مع التطور السريع لتكنولوجيا الذكاء الاصطناعي، يتزايد الطلب على نماذج اللغة المرئية يومًا بعد يوم، لكن متطلباتها العالية من موارد الحوسبة تحد من تطبيقها على الأجهزة العادية. سيقدم لك محرر Downcodes اليوم نموذج لغة مرئية خفيف الوزن يسمى SmolVLM، والذي يمكن تشغيله بكفاءة على الأجهزة ذات الموارد المحدودة، مثل أجهزة الكمبيوتر المحمولة ووحدات معالجة الرسومات المخصصة للمستهلك. لقد أتاح ظهور SmolVLM الفرصة لمزيد من المستخدمين لتجربة تقنية الذكاء الاصطناعي المتقدمة، وخفض عتبة الاستخدام، كما زود المطورين بأدوات بحث أكثر ملاءمة.
في السنوات الأخيرة، كان هناك طلب متزايد على تطبيق نماذج التعلم الآلي في مهام الرؤية واللغة، ولكن معظم النماذج تتطلب موارد حاسوبية ضخمة ولا يمكن تشغيلها بكفاءة على الأجهزة الشخصية. تواجه الأجهزة الصغيرة بشكل خاص مثل أجهزة الكمبيوتر المحمولة ووحدات معالجة الرسومات الاستهلاكية والأجهزة المحمولة تحديات كبيرة عند معالجة مهام اللغة المرئية.
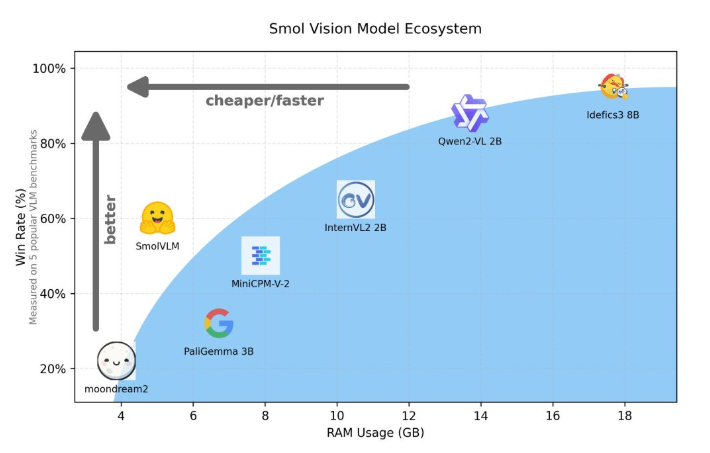
لنأخذ Qwen2-VL كمثال، على الرغم من أنه يتمتع بأداء ممتاز، إلا أنه يتطلب متطلبات عالية للأجهزة، مما يحد من سهولة استخدامه في التطبيقات في الوقت الفعلي. لذلك، أصبح تطوير نماذج خفيفة الوزن لتعمل بموارد أقل حاجة مهمة.
أصدرت Hugging Face مؤخرًا SmolVLM، وهو نموذج لغة مرئية بمعلمة 2B مصمم خصيصًا للاستدلال من جانب الجهاز. يتفوق SmolVLM على النماذج المماثلة الأخرى من حيث استخدام ذاكرة وحدة معالجة الرسومات وسرعة إنشاء الرمز المميز. وتتمثل الميزة الرئيسية له في القدرة على العمل بكفاءة على الأجهزة الأصغر حجمًا، مثل أجهزة الكمبيوتر المحمولة أو وحدات معالجة الرسومات المخصصة للمستهلك، دون التضحية بالأداء. يجد SmolVLM توازنًا مثاليًا بين الأداء والكفاءة، وحل المشكلات التي كان من الصعب التغلب عليها في النماذج المماثلة السابقة.
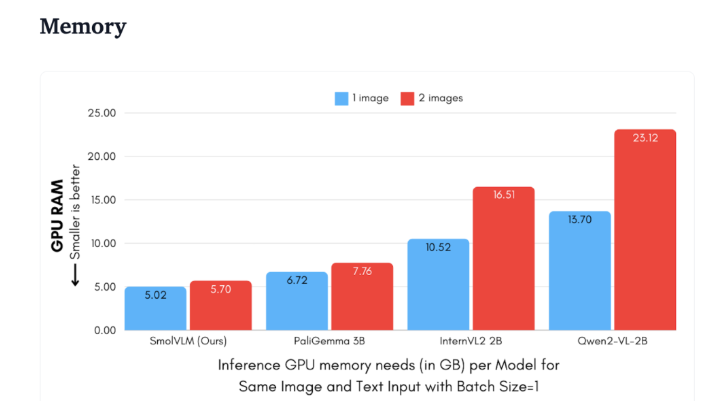
بالمقارنة مع Qwen2-VL2B، يقوم SmolVLM بإنشاء الرموز المميزة بمعدل 7.5 إلى 16 مرة أسرع، وذلك بفضل بنيته المحسنة، مما يجعل الاستدلال خفيف الوزن ممكنًا. لا تجلب هذه الكفاءة فوائد عملية للمستخدمين النهائيين فحسب، بل تعمل أيضًا على تحسين تجربة المستخدم بشكل كبير.
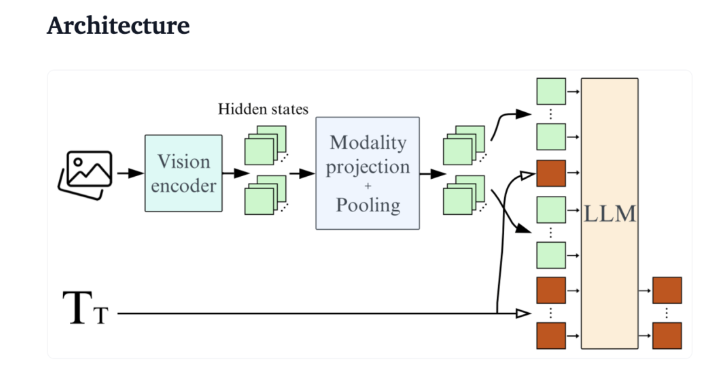
من منظور تقني، يتمتع SmolVLM ببنية محسنة تدعم الاستدلال الفعال من جانب الجهاز. ويمكن للمستخدمين أيضًا إجراء الضبط الدقيق على Google Colab بسهولة، مما يخفض حد التجريب والتطوير بشكل كبير.
نظرًا لصغر حجم الذاكرة، فإن SmolVLM قادر على العمل بسلاسة على الأجهزة التي لم تكن قادرة في السابق على استضافة نماذج مماثلة. عند اختبار مقطع فيديو من 50 إطارًا على YouTube، كان أداء SmolVLM جيدًا، حيث سجل 27.14%، وتفوق على النموذجين الأكثر استهلاكًا للموارد من حيث استهلاك الموارد، مما يدل على قدرته القوية على التكيف والمرونة.
يعد SmolVLM علامة فارقة مهمة في مجال نماذج اللغة المرئية. يتيح إطلاقه إمكانية تشغيل مهام اللغة المرئية المعقدة على الأجهزة اليومية، مما يسد فجوة مهمة في أدوات الذكاء الاصطناعي الحالية.
لا يتفوق SmolVLM في السرعة والكفاءة فحسب، بل يوفر أيضًا للمطورين والباحثين أداة قوية لتسهيل معالجة اللغة المرئية دون نفقات الأجهزة باهظة الثمن. مع استمرار تزايد شعبية تقنية الذكاء الاصطناعي، فإن نماذج مثل SmolVLM ستجعل إمكانيات التعلم الآلي القوية أكثر سهولة.
العرض التوضيحي: https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
بشكل عام، وضعت SmolVLM معيارًا جديدًا لنماذج اللغة المرئية خفيفة الوزن، وسيؤدي أدائها الفعال واستخدامها المريح إلى تعزيز تعميم تكنولوجيا الذكاء الاصطناعي وتطويرها بشكل كبير. ونحن نتطلع إلى المزيد من الابتكارات المماثلة في المستقبل، مما يسمح لتكنولوجيا الذكاء الاصطناعي بإفادة المزيد من الناس.