build your local ragstack chatbot
1.0.0
مرحبًا بك في ورشة العمل هذه لبناء ونشر برنامج Enterprise Co-Pilot الخاص بك باستخدام تقنية Retrieval Augmented Generation مع DataStax Enterprise v7، وهو جهاز استدلال محلي وMistral، وهو نموذج لغة كبير محلي ومفتوح.
يركز هذا المستودع على السلامة والأمان من خلال الاحتفاظ ببياناتك الحساسة داخل جدار الحماية!
لماذا؟
إنه يستفيد من DataStax RAGStack، وهو عبارة عن مجموعة منسقة من أفضل البرامج مفتوحة المصدر لتسهيل تنفيذ نمط RAG في التطبيقات الجاهزة للإنتاج التي تستخدم DataStax Enterprise أو Astra Vector DB أو Apache Cassandra كمخزن متجه.
ما ستتعلمه:
؟ كيفية الاستفادة من DataStax RAGStack للاستخدام الجاهز للإنتاج للمكونات التالية:
؟ كيفية استخدام Ollama كمحرك استدلال محلي
؟ كيفية استخدام ميسترال كنموذج لغة كبير محلي ومفتوح (LLM) لروبوتات الدردشة ذات نمط الأسئلة والأجوبة
؟ كيفية استخدام Streamlit لنشر تطبيقك الرائع بسهولة!
يمكن العثور على شرائح العرض التقديمي هنا
تفترض ورشة العمل هذه أن لديك إمكانية الوصول إلى:
في الخطوات التالية، سنقوم بإعداد المستودع، وDataStax Enterprise، وJupyter Notebook، وOllama Inference Engine مع Ollama.
أول شيء، سنحتاج إلى استنساخ هذا المستودع على جهاز الكمبيوتر المحمول الخاص بالتطوير المحلي.
افتح مستودع build-your-local-ragstack-chatbot
انقر فوق Use this template -> Ceate new repository كما يلي:
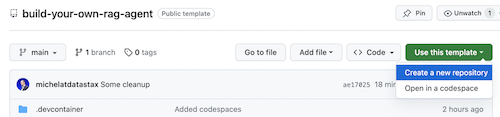
الآن حدد حساب جيثب الخاص بك وقم بتسمية المستودع الجديد. من الناحية المثالية أيضا تعيين الوصف. انقر فوق Create repository
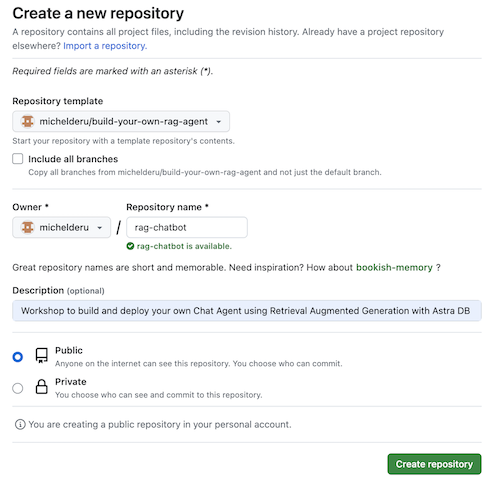
رائع! لقد قمت للتو بإنشاء نسخة في حساب Gihub الخاص بك!
cd إلى دليل معقول (مثل /projects أو نحو ذلك) ؛git clone <url-to-your-repo>cd إلى الدليل الجديد الخاص بك!وأنت على استعداد لموسيقى الروك أند رول! ؟
من المفيد إنشاء بيئة افتراضية . استخدم ما يلي لإعداده:
python3 -m venv myenv
ثم قم بتفعيله كالتالي:
source myenv/bin/activate # on Linux/Mac
myenvScriptsactivate.bat # on Windows
الآن يمكنك البدء في تثبيت الحزم المطلوبة:
pip3 install -r requirements.txt
قم بتشغيل DSE 7 بأي من هاتين الطريقتين من نافذة طرفية جديدة:
docker-compose up
يستخدم هذا ملف docker-compose.yml في جذر هذا المستودع والذي سيبدأ أيضًا تشغيل Jupyter Interpreter بشكل ملائم.
سيتم تشغيل DataStax على http://localhost:9042 وسيكون من الممكن الوصول إلى Jupyter من خلال التصفح على http://localhost:8888
هناك العديد من محركات الاستدلال. يمكنك الانتقال إلى LM Studio الذي يحتوي على واجهة مستخدم رائعة. في هذا الدفتر، سوف نستخدم أولاما.
ollama run mistral في نافذة طرفية جديدةفي حالة فشل كل هذا، بسبب قيود ذاكرة الوصول العشوائي (RAM)، يمكنك اختيار استخدام tinyllama كنموذج.
لبدء ورشة العمل هذه، سنقوم أولاً بتجربة المفاهيم الموجودة في دفتر الملاحظات المرفق. نحن نفترض أنك ستعمل من داخل Jupyter Docker Container، إذا لم تكن كذلك، فيرجى تغيير أسماء المضيف من host.docker.internal إلى localhost .
يعرض هذا الدفتر الخطوات التي يجب اتخاذها لاستخدام DataStax Enterprise Vector Store كوسيلة لجعل تفاعلات LLM ذات معنى وبدون هلوسة. النهج المتبع هنا هو الاسترجاع المعزز للجيل.
سوف تتعلم:
استعرض للوصول إلى http://localhost:8888 وافتح دفتر الملاحظات المتوفر في الجذر المسمى Build_Your_Own_RAG_Meetup.ipnb .
في ورشة العمل هذه، سنستخدم Streamlit وهو إطار عمل سهل الاستخدام بشكل مذهل لإنشاء تطبيقات الويب الأمامية.
للبدء، لنقم بإنشاء تطبيق helloworld كما يلي:
import streamlit as st
# Draw a title and some markdown
st . markdown ( """# Your Enterprise Co-Pilot
Generative AI is considered to bring the next Industrial Revolution.
Why? Studies show a **37% efficiency boost** in day to day work activities!
### Security and safety
This Chatbot is safe to work with sensitive data. Why?
- First of all it makes use of [Ollama, a local inference engine](https://ollama.com);
- On top of the inference engine, we're running [Mistral, a local and open Large Language Model (LLM)](https://mistral.ai/);
- Also the LLM does not contain any sensitive or enterprise data, as there is no way to secure it in a LLM;
- Instead, your sensitive data is stored securely within the firewall inside [DataStax Enterprise v7 Vector Database](https://www.datastax.com/blog/get-started-with-the-datastax-enterprise-7-0-developer-vector-search-preview);
- And lastly, the chains are built on [RAGStack](https://www.datastax.com/products/ragstack), an enterprise version of Langchain and LLamaIndex, supported by [DataStax](https://www.datastax.com/).""" )
st . divider () الخطوة الأولى هي استيراد الحزمة المبسطة. ثم نستدعي st.markdown لكتابة عنوان وأخيرًا نكتب بعض المحتوى على صفحة الويب.
لبدء تشغيل هذا التطبيق محليًا، ستحتاج إلى تثبيت التبعية المبسطة على النحو التالي (والتي يجب أن يتم تنفيذها بالفعل كجزء من المتطلبات الأساسية):
pip install streamlitالآن قم بتشغيل التطبيق:
streamlit run app_1.pyسيؤدي هذا إلى تشغيل خادم التطبيق وسينقلك إلى صفحة الويب التي أنشأتها للتو.
بسيطة، أليس كذلك؟ ؟
سنبدأ في هذه الخطوة بإعداد التطبيق للسماح بتفاعل chatbot مع المستخدم. سنستخدم مكونات Streamlit التالية: 1. 2. st.chat_input لكي يسمح للمستخدم بإدخال سؤال 2. st.chat_message('human') لرسم مدخلات المستخدم 3. st.chat_message('assistant') لرسم استجابة برنامج الدردشة الآلي
وينتج عن هذا الكود التالي:
# Draw the chat input box
if question := st . chat_input ( "What's up?" ):
# Draw the user's question
with st . chat_message ( 'human' ):
st . markdown ( question )
# Generate the answer
answer = f"""You asked: { question } """
# Draw the bot's answer
with st . chat_message ( 'assistant' ):
st . markdown ( answer ) جربه باستخدام app_2.py وابدأ تشغيله على النحو التالي.
إذا كان تطبيقك السابق لا يزال قيد التشغيل، فما عليك سوى إيقافه بالضغط على ctrl-c مسبقًا.
streamlit run app_2.pyالآن اكتب سؤالاً، ثم اكتب سؤالاً آخر مرة أخرى. سترى أنه تم الاحتفاظ بالسؤال الأخير فقط.
لماذا؟؟؟
وذلك لأن Streamlit سيعيد رسم الشاشة بأكملها مرارًا وتكرارًا بناءً على أحدث المدخلات. نظرًا لأننا لا نتذكر الأسئلة، فسيتم عرض الأسئلة الأخيرة فقط.
في هذه الخطوة سوف نتأكد من متابعة الأسئلة والأجوبة بحيث يتم عرض السجل مع كل إعادة رسم.
وللقيام بذلك سنتخذ الخطوات التالية:
st.session_state يسمى messagesst.session_state يسمى messagesfor message in st.session_state.messages يعمل هذا الأسلوب نظرًا لأن session_state تكون ذات حالة عبر تشغيل Streamlit.
تحقق من الكود الكامل في app_3.py.
كما سترى، نستخدم قاموسًا لتخزين كل من role (الذي يمكن أن يكون إما الإنسان أو الذكاء الاصطناعي) question أو answer . يعد تتبع الدور أمرًا مهمًا لأنه سيرسم الصورة الصحيحة في المتصفح.
تشغيله مع:
streamlit run app_3.pyأضف الآن أسئلة متعددة وسترى أنه يتم إعادة رسمها على الشاشة في كل مرة يتم فيها إعادة تشغيل Streamlit. ؟
سنقوم هنا بالرجوع إلى العمل الذي قمنا به باستخدام Jupyter Notebook ودمج السؤال مع استدعاء نموذج الدردشة Mistral.
هل تتذكر أن Streamlit يعيد تشغيل الكود في كل مرة يتفاعل فيها المستخدم؟ ولهذا السبب، سنستفيد من التخزين المؤقت للبيانات والموارد في Streamlit بحيث يتم إعداد الاتصال مرة واحدة فقط. سنستخدم @st.cache_data() و @st.cache_resource() لتعريف التخزين المؤقت. يتم استخدام cache_data عادةً لهياكل البيانات. يتم استخدام cache_resource في الغالب لموارد مثل قواعد البيانات.
ينتج عن هذا التعليمة البرمجية التالية لإعداد نموذج المطالبة والدردشة:
# Cache prompt for future runs
@ st . cache_data ()
def load_prompt ():
template = """You're a helpful AI assistent tasked to answer the user's questions.
You're friendly and you answer extensively with multiple sentences. You prefer to use bulletpoints to summarize.
QUESTION:
{question}
YOUR ANSWER:"""
return ChatPromptTemplate . from_messages ([( "system" , template )])
prompt = load_prompt ()
# Cache Mistral Chat Model for future runs
@ st . cache_resource ()
def load_chat_model ():
# parameters for ollama see: https://api.python.langchain.com/en/latest/chat_models/langchain_community.chat_models.ollama.ChatOllama.html
# num_ctx is the context window size
return ChatOllama (
model = "mistral:latest" ,
num_ctx = 18192 ,
base_url = st . secrets [ 'OLLAMA_ENDPOINT' ]
)
chat_model = load_chat_model ()بدلًا من الإجابة الثابتة التي استخدمناها في الأمثلة السابقة، سننتقل الآن إلى استدعاء السلسلة:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'question' : lambda x : x [ 'question' ]
})
chain = inputs | prompt | chat_model
response = chain . invoke ({ 'question' : question })
answer = response . contentتحقق من الكود الكامل في app_4.py.
قبل أن نواصل، علينا توفير OLLAMA_ENDPOINT في ./streamlit/secrets.toml . يوجد مثال مقدم في secrets.toml.example :
# Ollama/Mistral Endpoint
OLLAMA_ENDPOINT = " http://localhost:11434 "لبدء تشغيل هذا التطبيق محليًا، ستحتاج إلى تثبيت RAGStack الذي يحتوي على إصدار ثابت من LangChain وجميع التبعيات (والتي يجب أن يتم تنفيذها بالفعل كجزء من المتطلبات الأساسية):
pip install ragstackالآن قم بتشغيل التطبيق:
streamlit run app_4.pyيمكنك الآن بدء تفاعل الأسئلة والأجوبة مع Chatbot. بالطبع، نظرًا لعدم وجود تكامل مع DataStax Enterprise Vector Store، فلن تكون هناك إجابات سياقية. نظرًا لعدم وجود تدفق مدمج حتى الآن، يرجى منح الوكيل بعض الوقت للتوصل إلى الإجابة الكاملة في وقت واحد.
لنبدأ بالسؤال:
What does Daniel Radcliffe get when he turns 18?
وكما سترى، ستتلقى إجابة عامة للغاية دون المعلومات المتوفرة في بيانات CNN.
الآن أصبحت الأمور مثيرة للاهتمام حقًا! في هذه الخطوة، سنقوم بدمج DataStax Enterprise Vector Store لتوفير السياق في الوقت الفعلي لنموذج الدردشة. الخطوات المتخذة لتنفيذ الجيل المعزز للاسترجاع:
سنعيد استخدام بيانات CNN التي أدخلناها بفضل دفتر الملاحظات.
لتمكين ذلك، يتعين علينا أولاً إعداد اتصال بمتجر DataStax Enterprise Vector Store:
# Cache the DataStax Enterprise Vector Store for future runs
@ st . cache_resource ( show_spinner = 'Connecting to Datastax Enterprise v7 with Vector Support' )
def load_vector_store ():
# Connect to DSE
cluster = Cluster (
[ st . secrets [ 'DSE_ENDPOINT' ]]
)
session = cluster . connect ()
# Connect to the Vector Store
vector_store = Cassandra (
session = session ,
embedding = HuggingFaceEmbeddings (),
keyspace = st . secrets [ 'DSE_KEYSPACE' ],
table_name = st . secrets [ 'DSE_TABLE' ]
)
return vector_store
vector_store = load_vector_store ()
# Cache the Retriever for future runs
@ st . cache_resource ( show_spinner = 'Getting retriever' )
def load_retriever ():
# Get the retriever for the Chat Model
retriever = vector_store . as_retriever (
search_kwargs = { "k" : 5 }
)
return retriever
retriever = load_retriever ()الشيء الآخر الوحيد الذي يتعين علينا القيام به هو تغيير السلسلة لتشمل استدعاء متجر Vector:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'context' : lambda x : retriever . get_relevant_documents ( x [ 'question' ]),
'question' : lambda x : x [ 'question' ]
})تحقق من الكود الكامل في app_5.py.
قبل أن نواصل، علينا توفير DSE_ENDPOINT و DSE_KEYSPACE و DSE_TABLE في ./streamlit/secrets.toml . يوجد مثال مقدم في secrets.toml.example :
# DataStax Enterprise Endpoint
DSE_ENDPOINT = " localhost "
DSE_KEYSPACE = " default_keyspace "
DSE_TABLE = " dse_vector_table "وتشغيل التطبيق:
streamlit run app_5.pyولنطرح السؤال مرة أخرى:
What does Daniel Radcliffe get when he turns 18?
كما سترى، ستتلقى الآن إجابة سياقية للغاية حيث يوفر Vector Store بيانات CNN ذات الصلة لنموذج الدردشة.
كم سيكون رائعًا رؤية الإجابة تظهر على الشاشة عند إنشائها! حسنا، هذا سهل.
أولاً، سنقوم بإنشاء معالج رد الاتصال المتدفق الذي يتم استدعاؤه عند كل جيل جديد من الرموز المميزة على النحو التالي:
# Streaming call back handler for responses
class StreamHandler ( BaseCallbackHandler ):
def __init__ ( self , container , initial_text = "" ):
self . container = container
self . text = initial_text
def on_llm_new_token ( self , token : str , ** kwargs ):
self . text += token
self . container . markdown ( self . text + "▌" )ثم نشرح نموذج الدردشة للاستفادة من StreamHandler:
response = chain . invoke ({ 'question' : question }, config = { 'callbacks' : [ StreamHandler ( response_placeholder )]}) يحدد response_placeholer في الكود أعلاه المكان الذي يجب كتابة الرموز المميزة فيه. يمكننا إنشاء تلك المساحة عن طريق callint st.empty() كما يلي:
# UI placeholder to start filling with agent response
with st . chat_message ( 'assistant' ):
response_placeholder = st . empty ()تحقق من الكود الكامل في app_6.py.
وتشغيل التطبيق:
streamlit run app_6.pyسترى الآن أنه سيتم كتابة الرد في الوقت الفعلي على نافذة المتصفح.
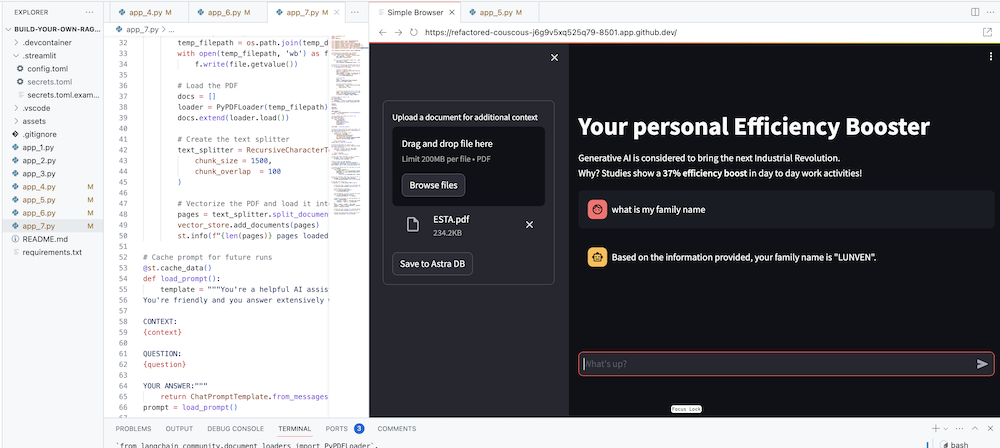
الهدف النهائي بالطبع هو إضافة سياق شركتك إلى الوكيل. وللقيام بذلك، سنضيف مربع تحميل يسمح لك بتحميل ملفات PDF والتي سيتم استخدامها بعد ذلك لتقديم استجابة ذات معنى وسياق!
نحتاج أولاً إلى نموذج تحميل يسهل إنشاؤه باستخدام Streamlit:
# Include the upload form for new data to be Vectorized
with st . sidebar :
with st . form ( 'upload' ):
uploaded_file = st . file_uploader ( 'Upload a document for additional context' , type = [ 'pdf' ])
submitted = st . form_submit_button ( 'Save to DataStax Enterprise' )
if submitted :
vectorize_text ( uploaded_file )نحتاج الآن إلى وظيفة لتحميل ملف PDF واستيعابه في DataStax Enterprise أثناء توجيه المحتوى.
# Function for Vectorizing uploaded data into DataStax Enterprise
def vectorize_text ( uploaded_file , vector_store ):
if uploaded_file is not None :
# Write to temporary file
temp_dir = tempfile . TemporaryDirectory ()
file = uploaded_file
temp_filepath = os . path . join ( temp_dir . name , file . name )
with open ( temp_filepath , 'wb' ) as f :
f . write ( file . getvalue ())
# Load the PDF
docs = []
loader = PyPDFLoader ( temp_filepath )
docs . extend ( loader . load ())
# Create the text splitter
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1500 ,
chunk_overlap = 100
)
# Vectorize the PDF and load it into the DataStax Enterprise Vector Store
pages = text_splitter . split_documents ( docs )
vector_store . add_documents ( pages )
st . info ( f" { len ( pages ) } pages loaded." )تحقق من الكود الكامل في app_7.py.
لبدء تشغيل هذا التطبيق محليًا، ستحتاج إلى تثبيت تبعية PyPDF على النحو التالي (وهو ما يجب أن يتم بالفعل كجزء من المتطلبات الأساسية):
pip install pypdfوتشغيل التطبيق:
streamlit run app_7.pyالآن قم بتحميل مستند PDF (كلما كان الأمر أكثر مرحًا) ذو صلة بك وابدأ في طرح الأسئلة حوله. سترى أن الإجابات ستكون ذات صلة وذات مغزى وسياقية! ؟ شاهد السحر يحدث!