ai toolkit
1.0.0
هذا هو الريبو البحثي الخاص بي. أقوم بتجارب كثيرة فيه ومن الممكن أن أكسر الأشياء. إذا تعطل شيء ما، قم بالخروج من التزام سابق. يمكن لهذا الريبو تدريب الكثير من الأشياء، ومن الصعب مواكبة كل هذه الأشياء.
لم يكن عملي في هذا المشروع ممكنًا بدون الدعم المذهل من Glif وكل فرد في الفريق. إذا كنت تريد أن تدعمني، ادعم جليف. انضم إلى الموقع، وانضم إلينا على Discord، وتابعنا على Twitter وتعال لتصنع بعض الأشياء الرائعة معنا
متطلبات:
لينكس:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv venv
source venv/bin/activate
# .venvScriptsactivate on windows
# install torch first
pip3 install torch
pip3 install -r requirements.txtويندوز:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
. v env S cripts a ctivate
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txtللبدء سريعًا، راجع البرنامج التعليمي @araminta_k حول Finetuning Flux Dev على الطراز 3090 المزود بذاكرة VRAM سعة 24 جيجابايت.
أنت بحاجة حاليًا إلى وحدة معالجة رسومات (GPU) مزودة بذاكرة فيديو (VRAM) بسعة 24 جيجابايت على الأقل لتدريب FLUX.1. إذا كنت تستخدمه كوحدة معالجة رسومات (GPU) للتحكم في الشاشات، فربما تحتاج إلى تعيين العلامة low_vram: true في ملف التكوين ضمن model: . سيؤدي هذا إلى تحديد حجم النموذج على وحدة المعالجة المركزية ويجب أن يسمح له بالتدريب مع الشاشات المرفقة. لقد جعل المستخدمون يعمل على Windows باستخدام WSL، ولكن هناك بعض التقارير عن وجود خطأ عند التشغيل على Windows محليًا. لقد اختبرت فقط على نظام التشغيل Linux في الوقت الحالي. لا يزال هذا تجريبيًا للغاية وكان لا بد من إجراء الكثير من الحيل لجعله مناسبًا لمساحة 24 جيجابايت على الإطلاق.
يتمتع FLUX.1-dev بترخيص غير تجاري. مما يعني أن أي شيء تدربه سوف يرث الرخصة غير التجارية. وهو أيضًا نموذج مسور، لذا يتعين عليك قبول ترخيص HF قبل استخدامه. وإلا فإن هذا سوف يفشل. فيما يلي الخطوات المطلوبة لإعداد الترخيص.
.env في الجذر على هذا المجلد.env مثل HF_TOKEN=your_key_hereFLUX.1-schnell هو أباتشي 2.0. يمكن ترخيص أي شيء يتم التدريب عليه كيفما تشاء ولا يتطلب التدريب HF_TOKEN. ومع ذلك، فهو يتطلب محولًا خاصًا للتدريب معه، ostris/FLUX.1-schnell-training-adapter. كما أنها تجريبية للغاية. للحصول على أفضل جودة شاملة، يوصى بالتدريب على FLUX.1-dev.
لاستخدامه، تحتاج فقط إلى إضافة المساعد إلى قسم model في ملف التكوين الخاص بك كما يلي:
model :
name_or_path : " black-forest-labs/FLUX.1-schnell "
assistant_lora_path : " ostris/FLUX.1-schnell-training-adapter "
is_flux : true
quantize : trueتحتاج أيضًا إلى تعديل خطوات العينة الخاصة بك نظرًا لأن schnell لا يتطلب عددًا كبيرًا
sample :
guidance_scale : 1 # schnell does not do guidance
sample_steps : 4 # 1 - 4 works wellconfig/examples/train_lora_flux_24gb.yaml ( config/examples/train_lora_flux_schnell_24gb.yaml لـ schnell) إلى مجلد config وأعد تسميته إلى whatever_you_want.ymlpython run.py config/whatever_you_want.ymlسيتم إنشاء مجلد بالاسم ومجلد التدريب من ملف التكوين عند البدء. سيكون به جميع نقاط التفتيش والصور. يمكنك إيقاف التدريب في أي وقت باستخدام ctrl+c وعندما تستأنفه، سيتم استئنافه من آخر نقطة تفتيش.
مهم. إذا ضغطت على crtl+c أثناء الحفظ، فمن المحتمل أن يؤدي ذلك إلى إتلاف نقطة التفتيش تلك. لذا انتظر حتى يتم الانتهاء من الحفظ
يرجى عدم فتح تقرير الأخطاء إلا إذا كان هناك خطأ في الكود. مرحبًا بك للانضمام إلى Discord الخاص بي وطلب المساعدة هناك. ومع ذلك، يرجى الامتناع عن مراسلتي مباشرة بسؤال عام أو دعم. اسأل في الخلاف وسأجيب عندما أستطيع.
لبدء التدريب محليًا باستخدام واجهة مستخدم مخصصة، بمجرد اتباع الخطوات المذكورة أعلاه وتثبيت ai-toolkit :
cd ai-toolkit # in case you are not yet in the ai-toolkit folder
huggingface-cli login # provide a `write` token to publish your LoRA at the end
python flux_train_ui.py ستقوم بإنشاء مثيل لواجهة مستخدم تتيح لك تحميل صورك والتسمية التوضيحية لها وتدريب ونشر LoRA الخاص بك 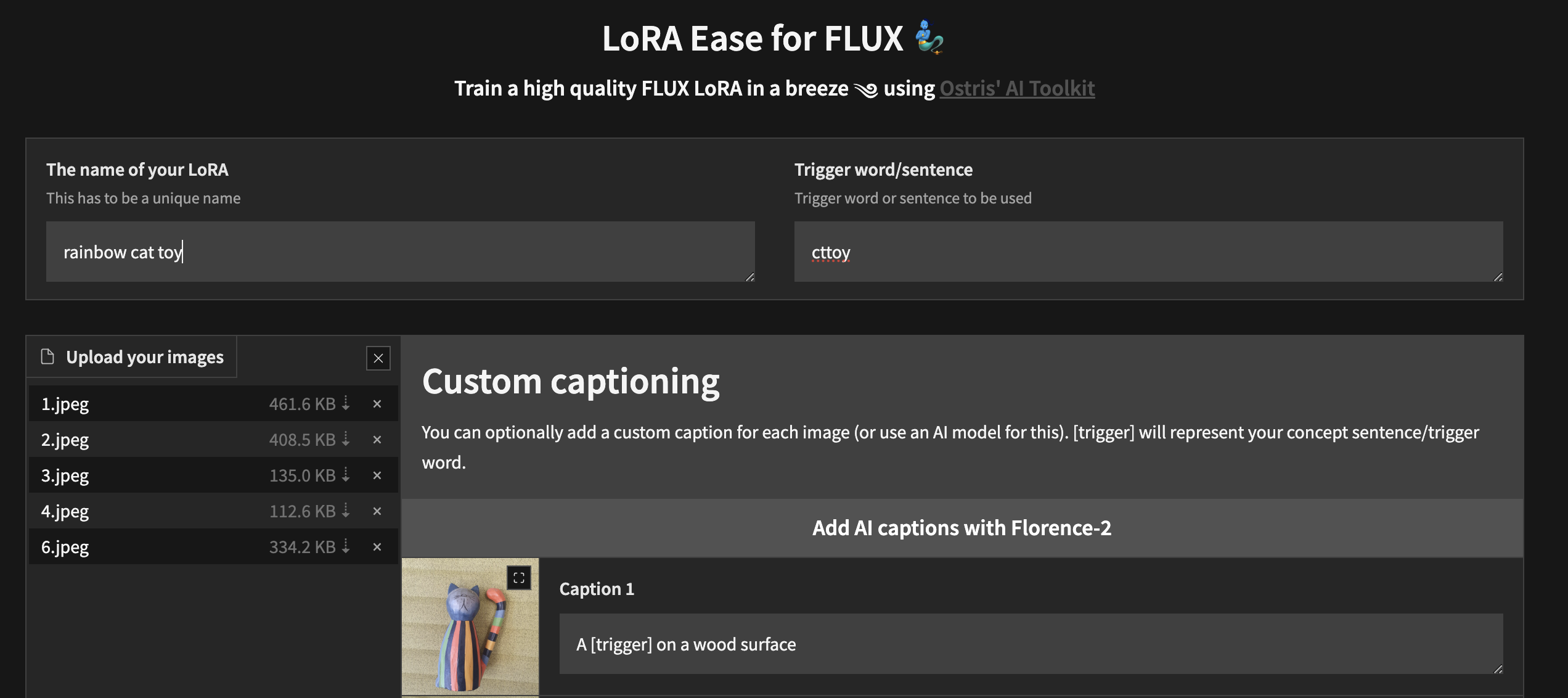
مثال لقالب RunPod: runpod/pytorch:2.2.0-py3.10-cuda12.1.1-devel-ubuntu22.04
أنت بحاجة إلى ذاكرة فيديو بسعة 24 جيجابايت كحد أدنى، اختر وحدة معالجة الرسومات (GPU) حسب تفضيلاتك.
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
dataset أو أي شيء تريده.huggingface-cli login والصق الرمز المميز الخاص بك.config/examples إلى مجلد التكوين وأعد تسميته إلى whatever_you_want.yml .folder_path: "/path/to/images/folder" إلى مسار مجموعة البيانات الخاصة بك مثل folder_path: "/workspace/ai-toolkit/your-dataset" .python run.py config/whatever_you_want.yml .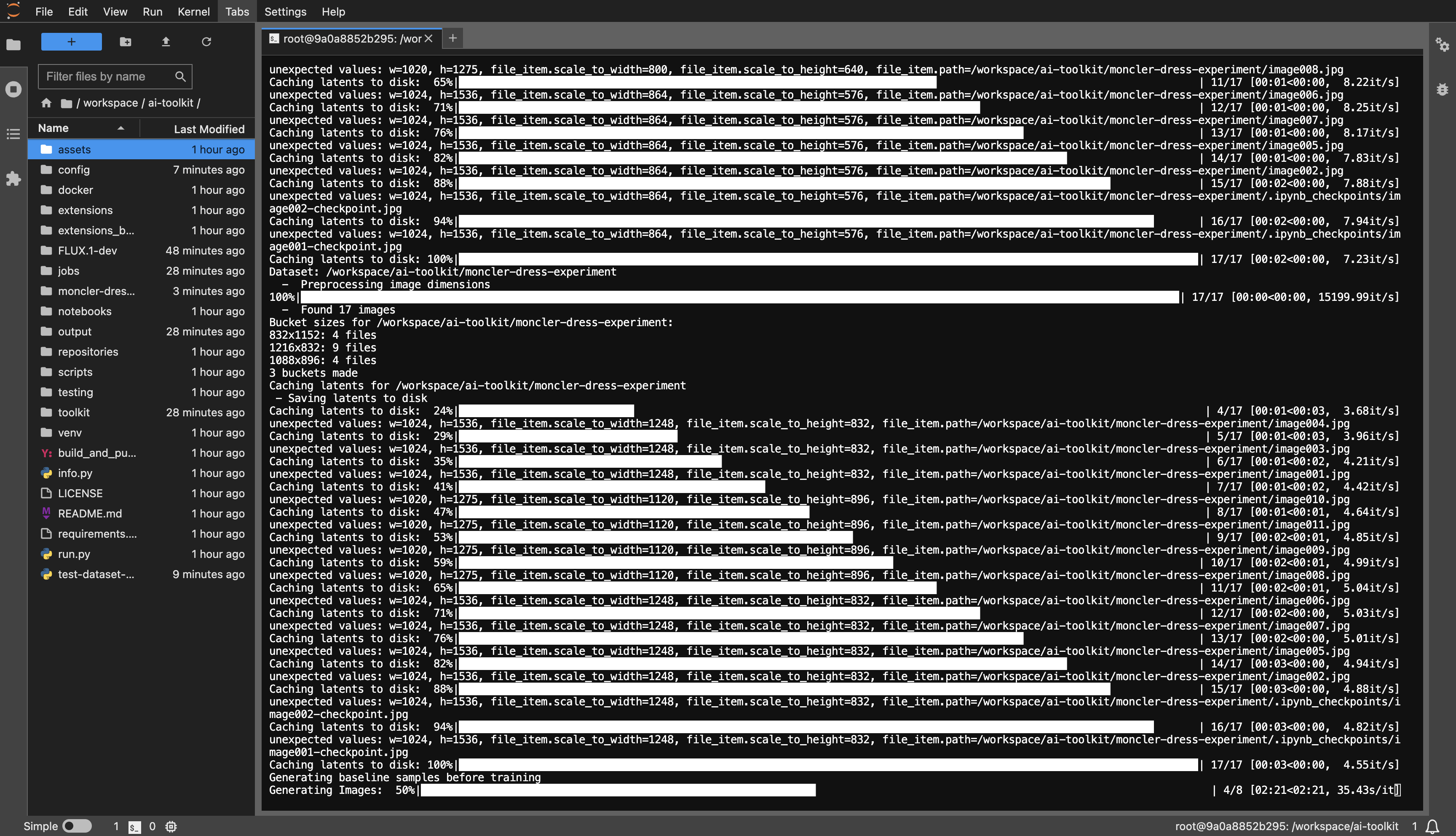
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
pip install modal لتثبيت حزمة Python المشروطة.modal setup للمصادقة (إذا لم ينجح ذلك، فجرّب python -m modal setup ). huggingface-cli login والصق الرمز المميز الخاص بك.ai-toolkit .config/examples/modal إلى مجلد config وأعد تسميته إلى whatever_you_want.yml ./root/ai-toolkit paths . قم بتعيين مسار ai-toolkit المحلي بالكامل على code_mount = modal.Mount.from_local_dir مثل:
code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit")
اختر GPU Timeout في @app.function (الافتراضي هو A100 40 جيجابايت ومهلة مدتها ساعتان) .
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml .Storage > flux-lora-models .modal volume ls flux-lora-models .modal volume get flux-lora-models your-model-name .modal volume get flux-lora-models my_first_flux_lora_v1 .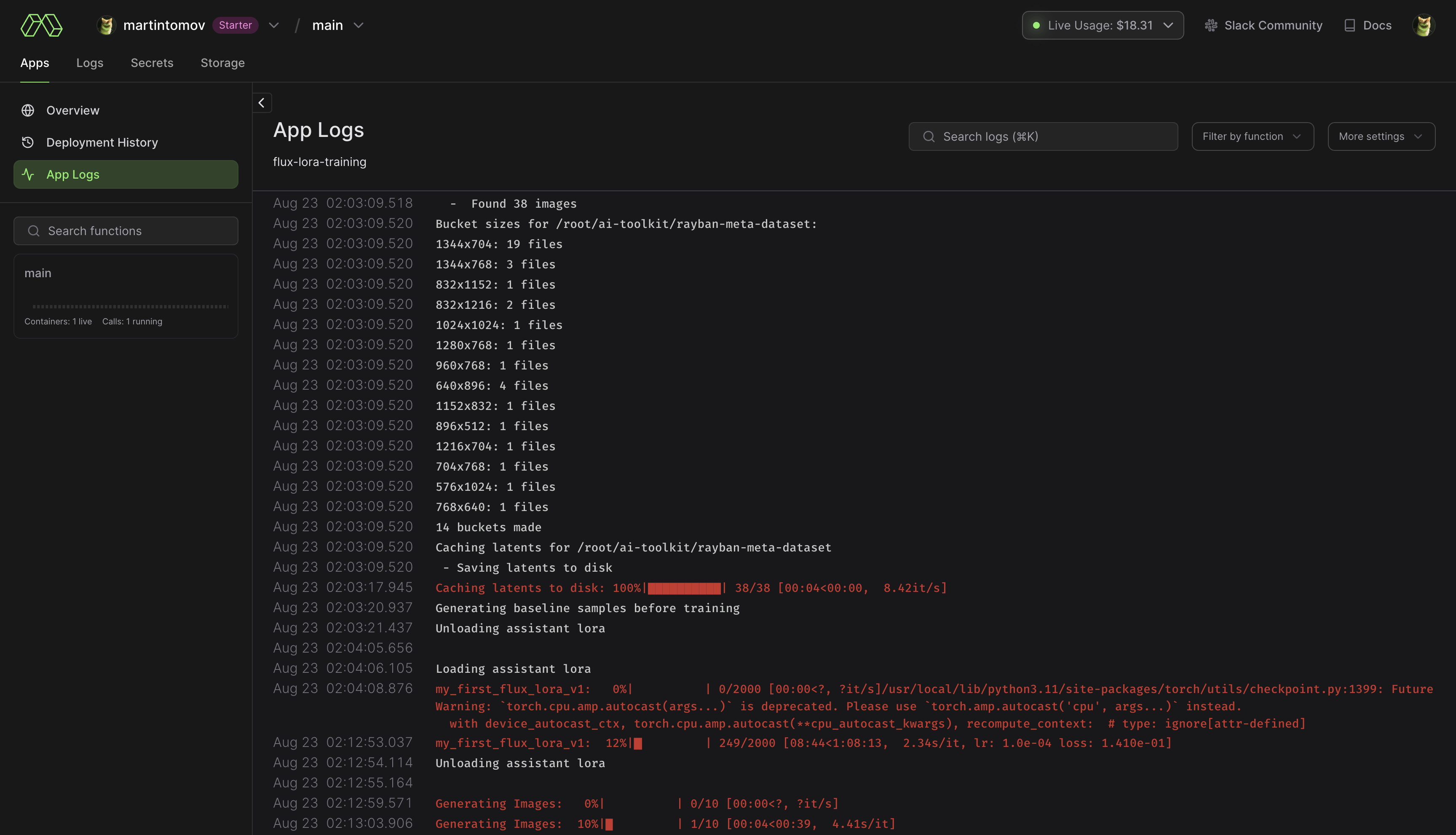
يجب أن تكون مجموعات البيانات عمومًا مجلدًا يحتوي على الصور والملفات النصية المرتبطة بها. حاليًا، التنسيقات الوحيدة المدعومة هي jpg وjpeg وpng. يواجه Webp مشكلات حاليًا. يجب تسمية الملفات النصية بنفس أسماء الصور ولكن بامتداد .txt . على سبيل المثال image2.jpg و image2.txt . يجب أن يحتوي الملف النصي على التسمية التوضيحية فقط. يمكنك إضافة الكلمة [trigger] في ملف التسمية التوضيحية وإذا كان لديك trigger_word في التكوين الخاص بك، فسيتم استبدالها تلقائيًا.
لا يتم ترقية الصور مطلقًا، ولكن يتم تصغير حجمها ووضعها في مجموعات للتجميع. لا تحتاج إلى اقتصاص/تغيير حجم صورك . سيقوم المُحمل بتغيير حجمها تلقائيًا ويمكنه التعامل مع نسب العرض إلى الارتفاع المختلفة.
لتدريب طبقات معينة باستخدام LoRA، يمكنك استخدام only_if_contains شبكة kwargs. على سبيل المثال، إذا كنت تريد تدريب الطبقتين المستخدمتين بواسطة The Last Ben فقط، المذكورين في هذا المنشور، فيمكنك ضبط kwargs شبكتك على النحو التالي:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks.7.proj_out "
- " transformer.single_transformer_blocks.20.proj_out " تكون اصطلاحات تسمية الطبقات في تنسيق الناشرين، لذا فإن التحقق من حالة النموذج سيكشف عن لاحقة اسم الطبقات التي تريد تدريبها. يمكنك أيضًا استخدام هذه الطريقة لتدريب مجموعات محددة من الأوزان فقط. على سبيل المثال، لتدريب المحول single_transformer لـ FLUX.1 فقط، يمكنك استخدام ما يلي:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks. " يمكنك أيضًا استبعاد الطبقات بأسمائها باستخدام ignore_if_contains kwarg. لذلك لاستبعاد جميع كتل المحولات الفردية،
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
ignore_if_contains :
- " transformer.single_transformer_blocks. " يحظى ignore_if_contains بالأولوية على only_if_contains . لذلك إذا تم تغطية الوزن من قبل كليهما، إذا سيتم تجاهله.
ربما لا يزال يعمل بهذه الطريقة، لكنني لم أختبره منذ فترة.
منشئ صور يمكنه أخذ النقاط من ملف التكوين أو تكوين ملف txt وإنشاءها في مجلد. لقد كنت بحاجة إلى هذا بشكل أساسي لاختبار SDXL الذي أقوم به ولكني أضفت بعض الصقل إليه حتى يمكن استخدامه لإنشاء مجموعة صور مجمعة. يتم تشغيل كل شيء من خلال ملف التكوين، والذي يمكنك العثور على مثال له في config/examples/generate.example.yaml . مجرد معلومات في التعليقات في المثال
وهو يعتمد على المستخرج الموجود في أداة LyCORIS، ولكنه يضيف بعض ميزات QOL ودعم LoRA (lierla). يمكنه القيام بأنواع متعددة من عمليات الاستخراج في جولة واحدة. يتم تشغيل كل ذلك من خلال ملف تكوين، والذي يمكنك العثور على مثال له في config/examples/extract.example.yml . ما عليك سوى نسخ هذا الملف إلى مجلد config ، وإعادة تسميته إلى whatever_you_want.yml . ومن ثم يمكنك تعديل الملف حسب رغبتك. ونسميها هكذا:
python3 run.py config/whatever_you_want.ymlيمكنك أيضًا وضع مسار كامل لملف التكوين، إذا كنت تريد الاحتفاظ به في مكان آخر.
python3 run.py " /home/user/whatever_you_want.yml "تتوفر المزيد من الملاحظات حول كيفية عمله في ملف التكوين النموذجي نفسه. يدعم كل من LoRA وLoCON عمليات استخراج "الثابت" و"العتبة" و"النسبة" و"الكمية". سأقوم بتحديث ما يفعله ويعنيه لاحقًا. معظم الناس يستخدمون الثابت، وهو استخراج البعد الثابت التقليدي.
process عبارة عن مجموعة من العمليات المختلفة للتشغيل. يمكنك إضافة القليل والمزج والمطابقة. واحد LoRA، وواحد LyCON، وما إلى ذلك.
قم بتغيير <lora:my_lora:4.6> إلى <lora:my_lora:1.0> أو ما تريد بنفس التأثير. أداة لإعادة قياس أوزان LoRA. ينبغي أن يكون مع LoCON أيضًا، لكنني لم أختبره. يتم تشغيل كل ذلك من خلال ملف التكوين، والذي يمكنك العثور على مثال له في config/examples/mod_lora_scale.yml . ما عليك سوى نسخ هذا الملف إلى مجلد config ، وإعادة تسميته إلى whatever_you_want.yml . ومن ثم يمكنك تعديل الملف حسب رغبتك. ونسميها هكذا:
python3 run.py config/whatever_you_want.ymlيمكنك أيضًا وضع مسار كامل لملف التكوين، إذا كنت تريد الاحتفاظ به في مكان آخر.
python3 run.py " /home/user/whatever_you_want.yml "تتوفر المزيد من الملاحظات حول كيفية عمله في ملف التكوين النموذجي نفسه. يعد هذا مفيدًا عند إنشاء جميع LoRAs، حيث نادرًا ما يكون الوزن المثالي 1.0، ولكن الآن يمكنك إصلاح ذلك. بالنسبة إلى أشرطة التمرير، يمكن أن تحتوي على مقاييس غريبة من -2 إلى 2 أو حتى -15 إلى 15. سيسمح لك ذلك بتخفيفها حتى تحصل جميعها على المقياس المطلوب
هذه هي الطريقة التي أقوم بها بتدريب معظم أشرطة التمرير الحديثة الموجودة لدي في Civitai، ويمكنك التحقق منها في ملفي الشخصي في Civitai. وهو يعتمد على العمل الذي قام به p1atdev/LECO وrohitgandikota/erasing ولكن تم تعديله بشكل كبير لإنشاء أشرطة تمرير بدلاً من مسح المفاهيم. لدي الكثير من الخطط في هذا الشأن، لكنها عملية للغاية كما هي. كما أنه سهل الاستخدام للغاية. ما عليك سوى نسخ ملف التكوين النموذجي في config/examples/train_slider.example.yml إلى مجلد config وإعادة تسميته إلى whatever_you_want.yml . ومن ثم يمكنك تعديل الملف حسب رغبتك. ونسميها هكذا:
python3 run.py config/whatever_you_want.ymlهناك الكثير من المعلومات في ملف المثال هذا. يمكنك أيضًا تشغيل المثال كما هو بدون أي تعديلات لترى كيف يعمل. سيتم إنشاء شريط تمرير يحول جميع الحيوانات إلى كلاب (neg) أو قطط (pos). فقط قم بتشغيله هكذا:
python3 run.py config/examples/train_slider.example.ymlوستكون قادرًا على رؤية كيفية عمله دون تكوين أي شيء. لا توجد مجموعات بيانات مطلوبة لهذه الطريقة. سأقوم بنشر برنامج تعليمي أفضل قريبا.
يمكنك الآن إنشاء ومشاركة ملحقات مخصصة. يتم تشغيله ضمن هذا الإطار ولديه جميع الأدوات المضمنة المتاحة لهم. من المحتمل أن أستخدم هذا باعتباره طريقة التطوير الأساسية للمضي قدمًا، لذلك لا أستمر في إضافة وإضافة المزيد والمزيد من الميزات إلى هذا الريبو الأساسي. من المحتمل أن أقوم بترحيل الكثير من الوظائف الحالية أيضًا لجعل كل شيء معياريًا. يوجد ملحق مثال في مجلد extensions يوضح كيفية إنشاء ملحق دمج النموذج. تم توثيق جميع التعليمات البرمجية بشكل كبير وهو ما نأمل أن يكون كافيًا للبدء. لإنشاء امتداد، ما عليك سوى نسخ هذا المثال واستبدال كل الأشياء التي تحتاج إليها.
وهو موجود في مجلد extensions . إنه عبارة عن دمج نموذجي كامل يمكنه دمج العديد من النماذج معًا كما تريد. إنه مثال جيد لكيفية إنشاء امتداد، ولكنه أيضًا ميزة مفيدة جدًا نظرًا لأن معظم عمليات الدمج يمكنها إجراء نموذج واحد فقط في كل مرة، وسيستغرق هذا النموذج العدد الذي تريده لتغذيته. يوجد مثال لملف التكوين هناك، ما عليك سوى نسخه إلى مجلد config الخاص بك وإعادة تسميته إلى whatever_you_want.yml . واستخدمه مثل أي ملف تكوين آخر.
يعمل هذا، ولكنه ليس جاهزًا ليستخدمه الآخرون، وبالتالي لا يحتوي على مثال للتكوين. ما زلت أعمل على ذلك. سأقوم بتحديث هذا عندما يكون جاهزًا. أقوم بإضافة الكثير من الميزات للمعايير التي استخدمتها في عملي لتكبير الصور. الناقد (المميز)، وفقدان المحتوى، وفقدان الأسلوب، والمزيد. إذا كنت لا تعرف، فإن VAE للانتشار المستقر (نعم حتى MSE واحد، وSDXL)، يعد أمرًا فظيعًا على الوجوه الأصغر حجمًا ويعوق SD. سوف أصلح هذا. سأقوم بنشر المزيد حول هذا الأمر لاحقًا مع أمثلة أفضل لاحقًا، ولكن هنا اختبار سريع للتجربة مع العديد من VAEs. فقط دخلت وخرجت. إنه أسوأ بكثير على الوجوه الأصغر مما هو موضح هنا.
extensions . اقرأ المزيد عن ذلك أعلاه.إعادة بناء كبيرة أخرى لجعل SD أكثر معيارية.
تم إنشاء برنامج نصي لتوليد الصور دفعة واحدة
التغييرات والتحديثات الرئيسية. أداة إعادة قياس LoRA جديدة، انظر أعلاه للحصول على التفاصيل. تمت إضافة بيانات وصفية أفضل حتى يعرف Automatic1111 ما هو النموذج الأساسي. تمت إضافة بعض التجارب والعديد من التحديثات. لا يزال هذا الشيء غير مستقر في الوقت الحالي، لذا نأمل ألا تكون هناك تغييرات جذرية.
لسوء الحظ، أنا كسول جدًا لدرجة أنني لا أستطيع كتابة سجل التغيير المناسب مع كل التغييرات.
لقد أضفت تدريب SDXL إلى أشرطة التمرير...ولكن..لا يعمل بشكل صحيح. يعتمد تدريب شريط التمرير على قدرة النموذج على فهم أن المطالبة غير المشروطة (الموجه السلبي) تعني أنك لا تريد هذا المفهوم في الإخراج. لا يفهم SDXL هذا لأي سبب من الأسباب، مما يجعل فصل المفاهيم داخل النموذج أمرًا صعبًا. أنا متأكد من أن المجتمع سيجد طريقة لإصلاح هذه المشكلة بمرور الوقت، لكن في الوقت الحالي، لن تعمل هذه الطريقة بشكل صحيح. وإذا كان أي منكم يفكر "هل يمكننا إصلاحه عن طريق إضافة جهاز أو اثنين من برامج تشفير النص إلى النموذج بالإضافة إلى عدد قليل من شبكات النشر المنفصلة تمامًا؟" لا والله لا. إنه يحتاج فقط إلى القليل من التدريب دون إضافة كل ورقة تجريبية جديدة إليه. مدير KISS.
تمت إضافة "المراسي" إلى المدرب المنزلق. يتيح لك هذا تعيين موجه سيتم استخدامه كمنظم. يمكنك ضبط مضاعف الشبكة لفرض اتساق الانتشار عند الأوزان العالية


