في دائرة الذكاء الاصطناعي، يعد يان ليكون، الحائز على جائزة تورينج، شخصية متطرفة نموذجية.
في حين أن العديد من الخبراء الفنيين يعتقدون اعتقادًا راسخًا أنه على طول المسار الفني الحالي، فإن تحقيق الذكاء الاصطناعي العام هو مسألة وقت فقط، وقد أثار يان ليكون اعتراضاته مرارًا وتكرارًا.
وفي مناقشات ساخنة مع أقرانه، قال أكثر من مرة إن المسار التكنولوجي السائد الحالي لا يمكن أن يقودنا إلى الذكاء الاصطناعي العام، وحتى المستوى الحالي للذكاء الاصطناعي ليس بجودة القطة.
الحائز على جائزة تورينج، كبير علماء الذكاء الاصطناعي، أستاذ جامعة نيويورك، وما إلى ذلك. هذه الألقاب المبهرة والخبرة العملية الثقيلة في الخطوط الأمامية تجعل من المستحيل على أي منا تجاهل رؤى خبير الذكاء الاصطناعي هذا.

إذًا، ما رأي يان ليكون في مستقبل الذكاء الاصطناعي؟ وفي خطاب عام ألقاه مؤخرا، أوضح مرة أخرى وجهة نظره: لا يمكن للذكاء الاصطناعي أبدا أن يصل إلى مستوى ذكاء قريب من مستوى الإنسان بالاعتماد فقط على التدريب على النصوص.
بعض وجهات النظر هي كما يلي:
1. في المستقبل، سيرتدي الأشخاص بشكل عام نظارات ذكية أو أنواعًا أخرى من الأجهزة الذكية، وستحتوي هذه الأجهزة على أنظمة مساعدة مدمجة لتشكيل فرق افتراضية ذكية شخصية لتحسين الإبداع الشخصي والكفاءة.
2. الغرض من الأنظمة الذكية ليس استبدال البشر، بل تعزيز الذكاء البشري حتى يتمكن الناس من العمل بكفاءة أكبر.
3. حتى القطة الأليفة لديها نموذج في دماغها أكثر تعقيدًا مما يمكن لأي نظام ذكاء اصطناعي أن يبنيه.
4. لم يعد FAIR يركز بشكل أساسي على نماذج اللغة، ولكنه يتحرك نحو الهدف طويل المدى المتمثل في الجيل التالي من أنظمة الذكاء الاصطناعي.
5. لا تستطيع أنظمة الذكاء الاصطناعي تحقيق مستوى ذكاء قريب من المستوى البشري من خلال التدريب على البيانات النصية وحدها.
6. اقترح يان ليكون التخلي عن النماذج التوليدية، والنماذج الاحتمالية، والتعلم المتباين، والتعلم المعزز، وبدلاً من ذلك اعتماد بنية JEPA والنماذج القائمة على الطاقة، معتقدًا أن هذه الأساليب من المرجح أن تعزز تطوير الذكاء الاصطناعي.
7. في حين أن الآلات ستتفوق في نهاية المطاف على الذكاء البشري، إلا أنه سيتم التحكم فيها لأنها مدفوعة بالأهداف.
ومن المثير للاهتمام أنه كانت هناك حلقة قبل بدء الخطاب.
عندما قدم المضيف LeCun، أطلق عليه لقب كبير علماء الذكاء الاصطناعي في معهد فيسبوك لأبحاث الذكاء الاصطناعي (FAIR) .
وفي هذا الصدد، أوضح LeCun قبل الخطاب أن حرف "F" في FAIR لم يعد يمثل Facebook، ولكنه يعني " أساسي ".
تم تجميع النص الأصلي للخطاب أدناه بواسطة APPSO وتم تحريره. وأخيراً مرفق رابط الفيديو الأصلي: https://www.youtube.com/watch?v=4DsCtgtQlZU
الذكاء الاصطناعي لا يفهم العالم كما تفعل قطتك
حسنًا، سأتحدث عن الذكاء الاصطناعي على المستوى البشري وكيف سنصل إلى هناك ولماذا لن نصل إلى هناك.
أولا، نحن حقا بحاجة إلى الذكاء الاصطناعي على المستوى البشري.
لأنه في المستقبل، سيرتدي معظمنا نظارات ذكية أو أنواعًا أخرى من الأجهزة. سنتحدث إلى هذه الأجهزة، وستستضيف هذه الأنظمة مساعدين، ربما أكثر من واحد، وربما مجموعة كاملة من المساعدين.
سيؤدي هذا إلى أن يكون لكل واحد منا فريق افتراضي ذكي يعمل لصالحنا.
لذلك، سيصبح الجميع "رئيسًا"، لكن هؤلاء "الموظفين" ليسوا بشرًا حقيقيين. نحن بحاجة إلى بناء أنظمة مثل هذه، بشكل أساسي لزيادة الذكاء البشري وجعل الناس أكثر إبداعًا وكفاءة.

ولكن لتحقيق ذلك، نحتاج إلى آلات يمكنها فهم العالم، وتذكر الأشياء، ولديها الحدس والحس السليم، والتفكير والتخطيط على نفس مستوى البشر.
على الرغم من أنك ربما سمعت بعض المؤيدين يقولون إن أنظمة الذكاء الاصطناعي الحالية لا تمتلك هذه القدرات. لذلك نحن بحاجة إلى أن نأخذ الوقت الكافي لتعلم كيفية نمذجة العالم، ليكون لدينا نماذج ذهنية لكيفية عمل العالم.
تقريبا كل حيوان لديه مثل هذا النموذج. يجب أن يكون لدى قطتك نموذج أكثر تعقيدًا مما يمكن لأي نظام ذكاء اصطناعي أن يبنيه أو يصممه.

نحن بحاجة إلى نظام يتمتع بذاكرة ثابتة لا تمتلكها نماذج اللغة الحالية (LLMs) ، ونظام يمكنه تخطيط تسلسلات معقدة من الإجراءات التي لا تستطيع أنظمة اليوم القيام بها، ونظام آمن وقابل للتحكم.
لذلك، سأقترح بنية تسمى الذكاء الاصطناعي الموجه نحو الهدف. لقد كتبت ورقة رؤية حول هذا الموضوع منذ حوالي عامين ونشرتها. يعمل العديد من الأشخاص في FAIR بجد لجعل هذه الخطة حقيقة واقعة.
عملت FAIR على المزيد من المشاريع التطبيقية في الماضي، لكن Meta أنشأت قسمًا للمنتجات يسمى Geneative AI (Gen AI) منذ عام ونصف للتركيز على منتجات الذكاء الاصطناعي.
إنهم يقومون بالبحث والتطوير التطبيقي، لذلك تم الآن إعادة توجيه FAIR نحو الهدف طويل المدى المتمثل في أنظمة الذكاء الاصطناعي من الجيل التالي. لم نعد نركز بشكل أساسي على نماذج اللغة.
يعتمد نجاح الذكاء الاصطناعي، بما في ذلك نماذج اللغات الكبيرة (LLMs) ، وخاصة نجاح العديد من الأنظمة الأخرى على مدى السنوات الخمس أو الستة الماضية، على مجموعة من التقنيات، بما في ذلك، بالطبع، التعلم الخاضع للإشراف الذاتي.

إن جوهر التعلم الخاضع للإشراف الذاتي هو تدريب النظام ليس على أي مهمة محددة، ولكن في محاولة تمثيل البيانات المدخلة بطريقة جيدة. إحدى الطرق لتحقيق ذلك هي من خلال التعافي من الأضرار وإعادة البناء.
لذا يمكنك أخذ جزء من النص وإفساده عن طريق إزالة بعض الكلمات أو تغيير كلمات أخرى. يمكن استخدام هذه العملية للنص أو تسلسل الحمض النووي أو البروتينات أو أي شيء آخر، وحتى الصور إلى حد ما. ثم تقوم بعد ذلك بتدريب شبكة عصبية ضخمة لإعادة بناء المدخلات الكاملة، أي النسخة غير التالفة.
هذا نموذج توليدي لأنه يحاول إعادة بناء الإشارة الأصلية.
إذًا، المربع الأحمر يشبه دالة التكلفة، أليس كذلك؟ فهو يحسب المسافة بين المدخلات Y والمخرجات المعاد بناؤها y، وهذه هي المعلمة التي يجب تقليلها أثناء عملية التعلم. في هذه العملية، يتعلم النظام تمثيلاً داخليًا للمدخلات، والذي يمكن استخدامه لمختلف المهام اللاحقة.
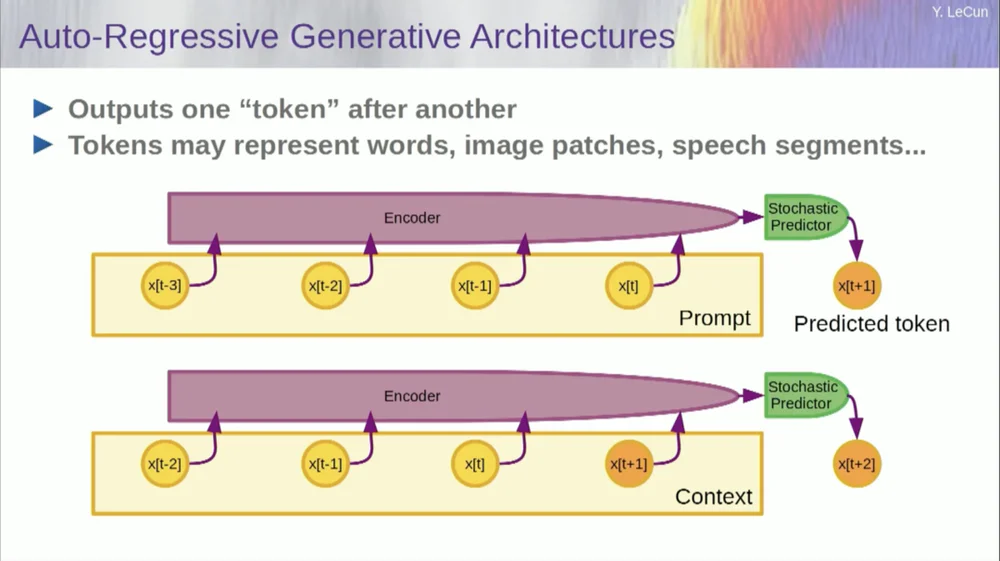
بالطبع، يمكن استخدام هذا للتنبؤ بالكلمات في النص، وهو ما يفعله التنبؤ الانحداري التلقائي .
تعد نماذج اللغة حالة خاصة من ذلك، حيث تم تصميم البنية بطريقة بحيث عند التنبؤ بعنصر أو رمز مميز أو كلمة، يمكنها فقط النظر إلى الرموز المميزة الأخرى الموجودة على يسارها.
ولا يستطيع النظر إلى المستقبل. إذا قمت بتدريب نظام بشكل صحيح، وعرضت عليه نصًا، وطلبت منه التنبؤ بالكلمة التالية أو الرمز المميز التالي في النص، فيمكنك استخدام النظام للتنبؤ بالكلمة التالية. ثم تضيف الكلمة التالية إلى الإدخال، وتتنبأ بالكلمة الثانية، وتضيفها إلى الإدخال، وتتنبأ بالكلمة الثالثة.
هذا هو التنبؤ الانحداري الذاتي .
هذا ما يفعله طلاب ماجستير إدارة الأعمال، وهو ليس مفهومًا جديدًا، فهو موجود منذ زمن شانون ، ويعود تاريخه إلى الخمسينيات، أي منذ وقت طويل، ولكن التغيير هو أننا أصبح لدينا الآن تلك البنى التحتية الضخمة للشبكات العصبية، ويمكنك التدريب عليها على كميات كبيرة من البيانات والميزات سوف تظهر للخروج منه.
لكن هذا النوع من التنبؤ الانحداري له بعض القيود الرئيسية، ولا يوجد منطق حقيقي هنا بالمعنى المعتاد.
هناك قيد آخر وهو أن هذا لا يعمل إلا مع البيانات التي تكون في شكل كائنات منفصلة، أو رموز، أو رموز، أو كلمات، وما إلى ذلك، وهي في الأساس أشياء يمكن فصلها.
ما زلنا نفتقد شيئًا مهمًا عندما يتعلق الأمر بالوصول إلى مستوى الذكاء البشري.
أنا لا أتحدث بالضرورة عن مستوى الذكاء البشري هنا، ولكن حتى قطتك أو كلبك يمكنه إنجاز بعض الأعمال البطولية المذهلة التي هي بعيدة عن متناول أنظمة الذكاء الاصطناعي الحالية.

يمكن لأي طفل يبلغ من العمر 10 أعوام أن يتعلم تنظيف الطاولة وملء غسالة الأطباق في جلسة واحدة، أليس كذلك؟ لا حاجة للتدرب أو أي شيء من هذا القبيل، أليس كذلك؟
يستغرق الأمر حوالي 20 ساعة من التدريب لشاب يبلغ من العمر 17 عامًا لتعلم القيادة.
ما زلنا لا نملك سيارات ذاتية القيادة من المستوى الخامس، وبالتأكيد ليس لدينا روبوتات منزلية قادرة على تنظيف الطاولات وملء غسالات الأطباق.
لن يصل الذكاء الاصطناعي أبدًا إلى ما يقرب من مستوى الذكاء البشري من خلال التدريب على النص وحده
لذا، نحن نفتقد حقًا شيئًا مهمًا، وإلا لكان بإمكاننا القيام بهذه الأشياء باستخدام أنظمة الذكاء الاصطناعي.
نستمر في مواجهة ما يسمى مفارقة مورافيك ، وهي أن الأشياء التي تبدو تافهة بالنسبة لنا ولا تعتبر حتى ذكية، يصعب فعلها في الواقع باستخدام الآلات، وأشياء مثل التلاعب بالتفكير المجرد المعقد عالي المستوى مثل اللغة. الأمر بسيط جدًا بالنسبة للآلات، وينطبق الشيء نفسه على أشياء مثل لعب الشطرنج ولعبة Go.
ربما يكون أحد الأسباب هو هذا.
عادةً ما يتم تدريب نموذج اللغة الكبير (LLM) على 20 تريليون رمز.
الرمز المميز هو في الأساس ثلاثة أرباع الكلمة، في المتوسط. لذلك، هناك 1.5 × 10 ^ 13 كلمة في المجموع. يبلغ حجم كل رمز حوالي 3B، وعادةً ما يتطلب ذلك 6 × 1013 بايت.
سيستغرق الأمر بضع مئات الآلاف من السنين حتى يقرأ أي منا هذا، أليس كذلك؟ هذا هو في الأساس كل النصوص العامة على الإنترنت مجتمعة.

لكن فكر في طفل يبلغ من العمر أربع سنوات ظل مستيقظًا لمدة إجمالية تبلغ 16000 ساعة. لدينا مليوني ألياف عصبية بصرية تدخل إلى دماغنا. ينقل كل ليف عصبي البيانات بمعدل 1 بايت في الثانية تقريبًا، وربما نصف بايت في الثانية. تشير بعض التقديرات إلى أن هذا قد يصل إلى 3 مليار في الثانية.
لا يهم، إنه أمر من حيث الحجم على أي حال.
تبلغ كمية البيانات هذه حوالي 10 أس 14 بايت، وهو تقريبًا نفس حجم LLM. لذلك، في غضون أربع سنوات، رأى طفل يبلغ من العمر أربع سنوات قدرًا كبيرًا من البيانات المرئية مثل أكبر نماذج اللغة المدربة على النصوص المتاحة للجمهور على الإنترنت بالكامل.
باستخدام البيانات كنقطة بداية، يخبرنا هذا بعدة أشياء.
أولاً، يخبرنا هذا أننا لن نتمكن أبدًا من تحقيق أي مستوى قريب من مستوى الذكاء البشري بمجرد التدريب على النص. وهذا ببساطة لن يحدث.
ثانيًا، المعلومات البصرية زائدة جدًا عن الحاجة، حيث تنقل كل ألياف عصبية بصرية 1B من المعلومات في الثانية، وهي مضغوطة بالفعل بنسبة 100 إلى 1 مقارنة بالمستقبلات الضوئية في شبكية العين.
يوجد ما يقرب من 60 مليون إلى 100 مليون مستقبل ضوئي في شبكية العين. يتم ضغط هذه المستقبلات الضوئية في مليون من الألياف العصبية بواسطة الخلايا العصبية الموجودة في الجزء الأمامي من شبكية العين. إذن هناك بالفعل ضغط بنسبة 100 إلى 1. ثم بحلول الوقت الذي تصل فيه المعلومات إلى الدماغ، يتم توسيع المعلومات حوالي 50 مرة.
إذن ما أقيسه هو معلومات مضغوطة، لكنها لا تزال زائدة عن الحاجة. والتكرار هو في الواقع ما يتطلبه التعلم الخاضع للإشراف الذاتي. لن يتعلم التعلم الخاضع للإشراف الذاتي إلا الأشياء المفيدة من البيانات الزائدة عن الحاجة. إذا كانت البيانات مضغوطة للغاية، مما يعني أن البيانات تصبح ضوضاء عشوائية، فلن تتمكن من تعلم أي شيء.
أنت بحاجة إلى التكرار لتعلم أي شيء. تحتاج إلى معرفة البنية الأساسية للبيانات. لذلك، نحتاج إلى تدريب النظام على تعلم الفطرة السليمة والفيزياء من خلال مشاهدة مقاطع الفيديو أو العيش في العالم الحقيقي.
قد يكون ترتيب كلماتي مربكًا بعض الشيء، وأريد بشكل أساسي أن أخبركم ما هي بنية الذكاء الاصطناعي الموجهة نحو الهدف. إنها مختلفة تمامًا عن LLMs أو الخلايا العصبية المغذية من حيث أن عملية الاستدلال لا تمر عبر سلسلة من طبقات الشبكة العصبية فحسب، ولكنها في الواقع تقوم بتشغيل خوارزمية تحسين.
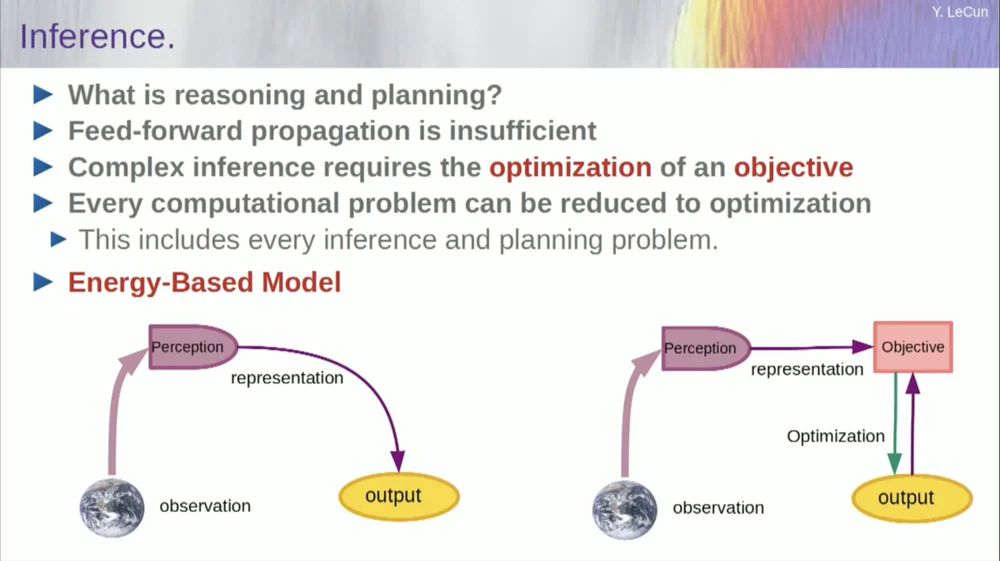
من الناحية النظرية، يبدو الأمر هكذا.
عملية التغذية الأمامية هي عملية يتم فيها تشغيل الملاحظات من خلال نظام إدراكي. على سبيل المثال، إذا كان لديك سلسلة من طبقات الشبكة العصبية وتنتج مخرجًا، فبالنسبة لأي مدخل واحد، يمكنك الحصول على مخرج واحد فقط، ولكن في كثير من الحالات، بالنسبة للإدراك، قد يكون هناك العديد من تفسيرات المخرجات المحتملة. أنت بحاجة إلى عملية رسم خرائط لا تحسب الوظائف فحسب، بل توفر مخرجات متعددة لإدخال واحد. الطريقة الوحيدة لتحقيق ذلك هي من خلال الوظائف الضمنية.
في الأساس، يمثل المربع الأحمر الموجود على الجانب الأيمن من إطار الهدف هذا وظيفة تقيس بشكل أساسي التوافق بين المدخلات والمخرجات المقترحة، ثم تحسب المخرجات من خلال إيجاد قيمة المخرجات الأكثر توافقًا مع المدخلات. يمكنك أن تتخيل أن هذا الهدف هو نوع من دالة الطاقة، وأنك تقوم بتقليل هذه الطاقة من خلال الإخراج كمتغير.
قد يكون لديك حلول متعددة، وقد يكون لديك طريقة ما للتعامل مع تلك الحلول المتعددة. وينطبق هذا على الجهاز الإدراكي البشري. إذا كان لديك تفسيرات متعددة لإدراك معين، فسوف يتنقل دماغك تلقائيًا بين تلك التفسيرات. لذلك هناك بعض الأدلة على أن هذا النوع من الأشياء يحدث بالفعل.
ولكن اسمحوا لي أن أعود إلى الهندسة المعمارية. لذا استفد من مبدأ الاستدلال هذا عن طريق التحسين. فيما يلي الافتراضات، إذا صح التعبير، حول الطريقة التي يعمل بها العقل البشري. يمكنك إجراء ملاحظات في العالم. يمنحك النظام الإدراكي فكرة عن الوضع الحالي للعالم. لكن بالطبع، فهو لا يعطيك سوى فكرة عن حالة العالم التي يمكنك إدراكها حاليًا.
قد تكون لديك بعض الأفكار التي تتذكرها حول حالة بقية العالم. ويمكن دمج هذا مع محتويات الذاكرة وإدخاله في نموذج للعالم.
ما هو النموذج؟ النموذج العالمي هو نموذج عقلي لكيفية تصرفك في العالم، بحيث يمكنك تخيل سلسلة من الإجراءات التي قد تقوم بها، وسيسمح لك نموذج العالم الخاص بك بالتنبؤ بتأثير تلك التسلسلات من الإجراءات على العالم.
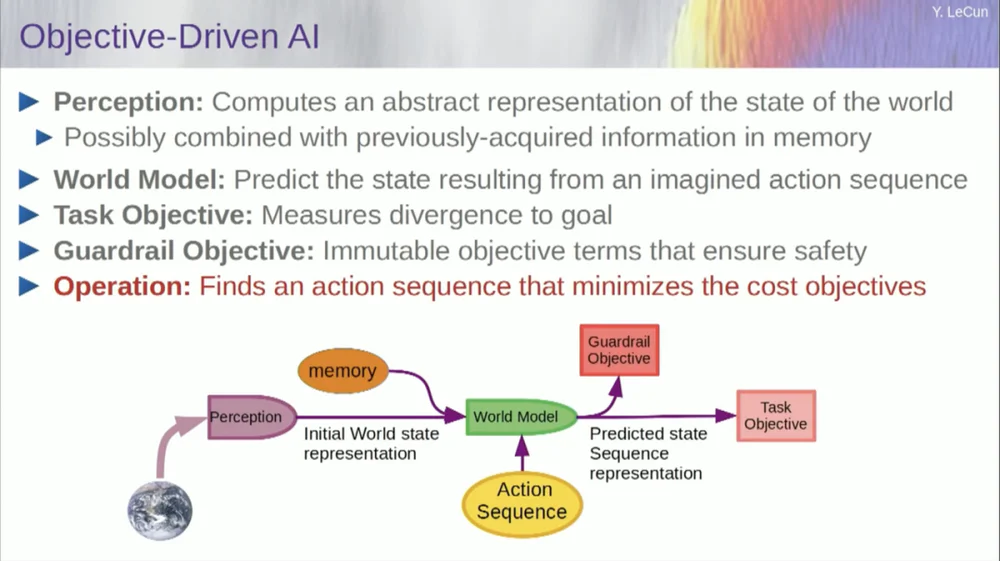
لذا فإن الصندوق الأخضر يمثل النموذج العالمي الذي تغذي فيه سلسلة افتراضية من الإجراءات التي تتنبأ بالحالة النهائية للعالم، أو المسار الكامل الذي تتوقعه سيحدث في العالم.
يمكنك دمج ذلك مع مجموعة من الوظائف الموضوعية. أحد الأهداف هو قياس مدى نجاح تحقيق الهدف، وما إذا كانت المهمة قد اكتملت، وربما مجموعة من الأهداف الأخرى التي تكون بمثابة هوامش أمان، وقياس مدى اتباع المسار أو الإجراء المتخذ لا يشكل أي خطر على الروبوت أو الأشخاص المحيطين بالجهاز، وما إلى ذلك، انتظر.
لذا فإن عملية التفكير الآن (لم أتحدث عن التعلم بعد) هي مجرد تفكير وتتكون من إيجاد تسلسلات من الإجراءات التي تقلل من هذه الأهداف، وإيجاد تسلسلات من الإجراءات التي تقلل من هذه الأهداف. هذه هي عملية التفكير.
لذلك فهي ليست مجرد عملية تغذية. يمكنك القيام بذلك عن طريق البحث عن خيارات منفصلة، ولكن هذا ليس فعالا. الطريقة الأفضل هي التأكد من أن كل هذه المربعات قابلة للتمييز، ويمكنك إعادة نشر التدرج من خلالها ثم تحديث تسلسل الإجراءات عبر نزول التدرج.

الآن، هذه الفكرة في الواقع ليست جديدة وهي موجودة منذ أكثر من 60 عامًا، وربما لفترة أطول. أولاً، اسمحوا لي أن أتحدث عن مزايا استخدام النموذج العالمي لهذا النوع من التفكير. الميزة هي أنه يمكنك إكمال مهام جديدة دون الحاجة إلى أي تعلم.
نحن نفعل هذا من وقت لآخر. عندما نواجه موقفًا جديدًا، نفكر فيه، ونتخيل عواقب أفعالنا، ثم نتخذ سلسلة من الإجراءات التي من شأنها تحقيق هدفنا (مهما كان) ولسنا بحاجة إلى التعلم لإنجاز هذه المهمة ، يمكننا التخطيط. لذلك هذا هو التخطيط في الأساس.
يمكنك تلخيص معظم أشكال الاستدلال وصولاً إلى التحسين. ولذلك، فإن عملية الاستدلال من خلال التحسين هي بطبيعتها أقوى من مجرد الجري عبر طبقات متعددة من الشبكة العصبية. كما قلت، فكرة التفكير من خلال التحسين موجودة منذ أكثر من 60 عامًا.
في مجال نظرية التحكم الأمثل، يسمى هذا بالتحكم التنبئي النموذجي.
لديك نموذج لنظام تريد التحكم فيه، مثل صاروخ أو طائرة أو روبوت. يمكنك أن تتخيل استخدام نموذج العالم الخاص بك لحساب تأثيرات سلسلة من أوامر التحكم.
ثم تقوم بتحسين هذا التسلسل حتى تحقق الحركة النتائج المرجوة. كل تخطيط الحركة في الروبوتات الكلاسيكية يتم بهذه الطريقة، وهذا ليس بالأمر الجديد. الجديد هنا هو أننا سنتعلم نموذجًا للعالم وسيقوم الجهاز الإدراكي باستخراج تمثيل تجريدي مناسب.
الآن، قبل أن أتناول مثالًا لكيفية تشغيل هذا النظام، يمكنك بناء نظام ذكاء اصطناعي شامل بكل هذه المكونات: نموذج عالمي، ووظيفة تكلفة يمكن تهيئتها للمهمة الحالية، ووحدة تحسين (على سبيل المثال، التحسين حقًا، والعثور على الوحدة المعينة التي تحدد التسلسل الأمثل للإجراءات للنموذج العالمي) ، والذاكرة قصيرة المدى، والنظام الإدراكي، وما إلى ذلك.
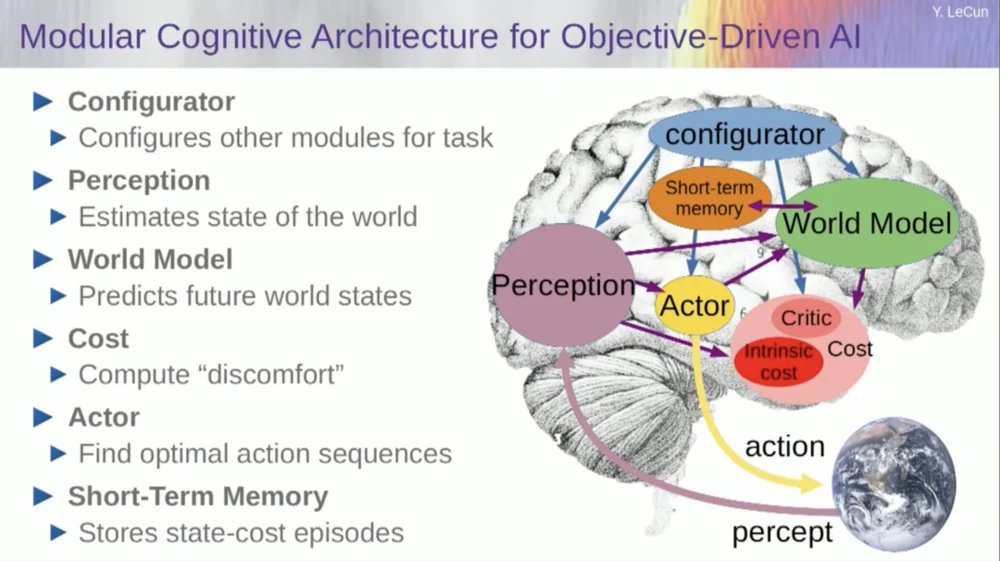
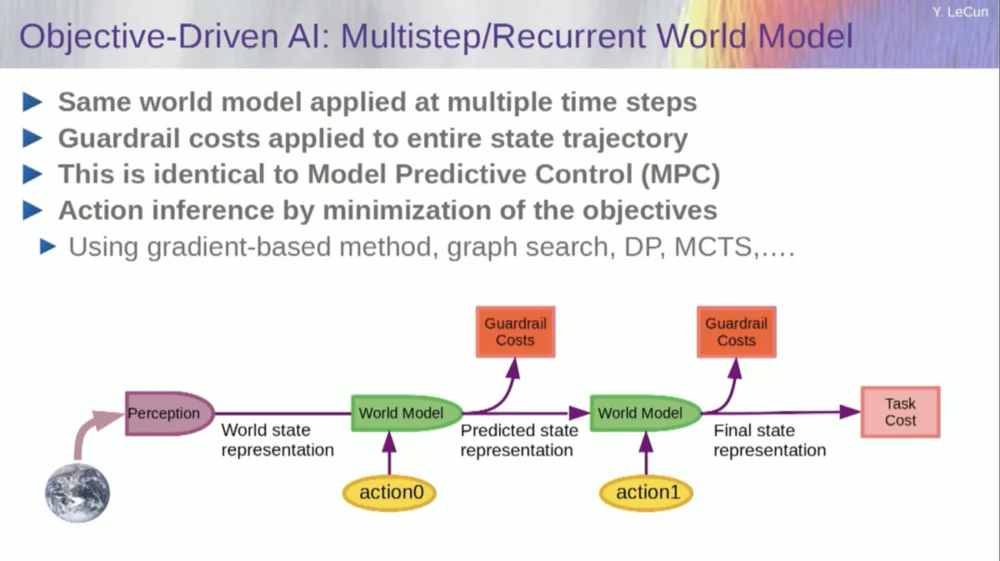
إذًا، كيف يعمل هذا؟ إذا لم يكن الإجراء الخاص بك إجراءً واحدًا، بل سلسلة من الإجراءات، وكان نموذج العالم الخاص بك هو في الواقع نظام يخبرك، بالنظر إلى حالة العالم في الوقت T والأفعال المحتملة، توقع حالة العالم في الوقت T+1.
أنت تريد التنبؤ بتأثير سلسلة من الإجراءين في هذه الحالة. يمكنك تشغيل النموذج العالمي الخاص بك عدة مرات لتحقيق ذلك.
احصل على التمثيل الأولي لحالة العالم، وأدخل افتراض الصفر للإجراء، واستخدم النموذج للتنبؤ بالحالة التالية، ثم نفذ الإجراء الأول، واحسب الحالة التالية، واحسب التكلفة، ثم استخدم الانتشار العكسي وأساليب التحسين المستندة إلى التدرج اكتشف ما الذي سيقلل من تكلفة إجراءين. هذا هو نموذج التحكم التنبئي.
الآن، العالم ليس حتميًا تمامًا، لذلك عليك استخدام المتغيرات الكامنة لتناسب نموذجك عن العالم. المتغيرات الكامنة هي في الأساس متغيرات يمكن تبديلها ضمن مجموعة من البيانات أو استخلاصها من التوزيع، وهي تمثل تبديل نموذج للعالم بين تنبؤات متعددة متوافقة مع الملاحظات.
والأمر الأكثر إثارة للاهتمام هو أن الأنظمة الذكية غير قادرة حاليًا على القيام بشيء يمكن للبشر وحتى الحيوانات القيام به، وهو التخطيط الهرمي.
على سبيل المثال، إذا كنت تخطط لرحلة من نيويورك إلى باريس، فيمكنك استخدام فهمك للعالم، ولجسدك، وربما فكرتك عن التكوين الكامل للوصول من هنا إلى باريس للتخطيط لرحلتك بأكملها مع التحكم في العضلات على مستوى منخفض.
يمين؟ إذا قمت بجمع عدد خطوات التحكم في العضلات لكل عشرة مللي ثانية من كل الأشياء التي عليك القيام بها قبل الذهاب إلى باريس، فهو رقم ضخم. إذن ما تفعله هو أنك تخطط بطريقة تخطيط هرمية، حيث تبدأ بمستوى عالٍ جدًا وتقول، حسنًا، للوصول إلى باريس، أحتاج أولاً إلى الذهاب إلى المطار، وركوب الطائرة.
كيف أصل إلى المطار؟ لنفترض أنني في مدينة نيويورك ويجب أن أذهب إلى الطابق السفلي وأحصل على سيارة أجرة. كيف يمكنني النزول إلى الطابق السفلي؟ لا بد لي من النهوض من الكرسي، وفتح الباب، والمشي إلى المصعد، والضغط على الزر، وما إلى ذلك. كيف أقوم من الكرسي؟
في مرحلة ما، سيتعين عليك التعبير عن الأشياء على أنها إجراءات تحكم في العضلات منخفضة المستوى، لكننا لا نخطط للأمر برمته بطريقة منخفضة المستوى، بل نقوم بالتخطيط الهرمي.

لا تزال كيفية القيام بذلك باستخدام أنظمة الذكاء الاصطناعي دون حل تمامًا وليس لدينا أدنى فكرة.
يبدو أن هذا مطلب مهم للسلوك الذكي.
إذًا، كيف نتعلم النماذج العالمية القادرة على التخطيط الهرمي، والقادرة على العمل على مستويات مختلفة من التجريد؟ لم يظهر أحد أي شيء قريب من هذا. وهذا يشكل تحديا كبيرا. الصورة توضح المثال الذي ذكرته للتو.
فكيف ندرب هذا النموذج العالمي الآن؟ لأن هذه مشكلة كبيرة بالفعل.
أحاول معرفة العمر الذي يتعلم فيه الأطفال المفاهيم الأساسية عن العالم. كيف يتعلمون الفيزياء البديهية، والحدس الجسدي، وكل تلك الأشياء؟ يحدث هذا قبل فترة طويلة من بدء تعلم أشياء مثل اللغة والتفاعل.
لذا فإن الإمكانيات مثل تتبع الوجه تحدث في وقت مبكر جدًا. الحركة البيولوجية، وهي التمييز بين الأشياء الحية وغير الحية، ظهرت أيضًا مبكرًا. الأمر نفسه ينطبق على ثبات الكائن، والذي يشير إلى حقيقة أن الكائن يستمر عندما يتم إعاقته بواسطة كائن آخر.
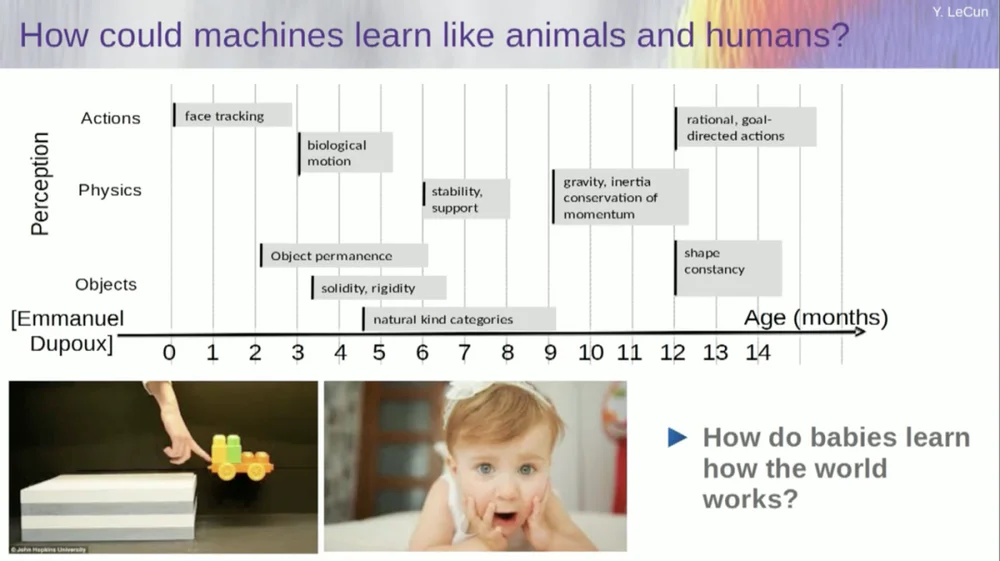
ويتعلم الأطفال بشكل طبيعي، ولا تحتاج إلى إعطائهم أسماء للأشياء. سيعرفون أن الكراسي والطاولات والقطط مختلفة. أما مفاهيم مثل الاستقرار والدعم، مثل الجاذبية والقصور الذاتي والحفظ والزخم، فهي في الواقع لا تظهر إلا بعد حوالي تسعة أشهر من العمر.
وهذا يستغرق وقتا طويلا. لذا، إذا عرضت لطفل عمره ستة أشهر السيناريو على اليسار، حيث تكون العربة على منصة، ودفعتها خارج المنصة، فإنها تبدو وكأنها تطفو في الهواء. سيلاحظ الطفل البالغ من العمر ستة أشهر ذلك، بينما سيشعر الطفل البالغ من العمر عشرة أشهر أن هذا لا ينبغي أن يحدث وأن الجسم يجب أن يسقط.
عندما يحدث شيء غير متوقع، فهذا يعني أن "نموذج العالم" الخاص بك خاطئ. لذلك انتبه لأنه قد يقتلك.
لذا فإن نوع التعلم الذي يجب أن يحدث هنا يشبه إلى حد كبير نوع التعلم الذي ناقشناه سابقًا.
خذ المدخلات، وأفسدها بطريقة ما، ثم قم بتدريب شبكة عصبية كبيرة للتنبؤ بالأجزاء المفقودة. إذا قمت بتدريب نظام ما على التنبؤ بما سيحدث في مقطع فيديو، تمامًا كما ندرب الشبكات العصبية على التنبؤ بما سيحدث في النص، فربما تكون هذه الأنظمة قادرة على تعلم المنطق السليم.
لسوء الحظ، كنا نحاول هذا لمدة عشر سنوات وكان فشلًا ذريعًا. لم نقترب أبدًا من نظام يمكنه في الواقع تعلم أي معرفة عامة بمجرد محاولة توقع وحدات البكسل في الفيديو.
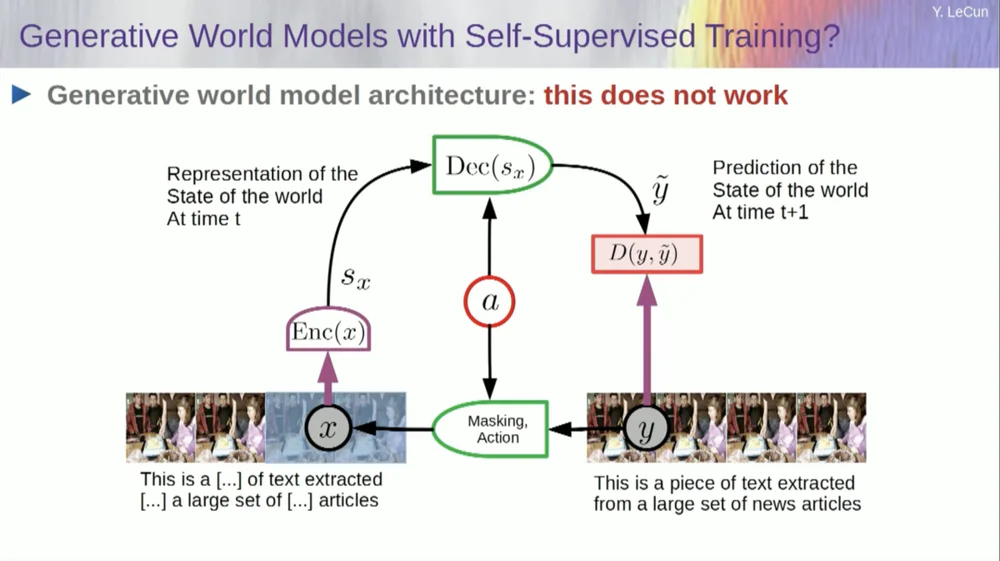
يمكنك تدريب نظام للتنبؤ بمقاطع الفيديو التي تبدو جيدة. هناك العديد من الأمثلة على أنظمة توليد الفيديو، لكنها داخليًا ليست نماذج جيدة للعالم المادي. لا يمكننا أن نفعل هذا معهم.
حسنًا، فكرة أننا سنستخدم النماذج التوليدية للتنبؤ بما سيحدث للأفراد، وسيفهم النظام بطريقة سحرية بنية العالم، هي فكرة فاشلة تمامًا.
لقد جربنا العديد من الأساليب على مدى العقد الماضي.
لقد فشل لأن هناك العديد من العقود المستقبلية المحتملة. في مساحة منفصلة مثل النص، حيث يمكنك التنبؤ بالكلمة التي ستتبع سلسلة من الكلمات، يمكنك إنشاء توزيع احتمالي على الكلمات المحتملة في القاموس. ولكن عندما يتعلق الأمر بإطارات الفيديو، ليس لدينا طريقة جيدة لتمثيل التوزيع الاحتمالي لإطارات الفيديو. في الواقع، هذه المهمة مستحيلة تماما.

لقد التقطت فيديو لهذه الغرفة، أليس كذلك؟ أخذت الكاميرا وصورت ذلك الجزء ثم أوقفت الفيديو. سألت النظام ماذا سيحدث بعد ذلك. قد يتنبأ بالغرف المتبقية. سيكون هناك جدار، وسيكون هناك أشخاص يجلسون عليه، ومن المحتمل أن تكون الكثافة مماثلة لتلك الموجودة على اليسار، ولكن من المستحيل تمامًا التنبؤ بدقة على مستوى البكسل بجميع التفاصيل التي سيبدو عليها كل واحد منكم وملمس العالم والحجم الدقيق للغرفة.
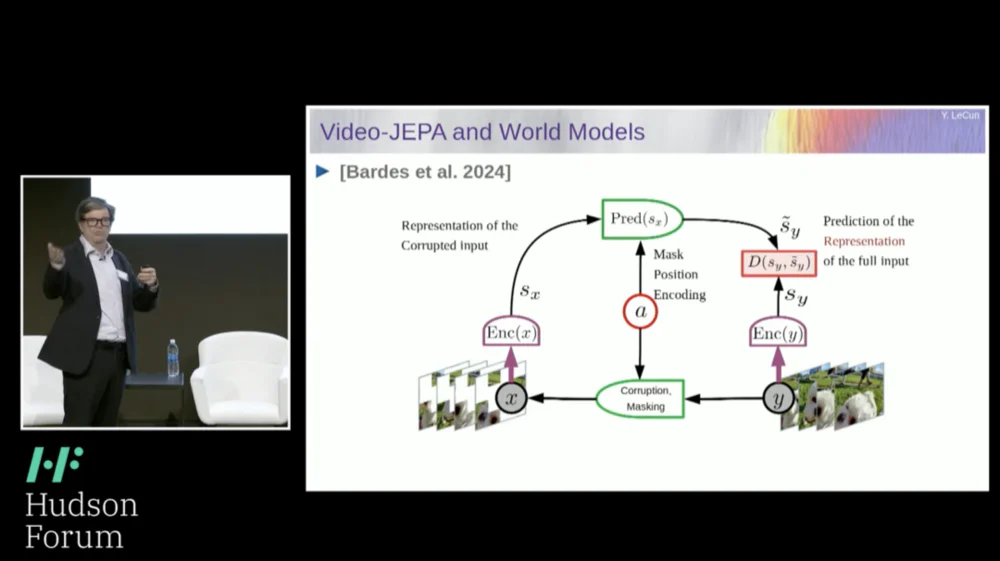
لذا، فإن الحل الذي أقترحه هو بنية التنبؤ بالتضمين المشترك (JEPA) .
تتمثل الفكرة في التخلي عن التنبؤ بالبكسلات وبدلاً من ذلك تعلم تمثيل تجريدي لكيفية عمل العالم ثم إجراء تنبؤات داخل مساحة التمثيل هذه. هذه هي البنية، بنية التنبؤ المشتركة. يأخذ هذان التضمينان X (النسخة التالفة) وY على التوالي، وتتم معالجتهما بواسطة المشفر، ثم يتم تدريب النظام على التنبؤ بتمثيل Y بناءً على تمثيل X.
المشكلة الآن هي أنه إذا قمت بتدريب مثل هذا النظام باستخدام النسب المتدرج والانتشار العكسي لتقليل خطأ التنبؤ، فسوف ينهار. قد يتعلم تمثيلًا ثابتًا بحيث تصبح التنبؤات بسيطة جدًا، ولكنها غير مفيدة.
لذا ما أريدك أن تتذكره هو الفرق بين أجهزة التشفير التلقائي، والبنيات التوليدية، وأجهزة التشفير التلقائي المقنعة، وما إلى ذلك، التي تحاول إعادة بناء التنبؤات، مقابل بنيات التضمين المشتركة التي تقوم بالتنبؤات في مساحة التمثيل.
أعتقد أن المستقبل يكمن في بنيات التضمين المشتركة هذه، ولدينا الكثير من الأدلة التجريبية على أن أفضل طريقة لتعلم تمثيلات الصور الجيدة هي استخدام بنيات التحرير المشتركة.
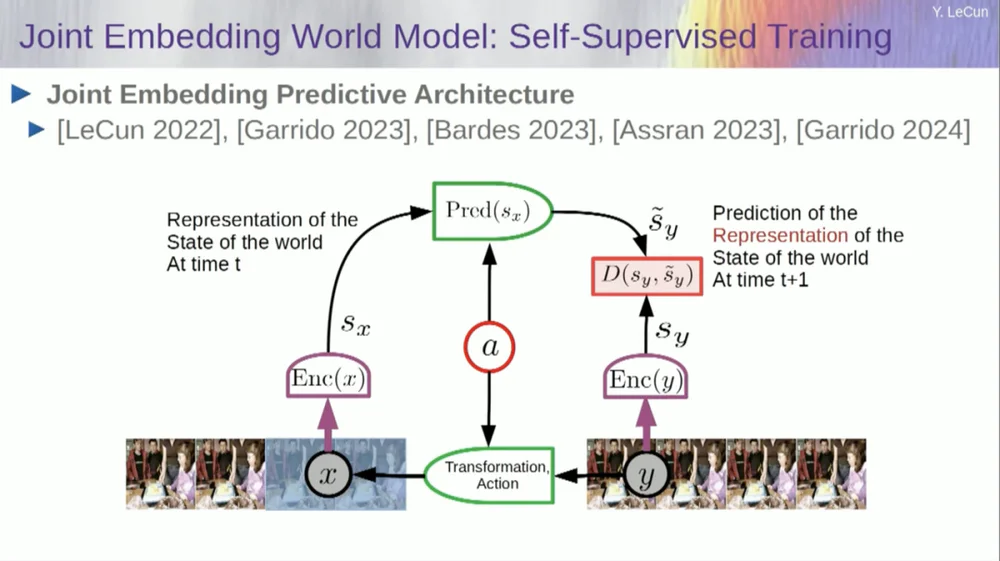
جميع المحاولات لتعلم تمثيل الصور من خلال إعادة البناء كانت سيئة ولا تعمل بشكل جيد، وعلى الرغم من وجود العديد من المشاريع الكبيرة التي تدعي أنها تعمل، إلا أنها لا تفعل ذلك، ويتم الحصول على أفضل أداء مع الهندسة المعمارية على اليمين.
الآن، إذا فكرتم في الأمر، هذا هو ما يدور حوله ذكائنا: العثور على تمثيل جيد لظاهرة ما حتى نتمكن من التنبؤ، هذا هو ما يدور حوله العلم حقًا.
حقيقي. فكر في الأمر، إذا كنت تريد التنبؤ بمسار كوكب ما، فالكوكب هو جسم معقد للغاية، وهو ضخم، وله جميع أنواع الخصائص مثل الطقس ودرجة الحرارة والكثافة.
على الرغم من كونه جسمًا معقدًا، للتنبؤ بمسار كوكب ما، فأنت تحتاج فقط إلى معرفة 6 أرقام: 3 إحداثيات للموقع و3 متجهات للسرعة، هذا كل شيء، ولا تحتاج إلى القيام بأي شيء آخر. وهذا مثال مهم جدًا يوضح حقًا أن جوهر القوة التنبؤية يكمن في إيجاد تمثيل جيد للأشياء التي نلاحظها.

إذن كيف ندرب مثل هذا النظام؟
لذلك تريد منع النظام من الانهيار. إحدى الطرق للقيام بذلك هي استخدام نوع من دالة التكلفة التي تقيس محتوى المعلومات لمخرجات التمثيل بواسطة المشفر وتحاول زيادة محتوى المعلومات إلى الحد الأقصى وتقليل المعلومات السلبية. يجب أن يستخرج نظام التدريب الخاص بك في نفس الوقت أكبر قدر ممكن من المعلومات من المدخلات مع تقليل خطأ التنبؤ في مساحة التمثيل هذه.
سيجد النظام بعض المفاضلة بين استخراج أكبر قدر ممكن من المعلومات وعدم استخراج معلومات غير متوقعة. سوف تحصل على مساحة تمثيل جيدة يمكن من خلالها إجراء التنبؤات.
الآن، كيف يمكنك قياس المعلومات؟ هذا هو المكان الذي تصبح فيه الأمور غريبة بعض الشيء. سوف أتخطى هذا.
سوف تتفوق الآلات على الذكاء البشري وستكون آمنة ويمكن السيطرة عليها
هناك في الواقع طريقة لفهم ذلك رياضيًا من خلال التدريب والنماذج المعتمدة على الطاقة ووظائف الطاقة، لكن ليس لدي الوقت للخوض فيها.
في الأساس، أنا أخبركم ببعض الأشياء المختلفة هنا: التخلي عن النماذج التوليدية لصالح بنيات JEPA، والتخلي عن النماذج الاحتمالية لصالح تلك النماذج المعتمدة على الطاقة، والتخلي عن أساليب التعلم التباينية، والتعلم المعزز. لقد كنت أقول هذا لمدة 10 سنوات.
وهذه هي الركائز الأربع الأكثر شيوعًا للتعلم الآلي اليوم. لذلك ربما لا أحظى بشعبية كبيرة في الوقت الحالي.
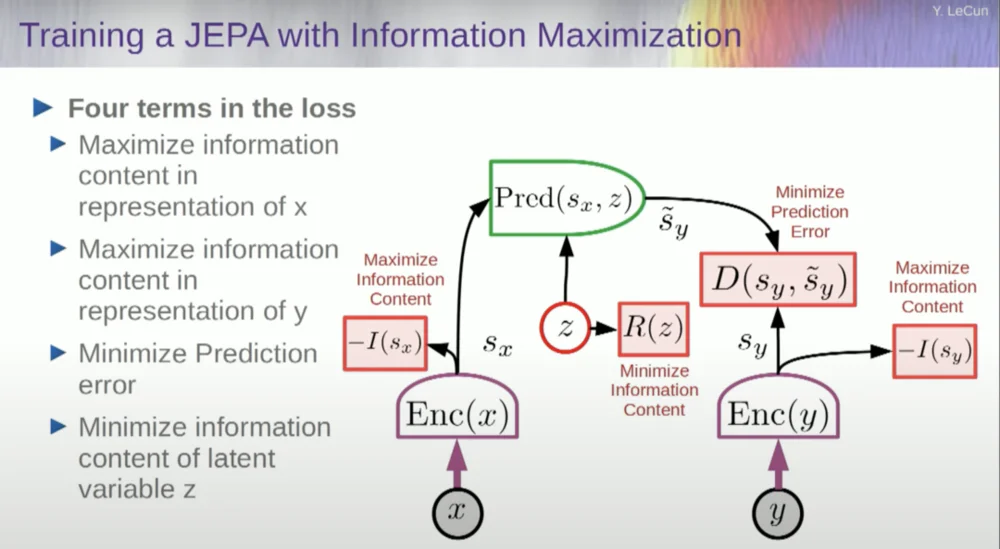
أحد الأساليب هو تقدير محتوى المعلومات، وقياس محتوى المعلومات القادمة من المشفر.
يوجد حاليًا ست طرق مختلفة لتحقيق ذلك. في الواقع، هناك طريقة تسمى MCR، من زملائي في جامعة نيويورك، وهي منع النظام من التعطل وإنتاج الثوابت.
خذ المتغيرات من جهاز التشفير وتأكد من أن هذه المتغيرات لها انحراف معياري غير صفر. يمكنك وضع ذلك في دالة تكلفة والتأكد من البحث في الأوزان وعدم انهيار المتغيرات وتصبح ثوابت. هذا بسيط نسبيا.
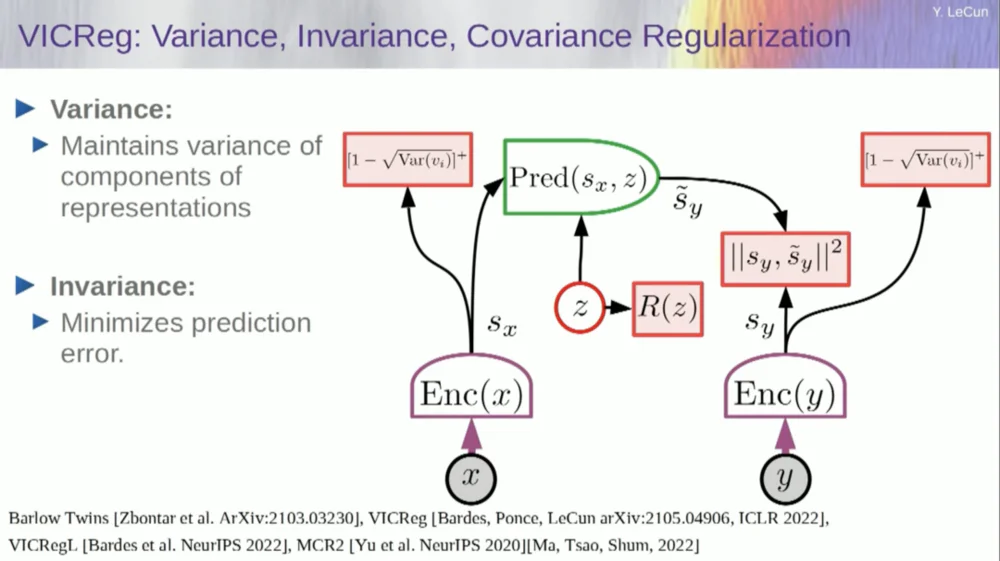
المشكلة الآن هي أن النظام يستطيع "الغش" وجعل جميع المتغيرات متساوية أو مرتبطة بشكل كبير. لذلك، تحتاج إلى إضافة مصطلح آخر، وهو الحد خارج القطر المطلوب لتقليل مصفوفة التغاير المشترك لهذه المتغيرات، للتأكد من ارتباطها ببعضها البعض.
وبطبيعة الحال، هذا لا يكفي، لأن المتغيرات قد لا تزال تابعة، ولكنها ليست ذات صلة. لذلك، نعتمد طريقة أخرى لتوسيع أبعاد SX إلى الفضاء ذي الأبعاد الأعلى VX وتطبيق تنظيم التباين والتباين في هذا الفضاء لضمان استيفاء المتطلبات.
هناك حيلة أخرى هنا، لأن ما أقوم بتعظيمه هو الحد الأعلى لمحتوى المعلومات. أريد أن يتبع محتوى المعلومات الفعلي تعظيم الحد الأعلى. ما أحتاجه هو حد أدنى بحيث يدفع الحد الأدنى وتزداد المعلومات. ولسوء الحظ، ليس لدينا معلومات حول الحدود الدنيا، أو على الأقل لا نعرف كيفية حسابها.
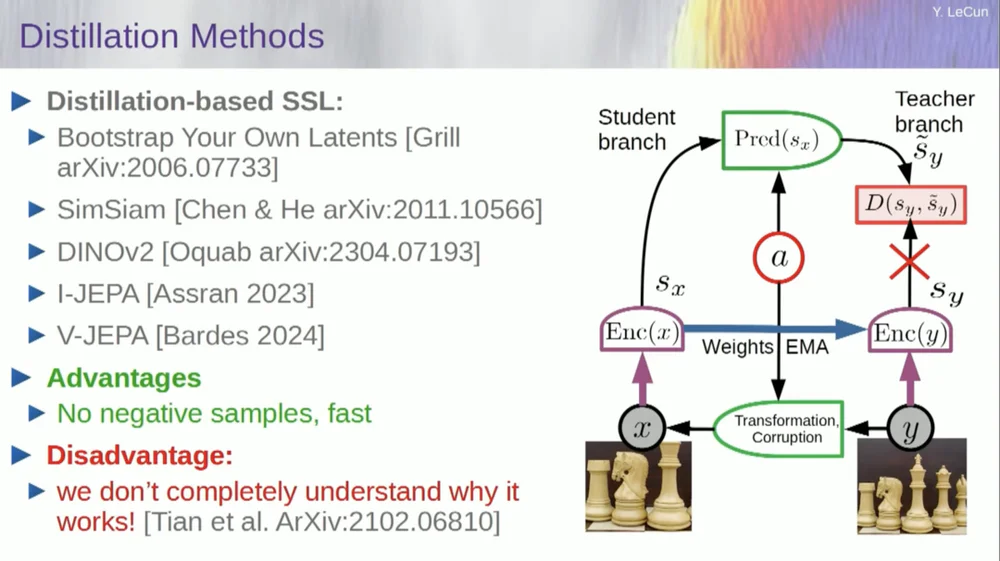
هناك مجموعة ثانية من الطرق تسمى "طريقة التقطير".
تعمل هذه الطريقة بطرق غامضة. إذا كنت تريد أن تعرف بالضبط من يفعل ماذا، عليك أن تسأل الرجل الجالس هنا في مطعم جريل.
لديه مقال شخصي حول هذا الأمر يحدده بشكل جيد للغاية. وتتمثل فكرتها الأساسية في تحديث جزء واحد فقط من النموذج دون التدرجات العكسية في الجزء الآخر ومشاركة الأوزان بطريقة مثيرة للاهتمام. وهناك أيضًا العديد من الأوراق حول هذا الجانب.
يعمل هذا الأسلوب بشكل جيد إذا كنت ترغب في تدريب نظام خاضع للإشراف الذاتي بالكامل لإنشاء تمثيلات صور جيدة. يتم تدمير الصور من خلال الإخفاء، وبعض الأعمال التي قمنا بها مؤخرًا لمقاطع الفيديو تسمح لنا بتدريب نظام لاستخراج تمثيلات فيديو جيدة لاستخدامها في المهام النهائية مثل مقاطع فيديو التعرف على الإجراءات، وما إلى ذلك. يمكنك أن ترى أن إخفاء جزء كبير من الفيديو وإجراء تنبؤات من خلال هذه العملية يستخدم خدعة التقطير هذه في مساحة التمثيل لمنع الانهيار. هذا يعمل بشكل رائع.
لذلك، إذا نجحنا في هذا المشروع وانتهى بنا الأمر إلى أنظمة يمكنها التفكير والتخطيط وفهم العالم المادي، فهذا هو ما ستبدو عليه جميع تفاعلاتنا في المستقبل.
سيستغرق الأمر سنوات، وربما حتى عقدًا من الزمن، حتى يعمل كل شيء بشكل صحيح. يستمر مارك زوكربيرج في سؤالي عن المدة التي سيستغرقها الأمر. إذا نجحنا في القيام بذلك، حسنًا، سيكون لدينا أنظمة تتوسط جميع تفاعلاتنا مع العالم الرقمي. وسوف يجيبون على جميع أسئلتنا.
سيكونون معنا لفترة طويلة وسيشكلون بشكل أساسي مستودعًا لجميع المعرفة الإنسانية. يبدو هذا وكأنه شيء يتعلق بالبنية التحتية، مثل الإنترنت. هذا أقل من المنتج وأكثر من البنية التحتية.
يجب أن تكون منصات الذكاء الاصطناعي هذه مفتوحة المصدر. تشارك IBM وMeta في مجموعة تسمى تحالف الذكاء الاصطناعي التي تروج لمنصات الذكاء الاصطناعي مفتوحة المصدر. نحن بحاجة إلى أن تكون هذه المنصات مفتوحة المصدر لأننا نحتاج إلى التنوع في أنظمة الذكاء الاصطناعي هذه.

نحن بحاجة إليهم أن يفهموا جميع اللغات، وجميع الثقافات، وجميع أنظمة القيم في العالم، ولن تحصل على ذلك من مجرد نظام واحد تنتجه شركة على الساحل الغربي أو الساحل الشرقي للولايات المتحدة. الدول. يجب أن تكون هذه مساهمة من جميع أنحاء العالم.
وبطبيعة الحال، يعد تدريب النماذج المالية مكلفًا للغاية، لذلك لا يتمكن سوى عدد قليل من الشركات من القيام بذلك. إذا تمكنت شركات مثل ميتا من توفير النموذج الأساسي كمصدر مفتوح، فسيتمكن العالم من ضبطه بدقة لتحقيق أغراضه الخاصة. هذه هي الفلسفة التي تتبناها Meta وIBM.

لذا فإن الذكاء الاصطناعي مفتوح المصدر ليس مجرد فكرة جيدة، بل هو ضروري للتنوع الثقافي وربما حتى للحفاظ على الديمقراطية.
سيتم إجراء التدريب والضبط من خلال التعهيد الجماعي أو من خلال نظام بيئي للشركات الناشئة والشركات الأخرى.
أحد الأشياء التي تدفع نمو النظام البيئي لبدء التشغيل في مجال الذكاء الاصطناعي هو توفر نماذج الذكاء الاصطناعي مفتوحة المصدر هذه. كم من الوقت سيستغرق الوصول إلى الذكاء الاصطناعي العام؟ لا أعلم، قد يستغرق الأمر سنوات أو عقودًا.

لقد كانت هناك الكثير من التغييرات على طول الطريق، ولا تزال هناك العديد من المشاكل التي تحتاج إلى حل. ومن المؤكد أن هذا سيكون أكثر صعوبة مما نعتقد. وهذا لا يحدث في يوم واحد، بل هو تطور تدريجي تدريجي.
لذا، ليس الأمر أننا سنكتشف يومًا ما سر الذكاء الاصطناعي العام، ونقوم بتشغيل الآلة ونحصل على الذكاء الفائق على الفور، وسيتم القضاء علينا جميعًا بواسطة الذكاء الفائق، لا، ليس هذا هو الحال.
سوف تتفوق الآلات على الذكاء البشري، لكنها ستكون تحت السيطرة لأنها تحركها الأهداف. نضع لهم الأهداف وهم يحققونها. مثل الكثير منا، هنا قادة في الصناعة أو الأوساط الأكاديمية.
نحن نعمل مع أشخاص أكثر ذكاءً منا، وأنا بالتأكيد أفعل ذلك أيضًا. فقط لأن هناك الكثير من الأشخاص الأكثر ذكاءً مني لا يعني أنهم يريدون السيطرة أو السيطرة، هذه هي حقيقة الأمر. بالطبع هناك مخاطر وراء ذلك، لكني سأترك ذلك للمناقشة لاحقًا، ولكم جزيل الشكر.