情況下,它的值設置為4 ,這意味著僅考慮轉換之前的最後四個通道。
每個通道的邊際貢獻的計算方法可以隨階參數而變化。默認情況下,它設置為false ,這意味著計算出貢獻,無視旅程中每個通道的順序。
attributions . attribution_shapley ( size = 4 , order = True , values_col = 'conv_rate' )[ 0 ]| 組合 | 轉換 | total_ sequences | conversion_value | cons_rate | attribution_shapley_size4_conv_rate_order_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | 直接的 | 909 | 926 | 909 | 0.981641 | [909.0] |
| 1 | 直接>電子郵件營銷 | 27 | 28 | 27 | 0.964286 | [13.948270234099155,13.051729765900845] |
| 2 | 直接>電子郵件營銷> Facebook | 5 | 5 | 5 | 1.000000 | [1.663666232390172,1.583583671498818,1.752 ... |
| 3 | 直接>電子郵件營銷> Facebook> Google D ... | 1 | 1 | 1 | 1.000000 | [0.2563402919193473,0.23455607999963515,0.259 ... |
| 4 | 直接>電子郵件營銷> Facebook> Google S ... | 1 | 1 | 1 | 1.000000 | [0.2522517802130265,0.2401286956930936,0.255 ... |
| ... | ... | ... | ... | ... | ... | ... |
| 1278 | YouTube>有機> Google搜索> Google dis ... | 1 | 2 | 1 | 0.500000 | [0.2514214624662836,0.24872101523605275,0.24 ... |
| 1279 | YouTube>有機> Google搜索> Instagram | 1 | 1 | 1 | 1.000000 | [0.2544401477637237,0.2541071889956603,0.253 ... |
| 1280 | YouTube>有機> Instagram | 4 | 4 | 4 | 1.000000 | [1.2757196742326997,1.4712839059493295,1.252 ... |
| 1281 | YouTube>有機> Instagram> Facebook | 1 | 1 | 1 | 1.000000 | [0.2357631944623868,0.2610913781266248,0.247 ... |
| 1282 | YouTube>有機> Instagram> Google搜索 | 3 | 3 | 3 | 1.000000 | [0.7223482210689489,0.7769049003203142,0.726 ... |
最後,指示用於計算shapley值的參數是values_col ,默認情況下將其設置為轉換率。這樣,沒有轉換的旅程就會進入acount。
但是,在使用模型時,有可能僅考慮字面轉換。
attributions . attribution_shapley ( size = 3 , order = False , values_col = 'conversions' )[ 0 ]| 組合 | 轉換 | total_ sequences | conversion_value | cons_rate | attribution_shapley_size3_conversions_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | 直接的 | 11 | 18 | 18 | 0.611111 | [11.0] |
| 1 | 直接>電子郵件營銷 | 4 | 5 | 5 | 0.800000 | [2.0,2.0] |
| 2 | 直接>電子郵件營銷> Google搜索 | 1 | 2 | 2 | 0.500000 | [-3.166666666666665,-7.666666666666666,11.8 ... |
| 3 | 直接>電子郵件營銷>有機 | 4 | 6 | 6 | 0.666667 | [-7.833333333333333,-10.833333333333332,22.6 ... |
| 4 | 直接> Facebook | 3 | 4 | 4 | 0.750000 | [-8.5,11.5] |
| ... | ... | ... | ... | ... | ... | ... |
| 75 | Instagram>有機> YouTube | 46 | 123 | 123 | 0.373984 | [5.83333333333332,34.33333333333333,5.83333 ... |
| 76 | Instagram> YouTube | 2 | 4 | 4 | 0.500000 | [2.0,0.0] |
| 77 | 有機的 | 64 | 92 | 92 | 0.695652 | [64.0] |
| 78 | 有機> YouTube | 8 | 11 | 11 | 0.727273 | [30.5,-22.5] |
| 79 | Youtube | 11 | 15 | 15 | 0.733333 | [11.0] |
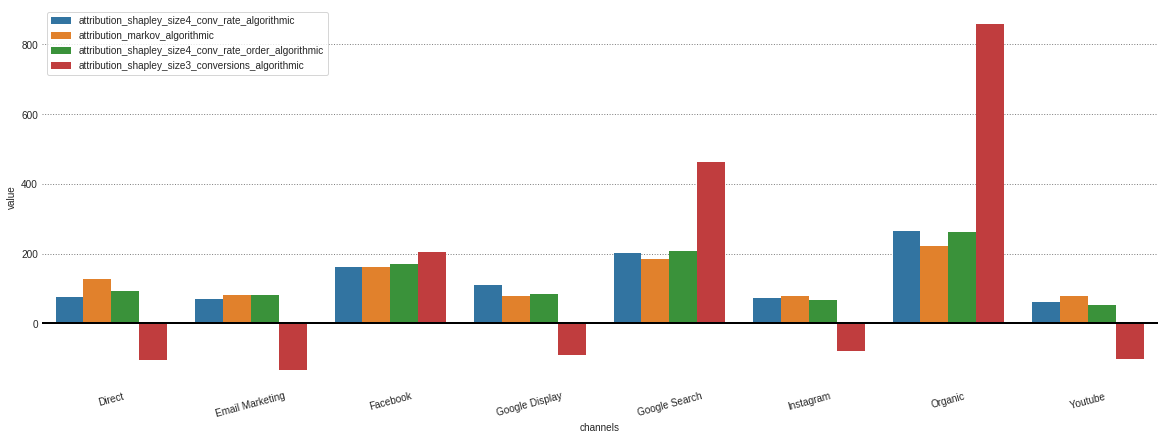
從我們的.group_by_channels_models對像中獲取了存儲的不同模型的所有歸因之後,可以繪製和比較洞察力的結果
attributions . plot ()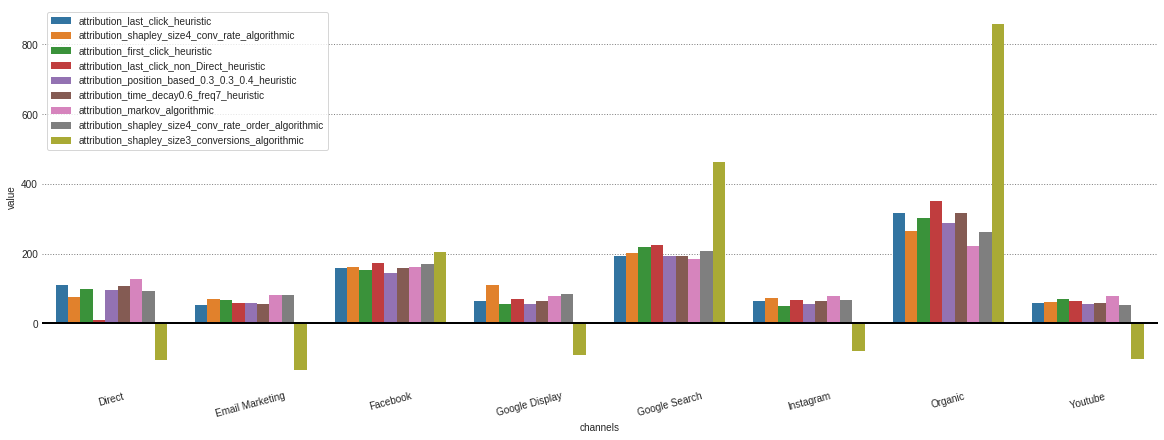
如果您只對算法模型感興趣,那麼我可以在model_type參數中指定。
attributions . plot ( model_type = 'algorithmic' )