في السنوات الأخيرة، ظلت تكلفة التدريب على نماذج اللغة واسعة النطاق مرتفعة، الأمر الذي أصبح عاملاً مهمًا يقيد تطوير الذكاء الاصطناعي. أصبحت كيفية تقليل تكاليف التدريب وتحسين الكفاءة محور الصناعة. يقدم لك محرر Downcodes تفسيرًا لأحدث ورقة بحثية من الباحثين في جامعة هارفارد وجامعة ستانفورد. تقترح هذه الورقة قاعدة قياس "مدركة للدقة" تعمل على تقليل تكاليف التدريب بشكل فعال عن طريق ضبط دقة تدريب النموذج، حتى في بعض الحالات الحالة، يمكنها أيضًا تحسين أداء النموذج. دعونا نلقي نظرة فاحصة على هذا البحث المثير.
في مجال الذكاء الاصطناعي، يبدو أن النطاق الأكبر يعني قدرات أكبر. في سعيها وراء نماذج لغوية أكثر قوة، تعمل شركات التكنولوجيا الكبرى بشكل محموم على تكديس معلمات النماذج وبيانات التدريب، لتجد أن التكاليف آخذة في الارتفاع أيضًا. أليس هناك طريقة فعالة من حيث التكلفة وفعالة لتدريب نماذج اللغة؟
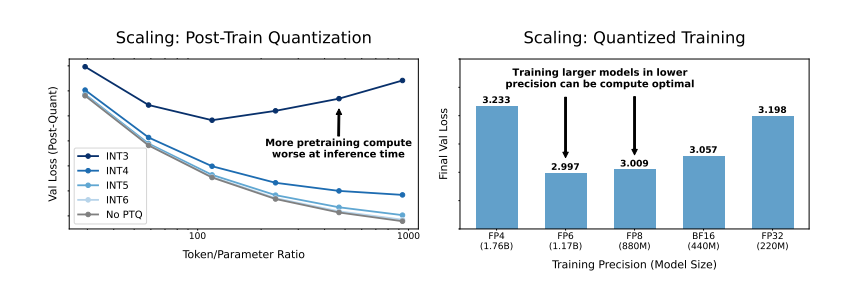
نشر باحثون من جامعتي هارفارد وستانفورد مؤخرًا بحثًا وجدوا فيه أن دقة التدريب النموذجي تشبه المفتاح المخفي الذي يمكنه فتح "رمز التكلفة" للتدريب على نماذج اللغة.
ما هي دقة النموذج؟ ببساطة، تشير إلى معلمات النموذج وعدد الأرقام المستخدمة في عملية الحساب. تستخدم نماذج التعلم العميق التقليدية عادة أرقام الفاصلة العائمة 32 بت (FP32) للتدريب، ولكن في السنوات الأخيرة، مع تطور الأجهزة، يتم استخدام أنواع أرقام أقل دقة، مثل أرقام الفاصلة العائمة 16 بت (FP16) أو 8- التدريب على الأعداد الصحيحة من البتات (INT8) ممكن بالفعل.
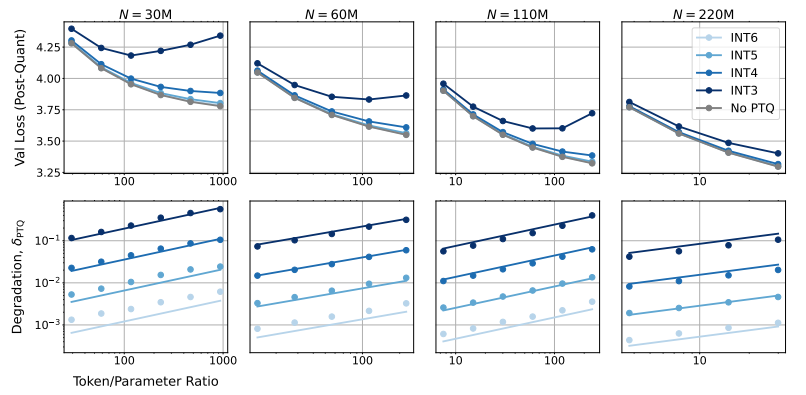
إذن، ما هو تأثير تقليل دقة النموذج على أداء النموذج؟ هذا هو بالضبط السؤال الذي تريد هذه الورقة استكشافه. من خلال عدد كبير من التجارب، قام الباحثون بتحليل التكلفة وتغييرات الأداء للتدريب النموذجي والاستدلال في ظل دقة مختلفة، واقترحوا مجموعة جديدة من قواعد القياس "المدركة للدقة".
ووجدوا أن التدريب بدقة أقل يقلل بشكل فعال من "العدد الفعال للمعلمات" للنموذج، وبالتالي يقلل من مقدار العمليات الحسابية المطلوبة للتدريب. وهذا يعني أنه باستخدام نفس الميزانية الحسابية، يمكننا تدريب نماذج واسعة النطاق، أو على نفس النطاق، باستخدام دقة أقل يمكن أن يوفر الكثير من الموارد الحسابية.
والأكثر إثارة للدهشة هو أن الباحثين وجدوا أيضًا أنه في بعض الحالات، يمكن أن يؤدي التدريب بدقة أقل إلى تحسين أداء النموذج، على سبيل المثال، بالنسبة لأولئك الذين يحتاجون إلى "التكميم بعد التدريب" إذا كان النموذج يستخدم دقة أقل أثناء مرحلة التدريب! سيكون النموذج أكثر قوة لتقليل الدقة بعد التكميم، وبالتالي يظهر أداء أفضل خلال مرحلة الاستدلال.
إذًا، ما هي الدقة التي يجب أن نختارها لتدريب النموذج؟ من خلال تحليل قواعد القياس الخاصة بهم، توصل الباحثون إلى بعض الاستنتاجات المثيرة للاهتمام:
قد لا يكون التدريب التقليدي بدقة 16 بت هو الأمثل. تشير أبحاثهم إلى أن 7-8 أرقام من الدقة قد تكون خيارًا أكثر فعالية من حيث التكلفة.
ومن غير الحكمة أيضًا اتباع تدريب منخفض الدقة (مثل 4 أرقام) بشكل أعمى. لأنه عند الدقة المنخفضة للغاية، سينخفض عدد المعلمات الفعالة للنموذج بشكل حاد. ومن أجل الحفاظ على الأداء، نحتاج إلى زيادة حجم النموذج بشكل كبير، الأمر الذي سيؤدي بدوره إلى ارتفاع التكاليف الحسابية.
قد تختلف دقة التدريب المثالية بالنسبة للنماذج ذات الأحجام المختلفة. بالنسبة لتلك النماذج التي تتطلب الكثير من "التدريب الزائد"، مثل سلسلة Llama-3 وGemma-2، قد يكون التدريب بدقة أعلى أكثر فعالية من حيث التكلفة.
يوفر هذا البحث منظورًا جديدًا لفهم وتحسين التدريب على نماذج اللغة. ويخبرنا أن اختيار الدقة ليس ثابتًا، ولكن يجب وزنه بناءً على حجم النموذج المحدد وحجم بيانات التدريب وسيناريوهات التطبيق.
وبطبيعة الحال، هناك بعض القيود على هذه الدراسة. على سبيل المثال، النموذج الذي استخدموه صغير الحجم نسبيًا، وقد لا تكون النتائج التجريبية قابلة للتعميم مباشرة على النماذج الأكبر حجمًا. بالإضافة إلى ذلك، فقد ركزوا فقط على وظيفة الخسارة للنموذج ولم يقيموا أداء النموذج في المهام النهائية.
ومع ذلك، لا يزال لهذا البحث آثار مهمة. فهو يكشف عن العلاقة المعقدة بين دقة النموذج وأداء النموذج وتكلفة التدريب، ويوفر لنا رؤى قيمة لتصميم وتدريب نماذج لغوية أكثر قوة واقتصادية في المستقبل.
الورقة: https://arxiv.org/pdf/2411.04330
بشكل عام، يقدم هذا البحث أفكارًا وطرقًا جديدة لتقليل تكلفة التدريب على نماذج اللغة على نطاق واسع، ويوفر قيمة مرجعية مهمة لتطوير الذكاء الاصطناعي في المستقبل. يتطلع محرر Downcodes إلى مزيد من التقدم في أبحاث دقة النماذج ويساهم في بناء نماذج ذكاء اصطناعي أكثر فعالية من حيث التكلفة.