super json mode
1.0.0
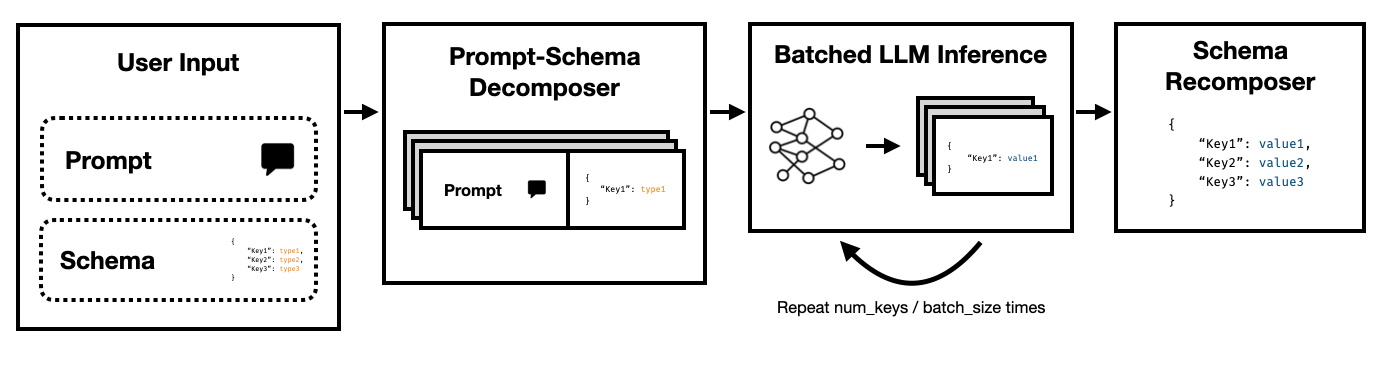
Super JSON模式是一個Python框架,可以通過將目標架構分解為原子組件,然後並行執行世代,從而使LLM有效地創建結構化輸出。
它通過OpenAI的遺產完成API和開源LLMS(例如通過擁抱Face Transformers和vllm)來支持最新的LLM。很快就會支持更多的LLM!
與依靠提示和HF變壓器的天真JSON生成管道相比,我們發現超級JSON模式可以快速生成10倍的輸出。與幼稚的產生相比,它也更確定性,並且不太可能遇到解析問題。
安裝很簡單: pip install super-json-mode
結構化輸出格式(例如JSON或YAML)具有固有的平行或分層結構。
考慮以下非結構化段落(由GPT-4生成):
歡迎來到123 Azure Lane,這是一個令人驚嘆的舊金山居所,擁有出色的當代設計,現在以2,500,000美元的價格在市場上。該物業散佈在豪華的3,000平方英尺上,結合了精緻和舒適,創造了真正獨特的生活體驗。
我們的獨家住宅是一個家庭或專業人士的田園詩般的房屋,配備了五間寬敞的臥室,每個臥室都散發著溫暖和現代優雅。精心計劃臥室,以允許自然光線和寬敞的存儲空間。該住宅擁有三個設計優雅的完整浴室,可為其居民提供便利和隱私。
大入口將您帶到一個寬敞的起居區,為聚會或大火安靜的夜晚提供了極好的氛圍。廚師的廚房包括最先進的電器,定制櫥櫃和美麗的花崗岩檯面,使其成為任何喜歡做飯的人的夢想。
如果我們想使用LLM提取address , square footage , number of bedrooms , number of bathrooms和price ,我們可以根據描述要求模型填充模式。
潛在的模式(例如由pydantic對象產生的模式)看起來像這樣:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
有效的輸出看起來像這樣:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
顯而易見的方法是將模式嵌套在提示中,並要求模型填寫。這是當前大多數團隊當前使用LLMS從非結構化文本中提取結構化輸出的方式。
但是,這是出於三個原因而效率低下的。
請注意,這些鍵中的每個鍵彼此獨立。超級JSON模式通過將模式中的每個鍵值對作為單獨的查詢來利用迅速的並行性。例如,我們可以在沒有生成address的情況下提取num_baths !
要求模型從頭開始生成JSON,不必要地消耗了可預測語法(如括號和鍵名)上的代幣(以及時間),這些語法名稱已經預期了。這是我們應該能夠用來改善潛伏期的一代人的重要事務。
LLM尷尬地並行,批次運行的查詢速度比串行順序快得多。因此,我們可以在多個查詢上將架構拆分。然後,LLM並行填充每個獨立鍵的架構,並在單個通過中發射較少的令牌,從而使推理時間更快。
運行以下命令:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
我們試圖使超級JSON模式超級易於使用。有關更多示例和vLLM使用情況,請參見examples文件夾。
使用OpenAI和gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }將Mistral 7B與HuggingFace Transformers使用:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } 有很多功能可以使超級JSON模式變得更好。這是一些想法。
定性產出分析:我們運行了性能基準,但是我們應該提出更嚴格的方法來判斷超級JSON模式的定性產出。
結構化採樣:理想情況下,我們應該掩蓋LLM的邏輯以執行類型的約束,類似於JSONFORMER。那裡已經有幾個軟件包已經這樣做了,要么它們應該集成我們並行的JSON生成管道,要么我們應該將其構建為超級JSON模式。
依賴圖圖支持:超級JSON模式具有非常明顯的故障情況:當鍵對另一鍵依賴時。考慮一個帶有兩個鑰匙的json斑點, thought和response 。這種所需的輸出對於使用大型語言模型進行思考很常見,很明顯, response取決於thought 。我們應該能夠以依賴關係和批處理提示的形式傳遞,以完成父量輸出並將其傳遞到子模架項目中。
本地模型支持:超級JSON模式在批處理大小通常為1的本地情況下最有效。您可以利用批處理以減少潛伏期,類似於投機解碼。 Llama.CPP是本地型號 + CPU推理的主要框架。如果可能的話,我很想使用Ollama實施此功能。
TRT-LLM支持:VLLM非常易於使用,但理想情況下,我們將其與TRT-LLM(例如TRT-LLM)更具性能的框架集成。
如果您發現圖書館對您的工作有用,請列舉此回購,我們將不勝感激:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
該項目是為CS 229:用於機器學習的系統建造的。非常感謝教學團隊和TAS在整個項目中的指導。


