في الآونة الأخيرة، أدت شعبية تطبيقات نماذج اللغات الكبيرة (LLM) للذكاء الاصطناعي إلى زيادة المنافسة الشرسة في مجال الأجهزة. أطلقت AMD أحدث سلسلة Strix Point APU، وتظهر معالجات Ryzen AI الخاصة بها مزايا كبيرة في التعامل مع مهام LLM، مع أداء يفوق بكثير سلسلة Lunar Lake من Intel. سيمنحك محرر Downcodes فهمًا متعمقًا لأداء سلسلة Strix Point APU والابتكار التكنولوجي الذي يقف وراءها.
أصدرت AMD مؤخرًا أحدث سلسلة Strix Point APU، مع التركيز على الأداء المتميز للسلسلة في تطبيقات نماذج اللغات الكبيرة (LLM) ذات الذكاء الاصطناعي، متجاوزة بكثير معالجات سلسلة Lunar Lake من Intel. مع استمرار نمو الطلب على أعباء عمل الذكاء الاصطناعي، أصبحت المنافسة على الأجهزة شرسة بشكل متزايد. واستجابة للسوق، أطلقت AMD معالجات الذكاء الاصطناعي المصممة لمنصات الأجهزة المحمولة، بهدف تحقيق أداء أعلى وزمن وصول أقل.
قالت AMD أن معالج Ryzen AI300 من سلسلة ix Point يمكنه زيادة عدد الرموز المميزة التي تتم معالجتها في الثانية بشكل كبير عند معالجة مهام AI LLM. وبالمقارنة مع Core Ultra258V من Intel، فقد تحسن أداء Ryzen AI9375 بنسبة 27٪. على الرغم من أن Core Ultra7V ليس الطراز الأسرع في سلسلة L Lake، إلا أن عدد النواة وعدد الخيوط فيه قريب من معالجات Lunar Lake المتطورة، مما يوضح القدرة التنافسية لمنتجات AMD في هذا المجال.
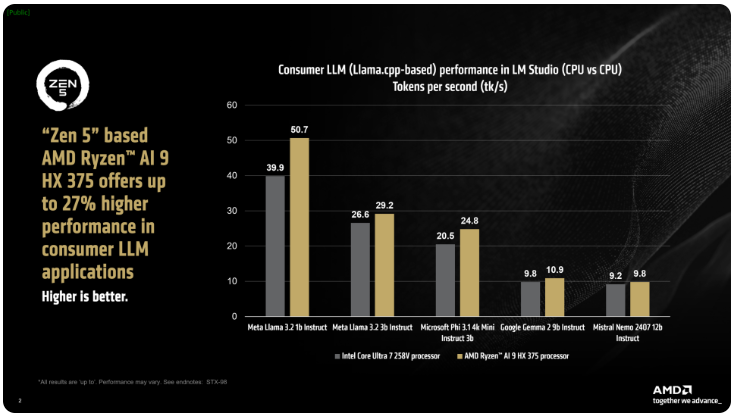
أداة AMD's LM Studio هي تطبيق موجه للمستهلك يعتمد على إطار عمل llama.cpp، وهو مصمم لتبسيط استخدام نماذج اللغات الكبيرة. يعمل الإطار على تحسين أداء وحدات المعالجة المركزية x86. على الرغم من أن وحدة معالجة الرسومات ليست مطلوبة لتشغيل LLM، إلا أن استخدام وحدة معالجة الرسومات يمكن أن يزيد من تسريع المعالجة. وفقًا للاختبار، يمكن لـ Ryzen AI9HX375 تحقيق زمن وصول أقل بمقدار 35 مرة في نموذج Meta Llama3.21b Instruct، ومعالجة 50.7 رمزًا في الثانية، وبالمقارنة، فإن Core Ultra7258V لا يتجاوز 39.9 رمزًا.
ليس هذا فحسب، فقد تم تجهيز Strix Point APU أيضًا ببطاقة رسومات مدمجة قوية من طراز Radeon تعتمد على بنية RDNA3.5، والتي يمكنها تفريغ المهام إلى iGPU من خلال واجهة ulkan API لتحسين أداء LLM بشكل أكبر. باستخدام تقنية ذاكرة الرسومات المتغيرة (VGM)، يمكن لمعالج Ryzen AI300 تحسين تخصيص الذاكرة، وتحسين كفاءة الطاقة، وفي النهاية تحقيق تحسين في الأداء يصل إلى 60%.
في اختبارات المقارنة، استخدمت AMD نفس الإعدادات على منصة Intel AI Playground ووجدت أن Ryzen AI9HX375 كان أسرع بنسبة 87% من Core Ultra7258V على Microsoft Phi3.1 وأسرع بنسبة 13% على طراز Mistral7b Instruct0.3. ومع ذلك، فإن النتائج أكثر إثارة للاهتمام عند مقارنتها بـ Core Ultra9288V، الرائد في سلسلة Lunar Lake. حاليًا، تركز AMD على جعل استخدام نماذج اللغات الكبيرة أكثر شيوعًا من خلال LM Studio، بهدف تسهيل الأمر على المزيد من المستخدمين غير التقنيين للبدء.
يمثل إطلاق سلسلة AMD Strix Point APU مزيدًا من تكثيف المنافسة في مجال معالجات الذكاء الاصطناعي، ويشير أيضًا إلى أن تطبيقات الذكاء الاصطناعي المستقبلية ستحظى بدعم أكثر قوة للأجهزة. ستوفر تحسينات الأداء وكفاءة الطاقة للمستخدمين تجربة ذكاء اصطناعي أكثر سلاسة وقوة. سيستمر محرر Downcodes في الاهتمام بأحدث التطورات في هذا المجال وتقديم المزيد من التقارير المثيرة للقراء.