text embeddings inference
v1.5.1
文本嵌入模型的燃燒快速推理解決方案。
Baai/BGE-BASE-EN-V1.5的基准在NVIDIA A10上,序列長度為512令牌:
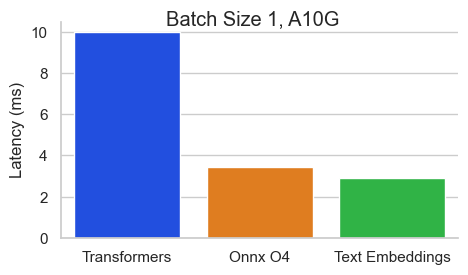
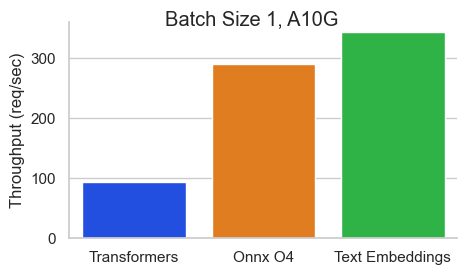
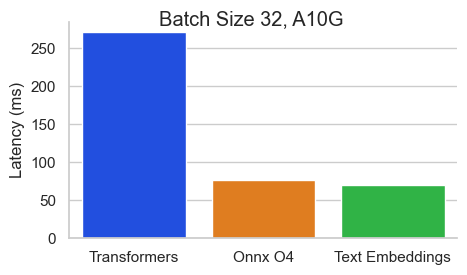
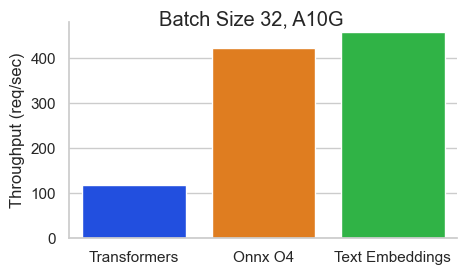
文本嵌入推理(TEI)是用於部署和服務開源文本嵌入和序列分類模型的工具包。 TEI可以為最受歡迎的模型,包括FlageMbedding,Ember,GTE和E5提供高性能提取。 TEI實現了許多功能,例如:
文本嵌入式推斷當前支持具有絕對位置的Nemic,Bert,Camembert,XLM-Roberta模型,具有alibi位置的Jinabert模型和Mistral,Alibaba GTE和Qwen2模型,具有繩索位置。
以下是當前支持模型的一些示例:
| MTEB等級 | 型號大小 | 型號類型 | 模型ID |
|---|---|---|---|
| 1 | 7b(非常昂貴) | Mistral | Salesforce/sfr-embedding-2_r |
| 2 | 7b(非常昂貴) | qwen2 | Alibaba-NLP/GTE-QWEN2-7B-INSTRUCT |
| 9 | 1.5B(昂貴) | qwen2 | Alibaba-NLP/GTE-QWEN2-1.5B-INSTRUCT |
| 15 | 0.4b | 阿里巴巴GTE | Alibaba-NLP/GTE-LARGE-EN-V1.5 |
| 20 | 0.3b | 伯特 | withisai/aue-large-v1 |
| 24 | 0.5B | XLM-Roberta | intfloat/多語言 - E5大型教學 |
| N/A。 | 0.1b | nomicbert | 提名 - ai/nomic-embed-text-v1 |
| N/A。 | 0.1b | nomicbert | 提名-AI/提名 - Embed-Text-V1.5 |
| N/A。 | 0.1b | Jinabert | jinaai/jina-embeddings-v2-base-en |
| N/A。 | 0.1b | Jinabert | jinaai/jina-embeddings-v2基本代碼 |
要探索最佳性能的文本嵌入式模型列表,請訪問大量的文本嵌入式基準(MTEB)排行榜。
文本嵌入推理當前支持Camembert,並且具有絕對位置的XLM-Roberta序列分類模型。
以下是當前支持模型的一些示例:
| 任務 | 型號類型 | 模型ID |
|---|---|---|
| 重新排列 | XLM-Roberta | baai/bge-reranker-large |
| 重新排列 | XLM-Roberta | baai/bge-reranker bas |
| 重新排列 | GTE | Alibaba-NLP/GTE-Multlityal-Reranker-base |
| 情感分析 | 羅伯塔 | samlowe/roberta-base-go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model然後您可以提出要求
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json '注意:要使用GPU,您需要安裝NVIDIA容器工具包。機器上的NVIDIA驅動程序必須與CUDA版本12.2或更高版本兼容。
要查看所有服務於您的模型的選項:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
帶有多個Docker圖像的文本嵌入式推理船隻,您可以用來針對特定的後端:
| 建築學 | 圖像 |
|---|---|
| 中央處理器 | ghcr.io/huggingface/text-embeddings-inference:Cpu-1.5 |
| Volta | 不支持 |
| 圖靈(T4,RTX 2000系列,...) | ghcr.io/huggingface/text-embeddings-inference:Turing-1.5(實驗) |
| 安培80(A100,A30) | ghcr.io/huggingface/text-embeddings-inference:1.5 |
| 安培86(A10,A40,...) | ghcr.io/huggingface/text-embeddings-inference:86-1.5 |
| Ada Lovelace(RTX 4000系列,...) | ghcr.io/huggingface/text-embeddings-inference:89-1.5 |
| 料斗(H100) | ghcr.io/huggingface/text-embeddings-inference:Hopper-1.5(實驗) |
警告:默認情況下,圖靈圖像遇到了精確問題,默認情況下關閉了閃光注意力。您可以使用USE_FLASH_ATTENTION=True Environment變量來打開Flash注意力V1。
您可以使用/docs路由諮詢text-embeddings-inference REST API的OpenAPI文檔。 Swagger UI也可在以下網址獲得:https://huggingface.github.io/text-embeddings-inference。
您可以選擇使用HF_API_TOKEN環境變量來配置text-embeddings-inference使用的令牌。這使您可以訪問受保護的資源。
例如:
HF_API_TOKEN=<your cli READ token>或與Docker:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model要在氣動環境中部署文本嵌入推斷,請首先下載權重,然後使用音量將其安裝在容器中。
例如:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5text-embeddings-inference V0.4.0增加了對Camembert,Roberta,XLM-Roberta和GTE序列分類模型的支持。重新率模型是序列分類的跨編碼器模型,其單個類別得分查詢和文本之間的相似性。
請參閱LlamainDex團隊的此博客文章,以了解如何在RAG管道中使用重新級別的模型來提高下游性能。
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model然後,您可以對查詢和文本列表之間的相似性進行排名:
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json '您還可以使用經典的序列分類模型,例如SamLowe/roberta-base-go_emotions :
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model部署模型後,您可以使用predict端點來獲得與輸入最相關的情緒:
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json '您可以選擇激活Bert和Distilbert MaskEdlm體系結構的Splade Pooling:
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade部署模型後,您可以使用/embed_sparse端點來獲取稀疏嵌入:
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json '使用OpentElemetry進行分佈式跟踪,儀器進行了text-embeddings-inference推動。您可以通過使用--otlp-endpoint參數將地址設置為OTLP收集器來使用此功能。
text-embeddings-inference提供GRPC API作為高性能部署的默認HTTP API的替代方案。可以在此處找到API Protobuf定義。
您可以通過將-grpc標籤添加到任何TEI Docker映像中來使用GRPC API。例如:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed您還可以在本地選擇安裝text-embeddings-inference 。
首先安裝Rust:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | sh然後運行:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metal現在,您可以使用以下方式啟動CPU上的文本嵌入式推論。
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080注意:在某些機器上,您可能還需要OpenSSL庫和GCC。在Linux機器上,運行:
sudo apt-get install libssl-dev gcc -y不支持具有CUDA計算功能<7.5的GPU(V100,Titan V,GTX 1000系列,...)。
確保您安裝了CUDA和NVIDIA驅動程序。設備上的NVIDIA驅動程序必須與CUDA版本12.2或更高版本兼容。您還需要將NVIDIA二進製文件添加到您的道路上:
export PATH= $PATH :/usr/local/cuda/bin然後運行:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-features現在,您可以使用以下方式啟動有關GPU的文本嵌入推斷。
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080您可以使用以下方式構建CPU容器
docker build .要構建CUDA容器,您需要知道您將在運行時使用的GPU的計算上限。
然後,您可以使用以下方式構建容器
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_cap如下所述,由MPS準備就緒,ARM64 Docker圖像,金屬 / MPS不受Docker的支持。因此,當在M1/M2 ARM CPU上使用此Docker映像時,CPU將是CPU綁定的,並且很可能很慢。
docker build . -f Dockerfile --platform=linux/arm64


