إن التطور السريع لنماذج اللغات الكبيرة (LLM) أمر مثير للإعجاب، ولكن مجرد السعي إلى توسيع نطاق النموذج لا يكفي لتحقيق ذكاء الذكاء الاصطناعي الحقيقي. يعتقد محرر Downcodes أن منح النموذج القدرة على التطور الذاتي حتى يتمكن من الاستمرار في التعلم والتحسين خلال مرحلة الاستدلال أمر بالغ الأهمية للتطوير المستقبلي للذكاء الاصطناعي. سوف تستكشف هذه المقالة العامل الرئيسي في التطور الذاتي للذكاء الاصطناعي - الذاكرة طويلة المدى (LTM)، وكيفية تحقيق التقدم المستمر في الذكاء الاصطناعي من خلال LTM.
أظهرت نماذج اللغات الكبيرة (LLM)، مثل سلسلة GPT، قدرات مذهلة في فهم اللغة والاستدلال والتخطيط باستخدام مجموعات البيانات الضخمة الخاصة بها، ووصلت إلى مستويات مماثلة للبشر في مختلف المهام الصعبة. وقد ركزت معظم الأبحاث على مواصلة تعزيز هذه النماذج من خلال تدريبها على مجموعات بيانات أكبر، بهدف تطوير نماذج أساسية أكثر قوة.
ومع ذلك، على الرغم من أن تدريب نموذج أساسي أكثر قوة أمر بالغ الأهمية، إلا أن الباحثين يعتقدون أن إعطاء النموذج القدرة على الاستمرار في التطور خلال مرحلة الاستدلال، أي التطور الذاتي للذكاء الاصطناعي، أمر بالغ الأهمية أيضًا لتطوير الذكاء الاصطناعي. بالمقارنة مع استخدام بيانات واسعة النطاق لتدريب النموذج، قد يتطلب التطور الذاتي فقط بيانات أو تفاعلات محدودة.
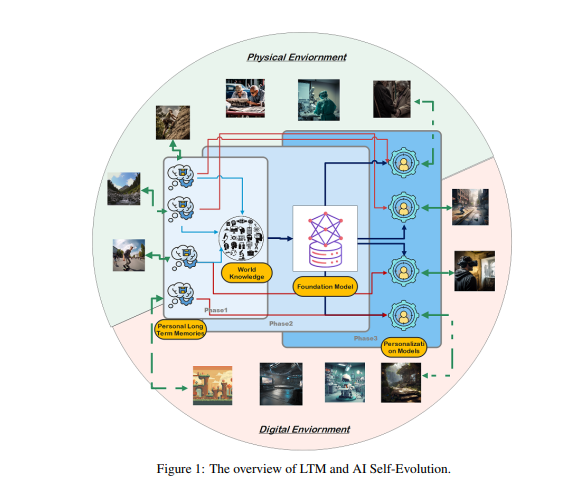
مستوحاة من البنية العمودية للقشرة الدماغية البشرية، افترض الباحثون أن نماذج الذكاء الاصطناعي يمكنها تطوير القدرات المعرفية الناشئة وبناء نماذج تمثيل داخلية من خلال التفاعلات التكرارية مع بيئتها.
ولتحقيق هذا الهدف، اقترح الباحثون أن النموذج يجب أن يحتوي على ذاكرة طويلة المدى (LTM) لتخزين وإدارة بيانات التفاعل الواقعية المعالجة. إن LTM ليس فقط قادرًا على تمثيل البيانات الفردية طويلة المدى في النماذج الإحصائية، ولكنه أيضًا يعزز التطور الذاتي من خلال دعم التجارب المتنوعة عبر بيئات ووكلاء مختلفين.
LTM هو المفتاح لتحقيق التطور الذاتي للذكاء الاصطناعي. على غرار الطريقة التي يتعلم بها البشر ويتحسنون باستمرار من خلال التجربة الشخصية والتفاعل مع البيئة، يعتمد التطور الذاتي لنماذج الذكاء الاصطناعي أيضًا على بيانات LTM المتراكمة أثناء التفاعلات. على عكس التطور البشري، لا يقتصر تطور النموذج المعتمد على LTM على التفاعلات في العالم الحقيقي. يمكن للنماذج أن تتفاعل مع البيئة المادية مثل البشر وتتلقى تعليقات مباشرة، والتي تتم معالجتها لتعزيز قدراتها. وهذا أيضًا مجال بحث رئيسي في الذكاء الاصطناعي المتجسد.
من ناحية أخرى، يمكن للنماذج أيضًا أن تتفاعل في بيئات افتراضية وتتراكم بيانات LTM، وهي أقل تكلفة وأكثر كفاءة من التفاعل في العالم الحقيقي، وبالتالي تعزيز القدرات بشكل أكثر فعالية.
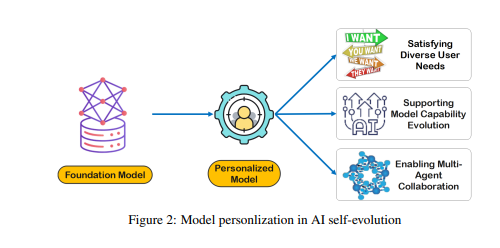
يتطلب بناء LTM تحسين البيانات الأولية وتنظيمها. تشير البيانات الأولية إلى جمع كافة البيانات غير المعالجة التي يتلقاها النموذج من خلال التفاعل مع البيئة الخارجية أو أثناء عملية التدريب. تحتوي هذه البيانات على مجموعة متنوعة من الملاحظات والسجلات، والتي قد تحتوي على أنماط قيمة وكميات كبيرة من المعلومات الزائدة أو غير ذات الصلة.
في حين أن البيانات الأولية تشكل أساس نموذج الذاكرة والإدراك، إلا أنها تتطلب المزيد من المعالجة قبل أن يتم استخدامها بشكل فعال للتخصيص أو تنفيذ المهام بكفاءة. يقوم LTM بتحسين هذه البيانات الأولية وبنيتها بحيث يمكن للنموذج استخدامها. تعمل هذه العملية على تحسين قدرة النموذج على تقديم استجابات وتوصيات مخصصة.
يواجه بناء LTM تحديات مثل تناثر البيانات وتنوع المستخدمين. في أنظمة LTM التي يتم تحديثها باستمرار، يعد تناثر البيانات مشكلة شائعة، خاصة بالنسبة للمستخدمين الذين لديهم سجل تفاعل محدود أو أنشطة متفرقة، مما يجعل التدريب النموذجي صعبًا. بالإضافة إلى ذلك، يضيف تنوع المستخدمين أيضًا تعقيدًا، مما يتطلب نماذج للتكيف مع الأنماط الفردية والتعميم الفعال عبر مجموعات المستخدمين المختلفة.
طور الباحثون إطار عمل تعاوني متعدد الوكلاء يسمى Omne، والذي ينفذ التطور الذاتي للذكاء الاصطناعي استنادًا إلى LTM. في هذا الإطار، يتمتع كل وكيل ببنية نظام مستقلة ويمكنه التعلم بشكل مستقل وتخزين نموذج بيئة كامل لبناء فهم مستقل للبيئة. من خلال هذا التطوير التعاوني القائم على LTM، يمكن لنظام الذكاء الاصطناعي التكيف مع التغييرات في السلوك الفردي في الوقت الفعلي، وتحسين تخطيط المهام وتنفيذها، ومواصلة تعزيز التطور الذاتي المخصص والفعال للذكاء الاصطناعي.
حقق إطار Omne المركز الأول في اختبار GAIA القياسي، مما يثبت الإمكانات الهائلة للاستفادة من LTM للتطور الذاتي للذكاء الاصطناعي وحل مشكلات العالم الحقيقي. ويعتقد الباحثون أن تطوير أبحاث LTM أمر بالغ الأهمية للتطوير المستمر والتطبيق العملي لتكنولوجيا الذكاء الاصطناعي، وخاصة فيما يتعلق بالتطور الذاتي.
وبشكل عام، تعد الذاكرة طويلة المدى أمرًا أساسيًا للتطور الذاتي للذكاء الاصطناعي، مما يمكّن نماذج الذكاء الاصطناعي من التعلم والتحسين من خلال التجربة تمامًا مثل البشر. يتطلب بناء LTM والاستفادة منه التغلب على التحديات مثل تناثر البيانات وتنوع المستخدمين. يوفر إطار عمل Omne حلاً ممكنًا للتطور الذاتي للذكاء الاصطناعي القائم على LTM، ويوضح نجاحه في اختبار GAIA المعياري الإمكانات الهائلة في هذا المجال.
الورقة: https://arxiv.org/pdf/2410.15665
من خلال البحث في الذاكرة طويلة المدى (LTM)، لم يعد التطور الذاتي للذكاء الاصطناعي حلمًا بعيد المنال. في المستقبل، من المتوقع أن تُظهر نماذج الذكاء الاصطناعي المستندة إلى LTM قدرات أكثر قوة في نطاق أوسع من المجالات وتحقيق فوائد أكبر للمجتمع البشري. نتطلع إلى المزيد من النتائج المبتكرة!