demo ai app
1.0.0
نموذج لتطبيق أفلام تم تصميمه باستخدام ❍ Ion لعرض كيفية استخدام الذكاء الاصطناعي في تطبيقاتك باستخدام بياناتك — movie.sst.dev
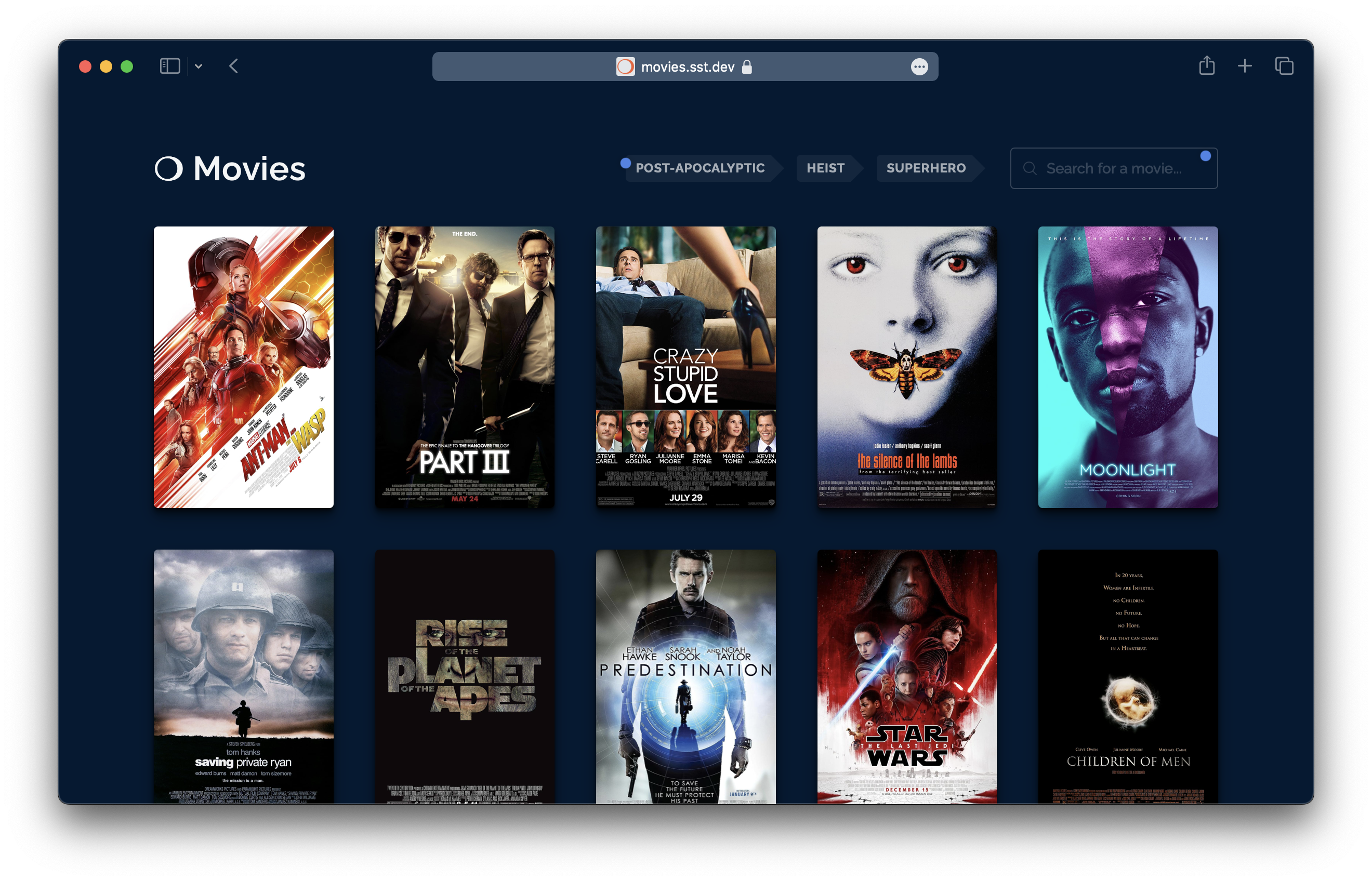
تحتوي قاعدة بيانات الأفلام في هذا التطبيق على حوالي 700 فيلم مشهور. يمكنك البحث فيها، والاطلاع على الأفلام ذات الصلة، كما يتم وضع علامة على بعض الأفلام أيضًا.
تتضمن معظم العروض التوضيحية للذكاء الاصطناعي حتى الآن شكلاً من أشكال الدردشة. وعلى الرغم من أن هذا مفيد، إلا أنه لا ينطبق على غالبية التطبيقات المتوفرة. ويتضمن أيضًا تخزين بياناتك خارج البنية التحتية الخاصة بك.
يوضح هذا العرض التوضيحي كيف يمكنك استخدام الميزات المتعلقة بالذكاء الاصطناعي في بنيتك الأساسية بطريقة منطقية للمستخدمين.
يتم تشغيل ميزات الذكاء الاصطناعي التالية بواسطة مكون Vector الجديد الخاص بنا.
يعتمد مكون Vector على Amazon Bedrock ويكشف عن وظيفتين تجعل من السهل استخدام الذكاء الاصطناعي مع بياناتك.
ingest : يأخذ هذا بعض النص، وينشئ تضمينًا بنموذج معين، ويخزنه في قاعدة بيانات Vector مدعومة بواسطة RDS. يأخذ أيضًا بعض البيانات الوصفية لوضع علامة على البيانات.retrieve : يأخذ البيانات التعريفية بشكل مطالبة واختياريًا للتصفية عليها. إرجاع النتائج المطابقة بنتيجة 0 - 1. حاليًا يمكن إنشاء التضمينات باستخدام titan-embed-text-v1 و titan-embed-image-v1 و text-embedding-ada-002 .
❍ Ion هو محرك تجريبي جديد لـ SST يتمتع ببعض المزايا الفريدة مقارنة بمحركنا السابق المعتمد على CDK. إليك زوجين يمكنك رؤيتهما أثناء العمل في هذا الريبو:
sst bind next build يعمل هذا العرض التوضيحي عن طريق استيعاب بيانات الفيلم من IMDB، وإنشاء التضمينات، وتخزينها في قاعدة بيانات Vector. يقوم تطبيق Next.js بعد ذلك باسترداد البيانات من قاعدة بيانات Vector.
يتكون نموذج التطبيق من 4 مكونات بسيطة محددة في sst.config.ts :
انضم إلى مجتمع SST على Discord وتابعنا على Twitter.


