في مجال توليد صور الذكاء الاصطناعي وفهمها، غالبًا ما تواجه النماذج الحالية التحدي المتمثل في تحقيق التوازن بين قدرات الفهم والتوليد، فهي غير فعالة وتعتمد على عدد كبير من المكونات المدربة مسبقًا. يوفر إطار عمل JanusFlow الذي أطلقته شركة DeepSeek AI فكرة جديدة لحل هذه المشكلة. سيمنحك محرر Downcodes فهمًا متعمقًا لكيفية تحقيق JanusFlow لتوحيد فهم الصور وإنشاءها من خلال التصميم المعماري المبتكر، وتحقيق نتائج رائعة.
على الرغم من التقدم السريع في مجال توليد الصور وفهمها باستخدام الذكاء الاصطناعي، لا تزال هناك تحديات كبيرة تعيق تطوير نهج سلس وموحد.
في الوقت الحالي، تميل النماذج التي تركز على فهم الصور إلى الأداء الضعيف عند إنشاء صور عالية الجودة، والعكس صحيح. لا تؤدي هذه البنية المفصولة عن المهام إلى زيادة التعقيد فحسب، بل تحد أيضًا من الكفاءة، مما يجعل التعامل مع المهام التي تتطلب الفهم والإبداع أمرًا مرهقًا. بالإضافة إلى ذلك، تعتمد العديد من النماذج الحالية بشكل كبير جدًا على التعديلات المعمارية أو المكونات المدربة مسبقًا لأداء أي وظيفة بفعالية، مما يؤدي إلى مقايضات الأداء وتحديات التكامل.
ولحل هذه المشكلات، أطلقت DeepSeek AI برنامج JanusFlow، وهو إطار عمل قوي للذكاء الاصطناعي مصمم لتوحيد فهم الصور وإنشائها. يحل JanusFlow أوجه القصور المذكورة سابقًا من خلال دمج فهم الصور وتوليدها في بنية موحدة. يتميز هذا الإطار الجديد بتصميم بسيط يجمع بين نماذج اللغة الانحدارية التلقائية والتدفق المصحح، وهو نهج نمذجة توليدي متطور.
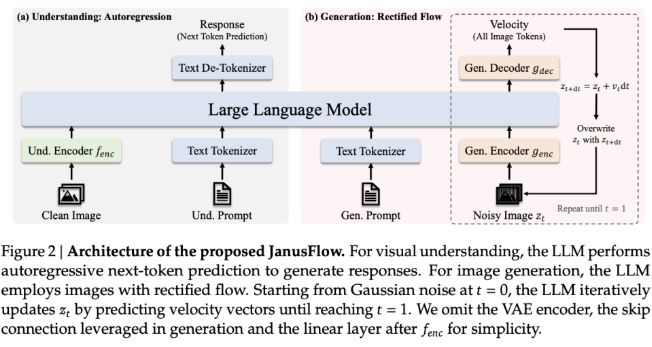
من خلال التخلص من الحاجة إلى مكونات LLM ومكونات توليد منفصلة، يتيح JanusFlow تكاملًا وظيفيًا أكثر إحكامًا مع تقليل التعقيد المعماري. فهو يقدم بنية تشفير وفك تشفير مزدوجة، ويفصل بين مهام الفهم والتوليد، ويضمن اتساق الأداء في مخطط تدريب موحد من خلال محاذاة التمثيلات.
فيما يتعلق بالتفاصيل الفنية، يدمج JanusFlow التدفق التصحيحي ونماذج اللغة الكبيرة بطريقة خفيفة الوزن وفعالة. تشتمل البنية على أجهزة تشفير مرئية مستقلة لمهام الفهم والتوليد. أثناء التدريب، تتم محاذاة أجهزة التشفير هذه مع بعضها البعض لتحسين الاتساق الدلالي، مما يسمح للنظام بأداء جيد في إنشاء الصور ومهام الفهم البصري.
يؤدي هذا الفصل بين أجهزة التشفير إلى منع التداخل بين المهام، وبالتالي تعزيز قدرات كل وحدة. يستخدم النموذج أيضًا التوجيه الخالي من المصنف (CFG) للتحكم في المحاذاة بين الصور التي تم إنشاؤها والظروف النصية، وبالتالي تحسين جودة الصورة. بالمقارنة مع الأنظمة الموحدة التقليدية التي تستخدم نماذج الانتشار كأدوات خارجية، يوفر JanusFlow عملية إنشاء أبسط وأكثر مباشرة مع قيود أقل. تتجلى فعالية هذه البنية من خلال قدرتها على مطابقة أو تجاوز أداء العديد من النماذج الخاصة بالمهام على معايير متعددة.
تكمن أهمية JanusFlow في كفاءته وتعدد استخداماته، مما يسد فجوة حرجة في تطوير النماذج متعددة الوسائط. من خلال التخلص من الحاجة إلى إنشاء وحدات مستقلة وفهمها، يمكّن JanusFlow الباحثين والمطورين من الاستفادة من إطار عمل واحد لمهام متعددة، مما يقلل بشكل كبير من التعقيد واستخدام الموارد.
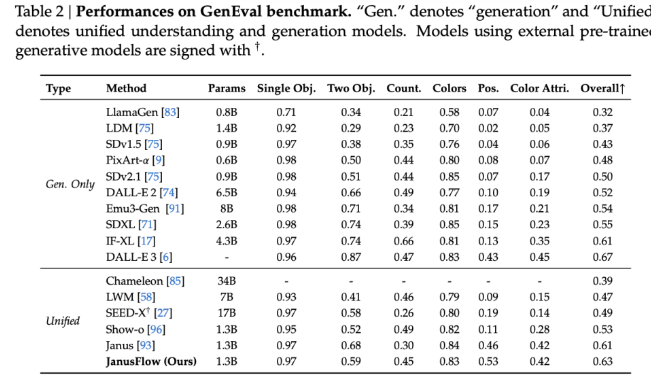
تظهر النتائج المعيارية أن JanusFlow يتفوق على العديد من النماذج الموحدة الحالية بدرجات 74.9 و70.5 و60.3 على MMBench وSeedBench وGQA على التوالي. فيما يتعلق بتوليد الصور، تجاوز JanusFlow SDv1.5 وSDXL، بنتيجة 9.51 لـ MJHQ FID-30k ودرجة 0.63 لـ GenEval. تُظهر هذه المقاييس قدرتها الممتازة على إنشاء صور عالية الجودة والتعامل مع المهام المعقدة متعددة الوسائط باستخدام معلمات تبلغ 1.3 مليار فقط.
في الختام، اتخذت JanusFlow خطوة مهمة نحو تطوير نموذج موحد للذكاء الاصطناعي قادر على فهم الصور وتوليدها في وقت واحد. إن نهجها البسيط - الذي يركز على دمج قدرات الانحدار الذاتي مع التدفقات التصحيحية - لا يعمل على تحسين الأداء فحسب، بل يبسط أيضًا بنية النموذج، مما يجعله أكثر كفاءة ويمكن الوصول إليه.
ومن خلال فصل برنامج التشفير المرئي ومحاذاة التمثيلات أثناء التدريب، نجح JanusFlow في سد الفجوة بين فهم الصور وتوليدها. مع استمرار أبحاث الذكاء الاصطناعي في دفع حدود قدرات النماذج، يمثل JanusFlow علامة فارقة مهمة نحو إنشاء أنظمة ذكاء اصطناعي متعددة الوسائط أكثر تنوعًا وتنوعًا.
النموذج: https://huggingface.co/deepseek-ai/JanusFlow-1.3B
الورقة: https://arxiv.org/abs/2411.07975
بشكل عام، أظهرت JanusFlow إمكانات كبيرة في مجال الذكاء الاصطناعي متعدد الوسائط بفضل بنيتها الفعالة وأدائها الممتاز، مما يشير إلى اتجاه جديد لتطوير نماذج الذكاء الاصطناعي المستقبلية. نتطلع إلى لعب JanusFlow دورًا في المزيد من سيناريوهات التطبيق!