في الآونة الأخيرة، ذكر تاداشي ناجا، رئيس قسم الأعمال اليابانية في OpenAI، "GPT Next" في مؤتمر أعمال، مما أثار مناقشات ساخنة في الصناعة حول الجيل التالي من نماذج اللغات واسعة النطاق. علم محرر Downcodes أن هذا البيان تم توضيحه رسميًا لاحقًا بواسطة OpenAI باعتباره بيانًا مجازيًا، وليس اسم المنتج الفعلي أو خطة الإصدار. تذكرنا هذه الحادثة مرة أخرى أنه يجب النظر إلى الشائعات في مجال الذكاء الاصطناعي بحذر لتجنب سوء الفهم غير الضروري.
في مؤتمر أعمال هذا الأسبوع، أدلى تاداو ناجازاكي، رئيس أعمال اليابان في شركة OpenAI، بتصريحات جذبت اهتماما واسع النطاق. وذكر "GPT Next"، والذي يتم تفسيره على نطاق واسع على أنه الجيل القادم من نموذج اللغة الكبير (LLM).
ومع ذلك، مع احتدام النقاش، خرجت شركة OpenAI لتوضيح هذا البيان. الكلمات "GPT Next" المكتوبة بين علامتي اقتباس على شريحة Tadashi هي مجرد عنصر نائب مجازي لإظهار كيف ستتطور نماذج OpenAI بشكل كبير مع مرور الوقت. وأوضح المتحدث الرسمي أيضًا أن الرسم البياني الخطي الموجود في الشريحة توضيحي وليس جدولًا زمنيًا فعليًا لخطط OpenAI.
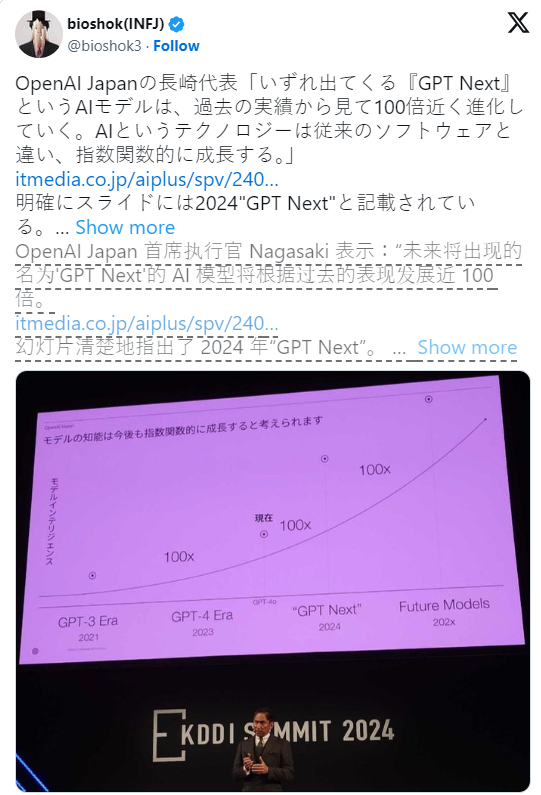
وفي السابق، قال Zhongzhiyong في المؤتمر: "إن نموذج الذكاء الاصطناعي القادم المسمى GPT Next سوف يتطور ما يقرب من 100 مرة بناءً على الإنجازات السابقة."
وتضمنت الشرائح التي عرضها تاداشي في المؤتمر، الانتقال من "عصر GPT-3" في عام 2021 إلى "عصر GPT-4" في عام 2023، إلى عصر "GPT Next" في عام 2024، وكذلك عصر "202x". الجدول الزمني لـ”نموذج المستقبل”.
يوضح توضيح OpenAI سوء الفهم الذي يحدث بسهولة أثناء نشر المعلومات، ويعكس أيضًا تركيز الشركة على دقة المعلومات. على الرغم من أن "GPT Next" ليس مشروعًا فعليًا، إلا أن تصميم OpenAI على الاستمرار في تطوير نماذج ذكاء اصطناعي أكثر قوة لا يزال يستحق التطلع إليه.